13.编码器的结构
从入门AI到手写Transformer-13.编码器的结构
- 13.编码器的结构
- 代码
整理自视频 老袁不说话 。
13.编码器的结构
T r a n s f o r m e r E n c o d e r : 输入 [ b , n ] TransformerEncoder:输入[b,n] TransformerEncoder:输入[b,n]
- E m b e d d i n g : − > [ b , n , d ] Embedding:->[b,n,d] Embedding:−>[b,n,d]
- P o s i t i o n a l E n c o d e r : − > [ b , n , d ] PositionalEncoder:->[b,n,d] PositionalEncoder:−>[b,n,d]
- D r o p o u t : − > [ b , n , d ] Dropout:->[b,n,d] Dropout:−>[b,n,d]
- E n c o d e r B l o c k : [ b , n , d ] − > [ b , n , d ] EncoderBlock:[b,n,d]->[b,n,d] EncoderBlock:[b,n,d]−>[b,n,d] 重复N次
- M u l t i h e a d A t t e n t i o n : 3 ∗ [ b , n , d ] − > [ b , n , d ] MultiheadAttention:3*[b,n,d]->[b,n,d] MultiheadAttention:3∗[b,n,d]−>[b,n,d]
- D r o p o u t : [ b , n , d ] − > [ b , n , d ] Dropout:[b,n,d]->[b,n,d] Dropout:[b,n,d]−>[b,n,d]
- A d d N o r m : 2 ∗ [ b , n , d ] ( D r o u p o u t 输出, M u l t i h e a d A t t e n t i o n 输入 ) − > [ b , n , d ] AddNorm:2*[b,n,d](Droupout输出,MultiheadAttention输入)->[b,n,d] AddNorm:2∗[b,n,d](Droupout输出,MultiheadAttention输入)−>[b,n,d]
- F F N : [ b , n , d ] − > [ b , n , d ] FFN:[b,n,d]->[b,n,d] FFN:[b,n,d]−>[b,n,d]
- D r o p o u t : [ b , n , d ] − > [ b , n , d ] Dropout:[b,n,d]->[b,n,d] Dropout:[b,n,d]−>[b,n,d]
- A d d N o r m : 2 ∗ [ b , n , d ] ( D r o u p o u t 输出, F F N 输入 ) − > [ b , n , d ] AddNorm:2*[b,n,d](Droupout输出,FFN输入)->[b,n,d] AddNorm:2∗[b,n,d](Droupout输出,FFN输入)−>[b,n,d]
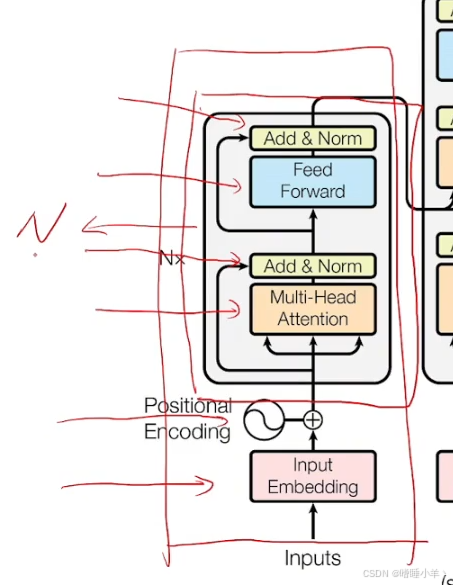
编码器结构
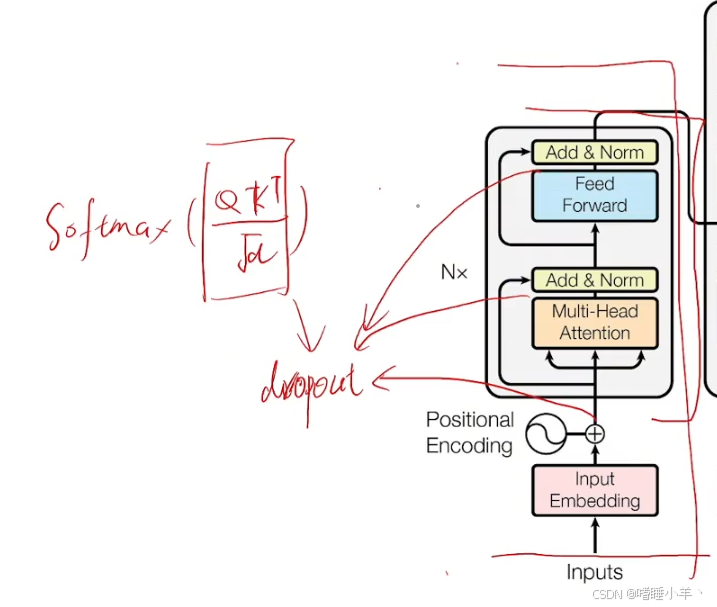
多处执行Dropout
代码
import torch.nn as nnclass Embedding(nn.Module):def __init__(self,*args,**kwargs)->None:super().__init__(*args,**kwargs)def forward(self):print(self.__class__.__name__)
class PositionalEncoding(nn.Module):def __init__(self,*args,**kwargs)->None:super().__init__(*args,**kwargs)def forward(self):print(self.__class__.__name__)
class MultiheadAttention(nn.Module):def __init__(self,*args,**kwargs)->None:super().__init__(*args,**kwargs)def forward(self):print(self.__class__.__name__)
class Dropout(nn.Module):def __init__(self,*args,**kwargs)->None:super().__init__(*args,**kwargs)def forward(self):print(self.__class__.__name__)
class AddNorm(nn.Module):def __init__(self,*args,**kwargs)->None:super().__init__(*args,**kwargs)def forward(self):print(self.__class__.__name__)
class FFN(nn.Module):def __init__(self,*args,**kwargs)->None:super().__init__(*args,**kwargs)def forward(self):print(self.__class__.__name__)class EncoderBlock(nn.Module):def __init__(self,*args, **kwargs)->None:super().__init__(*args,**kwargs)self.mha = MultiheadAttention()self.dropout1=Dropout()self.addnorm1=AddNorm()self.ffn=FFN()self.dropout2=Dropout()self.addnorm2 = AddNorm()def forward(self):self.mha()self.dropout1()self.addnorm1()self.ffn()self.dropout2()self.addnorm2()class TransformerEncoder(nn.Module):def __init__(self,*args,**kwargs)->None:super().__init__(*args,**kwargs)self.embedding=Embedding() # 把序号转变为有语义信息的编码self.posenc=PositionalEncoding()self.dropout=Dropout()self.encblocks=nn.Sequential()for i in range(3):self.encblocks.add_module(str(i),EncoderBlock())def forward(self):self.embedding()self.posenc()self.dropout()for i,blk in enumerate(self.encblocks):print(i)blk()te=TransformerEncoder()
te()
输出结果
Embedding
PositionalEncoding
Dropout
0
MultiheadAttention
Dropout
AddNorm
FFN
Dropout
AddNorm
1
MultiheadAttention
Dropout
AddNorm
FFN
Dropout
AddNorm
2
MultiheadAttention
Dropout
AddNorm
FFN
Dropout
AddNorm