Windows程序包管理器WinGet实战
概述
WinGet,Windows Package Manager,Windows软件包管理器,开源在GitHub,GitHub Releases可下载,官方文档。
WinGet由一个命令行工具和一组用于在Windows 10/11等版本上安装应用的服务组成,可帮助用户快速轻松地发现及安装不同的工具。与 apt-get、pip等软件包管理器类似,WinGet提供软件包搜索、显示、列表、安装、升级、卸载等功能。
对于开发者来说,可使用WinGet命令行工具发现、安装、升级、删除和配置选定应用集。安装后,可通过Windows终端、PowerShell或cmd使用WinGet。
而独立软件供应商(ISV)可将WinGet用作集成工具和应用软件包分发渠道,通过使用开源仓库,ISV可将软件包(包括.msix、.msi与.exe安装程序)提交到WinGet,用户再通过WinGet命令即可获取相应软件。
安装
Windows 11默认自带WinGet。
注:本文使用的WinGet是v1.10.340。
使用
输入winget,输出:
Windows 程序包管理器 v1.10.340
版权所有 (C) Microsoft Corporation。保留所有权利。WinGet 命令行实用工具可从命令行安装应用程序和其他程序包。使用情况: winget [<命令>] [<选项>]下列命令有效:install 安装给定的程序包show 显示包的相关信息source 管理程序包的来源search 查找并显示程序包的基本信息list 显示已安装的程序包upgrade 显示并执行可用升级uninstall 卸载给定的程序包hash 哈希安装程序的帮助程序validate 验证清单文件settings 打开设置或设置管理员设置features 显示实验性功能的状态export 导出已安装程序包的列表import 安装文件中的所有程序包pin 管理包钉configure 将系统配置为所需状态download 从给定的程序包下载安装程序repair 修复所选包如需特定命令的更多详细信息,请向其传递帮助参数。 [-?]下列选项可用:-v,--version 显示工具的版本--info 显示工具的常规信息-?,--help 显示选定命令的帮助信息--wait 提示用户在退出前按任意键--logs,--open-logs 打开默认日志位置--verbose,--verbose-logs 启用 WinGet 的详细日志记录--nowarn,--ignore-warnings 禁止显示警告输出--disable-interactivity 禁用交互式提示--proxy 设置要用于此执行的代理--no-proxy 禁止对此执行使用代理
winget list
winget list输出如下:

如上图,Git之前并不是通过WinGet安装的,而是直接去Git官网下载并安装的,也能被WinGet统一管理。
文本版:
>winget list
名称 ID 版本 可用 源
-----------------------------------------------------------------------------------------------------------------------
Redis Insight 2.66.0 ARP\Machine\X64\35443657-9fe0-5c86-… 2.66.0
Sublime Text ARP\Machine\X64\Sublime Text_is1 Unknown
飞书 ByteDance.Feishu 7.38.6
Python Launcher Python.Launcher > 3.12.0 winget
Windows 终端 Microsoft.WindowsTerminal 1.21.10351.0 1.22.10352.0 winget
包含5列:
- 名称:含有空格、英文、中文
