【datawhaleAI春训营第一期笔记】AI+航空安全
记录了一些数据竞赛相关的知识,赛题的代码相关笔记可以从目录寻找
目录
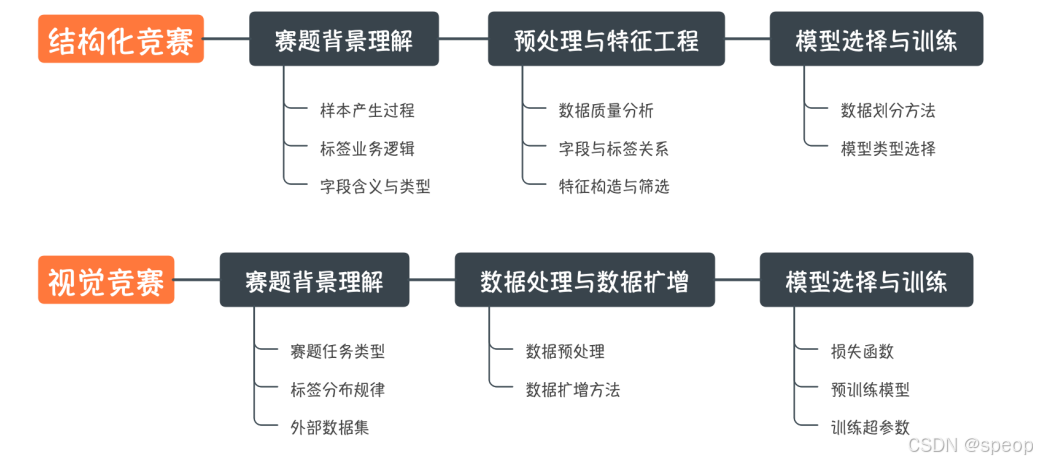
- 数据竞赛知识
- 前置知识
- TPOP
- 竞赛分类:
- 机器学习基础
- 线性模型
- 树模型
- KNN模型
- 神经网络
- 深度学习
- 全连接网络
- 深度学习正则化
- 深度学习的优化
- 卷积神经网络
- 竞赛基础知识
- 数据清洗
- 特征工程
- 模型训练与验证
- **模型融合**
- 赛题
- 任务和主题
- 比赛数据
- 第一课baseline 代码 基于历史均值的简单方案
- 第二课
- 基于树模型的气象预测进阶路线(结构化回归问题)
- 算法方案
- 关键概念
- baseline简介
- 基于深度学习的进阶路线( 时空序列预测问题)
- 一、问题重新建模
- 二、技术路线设计
- 关键实现步骤
数据竞赛知识
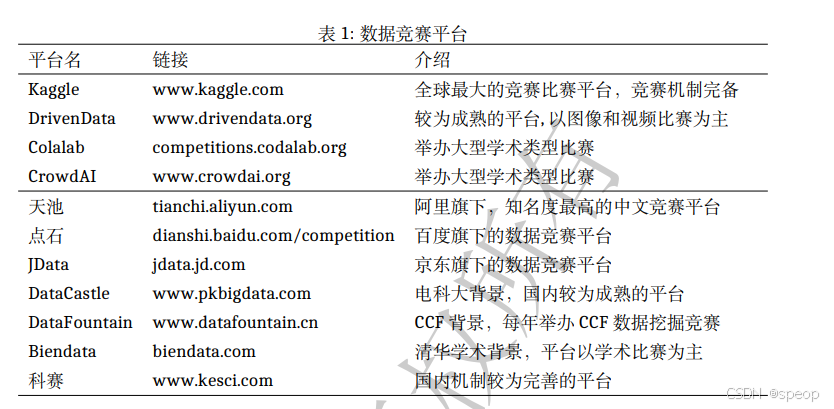
数据竞赛平台
数据科学:
- 数据科学常用的技能还包括数据分析、数据可视化和数据存储
- 本身是一种编程活动
- 数据科学不仅要程序能够正确运行,还要有” 额外” 的目标。
- 数据挖掘是以数据为研究对象的任务,任务的核心点是数据。因此在实践的过程中最为重要的就是对数据的理解,并结合领域知识来对数据二次加工。
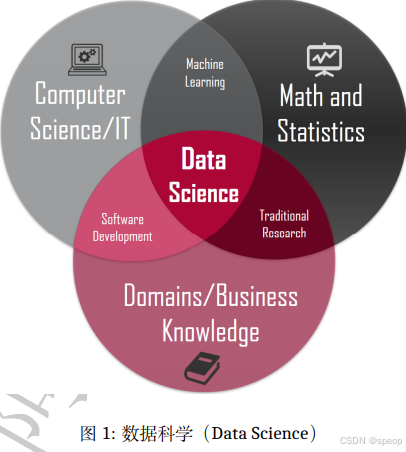
数据挖掘目标是从海量数据中挖掘出有用的信息,核心是找到变量之间的关系。机器学习目标是设计算法模型让其能够自动从经验中学习新知识。数据挖掘与机器学习相辅相成,数据挖掘很多任务都是用机器学习的方法完成的。
前置知识
- 代码基础
基础技能包括:Pandas、数据分析技能、树模型使用与调参;
进阶技能包括:模型集成、特征工程 - 关键代码部分
步骤1:对数据集进行数据分析
步骤2:对数据集字段进行编码
步骤3:使用LightGBM进行五折交叉验证 - 竞赛学习路径
- 入门阶段(一周):掌握数据挖掘流程、Pandas、Sklearn
- 进阶阶段(四周):掌握特征工程、特征筛选、掌握XGBoot、LightGBM
- 深入阶段(半年):
- 深度学习基础:Pytorch、Keras、模型搭建、训练流程、深度学习调参
- NLP领域知识:TFIDF、Word2Vec、TextCNN、Bert
- CV领域知识:CNN、预训练模型、分类模型、检测模型、分割模型
K折交叉验证方法进行离线评估,大体流程如下:
1、K折交叉验证会把样本数据随机的分成K份;
2、每次随机的选择K-1份作为训练集,剩下的1份做验证集;
3、当这一轮完成后,重新随机选择K-1份来训练数据;
4、最后将K折预测结果取平均作为最终提交结果。
- 数学知识
微积分
• 函数极限
• 上确界与下确界
• 导数与偏导数
• 单调性与极值
• 函数的凹凸性
• 泰勒级数
2 数据科学必知必会 14
• 牛顿-莱布尼兹公式
• Lipschitz 连续性
• Hessian 矩阵 - 线性代数
• 线性空间与线性映射
• 行列式求解
• 特征值与特征向量
• 最小二乘法 - 矩阵分析
• 矩阵运算
• 广义特征值
• 奇异值分解
• 矩阵求导
• 协方差矩阵 - 概率论与数理统计
• 概率空间与事件
• 随机变量与概率公式
• 概率独立性
• 条件概率、联合概率与边缘概率
• 贝叶斯公式
• 大数定理与中心极限定理
• 参数估计 - 信息论
- 最优化方法
• 凸优化介绍
• 凸函数与凸集合
• 拉格朗日乘数法与 KKT 条件
• 常见的凸优化问题 - 图论
• 图概念
• 常见的图
• 路径搜索问题
• 最大流问题
• 拉普拉斯矩阵
TPOP
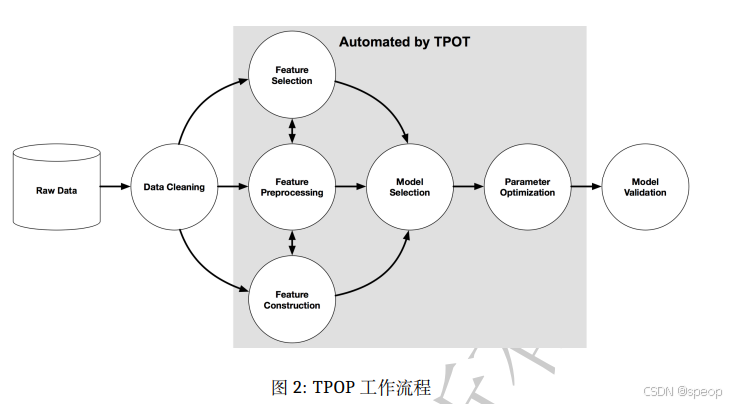
TPOT 是 Tree - based Pipeline Optimization Tool 的缩写 ,即基于树的管道优化工具。它是一个开源的自动化机器学习工具:
功能:能自动完成从数据预处理、特征工程(包括特征选择、特征预处理、特征构造)、模型选择到超参数优化等一系列机器学习流程,通过优化组合不同的算法和参数,构建最优的机器学习模型。
原理:采用遗传算法等技术,对各种可能的机器学习管道(由数据处理步骤和模型组成的序列)进行搜索和优化,就像在一个庞大的算法组合空间中寻找最佳的 “配方”,以最小化预测误差。
应用场景:适用于数据挖掘、数据分析、预测建模等多种场景,能帮助数据科学家、分析师等快速找到相对较好的模型解决方案,节省大量手动调优时间 。 图中展示了 TPOT 自动化处理的工作流程,从原始数据开始,经过数据清洗,再到特征工程相关环节,接着进行模型选择、参数优化,最后到模型验证。
竞赛分类:
-
分类赛题
-
回归赛题
-
时序赛题
-
结构化数据
-
非结构化数据
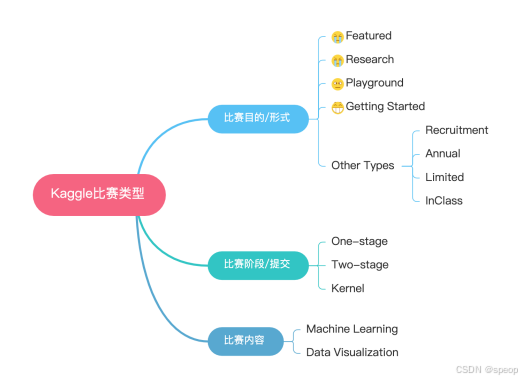
翻译一下
Featured:特色赛
Research:研究赛
Playground:新手练习赛
Getting Started:入门赛
Recruitment:招聘赛
Annual:年度赛
Limited:限时赛
InClass:课堂赛
One - stage:单阶段赛
Two - stage:双阶段赛
Kernel:内核赛
Machine Learning:机器学习赛
Data Visualization:数据可视化赛
(翻译不一定准确
Leaderboard 页面:是比赛得分的排行榜
Rong360-用户贷款风险预测
https://www.pkbigdata.com/common/cmpt/用户贷款风险预测 _ 竞赛信息.html
