DFS/BFS专练-搞定图论基础!(从海岛问题过渡至图论基础应用C++/C)

:: 图论基础理论 :: 紧接着,图论基础理论中,咱们讲到,图论的遍历主要由(dfs与bfs决定)
那咱们本篇博客就来聊聊dfs与bfs。
dfs(深度优先搜索)、bfs(广度优先搜索)的区别:
- dfs(深度优先),就如名字一般,优先不断向下探索。不到黄河不回头,一直到达了绝境之后,才会回溯到原本的位置,然后换个方向,用同样的方式继续遍历。
- bfs(广度优先),优先遍历与本节点相连的所有节点。遍历完毕之后,到达下一个节点,继续用同样的方式遍历。
为什么要讲两种遍历方式呢,因为在创建 邻接表 与 邻接矩阵 之后,想要运用,最基本的就是遍历。
当然、想要掌握一个知识点,靠的从来不是纯概念。
接下来,咱们用dfs遍历邻接表与邻接矩阵。用来练手。
DFS(深度优先搜索)
DFS(深度优先遍历)模版:
void dfs(参数){if(终止条件){存放结果;return;}for(选择:本节点相连的其他节点){处理节点dfs(图,选择的节点);回溯,撤销处理的结果}
}那咱们根据例题,实战一下吧。
98. 所有可达路径
题目描述
给定一个有 n 个节点的有向无环图,节点编号从 1 到 n。请编写一个函数,找出并返回所有从节点 1 到节点 n 的路径。每条路径应以节点编号的列表形式表示。
输入描述
第一行包含两个整数 N,M,表示图中拥有 N 个节点,M 条边
后续 M 行,每行包含两个整数 s 和 t,表示图中的 s 节点与 t 节点中有一条路径
输出描述
输出所有的可达路径,路径中所有节点之间空格隔开,每条路径独占一行,存在多条路径,路径输出的顺序可任意。如果不存在任何一条路径,则输出 -1。
注意输出的序列中,最后一个节点后面没有空格! 例如正确的答案是 `1 3 5`,而不是 `1 3 5 `, 5后面没有空格!
输入示例
5 5 1 3 3 5 1 2 2 4 4 5输出示例
1 3 5 1 2 4 5提示信息
用例解释:
有五个节点,其中的从 1 到达 5 的路径有两个,分别是 1 -> 3 -> 5 和 1 -> 2 -> 4 -> 5。
因为拥有多条路径,所以输出结果为:
1 3 5
1 2 4 5或
1 2 4 5
1 3 5
都算正确。数据范围:
- 图中不存在自环
- 图中不存在平行边
- 1 <= N <= 100
- 1 <= M <= 500
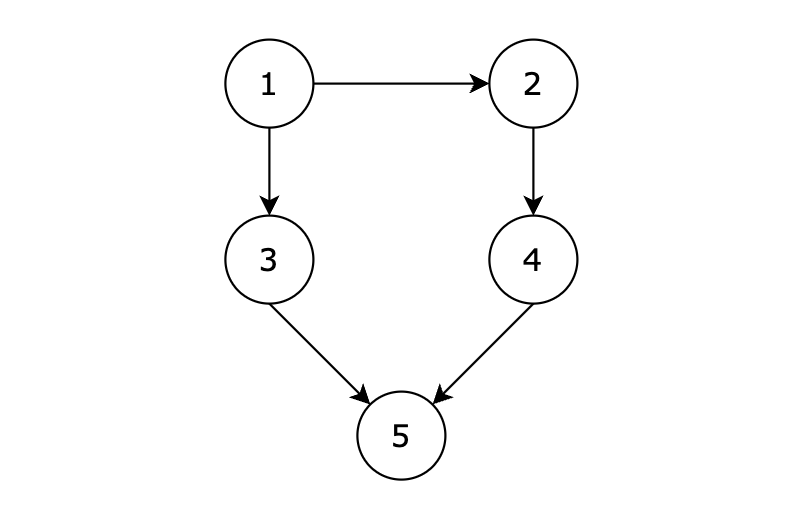
利用邻接矩阵进行深搜:
#include <iostream>
#include <vector>
using namespace std;
const int N = 105;
// 定义邻接矩阵,用于存储图的连接关系
// arr[i][j] = 1 表示存在从节点 i 到节点 j 的有向边
int arr[N][N];
// 存储当前正在探索的路径
vector<int> cur;
// 存储所有从节点 1 到节点 n 的路径
vector<vector<int>> res; // 深度优先搜索函数
// k 表示当前正在访问的节点
// n 表示图中节点的总数
void dfs(int k, int n) { // 如果当前节点是目标节点 nif (k == n) { // 将当前路径添加到结果集合中// emplace_back 比 push_back 更高效res.emplace_back(cur); return;}// 遍历所有可能的下一个节点for (int i = 1; i <= n; ++i) { // 如果存在从节点 k 到节点 i 的有向边if (arr[k][i] == 1) { // 将节点 i 添加到当前路径中cur.emplace_back(i); // 递归调用 dfs 函数,继续探索从节点 i 出发的路径dfs(i, n); // 回溯操作,移除最后添加的节点,以便尝试其他路径cur.pop_back(); }}
}int main() {int n, m;// 输入节点数量 n 和边的数量 mcin >> n >> m; // 有向图,存储边的信息for (int i = 0; i < m; ++i) {int x, y;// 输入边的起点 x 和终点 ycin >> x >> y; // 在邻接矩阵中标记存在从节点 x 到节点 y 的有向边arr[x][y] = 1; }// 首先将起始节点 1 存入当前路径cur.emplace_back(1); // 从节点 1 开始进行深度优先搜索dfs(1, n); // 如果没有找到从节点 1 到节点 n 的路径if (res.size() == 0) { // 输出 -1 表示无解cout << -1 << endl; }// 如果找到了从节点 1 到节点 n 的路径else if (res.size() != 0) { // 遍历所有找到的路径for (auto vec : res) { // 输出路径中的每个节点,除了最后一个节点for (int i = 0; i < vec.size() - 1; ++i) { cout << vec[i] << " ";}// 输出路径中的最后一个节点,并换行cout << vec[vec.size() - 1] << endl; }}return 0;
}利用邻接表进行深搜:
#include <iostream>
#include <vector>
#include <list>
using namespace std;
// 定义常量 N,用于表示图中节点数量的上限
const int N = 105;
