汇编语言中的数据
在汇编语言中,程序都是由指令流构成的,而指令一般是由操作符和操作数组成的,操作符是CPU用来完成某项功能的操作,而操作数是操作符所处理加工的对象。比如:add eax, 42,add是执行一个加法运算的操作符,是把eax中的值和常数42相加,并保存到eax中,而指令中的操作数,如常数42和存放在eax寄存器中的数值。
在高级语言中,数据本身带有类型信息,比如C语言中,6是一个整型(int)的值,'6’是字符型(char)的值,而"6"就是字符串类型的值,再比如变量:int a,那么在内存地址“&a”中存放的数据是有符号int整型数据。而在汇编语言中,如果脱离开指令上下文环境单独看待它们,它们仅仅是一个二进制的数据,并没有具体的意义,也就是它们没有类型信息,一个数据只有出现在指令中,作为操作数进行操作时才知道它所表示的意义,同一个数据用在不同形式的指令中,可能表示不同的类型。
注,本文以x86-64处理器的汇编语言说明,汇编指令的格式是Intel风格,下面内容均为个人观点。
1、如何表述数据?
既然在汇编语言中,数据自身没有类型信息,那么,如何来表述它们呢?描述数据有三个要素:位置、长度和内容。
位置,就是表示数据存放在哪儿,以及怎么才能找到它?数据只能存放在三个地方:指令中、寄存器中和内存中。
长度,就是数据它占有多大的存放空间。比如数据可以占用1字节、2字节、4字节、8字节、16字节等2的次幂大小的空间,如果是存放在内存中,也可以是3字节、5字节、6字节、乃至n字节大小的空间,比如表示串操作的数组、字符串等数据。
内容,就是指它所表示的是什么。同一个数据可能表示一个字符、整型数、浮点数、地址等,取决于数据用作什么指令的操作数,也就是数据表示什么是根据所处的上下文环境决定的,所表示的是什么和操作它的指令息息相关。
显然,长度和内容对应了高级语言中的类型,比如在C/C++中声明short data,则表示data长度占用2个字节,表示的是范围在-37768~37767之间的整型数,data的位置取决于定义的场合:可以在栈中、堆中,数据区、常量区等。在汇编语言中,如果数据存放在内存中的话,比如[rax],寄存器rax中存放64位的地址,rax可以对应高级语言的void*指针,只是一个位置地址,如果没有相关的前缀信息比如dword ptr,是不知道所指向的数据的长度,也不知道表示的是什么。
下面分别看一下它们在汇编语言中是如何表示的。
2、数据位置-放在什么地方?
在汇编语言中,数据就存在于三个地方:
1、位于指令中
是一个常量,也叫立即数,一般会被编码到指令中,成为指令的一部分。 它只能用作指令的源操作数,比如指令mov eax, 42,源数据42位于指令中。
下面是这条指令编译完之后的二进制指令流,就是这条mov指令汇编完之后的二进制数据b82a000000,在执行时,CPU要把这个二进制指令流放在执行引擎中执行,在译码时就能从中得到数据42。
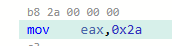
我们知道,十进制数字42对应的16进制是0x2a,而b8表示把4字节的二进制数据存入寄存器eax,指令的其余部分2a000000就是数字42,是个4字节长度的数据。
立即数一般来源自高级程序中的const int、constexpr int、整数字面量等,但高级程序中的常量也不一定都会当作立即数位于指令中,有时候也会位于只读数据区,存放于内存中。
2、位于寄存器中
数据存放在通用寄存器中,它可以用作源操作数和目的操作数。比如:
add eax, edx
加法操作add有两个操作数,数据分别存放在寄存器eax和edx中,CPU在执行时,执行引擎会从这两个寄存器中得到数据。
3、位于内存中
指定的是数据在内存中的位置,可以用作源操作数或目的操作数,但不能同时用作源和目的操作数。所在内存位置最常见的表示形式是:[64位寄存器±偏移量],比如[rax+4],寄存器rax的值表示一个内存地址,假设是0x8000000000,把它加上4之后,也就是在0x80000000004内存位置。
3、数据长度-占多大的地方?