赛题:根据用户的基本属性、银行流水记录、用户浏览行为、信用卡账单记录、放款时间, 以及这
些顾客是否发生逾期行为的记录。
目标:风控背景的二分类问题,预测用户是否违约;
思路:根据不同的表,提取用户不同的特征;
难点:用户 ID 存在 leak,且放款时间存在特殊分布;需要有较好的交叉特征方法;
Planet: Understanding the Amazon from Space
https://www.kaggle.com/c/planet-understanding-the-amazon-from-space
赛题: 遥感图像, 判断地表的天气和地表覆盖物;
目标: 对天气和地表进行多分类;
思路: 使用预训练模型 (ResNet/Desnet/Inception…), 微调 CNN 模型;
难点: 类别分布差异大, 且训练需要 4*1080ti 的计算能力;
误差:
分类任务:分类错误率
- 训练集:训练误差
- 测试集:泛化误差(【偏差 (Bias)】,【方差 (Variance)】 和噪声 (Noise)[不可约减的误差])
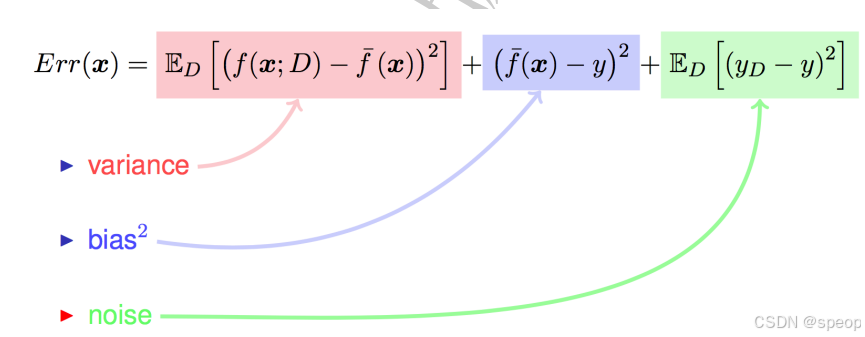
- 偏差:度量了算法预测结果与真实结果的偏离,刻画了算法的拟合能力
- 方差:度量了同样大小的训练集的变动所导致的学习性能的变化,即数据扰动所造成的影响;
- 噪声:表达了在当前任务上任何算法能达到的泛化误差的下界,即;刻画了学习问题本身的难度;
模型的泛化性能是由模型的学习能力、数据量以及数据噪音所决定的。
偏差与方差是有冲突的,但模型在欠拟合状态时,模型对训练集的拟合程度不够,数据的扰动不足以影响模型;模型在过拟合情况下,模型拟合能力很强,模型也会学习到数据的扰动。
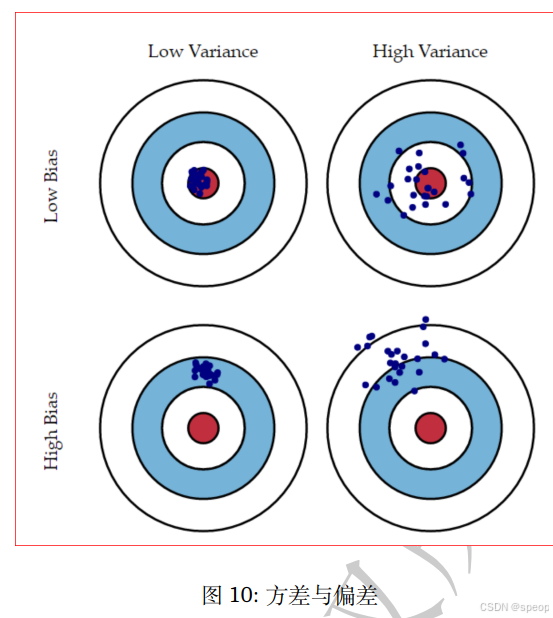
机器学习基础
过拟合:模型在训练集误差较低,但在测试集上误差较高;泛化能力差,模型复杂度高,学习到了虚拟蓝数据的方方面面。解决方法的核心是降低模型复杂度(剪枝,特征选择【PCA,L1正则化,相关性选择】,减少参数数量,dropout【训练时随机关闭一部分神经元】)或增强数据多样性(交叉验证,早停,集成学习【降低方差或偏差】)。
欠拟合:模型在训练集误差较高,还没有完全拟合训练集;需要增加模型的复杂度或者增加模型的训练轮数
机器学习任务可分为:分类、回归和排序三种。
其中每种任务的侧重点不同,因此可用不同的评
价函数进行度量。
有监督任务,误差通过样本标签与模型预测的标签
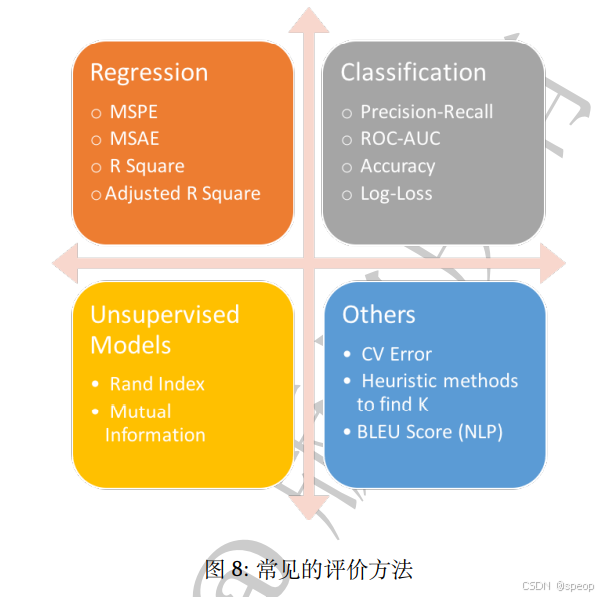
Regression 回归
MSPE 均方预测误差
MSAE 平均绝对误差
R Square R 方
Adjusted R Square 调整后的 R 方
Classification 分类
Precision-Recall 精确率 - 召回率
ROC-AUC 受试者工作特征曲线下面积
Accuracy 准确率
Log-Loss 对数损失
Unsupervised Models 无监督模型
Rand Index 兰德指数
Mutual Information 互信息
others
CV Error 交叉验证误差
Heuristic methods to find K 寻找 K 值的启发式方法
BLEU Score (NLP) 双语评估替补得分(自然语言处理 )






线性模型
线性模型:
(线性回归:利用线性模型完成回归任务,逻辑回归:利用线性模型完成分类任务)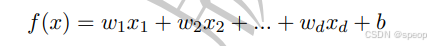
首先线性模型的解释性强,模型的参数可以表示特征的重要性;其次线性模型转换为非线性模型,只需要引入高维空间即可;线性模型非常适合分布式训练。
树模型
是以树结构来进行决策的
每个叶子阶段对应决策结果,非叶子节点对应一个决策情况。
决策树是根据最优属性进行划分的,一般可以用【信息熵】、【信息增益】和【基尼指数】等指标进行衡量。
- 决策树能够处理非线性关系,并且可以自动捕获特征之间的交互作用。
- 它可以生成可解释的规则,有助于理解模型如何做出决策。
-
- 决策树能够处理不同类型的特征,包括分类和数值型。
由于决策树每次只使用单个属性进行决策,因此决策树对量纲并不敏感。同时树模型对缺失值也比较友好,可以将缺失值视为一个特殊的取值。
决策树的训练过程中可以加入节点随机选择、Boosting(将弱学习器提升为强学习器的集成学习算法 。核心思想是顺序训练一系列弱学习器,每个学习器都尝试修正前一个的错误。)和 Bagging (并行式集成学习代表方法)等技术,进一步增加树模型的拟合能力
- 决策树能够处理不同类型的特征,包括分类和数值型。
弱学习器
定义:泛化性能略优于随机猜测的学习器。在二分类问题中,其准确率略高于 50% 。比如在判断邮件是否为垃圾邮件的任务中,弱学习器能比随机判断稍微准确一些。
特点:结构简单,容易构建,计算开销小。但单独使用时,预测能力有限,难以处理复杂任务。像简单的决策树桩(只有一层的决策树 ),只能捕捉到数据中较简单的模式 。
强学习器
定义:具有高预测性能的模型,错误率远低于随机猜测。能很好地拟合数据,对未知数据有较准确的预测能力。
特点:通常结构相对复杂,能捕捉数据中深层次、复杂的模式和关系。比如深度神经网络,通过多层神经元结构,可以学习到图像、语音等复杂数据的特征表示,在图像识别、语音识别任务中表现出色 。
基学习器
定义:集成学习中的基本单元,即构成集成模型的单个模型。
特点:具有同质性(相同类型的模型 )或异质性(不同类型的模型 )。可以是决策树、感知机、神经网络等任何类型的模型 。
作用:作为集成模型的组成部分,其性能和特点会影响整个集成模型的表现。在不同集成学习算法中扮演不同角色,如在 Bagging 中,基学习器并行训练,通过组合降低方差;在 Boosting 中,基学习器串行训练,逐步减少偏差 。 基学习器可以是弱学习器,也可以是强学习器 。
