docker部署springboot(eureka server)项目
打jar包
使用maven:
<build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><configuration><source>17</source><target>17</target><encoding>UTF-8</encoding></configuration></plugin><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build>
打开idea右侧的 Maven 工具窗口(View → Tool Windows → Maven)双击 package 目标
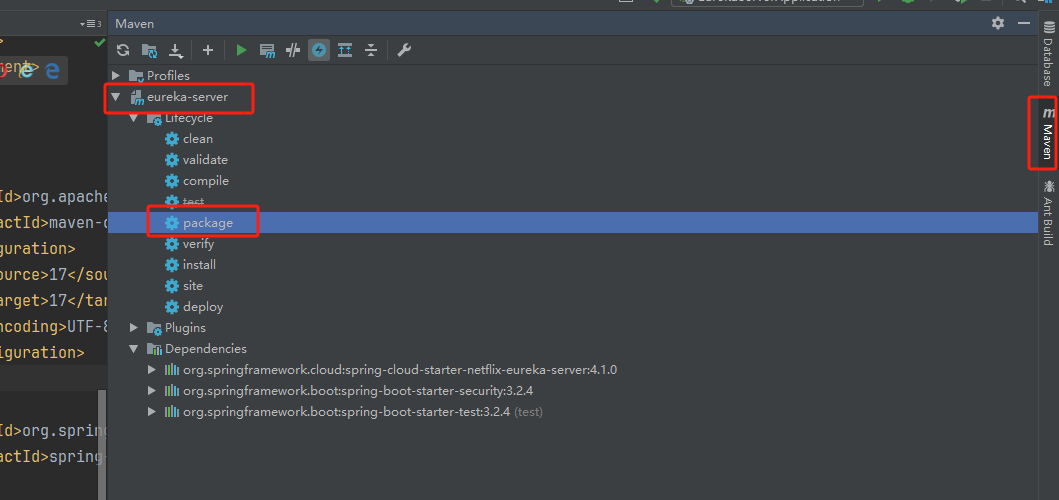
生成的jar包:
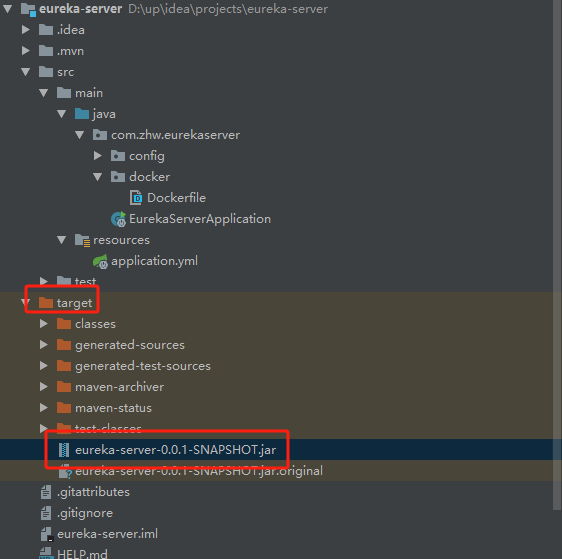
Dockerfile文件
# 基础镜像使用java
# Docker 首先检查本地是否已存在指定的镜像(包括名称和标签):
# 如果存在,则直接使用本地镜像。
# 若本地没有镜像,Docker 会尝试从配置的镜像仓库拉取(默认是 Docker Hub)
FROM openjdk:17-jdk
# 作者
LABEL maintainer="zhw"
# VOLUME 指定了临时文件目录为/tmp。
# 其效果是在主机 /var/lib/docker 目录下创建了一个临时文件,并链接到容器的/tmp
VOLUME /tmp
# 将jar包添加到容器中并更名为app.jar
ADD eureka-server-0.0.1-SNAPSHOT.jar eureka-server.jar
# 运行jar包
RUN bash -c 'touch /eureka-server.jar'
ENTRYPOINT ["java","-Duser.timezone=GMT+8","-Djava.security.egd=file:/dev/./urandom","-jar","/eureka-server.jar"]
上传Dockerfile jar包至服务器

拉取open-jdk 17 作为基础镜像
# 对应dockerfile中 FROM openjdk:17-jdk
docker pull openjdk:17-jdk
eureka-server 生成镜像
docker build -t eureka-server:0 .
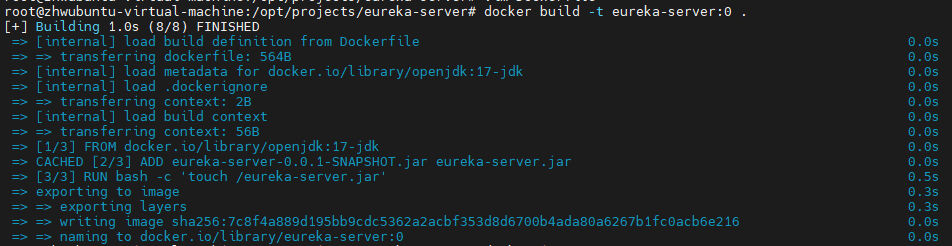
运行镜像
docker run --name eureka-server -d --restart always -p 9007:8800 eureka-server:0

访问 eureka页面
http://10.0.1.129:9007/

添加环境变量
1.通过 Dockerfile 定义环境变量
在构建镜像时使用 ENV 指令设置 默认环境变量(适合不敏感配置):
ENV SPRING_PROFILES_ACTIVE=prod \APP_PORT=8080
2.通过 docker run 命令行传递
运行容器时通过 -e 动态覆盖环境变量:
docker run -d \-e "SPRING_PROFILES_ACTIVE=prod" \-e "DB_URL=jdbc:mysql://db-host:3306/mydb" \-p 8080:8080 \my-spring-app