// 采用邻接表来表示图,graph[i] 存储的是从节点 i 出发能到达的所有节点
// 这里使用 vector<list<int>> 类型,每个元素是一个链表,链表中存储邻接节点
vector<list<int>> graph(N);
// 用于存储当前正在探索的路径
vector<int> cur;
// 用于存储从起点到终点的所有路径
vector<vector<int>> res;// 深度优先搜索函数,k 表示当前所在的节点,n 表示目标节点
void dfs(int k, int n){// 当当前节点 k 等于目标节点 n 时,说明找到了一条从起点到终点的路径if(k==n){// 将当前路径 cur 添加到结果集合 res 中res.emplace_back(cur);return;}// 遍历当前节点 k 的所有邻接节点for(int i : graph[k]) {// 将邻接节点 i 添加到当前路径 cur 中cur.emplace_back(i);// 以邻接节点 i 为当前节点,继续进行深度优先搜索dfs(i, n);// 回溯操作,将邻接节点 i 从当前路径 cur 中移除// 以便尝试其他可能的路径cur.pop_back();}
}int main(){int n,m;// 输入图的节点数量 n 和边的数量 mcin>>n>>m;// 循环 m 次,每次输入一条边的信息for(int i=0; i<m; ++i){int x,y;// 输入边的起点 x 和终点 ycin>>x>>y;// 将终点 y 添加到起点 x 的邻接表中graph[x].emplace_back(y);}// 将起点 1 添加到当前路径 cur 中cur.emplace_back(1);// 从起点 1 开始进行深度优先搜索dfs(1,n);// 如果结果集合 res 为空,说明没有找到从起点到终点的路径if(res.size()==0) cout<<-1<<endl;else {// 遍历结果集合 res 中的每一条路径for(auto vec:res){// 输出路径中除最后一个节点外的其他节点,节点之间用空格分隔for(int i=0; i<vec.size()-1; ++i) cout<<vec[i]<<" ";// 输出路径中的最后一个节点,并换行cout<<vec[vec.size()-1]<<endl;}}return 0;
}BFS(广度优先搜索)
BFS优先搜索,通常用于解决,最短路径问题。
遍历方式,咱们在上方已经提及(优先遍历与本节点相连的所有节点。遍历完毕之后,到达下一个节点,继续用同样的方式遍历)。
我就直接,引入了Carl的给出的注释图了,如下图所示。
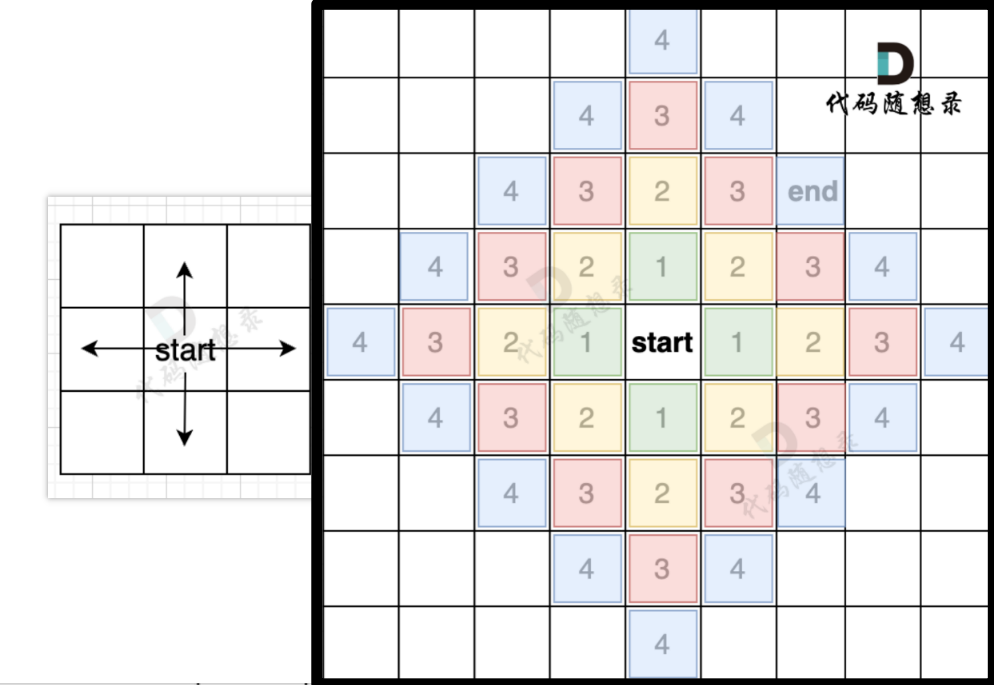
大家对图进行广搜的话,大多数需要一个容器进行媒介。大家习惯性的会用队列进行广度搜索。
但其实不论用队列、还是栈(stack),都行。只不过用栈,是一次正向遍历、一次逆向遍历而已,其实是没有影响的。
这是对图的BFS遍历方式。
// 定义一个二维数组 dir,用于表示四个方向的偏移量
// 分别为:下(1, 0)、上(-1, 0)、右(0, 1)、左(0, -1)
int dir[4][2]={1,0,-1,0,0,1,0,-1};// 定义广度优先搜索函数 bfs
// 参数 grid 是一个二维向量,表示地图或网格
// 参数 used 是一个二维布尔向量,用于标记某个位置是否已经被访问过
void bfs(vector<vector<int>> grid, vector<vector<bool>> used){// 定义一个队列 q,队列中存储的元素是 std::pair<int, int> 类型// 表示网格中的一个坐标点 (x, y)queue<pair<int,int>> q;// 将起始点 (0, 0) 加入队列q.push({0,0});// 当队列不为空时,继续进行广度优先搜索while(!q.empty()){// 获取队列的队首元素,即当前要处理的坐标点auto cur = q.front();// 将队首元素从队列中移除q.pop();// 标记当前坐标点为已访问used[cur.first][cur.second] = true;// 遍历四个方向for(int i=0; i<4; ++i){// 计算当前方向的偏移量后的新坐标 xint x = cur.first+dir[i][0];// 计算当前方向的偏移量后的新坐标 yint y = cur.second+dir[i][1];// 检查新坐标是否越界// 如果越界(x 小于 0 或者 x 大于等于网格的行数,// 或者 y 小于 0 或者 y 大于等于网格的列数),则跳过该方向if(x>=grid.size()||x<0||y>=grid[0].size()||y<0) continue;// 检查新坐标是否未被访问过if(!used[x][y]){// 如果未被访问过,将新坐标加入队列q.push({x,y});}}}
}工欲善其事,必先利其器
想要讲图学好,就要将dfs与bfs练习熟练。故我们这里通过 “岛屿问题” 磨炼遍历的基本式。
而接下来几道,都将是经典板子题!
大纲:
1、岛屿数量--基本深度优先搜索(dfs),结合去重进行😉
2、岛屿的面积--岛屿数量的进阶版
3、孤岛的总面积--岛屿的面积的变种
4、沉没孤岛--解法与岛屿的总面积刚好相反(但同属一种思想
5、水流问题--逆推法,我觉得解法蛮帅的😎
6、建造最大岛屿--”就是在海上填一块岛屿“,对每一块岛屿打个编号。用map储存。
7、岛屿的周长--只要记录所有1->0的变化,就能找到所有边