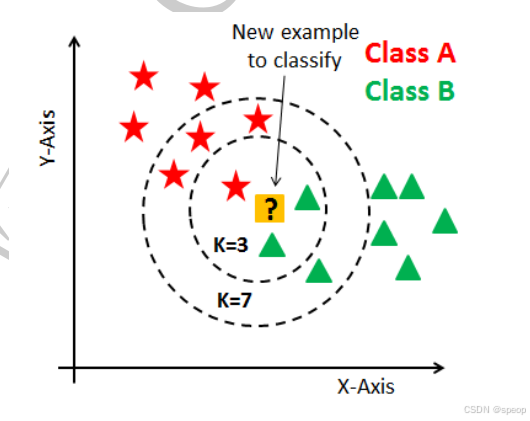
KNN模型
算法思路非常简单。
给定测试样本,样本的标签取决于最近 K 个邻居样本的取值情况。对于分类任务,KNN 选择最近的 K个邻居完成投票或者结果平均;对于回归任务,KNN 选择最近的 K 个邻居完成样本的结果平均
神经网络
神经网络感知机模型。神经网络中最基础的元素是神经元,神经元之间相互连接,可以可以相互发送信号。
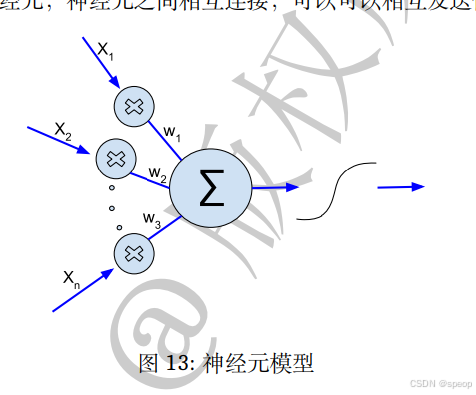
神经元被激活后,它就会被激活,向后序的神经元发送信号。在神经元模型中神经元会受到前序神经元的信息输出,并将信号经激活函数处理后输出,典型的神经元模型是 Sigmoid 函数。将神经元按照一定规律组合后,就成为神经网络。神经网络通常使用误差反向传播进行优化,并按照批量样本多次进行梯度反传
梯度的作用:
梯度是一个向量,它由损失函数对神经网络中各个参数(如权重W和偏置b )的偏导数组成
梯度反映了每个参数对损失函数的影响程度和方向。若梯度的某个分量为正,意味着增加对应参数值会使损失函数增大;若为负,则增加该参数值损失函数会减小 。例如在训练图像识别神经网络时,某个权重的梯度较大且为正,说明该权重的增加会让模型预测误差增大,就需要对其进行调整。
误差反向传播借助梯度计算:误差反向传播是利用链式法则高效计算梯度的过程。从输出层开始,根据输出误差,通过链式法则逐层计算每个神经元参数的梯度。因为神经网络层与层之间存在依赖关系,链式法则能将输出层的误差反向传递到前面各层,算出各层参数梯度 。例如在一个三层神经网络中,先算出输出层误差对输出层参数的梯度,再根据链式法则传递到隐藏层,算出隐藏层参数梯度。
实现模型优化:计算出各层梯度后,就能按梯度下降策略更新参数,调整神经网络结构,使模型在训练过程中不断优化,提高对输入数据的处理和预测能力 。比如在训练语言模型时,通过误差反向传播和梯度更新,让模型能更准确地预测下一个单词
深度学习
深度学习本质是多层的神经网络,具有较强的特征学习能力。深度学习模型学习的学习能力是分布式表示的,并利用了分层抽象的思路,高层次的概念从低层次的概念学习得到。
神经网络的隐含层越多、模型参数越多,模型拟合能力更强,同时训练的难度也会增加。减少模型参数的方法有两种:逐层训练和权重共享。
深度学习作为机器学习中的一个分支,基本定义(偏差与方差、误差与过拟合等)与传统的机器学习类似,但深度学习还是有很多独有的特点。
深度学习并不需要很多的人工特征工程,利用其
强大的建模能力来代替,整个训练的过程是端到端的过程(End-to-End);其次深度学习模型参数居多,
训练过程中需要大量的训练样本。
深度学习利用网络强大的特征表征能力,能够提取多层的高层特征,并将特征空间与标签空间直接进行映射。
深度学习多层网络可以将数据进行多层映射,进行逐层学习。在卷积神经网络网络中底层网络可以学习到图像的底层信息,如边缘和角点,高层网络可以学习到图像的直接和复杂形状。
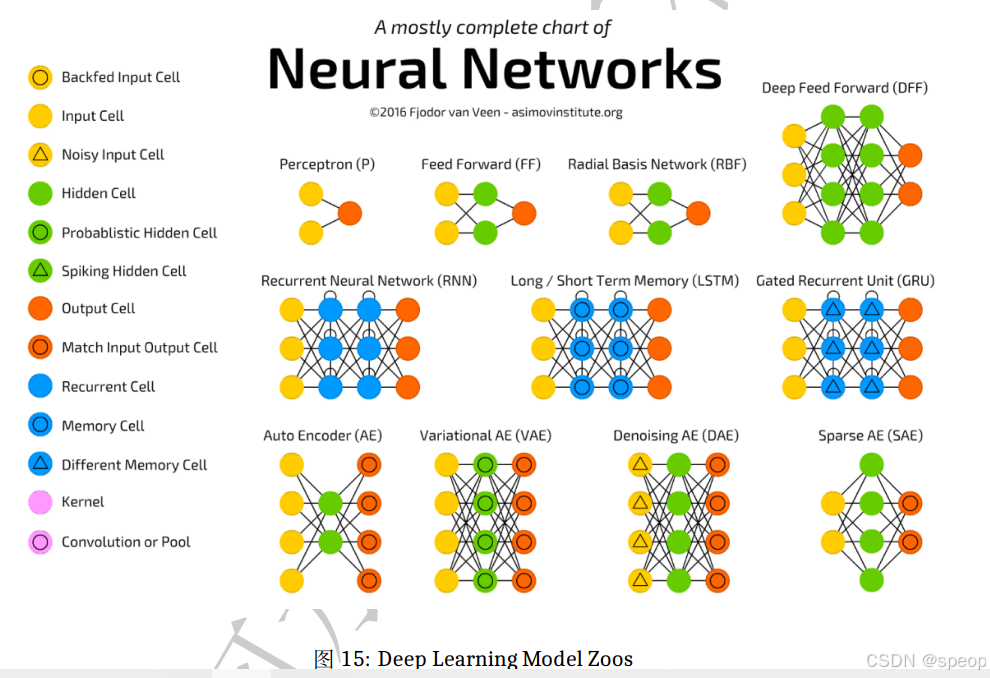
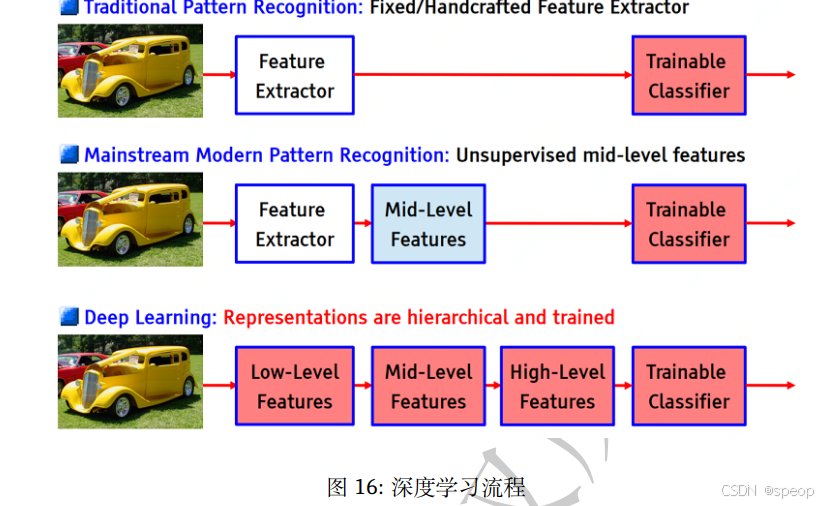

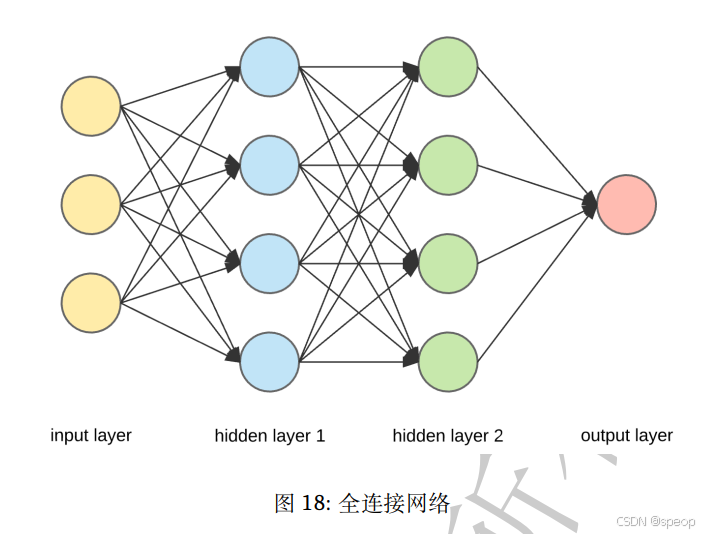
全连接网络
全连接网络(Full Connected,FC)是基础的深度学习模型,它的每一个神经元把前一层所有神经元的输出作为输入,其输出又会给下一层的每一个神经元作为输入,相邻层的每个神经元都有“连接”。
全连接的核心操作是矩阵乘法,本质上是把一个特征空间线性变换到另一个特征空间。全连接网络如果没有隐含层,就变成了全连接层。全连接层对输入的维度敏感,同时也包含了较多的冗余参数,也很难提取局部信息和时序信息。
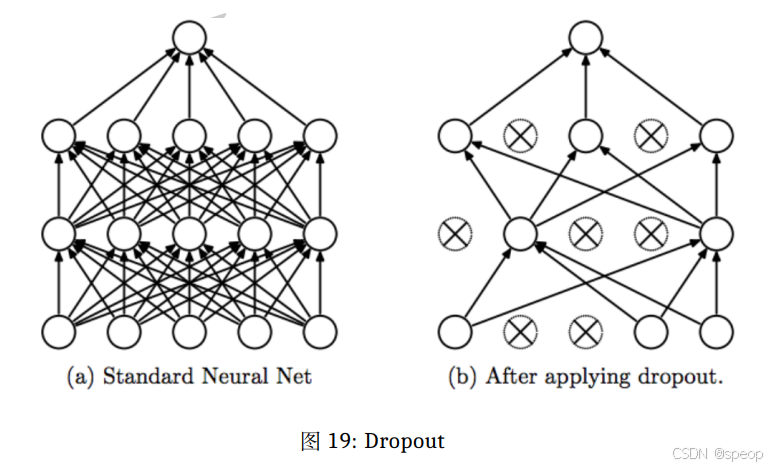
深度学习正则化
在机器学习中,正则化是指基于增强模型泛化能力的先验知识。深度学习拥有较多的参数,如果没
有正则化技术,模型很容易陷入过拟合状态。
深度学习的正则化技术包括参数正则化、Dropout、EarlyStop、数据增强、梯度裁剪和标签平滑等技术。
- Dropout
Dropout 是指在深度学习网络的训练过程中,对于每层网络单元,可以按照一定的概率将其暂时从网络中丢弃。因此每次前向传播的过程中,被丢弃的节点是随机选择的。对于随机梯度下降来说,由于是随机丢弃,故而每一个 mini-batch 都在训练不同的网络。
在预测阶段,Dropout 应该关闭。Dropout 给神经网络带来了随机性,Dropout 关闭的情况下等同于多个模型进行了集成。
2. 数据增强(Data Augmentation)
数据增强是用来扩充数据集,可以进一步减缓模型过拟合的情况。在图像分类任务中,图像的翻转、旋转、颜色改变、边缘处理等操作都不会改变图像的标签。在其他任务中,也可以使用类似的数据增强操作。
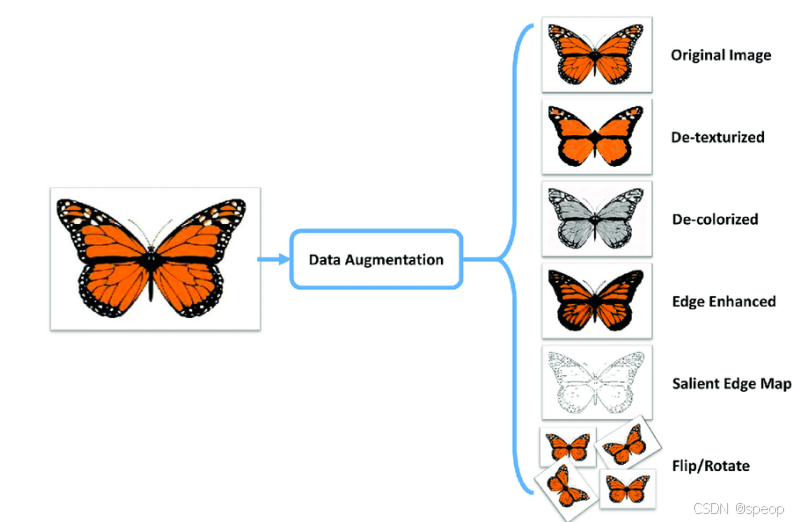
数据增强一般在训练过程中动态进行,因此每次迭代过程中都会有不同的图像进行训练。在预测阶段,也可以对图像进行数据扩增,然后对扩增图像的结果进行平均操作。
深度学习的优化
使用整个训练的优化算法成为批量(Batch)梯度算法,这种方式会在一个批量中处理所有的训练样本。每次只使用一个样本的优化算法称为随机(Stochastic)或在线(Online)算法,这种方式会每次从数据流中抽取样本。现有的深度学习大都使用小批量(Mini-Batch)方法,这种方法使用一个以上而又不是所有的训练样本,这里的样本个数又称为 Batch Size,是深度学习的一个超参数。