- ID:唯一标识符
- 版本:当前安装的版本
- 可用:可更新的版本
- 源:两种,winget或空白
winget list列出的软件太多,可通过管道符加上find或findstr命令过滤。默认情况下,find是大小写敏感的,加上/I忽略大小写:
>winget list | find "Sublime"
Sublime Text ARP\Machine\X64\Sublime Text_is1 Unknown
>winget list | find "sublime"
>winget list | find /I "sublime"
Sublime Text ARP\Machine\X64\Sublime Text_is1 Unknown
>winget list | findstr "Sublime"
Sublime Text SublimeHQ.SublimeText.4 Unknown 4.0.0.419200 winget
另外需要注意的是,是对第二列进行搜索:
>winget list | find /I "FeiShu"
椋炰功 ByteDance.Feishu 7.38.6 winget
>winget list | find /I "飞书"
如上,只有英文才有输出,中文先是还有乱码。
另外需要注意的是,在CMD Terminal下使用find搜索,在PowerShell得使用findstr命令。
winget search
网站,以可视化的UI界面提供近万个Windows App,可看到简介、最后更新时间、版本号、开发者等信息:
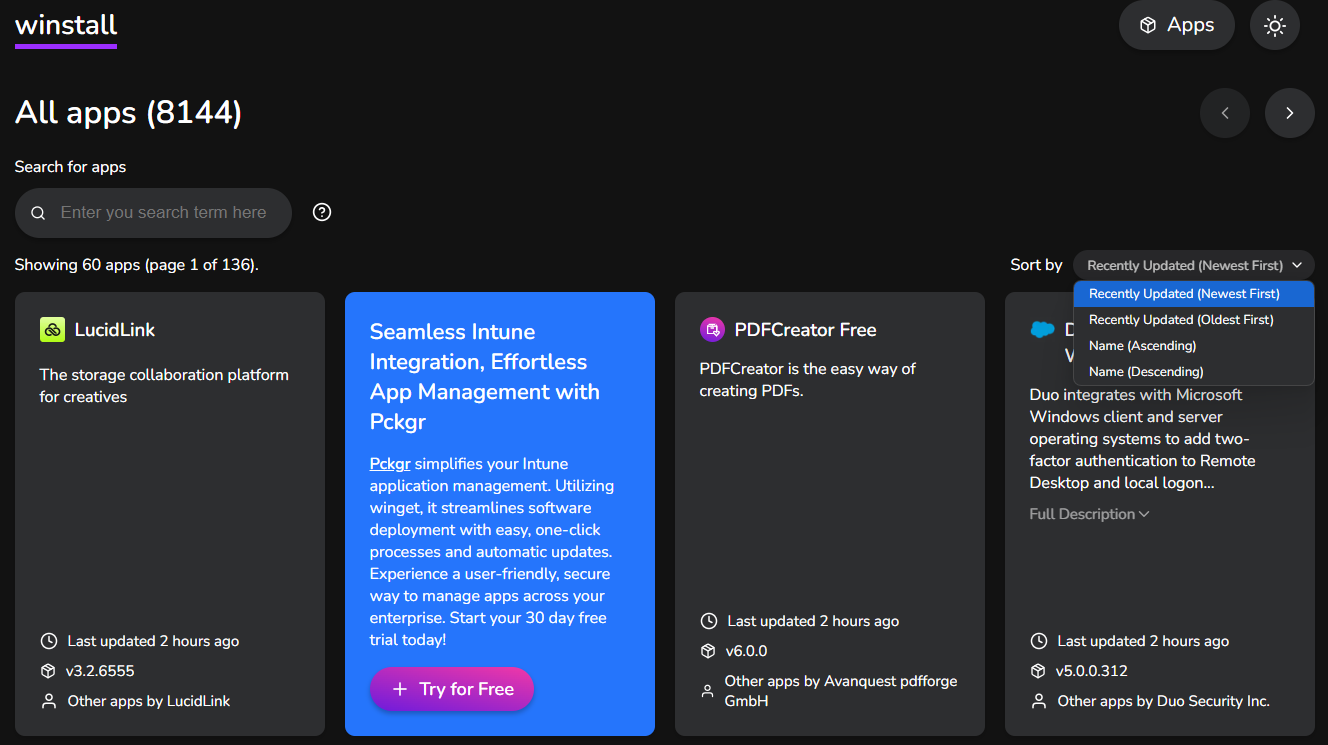
类似于AppStore,或Windows Store,可浏览一些常用的或有趣的App。
此外还可以通过命令行方式。使用winget search搜索软件时,对于含有空格的软件,需要带上双引号:
>winget search sublime text
在未预期的情况下找到位置参数: "text"
>winget search "sublime text"
名称 ID 版本 源
--------------------------------------------------------------------------
Sublime Text 3 SublimeHQ.SublimeText.3 3.2.2 winget
Sublime Text 3 SublimeHQ.SublimeText.3.Portable 3211 winget
Sublime Text 4 SublimeHQ.SublimeText.4 4.0.0.419200 winget
Sublime Text 4 (Dev) SublimeHQ.SublimeText.4.Dev 4.0.0.417300 winget
Sublime Text 4 SublimeHQ.SublimeText.4.Portable 4143 winget
winget show
使用winget show显示软件具体信息,如:winget show SublimeHQ.SublimeText.4,输出省略。
winget install
不管是通过网站,还是通过winget search搜索到App,都可通过命令并指定--id安装:
winget install --id=SublimeHQ.SublimeText.4 -e
如果已经安装sublime text并且没有退出该应用程序,安装会失败并给出提示信息:
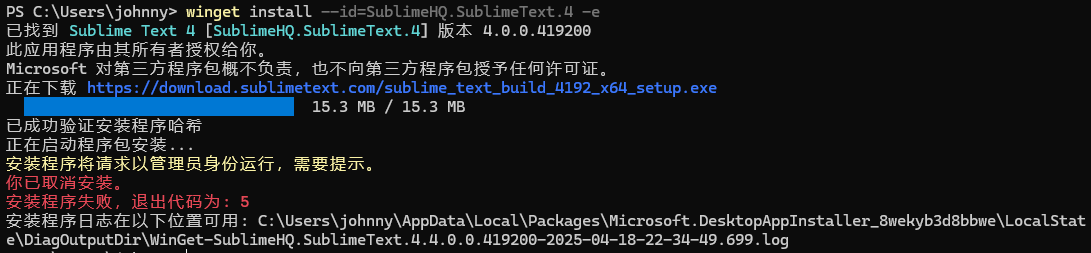
查看日志:
Log opened. (Time zone: UTC+08:00)
Setup version: Inno Setup version 5.5.9 (u)