8、字符串接龙--遇事不决,直接画图。去重非常重要。(防超时)
9、有向图的完全联通--简单应用used与graph(邻接表)结合。
1、岛屿数量(dfs)
题目描述:
给定一个由 1(陆地)和 0(水)组成的矩阵,你需要计算岛屿的数量。岛屿由水平方向或垂直方向上相邻的陆地连接而成,并且四周都是水域。你可以假设矩阵外均被水包围。
输入描述:
第一行包含两个整数 N, M,表示矩阵的行数和列数。
后续 N 行,每行包含 M 个数字,数字为 1 或者 0。
输出描述:
输出一个整数,表示岛屿的数量。如果不存在岛屿,则输出 0。
输入示例:
4 5 1 1 0 0 0 1 1 0 0 0 0 0 1 0 0 0 0 0 1 1输出示例:
3
提示信息
根据测试案例中所展示,岛屿数量共有 3 个,所以输出 3。
数据范围:
- 1 <= N, M <= 50
DFS(解法)

#include <iostream>
#include <cstring>
#include <vector>
using namespace std;
// 定义数组的最大长度
const int N = 55;
// 二维数组 arr 用于存储地图信息,1 表示陆地,0 表示海洋
int arr[N][N];
// 二维布尔数组 used 用于标记每个位置是否已经被访问过
bool used[N][N];
// 二维数组 dir 存储四个方向的偏移量,分别是右、左、下、上
int dir[4][2] = {0, 1, 0, -1, 1, 0, -1, 0}; // 深度优先搜索函数,从 (x, y) 位置开始探索相连的陆地
// 可走、可不走
void dfs(int x, int y) {// 遍历四个方向for (int i = 0; i < 4; ++i) {// 计算下一个位置的横坐标int x_cur = x + dir[i][0];// 计算下一个位置的纵坐标int y_cur = y + dir[i][1];// 检查下一个位置是否未被访问过且是陆地if (!used[x_cur][y_cur] && arr[x_cur][y_cur] == 1) { // 标记下一个位置为已访问used[x_cur][y_cur] = true;// 递归调用 dfs 函数,继续从下一个位置探索dfs(x_cur, y_cur);} }
}int main() {int n, m;// 用于记录岛屿的数量int cnt = 0; // 输入地图的行数和列数cin >> n >> m;// 进行基本的储存 // 输入地图信息,将其存储到 arr 数组中for (int i = 1; i <= n; ++i)for (int j = 1; j <= m; ++j)cin >> arr[i][j];// 将 used 数组的所有元素初始化为 false,表示所有位置都未被访问过memset(used, false, sizeof used);// 被用过的,通通标记成2 // 遍历地图的每个位置for (int i = 1; i <= n; ++i)for (int j = 1; j <= m; ++j) {// 若当前位置未被访问过且是陆地if (!used[i][j] && arr[i][j] == 1) {// 标记当前位置为已访问used[i][j] = true;// 岛屿数量加 1cnt++;// 从当前位置开始进行深度优先搜索,标记该岛屿的所有陆地为已访问dfs(i, j); }}// 输出岛屿的数量cout << cnt << endl;return 0;
} BFS(解法)
其实,在岛屿问题中,我们可以看出。
DFS与BFS的主要差别在于,搜索的方式不同,其他的基本遍历方式都是相同的。
而BFS的核心在于用一个容器(queue),来遍历岛屿。
核心函数:
// 广度优先遍历函数
// grid 为二维网格,used 为标记数组,记录每个位置是否已经被访问过
// n 和 m 分别为起始点的行和列
void bfs(const vector<vector<int>> &grid, vector<vector<bool>> &used, int n, int m) {// 创建一个队列,用于存储待访问的节点坐标queue<pair<int, int>> que;// 将起始点的坐标加入队列que.push({n, m});// 标记起始点为已访问used[n][m] = true;// 当队列不为空时,持续进行遍历while (!que.empty()) {// 取出队列头部的节点坐标pair<int, int> cur = que.front();// 将该节点从队列中移除que.pop();// 遍历四个方向for (int i = 0; i < 4; ++i) {// 计算下一个节点的行坐标int nextY = cur.first + dir[i][0];// 计算下一个节点的列坐标int nextX = cur.second + dir[i][1];// 检查下一个节点的坐标是否越界if (nextX < 0 || nextX >= grid[0].size() || nextY < 0 || nextY >= grid.size())// 如果越界,则跳过该方向continue;// 检查下一个节点的值是否为 1 且未被访问过if (grid[nextY][nextX] == 1 && !used[nextY][nextX]) {// 标记下一个节点为已访问used[nextY][nextX] = true;// 将下一个节点的坐标加入队列que.push({nextY, nextX});}}}