卷积神经网络
卷积神经网络与全连接网络非常相似:它们都是由神经元组成,都具有学习能力的权重和偏差。神经元都得到一些输入数据,进行内积运算后再进行激活函数运算。卷积神经网络的训练过程也是端到端的过程:输入是原始的图像像素,输出是不同类别的评分。
竞赛基础知识
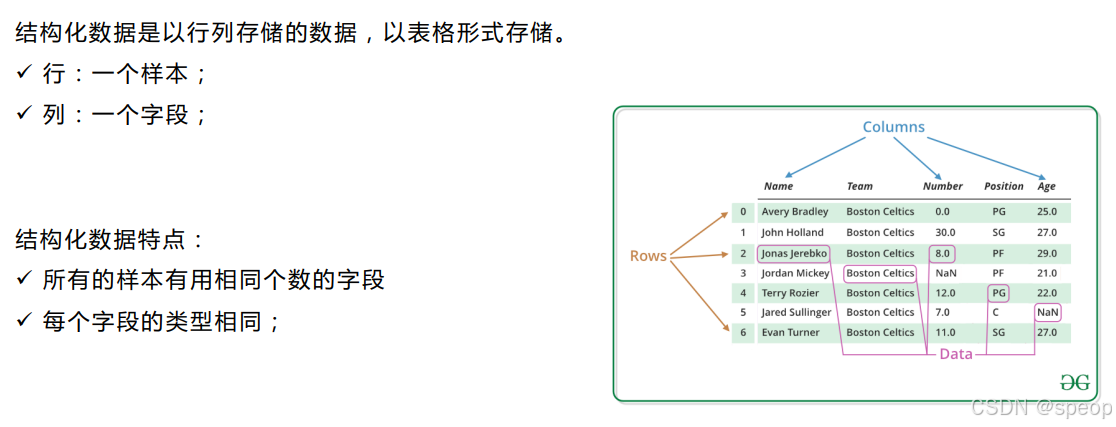


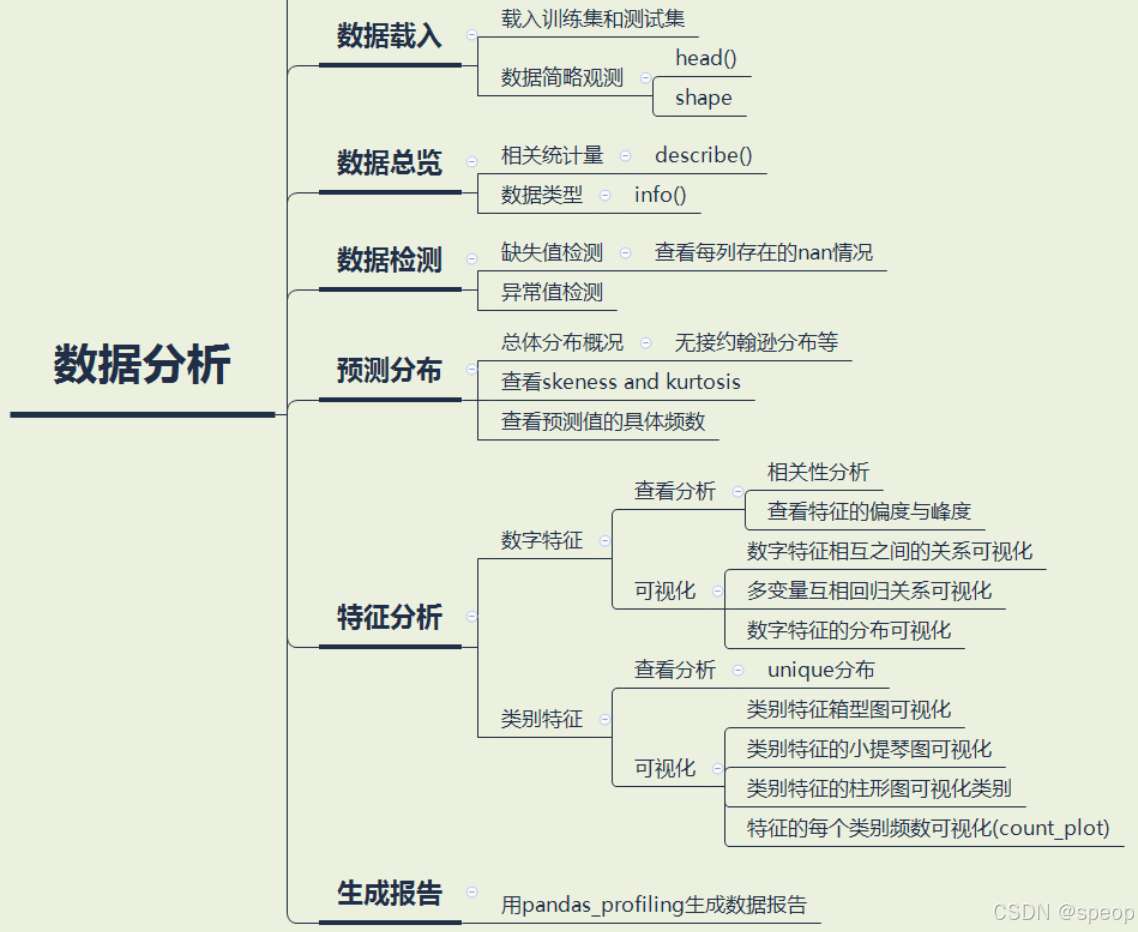
数据探索性分析,是通过了解数据集,了解变量间的相互关系以及变量与预测值之间的关系,对已有数据在尽量少的先验假设下通过作图、制表、方程拟合、计算特征量等手段探索数据的结构和规律的一种数据分析方法,从而帮助我们后期更好地进行特征工程和建立模型,是机器学习中十分重要的一步。
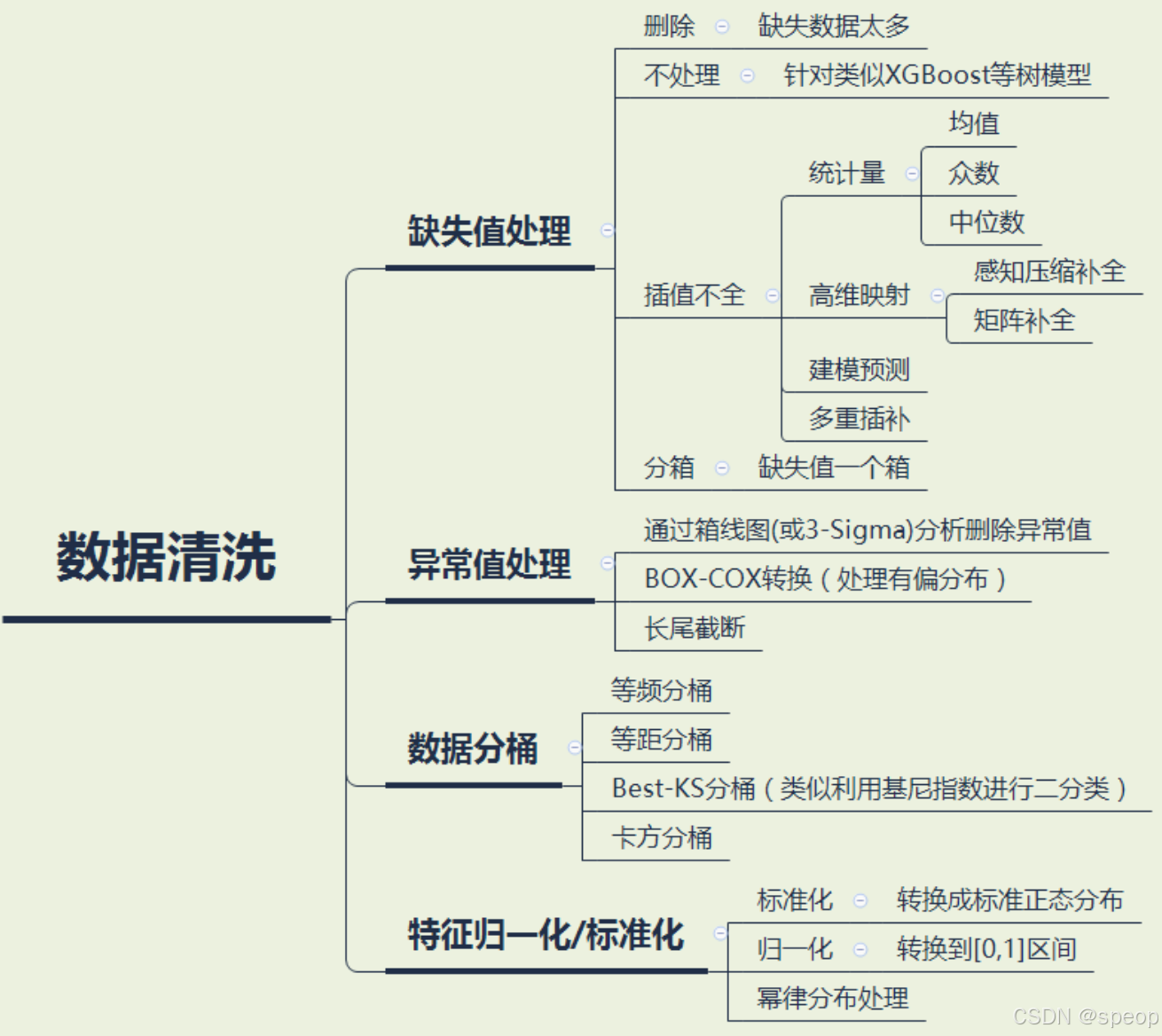
数据清洗
数据清洗的作用是利用有关技术如数理统计、数据挖掘或预定义的清理规则将脏数据转化为满足数据质量要求的数据。主要包括缺失值处理、异常值处理、数据分桶、特征归一化/标准化等流程。
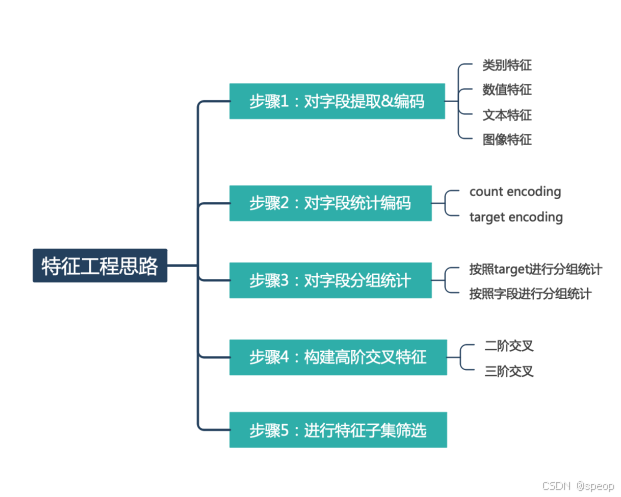
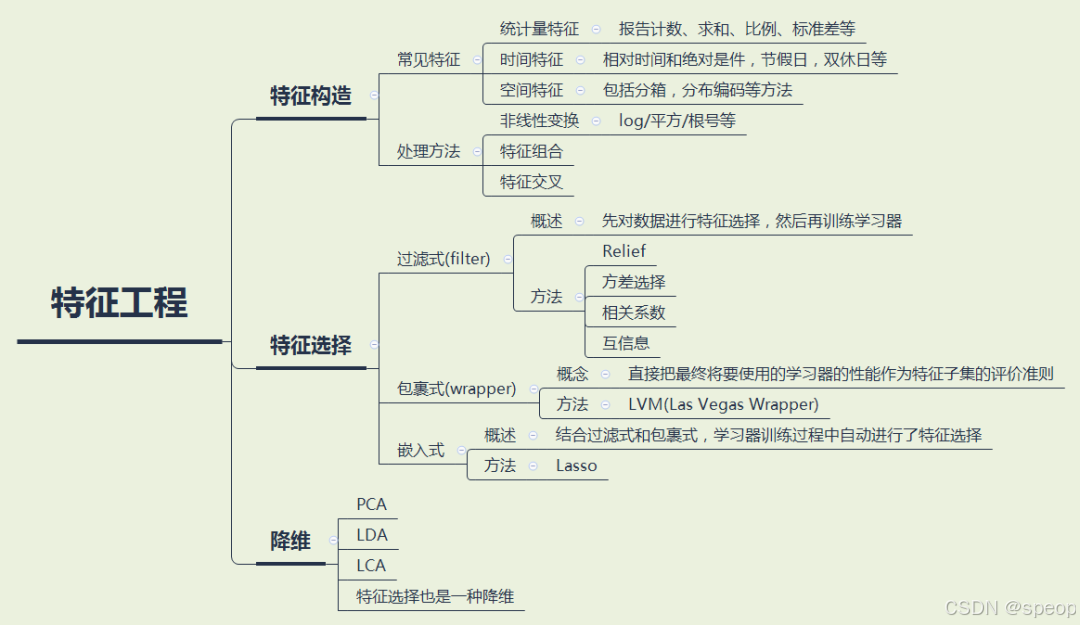
特征工程
特征工程指的是把原始数据转变为模型训练数据的过程,目的是获取更好的训练数据特征。特征工程能使得模型的性能得到提升,有时甚至在简单的模型上也能取得不错的效果。
优化方法建议:
- 提取更多特征:在数据挖掘比赛中,特征总是最终制胜法宝,去思考什么信息可以帮助我们提高预测精准度,然后将其转化为特征输入到模型。
- 尝试不同的模型:模型间存在很大的差异,预测结果也会不一样,比赛的过程就是不断的实验和试错的过程,通过不断的实验寻找最佳模型,同时帮助自身加强模型的理解能力。
特征优化
这里主要构建了历史平移特征、差分特征、和窗口统计特征;每种特征都是有理可据的,具体说明如下:
(1)历史平移特征:通过历史平移获取上个阶段的信息;
(2)差分特征:可以帮助获取相邻阶段的增长差异,描述数据的涨减变化情况。在此基础上还可以构建相邻数据比值变化、二阶差分等;
(3)窗口统计特征:窗口统计可以构建不同的窗口大小,然后基于窗口范围进统计均值、最大值、最小值、中位数、方差的信息,可以反映最近阶段数据的变化情况。
模型训练与验证
模型的建立和调参决定了最终的结果。模型的选择决定结果的上限, 如何更好的去达到模型上限取决于模型的调参。
模型融合
进行模型融合的前提是有多个模型的输出结果,比如使用catboost、xgboost和lightgbm三个模型分别输出三个结果,这时就可以将三个结果进行融合,最常见的是将结果直接进行加权平均融合。
另外一种就是stacking融合,stacking是一种分层模型集成框架。以两层为例,第一层由多个基学习器组成,其输入为原始训练集,第二层的模型则是以第一层基学习器的输出作为特征加入训练集进行再训练,从而得到完整的stacking模型。
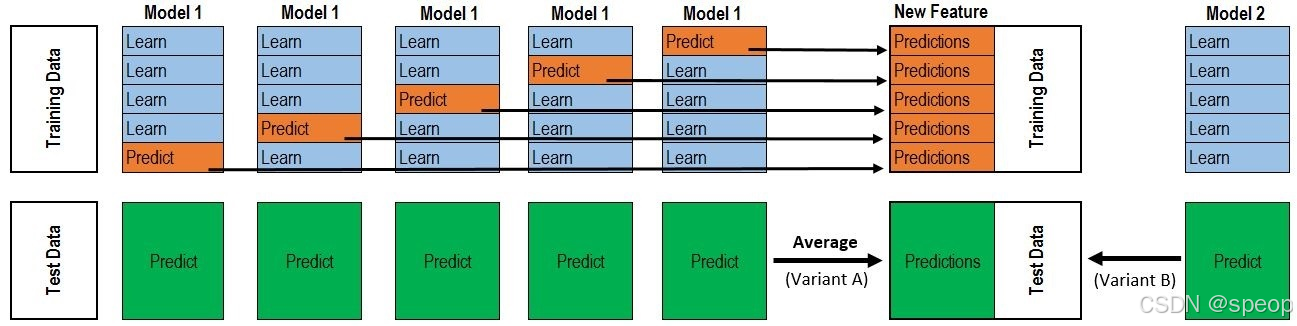
第一层:(类比cv_model函数)
- 划分训练数据为K折(5折为例,每次选择其中四份作为训练集,一份作为验证集);
- 针对各个模型RF、ET、GBDT、XGB,分别进行5次训练,每次训练保留一份样本用作训练时的验证,训练完成后分别对Validation set,Test set进行预测,对于Test set一个模型会对应5个预测结果,将这5个结果取平均;对于Validation set一个模型经过5次交叉验证后,所有验证集数据都含有一个标签。此步骤结束后:5个验证集(总数相当于训练集全部)在每个模型下分别有一个预测标签,每行数据共有4个标签(4个算法模型),测试集每行数据也拥有四个标签(4个模型分别预测得到的)
第二层:(类比stack_model函数) - 将训练集中的四个标签外加真实标签当作五列新的特征作为新的训练集,选取一个训练模型,根据新的训练集进行训练,然后应用测试集的四个标签组成的测试集进行预测作为最终的result。
赛题
航空安全赛道聚焦AI航空结冰气象要素预测,旨在通过历史再分析数据构建预测模型,实现未来三天云水、云冰、云雨、云雪、比湿、温度等要素的精准预测,助力国产大飞机适航认证和全球航线安全运营,为提升飞行经济性与安全性提供创新技术思路。选手需攻克气象条件时间序列预测的复杂性,云水、云冰等要素时空分布不均匀性,极端冰冻事件预测,模型可解释性等关键科学问题,尝试解决航空结冰导致的飞行安全风险。
本次大赛为全球 AI 天气预测竞赛,主办方提供了跨度 5 年的再分析数据。参赛者需凭借 117 个历史大气变量数据,对全球区域未来 1 至 3 天内云水、云冰、云雨、云雪、比湿及温度等气象要素进行预测。这些气象要素直接关乎航空飞行安全,比如其形成的航空结冰现象。航空结冰预测是航空安全领域的关键技术,对于保障飞行安全,提升飞行经济性以及满足适航认证和监管要求具有重要作用。我们期望借由此次大赛,大力推动人工智能技术在航空气象方向的探索。通过加速深度学习算法于航空气象范畴的发展与普及,提升航空气象预报的精准度与时效性,进而全方位促进气象行业与航空业深度融合的数字化、智能化进程。
任务和主题
航空安全:输入历史2个时刻的多个大气变量,输出未来3天逐6小时的高空云水、云冰、云雨、云雪、比湿、温度的预测。
比赛数据
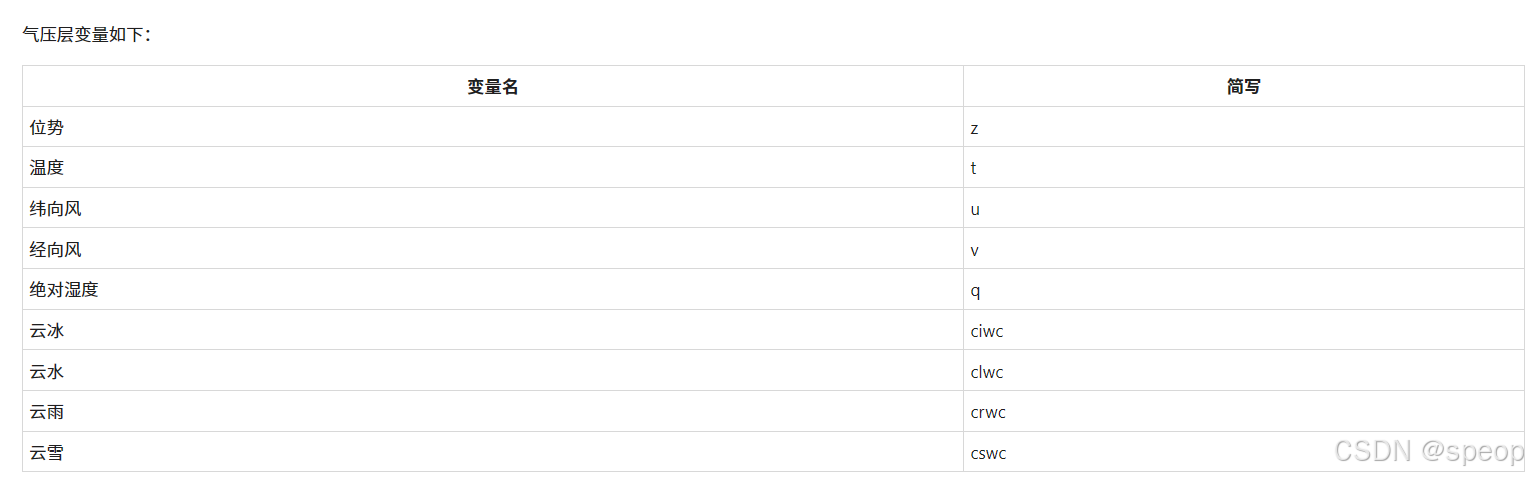
比赛数据来自欧洲中期天气预报中心(ECMWF)的再分析数据ERA5,使用了ERA5的子集,包含9个气压层变量,每个变量有13个气压层(50, 100, 150, 200, 250, 300, 400, 500, 600, 700, 850, 925, 1000 hPa),共计117个变量,时间间隔6小时,空间分辨率1度,覆盖全球区域。