Original Setup EXE: C:\Users\johnny\AppData\Local\Temp\WinGet\SublimeHQ.SublimeText.4.4.0.0.419200\sublime_text_build_4192_x64_setup.exe
Setup command line: /SL5="$6807C8,15677780,121344,C:\Users\johnny\AppData\Local\Temp\WinGet\SublimeHQ.SublimeText.4.4.0.0.419200\sublime_text_build_4192_x64_setup.exe" /SPAWNWND=$280928 /NOTIFYWND=$331820 /SP- /SILENT /SUPPRESSMSGBOXES /NORESTART /LOG="C:\Users\johnny\AppData\Local\Packages\Microsoft.DesktopAppInstaller_8wekyb3d8bbwe\LocalState\DiagOutputDir\WinGet-SublimeHQ.SublimeText.4.4.0.0.419200-2025-04-18-22-34-49.699.log"
Windows version: 10.0.26100 (NT platform: Yes)
64-bit Windows: Yes
Processor architecture: x64
User privileges: Administrative
64-bit install mode: Yes
Created temporary directory: C:\Users\johnny\AppData\Local\Temp\is-591P8.tmp
RestartManager found an application using one of our files: Sublime Text
RestartManager found an application using one of our files: plugin_host-3.3.exe
RestartManager found an application using one of our files: plugin_host-3.8.exe
RestartManager found an application using one of our files: crash_handler.exe
Can use RestartManager to avoid reboot? Yes (0)
Starting the installation process.
Shutting down applications using our files.
Some applications could not be shut down.
Defaulting to Abort for suppressed message box (Abort/Retry/Ignore):Setup was unable to automatically close all applications. It is recommended that you close all applications using files that need to be updated by Setup before continuing.Click Retry to try again, Ignore to proceed anyway, or Abort to cancel installation.
User canceled the installation process.
Rolling back changes.
Starting the uninstallation process.
Uninstallation process succeeded.
Deinitializing Setup.
Log closed.