}总体函数:
// bfs 广度遍历
#include "iostream"
#include "vector"
#include "queue"
using namespace std;int dir[4][2]={{0,1},{0,-1},{1,0},{-1,0}};
int result = 0;void bfs(const vector<vector<int>> &grid, vector<vector<bool>> &used, int n, int m){ // 广度优先遍历queue<pair<int,int>> que; // 用一队列,来排顺序que.push({n,m}); // 储存while(!que.empty()){pair<int,int> cur = que.front();que.pop();for(int i=0; i<4; ++i){ // 改变四个方向int nextY = cur.first + dir[i][0];int nextX = cur.second + dir[i][1];if(nextX<0 || nextX>=grid[0].size() || nextY<0 || nextY>=grid.size()) continue;if(grid[nextY][nextX]==1 && !used[nextY][nextX]){used[nextY][nextX]=true;que.push({nextY,nextX});}}}
}int main(){int n,m; // n-行,m-列cin>>n>>m;// 准备阶段vector<vector<int>> grid(n,vector<int>(m,0));vector<vector<bool>> used(n,vector<bool>(m, false));for(int i=0; i<n; ++i)for(int j=0; j<m; ++j){cin>>grid[i][j];}// 遍历阶段for(int i=0; i<n; ++i)for(int j=0; j<m; ++j){if(grid[i][j]==1 && !used[i][j]){result++;bfs(grid,used,i,j);}}cout<<result<<endl;return 0;
}2、岛屿的面积(dfs)
题目描述
给定一个由 1(陆地)和 0(水)组成的矩阵,计算岛屿的最大面积。岛屿面积的计算方式为组成岛屿的陆地的总数。岛屿由水平方向或垂直方向上相邻的陆地连接而成,并且四周都是水域。你可以假设矩阵外均被水包围。
输入描述
第一行包含两个整数 N, M,表示矩阵的行数和列数。后续 N 行,每行包含 M 个数字,数字为 1 或者 0,表示岛屿的单元格。
输出描述
输出一个整数,表示岛屿的最大面积。如果不存在岛屿,则输出 0。
输入示例
4 5 1 1 0 0 0 1 1 0 0 0 0 0 1 0 0 0 0 0 1 1输出示例
4
提示信息
样例输入中,岛屿的最大面积为 4。
数据范围:
- 1 <= M, N <= 50
做过,岛屿数量之后,你会发现本题换汤不换药。
就是在dfs遍历岛屿的过程中。
一共设置了两个变量cur_area、max_area;
cur_area表示当前陆地的最大面积、max_area表示每遍历到一块新的陆地,就根据max_area刷新一次。
如下:
#include <iostream>
#include <cstring>
#include <vector>
using namespace std;
const int N = 55;
int arr[N][N];
bool used[N][N];
int dir[4][2]={0,1,0,-1,1,0,-1,0};
int cur_area; // 用于表示面积
int max_area;
// 可走、可不走,天呐
void dfs(int x,int y){for(int i=0; i<4; ++i){int x_cur = x + dir[i][0];int y_cur = y + dir[i][1];if(!used[x_cur][y_cur]&&arr[x_cur][y_cur]==1){ used[x_cur][y_cur]=true;cur_area++;dfs(x_cur,y_cur);} }
}
int main(){int n,m;cin>>n>>m;// 进行基本的储存 for(int i=1; i<=n; ++i)for(int j=1; j<=m; ++j)cin>>arr[i][j];memset(used,false,sizeof used);// 被用过的,通通标记成2 for(int i=1; i<=n; ++i)for(int j=1; j<=m; ++j){if(!used[i][j]&&arr[i][j]==1){cur_area=1;used[i][j]=true;dfs(i,j); max_area=max_area<cur_area?cur_area:max_area; }}cout<<max_area<<endl;return 0;
} 3、孤岛的总面积(dfs)
题目描述
给定一个由 1(陆地)和 0(水)组成的矩阵,岛屿指的是由水平或垂直方向上相邻的陆地单元格组成的区域,且完全被水域单元格包围。孤岛是那些位于矩阵内部、所有单元格都不接触边缘的岛屿。
现在你需要计算所有孤岛的总面积,岛屿面积的计算方式为组成岛屿的陆地的总数。
输入描述
第一行包含两个整数 N, M,表示矩阵的行数和列数。之后 N 行,每行包含 M 个数字,数字为 1 或者 0。