第一课baseline 代码 基于历史均值的简单方案
全局通道索引(Global Channel Indices) 是一个关键的中间变量,用于将输出通道与输入数据的对应关系建立起来。具体来说,全局通道索引用于确定哪些输入通道(对应不同的气象变量和气压层)将被用于生成最终的预测输出。
全局通道索引 是一个列表,包含了所有需要从输入数据中提取的通道的索引位置。这些索引决定了哪些输入通道会被选中并用于后续的预测计算。具体而言,全局通道索引用于:
1.选择特定的气压层:根据比赛要求,选择特定的气压层(如200 hPa、500 hPa等)。
2.选择特定的气象变量:根据比赛要求,选择特定的气象变量(如温度t、湿度q、云冰ciwc等)。
全局通道索引的数据结构是一个一维列表(List),其中每个元素代表一个输入通道的索引位置。这些索引位置是根据变量组和气压层的组合计算得出的。
以 (‘t’, 200) 为例:
1.查找变量组起始索引:
var_groups[‘t’] = 13,表示温度变量组从索引13开始。
2.查找气压层索引:
pressure_levels.index(200) = 3,表示200 hPa在 pressure_levels 列表中的索引位置是3。
3.计算全局通道索引:
global_index = 13 + 3 = 16。
4.结果:
indices 列表中将包含 16,表示温度变量在200 hPa层的全局通道索引是16。
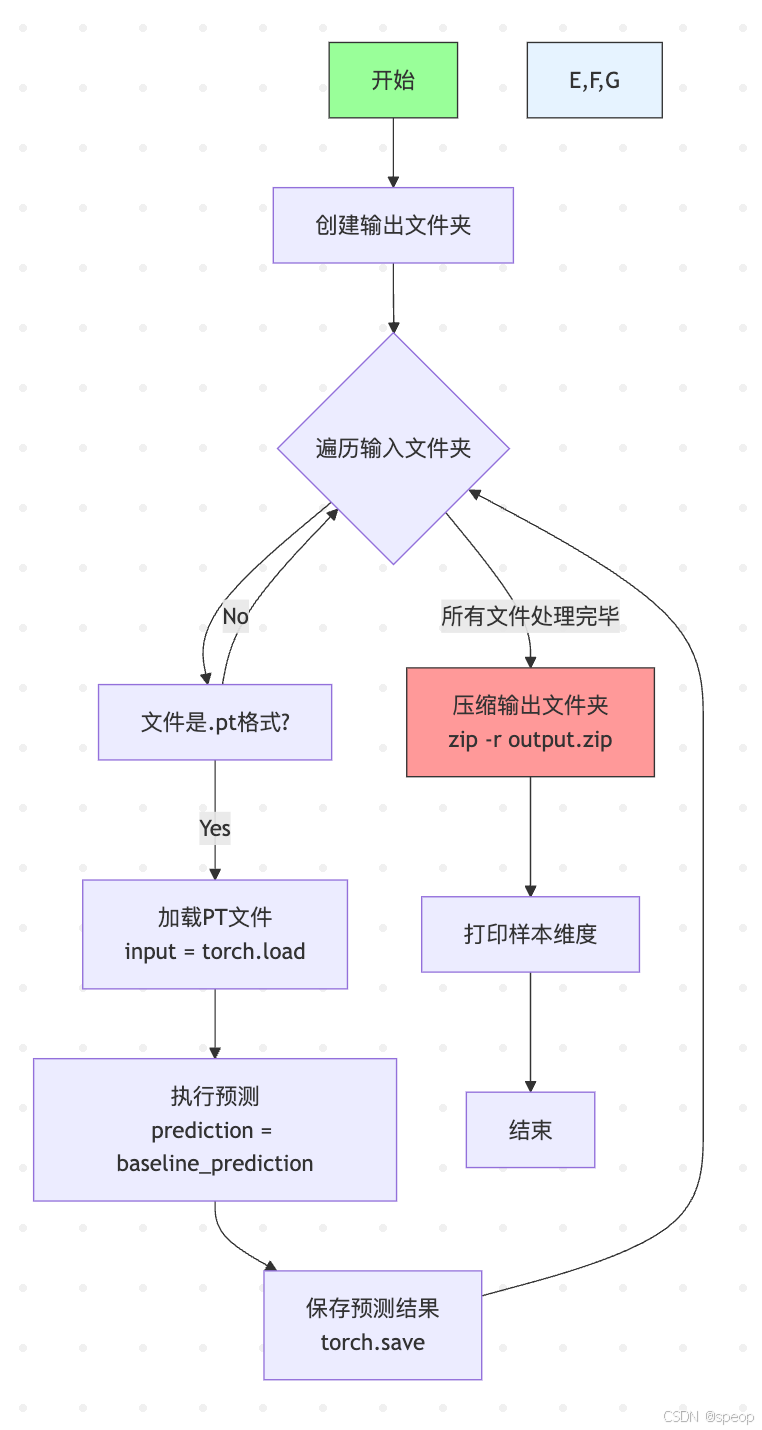
import torch
import os
from pathlib import Pathdef get_output_channels_indices():"""生成输出通道对应的输入通道索引列表"""# 定义了每个气象变量组的起始索引#'t'(温度)变量的起始索引是13,意味着温度相关的气压层从索引13开始。var_groups = {'z': 0,'t': 13,'u': 26,'v': 39,'q': 52,'ciwc': 65,'clwc': 78,'crwc': 91,'cswc': 104}# 这个列表定义了需要输出的通道,每个元组包含变量名和对应的气压层。# 例如,('t', 200) 表示温度变量在200 hPa层。output_config = [('t', 200), ('t', 500), ('t', 700), ('t', 850), ('t', 1000),('q', 200), ('q', 500), ('q', 700), ('q', 850), ('q', 1000),('ciwc', 200), ('ciwc', 500), ('ciwc', 700), ('ciwc', 850), ('ciwc', 1000),('clwc', 200), ('clwc', 500), ('clwc', 700), ('clwc', 850), ('clwc', 1000),('crwc', 200), ('crwc', 500), ('crwc', 700), ('crwc', 850), ('crwc', 1000),('cswc', 200), ('cswc', 500), ('cswc', 700), ('cswc', 850), ('cswc', 1000)]# 表定义了气压层的顺序,从50 hPa到1000 hPa。pressure_levels = [50, 100, 150, 200, 250, 300, 400, 500, 600, 700, 850, 925, 1000]#计算全局通道索引indices = []#遍历 output_config 中的每个变量和气压层组合for var, level in output_config:# 使用 pressure_levels.index(level) 找到给定气压层在 pressure_levels 列表中的索引位置 level_index。level_index = pressure_levels.index(level)# 计算全局通道索引global_index = var_groups[var] + level_indexindices.append(global_index)return indicesdef baseline_prediction(input_tensor):
### 如果需要该预测的模型可以从这里入手"""核心预测逻辑"""# 获取动态生成的通道索引output_channels_indices = get_output_channels_indices()# 计算两个时间步的均值 (1,117,181,360)mean_data = input_tensor.squeeze(0).mean(dim=0)# 空间裁剪参数lat_slice = slice(35, 81) # 55N~10N 对应的纬度切片lon_slice = slice(70, 141) # 70E~140E 对应的经度切片# 提取目标区域数据 (117,46,71)cropped_global = mean_data[:, lat_slice, lon_slice]# 筛选输出通道 (30,46,71)output_core = cropped_global[output_channels_indices, :, :]#通过这些索引,代码从裁剪后的全局数据 cropped_global 中选择出需要的通道,形成最终的输出核心 output_core。