退出sublime text,再次执行命令,发现winget install相当于执行升级:
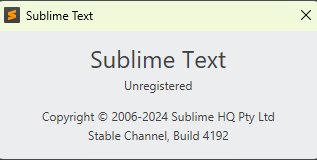
Build版本号已更新。
winget upgrade
使用winget upgrade升级软件:
>winget upgrade Microsoft.WindowsTerminal
已找到 Windows Terminal [Microsoft.WindowsTerminal] 版本 1.22.10352.0
此应用程序由其所有者授权给你。
Microsoft 对第三方程序包概不负责,也不向第三方程序包授予任何许可证。
此包需要以下依赖项:- 程序包Microsoft.UI.Xaml.2.8 [>= 8.2306.22001.0]
已成功验证安装程序哈希
正在启动程序包安装...████████████████████████████▌ 95%
已成功安装。重启应用程序以完成升级。
验证安装:
>winget list | find "Microsoft.WindowsTerminal"
Windows 缁堢 Microsoft.WindowsTerminal 1.22.10352.0 winget
winget uninstall
WinGet默认安装路径在C:\Program Files中,与下载安装包安装没有太大的差别:
>winget uninstall Npcap
已找到 Npcap [ARP\Machine\X86\NpcapInst]
正在启动程序包卸载...
已成功卸载
会弹窗二次确认。
查看命令帮助:
>winget uninstall -?
Windows 程序包管理器 v1.10.340
版权所有 (C) Microsoft Corporation。保留所有权利。通过搜索已安装的程序包列表或直接从清单中卸载选择的程序包。默认情况下,查询必须 insensitively 匹配程序包的 id、名称或名字对象。可通过传递适当的选项来使用其他字段。使用情况: winget uninstall [[-q] <query>...] [<选项>]以下命令别名可用:removerm以下参数可用:-q,--query 用于搜索程序包的查询下列选项可用:-m,--manifest 程序包清单的路径--id 按 id 筛选结果--name 按名称筛选结果--moniker 按名字对象筛选结果--product-code 使用产品代码进行筛选-v,--version 要执行的版本--all,--all-versions 卸载所有版本-s,--source 使用指定的源查找程序包-e,--exact 使用精确匹配查找程序包--scope 选择已安装的程序包范围筛选器 (user 或 machine)-i,--interactive 请求交互式安装;可能需要用户输入-h,--silent 请求无提示安装--force 直接运行命令并继续处理与安全无关的问题--purge 删除包目录中的所有文件和目录(可移植)--preserve 保留由包创建的所有文件和目录(可移植)-o,--log 日志位置(如果支持)--header 可选的 Windows-Package-Manager REST 源 HTTP 标头--authentication-mode 指定身份验证窗口首选项(silent、silentPreferred 或 interactive)--authentication-account 指定用于身份验证的帐户--accept-source-agreements 在源操作期间接受所有源协议-?,--help 显示选定命令的帮助信息--wait 提示用户在退出前按任意键--logs,--open-logs 打开默认日志位置--verbose,--verbose-logs 启用 WinGet 的详细日志记录--nowarn,--ignore-warnings 禁止显示警告输出--disable-interactivity 禁用交互式提示--proxy 设置要用于此执行的代理--no-proxy 禁止对此执行使用代理
禁用交互式提示删除:
winget uninstall --disable-interactivity Wireshark
软件源
类似于,WinGet也有软件源概念。
列出软件源:
winget source list
名称 参数 显式
-----------------------------------------------------------
winget https://mirrors.ustc.edu.cn/winget-source false
msstore https://storeedgefd.dsx.mp.microsoft.com/v9.0 false
子命令可用:
# 删除指定源
winget source remove winget
# 添加源
winget source add winget https://mirrors.ustc.edu.cn/winget-source --trust-level trusted
# 更新源
winget source update
# 重置源
winget source reset winget
其他
在Windows平台下线,类似工具还有很多。
SDKMAN!
参考SDKMAN!实战。