输出描述
输出一个整数,表示所有孤岛的总面积,如果不存在孤岛,则输出 0。
输入示例
4 5 1 1 0 0 0 1 1 0 0 0 0 0 1 0 0 0 0 0 1 1输出示例:
1
提示信息:
在矩阵中心部分的岛屿,因为没有任何一个单元格接触到矩阵边缘,所以该岛屿属于孤岛,总面积为 1。
数据范围:
1 <= M, N <= 50。
其实本题,思路很清奇,(所有单元格都不接触边缘的岛屿)
因为这句话的存在,只要将靠近上、下、左、右四条边的海岛OK掉就行。
然后,对接下来的部分,解决掉。
#include <iostream>
#include <cstring>
using namespace std;
const int N = 55;
int arr[N][N];
bool used[N][N];
int n,m;
int dir[4][2]={1,0,-1,0,0,1,0,-1};void dfs(int x, int y){for(int i=0; i<4; ++i){int cur_x = x+dir[i][0];int cur_y = y+dir[i][1];if(cur_x<0||cur_x>=m||cur_y<0||cur_y>=n) continue;if(used[cur_x][cur_y]||arr[cur_x][cur_y]==0) continue;used[cur_x][cur_y] = true;dfs(cur_x,cur_y);}
}int main(){cin>>m>>n;memset(used, false, sizeof used);for(int i=0; i<m; ++i)for(int j=0; j<n; ++j) cin>>arr[i][j];// 清空边界// 左边for(int i=0; i<m; ++i){if(used[i][0]||arr[i][0]==0) continue;used[i][0] = true;dfs(i,0);}// 右for(int i=0; i<m; ++i){if(used[i][n-1]||arr[i][n-1]==0) continue;used[i][n-1] = true;dfs(i,n-1);}// 上for(int i=0; i<n; ++i){if(used[0][i]||arr[0][i]==0) continue;used[0][i] = true;dfs(0,i);}// 下for(int i=0; i<n; ++i){if(used[m-1][i]||arr[m-1][i]==0) continue;used[m-1][i] = true;dfs(m-1,i);}int cnt = 0;for(int i=0; i<m; ++i) {for (int j = 0; j < n; ++j) { // 我的荣幸if (!used[i][j] && arr[i][j] == 1) cnt++;}}cout<<cnt<<endl;return 0;
}4、沉没孤岛(dfs)
题目描述:
给定一个由 1(陆地)和 0(水)组成的矩阵,岛屿指的是由水平或垂直方向上相邻的陆地单元格组成的区域,且完全被水域单元格包围。孤岛是那些位于矩阵内部、所有单元格都不接触边缘的岛屿。
现在你需要将所有孤岛“沉没”,即将孤岛中的所有陆地单元格(1)转变为水域单元格(0)。
输入描述:
第一行包含两个整数 N, M,表示矩阵的行数和列数。
之后 N 行,每行包含 M 个数字,数字为 1 或者 0,表示岛屿的单元格。
输出描述
输出将孤岛“沉没”之后的岛屿矩阵。
输入示例:
4 5 1 1 0 0 0 1 1 0 0 0 0 0 1 0 0 0 0 0 1 1输出示例:
1 1 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 1 1提示信息:
将孤岛沉没:
数据范围:
1 <= M, N <= 50
其实沉默孤岛,就是在岛屿总面积的基础上,将原本加在cnt的岛屿变为0。然后没啦
#include "iostream"
#include "vector"
using namespace std;int dir[4][2] = {{0,1},{0,-1},{1,0},{-1,0}};
void dfs(const vector<vector<int>> &grid, vector<vector<bool>> &used, int x, int y) {used[x][y]=true;for (int i = 0; i < 4; ++i) {int nextX = x + dir[i][0];int nextY = y + dir[i][1];if (nextX < 0 || nextX >= grid.size() || nextY < 0 || nextY >= grid[0].size()) continue;if (grid[nextX][nextY]==1 && !used[nextX][nextY]) {used[nextX][nextY] = true;dfs(grid, used, nextX, nextY);}}