# 扩展时间维度并复制12次 (1,12,30,46,71)output = output_core.unsqueeze(0).unsqueeze(0).expand(1, 12, -1, -1, -1)return output.half() # 转换为float16def process_files(input_dir="input", output_dir="output"):"""批量处理文件"""# 创建输出目录Path(output_dir).mkdir(parents=True, exist_ok=True)# 遍历输入目录for file_name in os.listdir(input_dir):if not file_name.endswith(".pt"):continueinput_path = os.path.join(input_dir, file_name)output_path = os.path.join(output_dir, file_name)try:# 加载数据并验证形状input_data = torch.load(input_path)# 生成预测prediction = baseline_prediction(input_data)# 保存结果torch.save(prediction, output_path)print(f"成功处理: {file_name}")except Exception as e:print(f"处理失败 {file_name}: {str(e)}")if __name__ == "__main__":# 执行批量处理process_files()# 验证示例输出形状sample = torch.load(Path("output")/"001.pt")print(f"输出形状验证: {sample.shape} (应为 torch.Size([1, 12, 30, 46, 71]))")

output = output_core.unsqueeze(0).unsqueeze(0).expand(1, 12, -1, -1, -1):
#squeeze(dim):
#当 dim 指定为某个维度时,仅在该维度大小为1时移除该维度。
#如果指定的维度大小不为1,则张量保持不变。
#unsqueeze(dim):
#在指定的位置插入一个新的维度,其大小为1。
#插入的位置由 dim 参数决定,可以是正数或负数。
作用:
unsqueeze(0)在第0维度添加一个新的维度,形状变为(1, 30, 46, 71)。
再次unsqueeze(0)在第0维度添加一个新的维度,形状变为(1, 1, 30, 46, 71)。
expand(1, 12, -1, -1, -1)在第1维度复制12次,最终形状变为(1, 12, 30, 46, 71)
squeeze(0)
作用: 移除张量中维度为1的维度。如果指定的维度不是1,则不会进行任何操作。
具体操作:
在代码中,input_tensor.squeeze(0)的作用是移除输入张量的第一个维度(假设这个维度的大小为1)。
例如,如果输入张量的形状是 (1, 117, 181, 360),那么 squeeze(0) 后的形状将变为 (117, 181, 360)。
squeeze(1)作用是移除输入张量的第二个维度(假设这个维度的大小为1)。(2,1,22,2)->(2,22,2),如果是(2,3,1,3)则不进行操作
unsqueeze(0)
作用: 在指定位置插入一个新的维度,其大小为1。
具体操作:
在代码中,output_core.unsqueeze(0) 的作用是在输出张量的第一个位置插入一个新的维度。
例如,如果 output_core 的形状是 (30, 46, 71),那么 unsqueeze(0) 后的形状将变为 (1, 30, 46, 71)。
再次调用 unsqueeze(0) 后,形状将变为 (1, 1, 30, 46, 71)。
return output.half():
作用: 将输出张量的数据类型转换为float16,以节省内存和计算资源
将张量的数据类型转换为float16(半精度浮点数)主要涉及底层的数值类型转换
这一过程包括:
截断位数:float16只有16位,相较于float32的32位,需要截断多余的位数。
舍入策略:在截断过程中,需要采用适当的舍入策略(如最近舍入、向上舍入、向下舍入等)来最小化精度损失。
PyTorch在实现类型转换时,主要依赖底层的库和硬件指令,具体步骤如下:
1.内存布局:PyTorch张量在内存中以连续的字节块存储。类型转换时,需要重新解释这些字节,以匹配目标数据类型的格式。
2.调用底层函数:PyTorch通过调用底层的BLAS(基础线性代数子程序)库或其他优化过的库函数,执行实际的类型转换操作。例如,对于GPU上的操作,PyTorch会调用CUDA的相应函数。
3.并行处理:为了提高效率,类型转换通常是并行进行的。例如,一次可以转换多个元素,利用SIMD指令或GPU的并行计算能力。
背后发生的事情:
1.内存复制与重解释:x.half()会创建一个新的张量x_half,其内存布局与x相同,但解释为float16类型。
2.硬件加速:如果操作在GPU上进行,PyTorch会利用CUDA的并行指令,快速地将数据从float32转换为float16。
3.舍入处理:在转换过程中,PyTorch会根据IEEE 754标准,采用合适的舍入策略,确保转换的精度尽可能高。
性能考虑
内存带宽:类型转换操作通常受限于内存带宽,因为需要读取原始数据并写入转换后的数据。
并行度:利用SIMD指令和GPU的并行计算能力,可以显著提高类型转换的性能。
第二课
数据探索分析、数据清洗、特征工程、模型训练、模型验证
基于树模型的气象预测进阶路线(结构化回归问题)
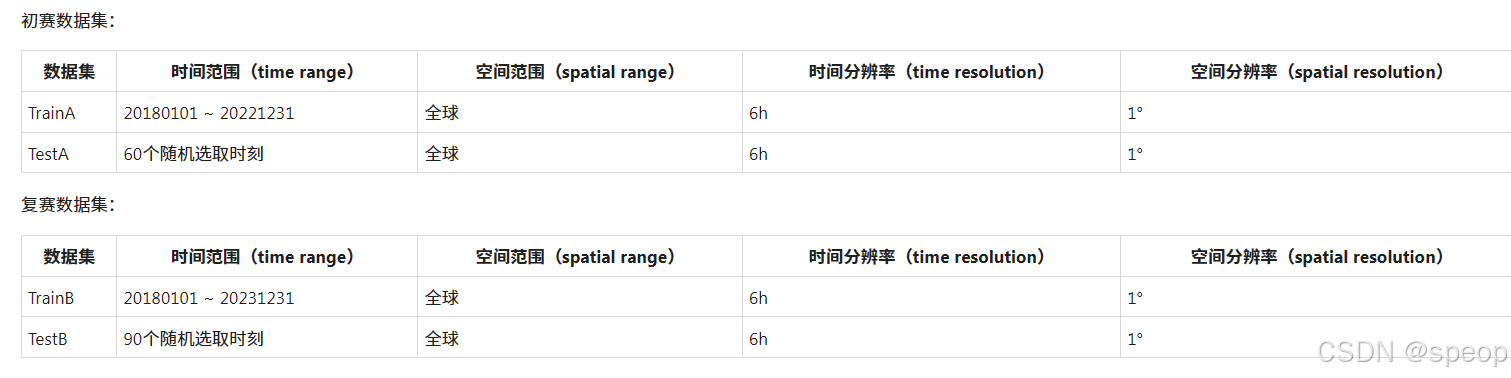
初赛数据集:
训练集:2018年1月1日~2022年12月31日
范围:全球
测试集:60个随机选取时刻
复赛数据集:
训练集:2018年1月1日~2023年12月31日
范围:全球
测试集:90个随机选取时刻
云冰、云水、云雨、云雪较稀疏;大部分时间,空间上为0或极小值,呈现长尾分布
评价指标:
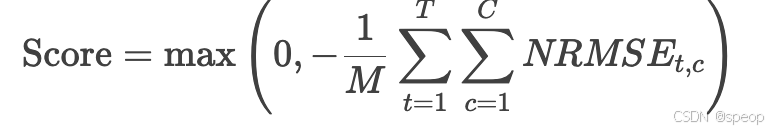
- T表示时间维度
- C表示通道维度
- M表示时间维度T和通道维度C的乘积
NRMSE表示归一化RMSE,公式为:
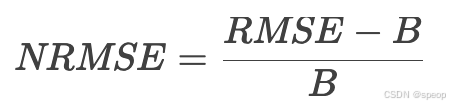
- B表示该通道的RMSE基准值
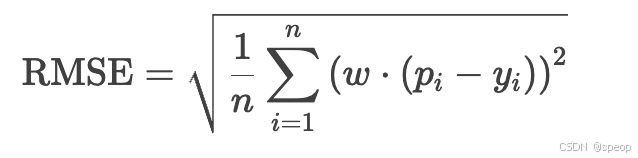
i表示测试集样本,样本数为n
p为预测值
y为学习目标
权重w = cos(deg2rad(lat))
航空安全:【输入历史2个时刻的多个大气变量,输出未来3天逐6小时的高空云水、云冰、云雨、云雪、比湿、温度的预测】
比赛数据来自欧洲中期天气预报中心(ECMWF)的再分析数据ERA5,使用了ERA5的子集,包含9个气压层变量,每个变量有13个气压层(50, 100, 150, 200, 250, 300, 400, 500, 600, 700, 850, 925, 1000 hPa),共计117个变量,时间间隔6小时,空间分辨率1度,覆盖全球区域。
3天 24*3=72小时,72小时每步6小时可以分为 72/6=12
输入数据的形状:(1,2,117,181,360)
目标变量有6个
赛题解读
a、算法抽象:类似AI中的视频预测任务,基于历史帧预测未来帧。本任务是构建预测模型,学习气象数据过去和未来的关系。
b、数据说明
i.ERA5再分析资料:同化了模式预报、观测数据,是目前最准确的标准化格点数据,表示真值。
算法方案
1.数据
a.数据清洗,标准化
b. 选择有效的输入通道
i. 比赛输出的30个通道(需预测以下 6类气象变量,每个变量需在 5个气压层 )
ii. 增加其他气压层通道
iii. 增加其他气象要素
2. 方案
a. 自回归
i. 单模型自回归(需解决迭代误差
ii. 多模型自回归
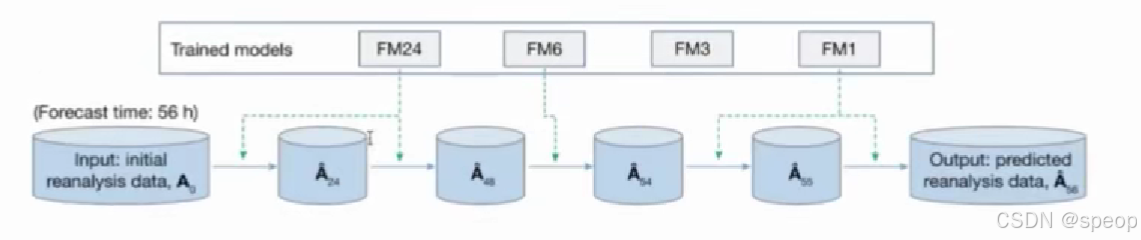
b 一步输出12时次
c. 集合预报
3. 模型
a. Unet/Unet 3D/SimVP/Swin Unet/
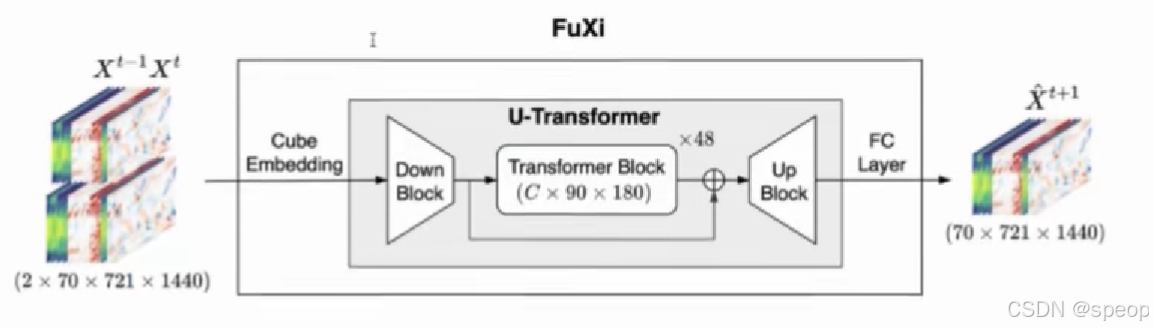
b. FuXi/PanGu/GraphCast
4. Loss
a. 纬度加权L1 Loss
b. 中国区域加权Loss
c. …
关键概念
- 位势z:单位质量相对于某标准面(习惯上指平均海平面)的位能
- 绝对湿度q:一定体积的空气中含有的水蒸气的质量
- 云水、云冰、云雨、云雪:云中一定体积的空气中含有水、冰、雨、雪质量
baseline简介
1.输入:过去2个时刻117个通道
2.目标:未来1个时刻117个通道
3.结果:自回归生成未来12小时预报
4.提交:截取30个通道的中国区域
将全球气象预测转换为 结构化回归问题 ,核心挑战:
5. 高维度时空数据 :2个历史时刻 × 117变量 × 181纬度 × 360经度 → 约千万原始特征
6. 长预测序列 :需预测未来12个时间步(72小时)的30个目标变量
7. 空间依赖性 :相邻格点的气象状态高度相关
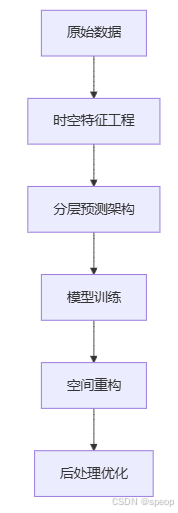
1)原始数据
2)时空特征工程
3)分层预测架构
4)模型训练
5)空间重构
6)后处理优化
- 特征工程策略
可能需要检测是否有空值或infinity
核心特征类型 :
特征降维技巧 :
# 基于特征重要性的筛选
import lightgbm as lgb
#lightgbm是一个实现了GBDT算法的框架,GBDT 在每一次迭代的时候,都需要遍历整个训练数据多次
#LightGBM 提出的主要原因就是为了解决 GBDT 在海量数据遇到的问题,让 GBDT 可以更好更快地用于工业实践。# 训练初始模型
model = lgb.LGBMRegressor()
model.fit(X_train, y_train)# 获取模型特征的重要性
importance = model.feature_importances_
selected_idx = np.where(importance > np.percentile(importance, 90))[0]
X_train_reduced = X_train[:, selected_idx]
- 分层预测架构
层级划分策略 :
- 变量层级 :为每个目标变量(如t500、ciwc200)单独训练模型
- 时间层级 :分阶段预测(0-24h、24-48h、48-72h)
- 空间层级 :将全球划分为5°×5°的区块单独建模
优势 :
- 降低单模型复杂度
- 允许变量特异性参数调优
- 并行化训练加速
- 模型训练方案
数据准备
# 样本构造示例(单个格点单时间步)
样本数 = 181(lat) × 360(lon) × 2(time) = 130,320
特征数 ≈ 200 (经筛选后)
目标值 = 未来12个时刻的30个变量值 → 需30×12=360个模型# 代码片段
for target_var in output_vars:for step in range(12):# 提取该变量该时刻的标签y = dataset[:, step, target_var]# 训练独立模型model = LGBMRegressor()model.fit(X_features, y)
关键参数配置
objective: 'regression'
metric: 'rmse'
boosting_type: 'dart'