}int main(){int n,m;cin >> n >> m;// 基础储存vector<vector<int>> grid(n,vector<int>(m,0));for(int i=0; i<n; i++){for(int j=0; j<m; j++){cin>>grid[i][j];}}vector<vector<bool>> used(n,vector<bool>(m,false));// 跳转for(int i=0; i<n; ++i){ // n为行if(grid[i][0] && !used[i][0]) dfs(grid,used,i,0);if(grid[i][m-1] && !used[i][m-1]) dfs(grid,used,i,m-1);}for(int i=0; i<m; ++i){// m为列if(grid[0][i] && !used[0][i]) dfs(grid,used,0,i);if(grid[n-1][i] && !used[n-1][i]) dfs(grid,used,n-1,i);}for(int i=0; i<n; ++i){for(int j=0; j<m; ++j){if(grid[i][j] && used[i][j]) cout<<1<<" ";else cout<<0<<" ";}cout<<endl;}return 0;}
5、水流问题
题目描述:
现有一个 N × M 的矩阵,每个单元格包含一个数值,这个数值代表该位置的相对高度。矩阵的左边界和上边界被认为是第一组边界,而矩阵的右边界和下边界被视为第二组边界。
矩阵模拟了一个地形,当雨水落在上面时,水会根据地形的倾斜向低处流动,但只能从较高或等高的地点流向较低或等高并且相邻(上下左右方向)的地点。我们的目标是确定那些单元格,从这些单元格出发的水可以达到第一组边界和第二组边界。
输入描述:
第一行包含两个整数 N 和 M,分别表示矩阵的行数和列数。
后续 N 行,每行包含 M 个整数,表示矩阵中的每个单元格的高度。
输出描述:
输出共有多行,每行输出两个整数,用一个空格隔开,表示可达第一组边界和第二组边界的单元格的坐标,输出顺序任意。
输入示例:
5 5 1 3 1 2 4 1 2 1 3 2 2 4 7 2 1 4 5 6 1 1 1 4 1 2 1输出示例:
0 4 1 3 2 2 3 0 3 1 3 2 4 0 4 1提示信息:
图中的蓝色方块上的雨水既能流向第一组边界,也能流向第二组边界。所以最终答案为所有蓝色方块的坐标。
数据范围:
1 <= M, N <= 50
本题中,有一个非常重要的细节,一定要建立记忆话搜索,否则会造成无限递归。
#include <iostream>
#include <cstring>
using namespace std;
// 在本题中,一定要实现记忆话搜索,否则会导致重复遍历一点,从而导致无限递归。
const int N = 105;
int n,m;
int arr[N][N];
int arr_one[N][N];
int arr_two[N][N];
int dir[4][2]={1,0,-1,0,0,1,0,-1};void dfs(int cur_arr[N][N], int flag,int x,int y){ // 要填充的数组、要填充成谁for(int i=0; i<4; ++i){int cur_x = x+dir[i][0];int cur_y = y+dir[i][1];if(cur_x<0||cur_x>=n||cur_y<0||cur_y>=m) continue;if(cur_arr[cur_x][cur_y]!=0) continue; // 这一步记忆化搜索,非常重要 if(arr[x][y]<=arr[cur_x][cur_y]){cur_arr[cur_x][cur_y]=flag; dfs(cur_arr,flag,cur_x,cur_y);}}
}int main(){cin>>n>>m;memset(arr_one,0,sizeof arr_one);memset(arr_two,0,sizeof arr_two);for(int i=0; i<n; ++i)for(int j=0; j<m; ++j) cin>>arr[i][j];for(int i=0; i<n; ++i){// 左arr_one[i][0]=1;dfs(arr_one,1,i,0);// 右arr_two[i][m-1]=2;dfs(arr_two,2,i,m-1);}for(int i=0; i<m; ++i){// 上arr_one[0][i]=1;dfs(arr_one,1,0,i);// 下arr_two[n-1][i]=2;dfs(arr_two,2,n-1,i);}for(int i=0; i<n; ++i)for(int j=0; j<m; ++j)if(arr_one[i][j]==1&&arr_two[i][j]==2) cout<<i<<" "<<j<<endl;return 0;
}6、建造最大岛屿
题目描述:
给定一个由 1(陆地)和 0(水)组成的矩阵,你最多可以将矩阵中的一格水变为一块陆地,在执行了此操作之后,矩阵中最大的岛屿面积是多少。
岛屿面积的计算方式为组成岛屿的陆地的总数。岛屿是被水包围,并且通过水平方向或垂直方向上相邻的陆地连接而成的。你可以假设矩阵外均被水包围。
输入描述:
第一行包含两个整数 N, M,表示矩阵的行数和列数。之后 N 行,每行包含 M 个数字,数字为 1 或者 0,表示岛屿的单元格。
输出描述:
输出一个整数,表示最大的岛屿面积。
输入示例:
4 5 1 1 0 0 0 1 1 0 0 0 0 0 1 0 0 0 0 0 1 1输出示例
6
提示信息
对于上面的案例,有两个位置可将 0 变成 1,使得岛屿的面积最大,即 6。
数据范围:
1 <= M, N <= 50。
如果硬写本题的话,时间复杂度n*n*n *n。
岛屿问题,最大的特点就是染色,故,我们可以对每一块岛屿染色,或者是打上特殊标记。