num_leaves: 127
learning_rate: 0.1
feature_fraction: 0.8
bagging_freq: 5
- 空间重构后处理
格点预测聚合:
def reassemble_global(preds):# preds: [num_samples, 1] → [181, 360]global_grid = np.zeros((181, 360))for i, (lat, lon) in enumerate(grid_coords):global_grid[lat, lon] = preds[i]return global_grid
物理约束应用 :
def apply_constraints(grid, var_name):if 'ciwc' in var_name:grid = np.maximum(grid, 0)elif 't' in var_name:grid = vertical_adjustment(grid) # 应用温度垂直递减率修正return grid
基于深度学习的进阶路线( 时空序列预测问题)
一、问题重新建模
需要将气象预测转化为 时空序列预测问题 ,核心挑战在于:
- 多变量耦合 :117个输入变量间的复杂相互作用
- 多尺度特征 :从局部对流到全球环流的空间尺度差异
- 长期依赖 :预测未来72小时(12个时间步)的演变
二、技术路线设计
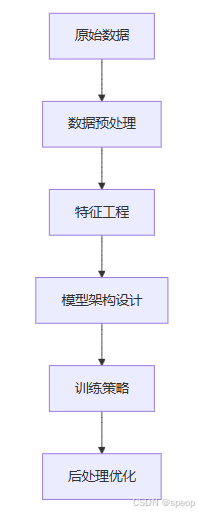
关键实现步骤
- 数据预处理
- 目标 :构建适合深度学习的高效数据管道
- 特征工程
- 核心特征类型 :
- 原始变量 :直接使用117个标准化后的气象变量(标准化便于模型处理)
- 派生特征 :
- 垂直梯度:∂变量/∂气压
- 水平梯度:纬向风切变、经向温度平流
- 物理组合量:涡度、散度、位涡
- 地理特征 :地形高度、海陆掩膜
- 时间特征 :年周期、日周期编码
- 特征筛选 :
from sklearn.feature_selection import mutual_info_regression
#计算特征重要性
mi = mutual_info_regression(X_train.reshape(-1,X_train.shape[-1]),y_train.flatten())selected_features = np.argsort(mi)[-50:]#保留前50个重要特征- 模型架构
推荐架构 :U-Net3D + Transformer 的混合模型
class WeatherNet(nn.Module):def __init__(self):super().__init__()# 编码器:提取多尺度空间特征self.encoder = UNet3D(in_channels=117, base_channels=64)# 时间建模:Transformer捕捉长期依赖self.transformer = TransformerEncoder(d_model=512, nhead=8, num_layers=6)# 解码器:生成多时间步预测self.decoder = nn.Sequential(nn.Conv3d(512, 30*12, kernel_size=1),nn.AdaptiveAvgPool3d((12,46,71))def forward(self, x):# x: [B, 2, 117, 13, 181, 360]x = self.encoder(x) # [B, 512, 13, 46, 71]x = self.transformer(x.flatten(2)) # [B, 512, 13*46*71]return self.decoder(x.view(-1,512,13,46,71)) # [B, 30, 12,46,71]
架构优势 :
- 3D卷积 :同时捕捉垂直-水平空间特征
- Transformer :建模全局时空依赖
- 轻量解码 :降低计算复杂度
- 训练策略
损失函数设计 :
def loss_function(pred, true):# 基础MSEmse_loss = F.mse_loss(pred, true)# 物理约束惩罚项cloud_vars = pred[:, 10:20] # 云参数通道neg_penalty = torch.relu(-cloud_vars).mean() # 非负约束# 梯度平滑约束dx = pred[:,:,:,1:,:] - pred[:,:,:,:-1,:]dy = pred[:,:,:,:,1:] - pred[:,:,:,:,:-1]smooth_loss = dx.abs().mean() + dy.abs().mean()return mse_loss + 0.1*neg_penalty + 0.05*smooth_loss
优化技巧 :
5. 后处理优化
物理一致性约束 :
def apply_physical_constraints(pred):# 云参数非负pred[..., 10:20] = torch.clamp_min(pred[..., 10:20], 0)# 温度垂直递减率修正for i, pl in enumerate([200,500,700,850,1000]):pred[...,i] -= 0.0065 * (1000 - pl) # 6.5K/km递减率return pred集成预测 :
# 使用多个模型预测并加权平均
model1_pred = model1(input_data)
model2_pred = model2(input_data)
final_pred = 0.6*model1_pred + 0.4*model2_pred
以上资料均来自datawhale组队学习春训营第一期