通过unordered_map标记,描绘其对应的值。对应的值。
#include <iostream>
#include <unordered_map>
#include <unordered_set>
using namespace std;
const int N = 55;
int n,m;
int arr[N][N]; // 集合
int dir[4][2]={1,0,-1,0,0,1,0,-1};
void dfs(int x, int y, int mark, int& cnt){if(x<0||x>=n||y<0||y>=m) return;if(arr[x][y]!=1) return; cnt++;arr[x][y]=mark;for(int i=0; i<4; ++i){dfs(x+dir[i][0],y+dir[i][1],mark,cnt);}
}int main(){ cin>>n>>m; for(int i=0; i<n; ++i)for(int j=0; j<m; ++j) cin>>arr[i][j];int mark = 2; // 用于标记unordered_map<int,int> umap;for(int i=0; i<n; ++i){for(int j=0; j<m; ++j){if(arr[i][j]!=1) continue;int cnt = 0; // 用于计数dfs(i,j,mark,cnt); umap[mark++]=cnt;}}unordered_set<int> uset;int max_all=0;for(int i=0; i<n; ++i){for(int j=0; j<m; ++j){if(arr[i][j]!=0) continue;uset.clear();int all = 1;for(int k=0; k<4; ++k){int x = i+dir[k][0];int y = j+dir[k][1];if(x<0||x>=n||y<0||y>=m) continue;if(uset.find(arr[x][y])!=uset.end()) continue;all += umap[arr[x][y]];uset.insert(arr[x][y]);}max_all = max(max_all,all); }}if(max_all==0) cout<<umap[arr[0][0]]<<endl;else cout<<max_all<<endl;return 0;
}7、岛屿的周长
题目描述
给定一个由 1(陆地)和 0(水)组成的矩阵,岛屿是被水包围,并且通过水平方向或垂直方向上相邻的陆地连接而成的。
你可以假设矩阵外均被水包围。在矩阵中拥有一个或者多个岛屿,假设组成岛屿的陆地边长都为 1,请计算岛屿的周长。岛屿内部没有水域。
输入描述
第一行包含两个整数 N, M,表示矩阵的行数和列数。之后 N 行,每行包含 M 个数字,数字为 1 或者 0,表示岛屿的单元格。
输出描述
输出一个整数,表示岛屿的周长。
输入示例
5 5 0 0 0 0 0 0 1 0 1 0 0 1 1 1 0 0 1 1 1 0 0 0 0 0 0输出示例
14
提示信息
岛屿的周长为 14。
数据范围:
1 <= M, N <= 50。
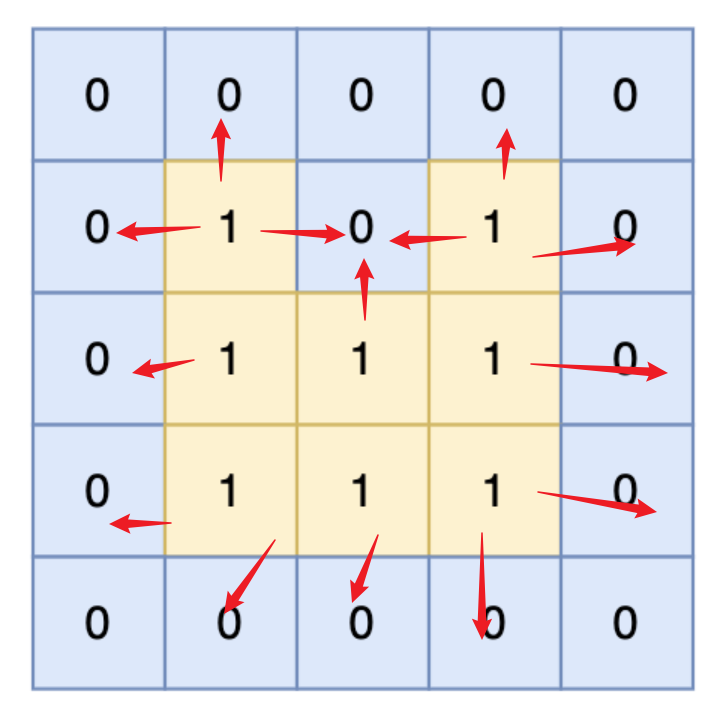
从上方给出的图片,我们可以看出。只有“1”与“0”的交界处,是可以计入周长的边。
if(x<0||x>=n||y<0||y>=m){ // 越界 cnt++;return;}if(arr[x][y]==0){cnt++;return;}所以可以根据,返回条件,进行cnt++,然后return;
#include <iostream>
using namespace std;
const int N = 55;
int n,m;
int arr[N][N];
bool used[N][N];
int dir[4][2]={1,0,-1,0,0,1,0,-1}; int cnt=0;
void dfs(int x, int y){if(x<0||x>=n||y<0||y>=m){ // 越界 cnt++;return;}if(used[x][y]) return; // 被遍历过if(arr[x][y]==0){cnt++;return;}used[x][y]=true;for(int i=0; i<4; ++i){int cur_x = x + dir[i][0];int cur_y = y + dir[i][1];dfs(cur_x, cur_y); }
}int main(){cin>>n>>m;for(int i=0; i<n; ++i)for(int j=0; j<m; ++j) cin>>arr[i][j];for(int i=0; i<n; ++i)for(int j=0; j<m; ++j){if(arr[i][j]==1){dfs(i,j);cout<<cnt<<endl;return 0; }}return 0;
}8、字符串接龙
题目描述
字典 strList 中从字符串 beginStr 和 endStr 的转换序列是一个按下述规格形成的序列:
序列中第一个字符串是 beginStr。
序列中最后一个字符串是 endStr。
每次转换只能改变一个位置的字符(例如 ftr 可以转化 fty ,但 ftr 不能转化 frx)。
转换过程中的中间字符串必须是字典 strList 中的字符串。
beginStr 和 endStr 不在 字典 strList 中
字符串中只有小写的26个字母
给你两个字符串 beginStr 和 endStr 和一个字典 strList,找到从 beginStr 到 endStr 的最短转换序列中的字符串数目。如果不存在这样的转换序列,返回 0。
输入描述
第一行包含一个整数 N,表示字典 strList 中的字符串数量。 第二行包含两个字符串,用空格隔开,分别代表 beginStr 和 endStr。 后续 N 行,每行一个字符串,代表 strList 中的字符串。
输出描述
输出一个整数,代表从 beginStr 转换到 endStr 需要的最短转换序列中的字符串数量。如果不存在这样的转换序列,则输出 0。
输入示例
6 abc def efc dbc ebc dec dfc yhn输出示例
4
提示信息
从 startStr 到 endStr,在 strList 中最短的路径为 abc -> dbc -> dec -> def,所以输出结果为 4
数据范围:
2 <= N <= 500
去重是非常有必要的,如果不去重,在输入结果大时,会导致结果超时。
而本题,画过图之后,思路会清晰很多:
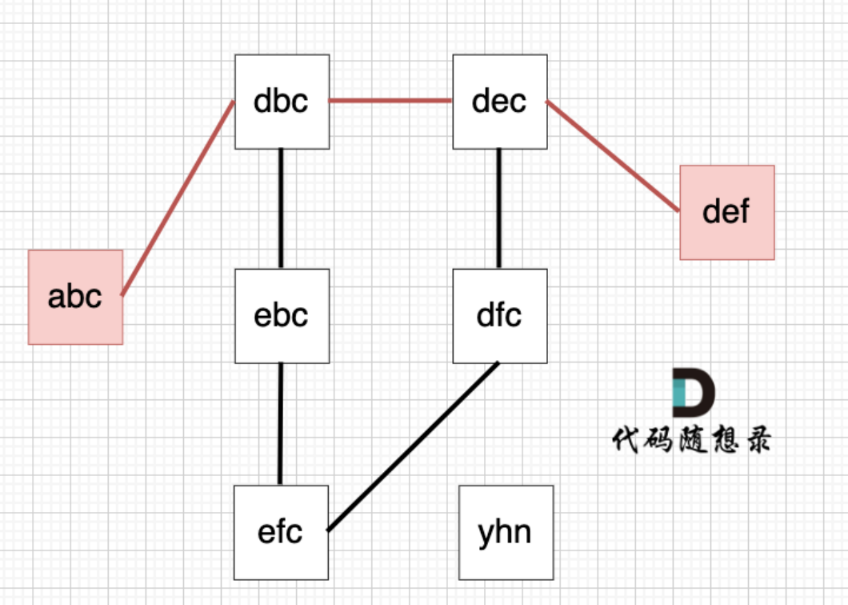
遇题不会,直接上纸。
// 用get_cnt(args) 用来判断,两个字符串相差几个字母
// 用广搜 搜索方便找到最短路径。
// 用umap去重,并存储搜索的长度。
#include <iostream>
#include <unordered_map>
#include <unordered_set>
#include <queue>
using namespace std;
// 如果,非要讲解这道题目的话,无非就两点,把图画出来,直接秒变最短路径
// 去重,是相当重要的一点。
// 基本标记
unordered_map<string,int> umap;
unordered_set<string> uset;bool get_cnt(string str1, string str2){ // true:刚好合格 if(str1.size()!=str2.size()) return false;int cnt = 0;for(int i=0; i<str1.size(); ++i){if(str1[i]!=str2[i]) cnt++;} if(cnt!=1) return false;return true;
} int main(){int n;string begin_str,end_str;cin>>n>>begin_str>>end_str;for(int i=0; i<n; ++i){string str;cin>>str;uset.insert(str);} queue<pair<string,int>> q;q.emplace(begin_str,1);while(!q.empty()){auto node = q.front();q.pop();string str = node.first;int cnt = node.second; if(get_cnt(str,end_str)){cout<<cnt+1<<endl;return 0;}for(auto str_cur : uset){if(umap.find(str_cur)!=umap.end()) continue;if(!get_cnt(str,str_cur)) continue;umap.emplace(str_cur,cnt+1);q.emplace(str_cur,cnt+1); }}cout<<0<<endl;return 0;
}9、有向图的完全联通
【题目描述】
给定一个有向图,包含 N 个节点,节点编号分别为 1,2,...,N。现从 1 号节点开始,如果可以从 1 号节点的边可以到达任何节点,则输出 1,否则输出 -1。
【输入描述】
第一行包含两个正整数,表示节点数量 N 和边的数量 K。 后续 K 行,每行两个正整数 s 和 t,表示从 s 节点有一条边单向连接到 t 节点。
【输出描述】
如果可以从 1 号节点的边可以到达任何节点,则输出 1,否则输出 -1。
【输入示例】
4 4 1 2 2 1 1 3 2 4【输出示例】
1
【提示信息】
从 1 号节点可以到达任意节点,输出 1。
数据范围:
- 1 <= N <= 100;
- 1 <= K <= 2000。
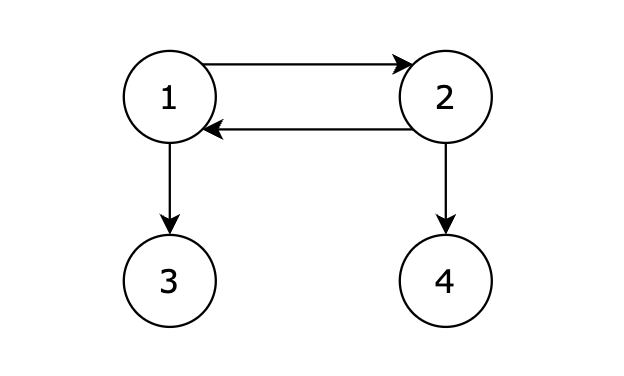
// 用邻接表graph存储所有节点。
// 用used表示,遍历过该节点,顺便去重
// 最后,根据used内,是否有节点未被遍历过,来判断结果
#include <iostream>
#include <cstring>
#include <list>
#include <vector>
using namespace std;
const int N = 105;
int used[N];
vector<list<int>> graph(N); int n,m;
void dfs(int i){if(used[i]!=0) return;used[i]=1;for(int node : graph[i]) dfs(node);
}
int main(){cin>>n>>m;for(int i=0; i<m; ++i){int s,t;cin>>s>>t;graph[s].push_back(t); }dfs(1);for(int i=1; i<=n; ++i) if(used[i]==0){cout<<-1<<endl;return 0;} cout<<1<<endl;return 0;
}借鉴博客:
1、深度优先理论