数据的长度信息表示,和它存放在哪儿有关,在不同的地方有不同的长度表示方式。
1、立即数
长度取决于字面形式源操作数和目的操作数的长度,一般都是1、2、4、8字节的长度。例如,对于0x42这个立即数,如果目的数是单字节长度,它在指令中是单字节长度,如果目的数是2字节长度,它在指令中的长度是2字节,如果目的数是4、8字节长度,它在指令中的长度是4字节;对于0x4200这个立即数,如果目的数是2字节长度,它在指令中的长度是2字节,如果目的数是4、8字节长度,它在指令中的长度是4字节;对于0x4200000000这个立即数,在指令中只能是8字节长度。
2、寄存器
长度取决于寄存器的大小,就以累加寄存器ax、eax、rax系列以及SIMD寄存器为例:
| 寄存器 1 | 字节 | bit | 长度可能对应的C/C++类型 |
|---|---|---|---|
| al | 1 | 8 | char、unit8_t、int8_t |
| ax | 2 | 16 | short、uint_16、int_16 |
| eax | 4 | 32 | int、uint32_t、int32_t、float |
| rax | 8 | 64 | long long、uint64_t, int64_t、double |
| rdx:rax组合 | 16 | 128 | struct {int64_t, int64_t}、int64_t[2]、double[2] |
| ymm | 16 | 128 | int8_t[16]、int16_t[8]、int32_t[4]、int64_t[2]、float[4]、double[2] |
| ymm | 32 | 256 | int8_t[32]、int16_t[16]、int32_t[8]、int64_t[4]、float[8]、double[4] |
| zmm | 64 | 512 | int8_t[64]、int16_t[32]、int32_t[16]、int64_t[8]、float[16]、double[8] |
即,如果一个数据存放在寄存器eax中,它的长度就是4字节32bit,显然可能是来自高级语言的int、uint32_t、int32_t、float、struct{short, short}, char[4]等类型的数据。
3、内存数据
内存可以存放更多的数据,而且存放数据的地方也没有额外的信息来表示它的长度,在指令中需要专门的标识符来表示长度,在不同风格形式的汇编语言中有不同的表示形式。
在Intel风格的汇编语言中,数据的长度信息需要专门指定前缀,如:单字节长度的内存数据使用byte ptr前缀来指示,4字节长度的内存数据使用dword ptr前缀来表示,例如 mov eax,dword ptr [rax],表示把寄存器rax中的值作为地址,从内存中读取4字节的数据放到寄存器eax中,即数据是[rax]指向的内存位置处连续4字节的长度。
而ATT风格的汇编语言中,长度信息是由操作符使用后缀来指示的,比如:movl (%rax), %eax,使用movl操作符来表示寄存器rax指向的内存位置的4字节数据,把它存入寄存器eax。其它的比如movb、movw、movq等用于不同长度的数据,b、w、l、q后缀分别表示1字节、2字节、4字节和8字节的内存数据的长度。
下面列举各种数据的长度的前缀,以及对应C/C++的类型:
| 前缀 | 字节 | bit | 长度可能对应的C/C++类型 |
|---|---|---|---|
| byte ptr | 1 | 8 | char、unit8_t、int8_t |
| word ptr | 2 | 16 | short、uint_16、int_16 |
| dword ptr | 4 | 32 | int、uint32_t、int32_t、float |
| qword ptr | 8 | 64 | long long、uint64_t, int64_t、double |
| xmm ptr | 16 | 128 | int8_t[16]、int16_t[8]、int32_t[4]、int64_t[2]、float[4]、double[2] |
| ymm ptr | 32 | 256 | int8_t[32]、int16_t[16]、int32_t[8]、int64_t[4]、float[8]、double[4] |
| zmm ptr | 64 | 512 | int8_t[64]、int16_t[32]、int32_t[16]、int64_t[8]、float[16]、double[8] |
此外,汇编中还有串操作(对应于C/C++语言中的数组类型),这些数据全部存放在内存中,串操作数据的长度,需要由专门的寄存器存放,存放在寄存器cx/ecx中。
4、数据内容- 存放的是什么?
数据所表示的类型,取决于用做什么指令的操作数。指令运算时的它眼中的操作数可以是整型、浮点型、指针、位域、BCD整型、串型(string)和组合类型。
比如,以下面的指令形式为例:
#操作符# eax, dword ptr [rbp-24];
源操作数: dword ptr [rbp-24];
位置:rbp-24指向的内存位置
长度:dword,双字,即4字节长度
类型:取决于操作符的类型,如果是传输型,如mov,不确定,如果是算术运算符,则是整型,如果是逻辑运算型,则是无符号整型
目的操作数:eax
位置:寄存器eax
长度:eax位长是32位,即4字节长度
类型:取决于操作符的类型
下面举一个例子:
假设源数据是qword ptr [rsp],此形式能确定数据的两个要素,位置:rsp指向的内存地址,长度:8字节。下面是它可能出现的场景及类型,假设long、double是64位长度:
MOV rax, qword ptr [rsp]
什么类型都可能,取决于后续以rax为操作数的操作
ADD rax, qword ptr [rsp]
因为ADD操作符用于整型加法运算,因此类型可能是long或unsigned long
MUL rax, qword ptr [rsp]
因为MUL操作符用于无符号整型乘法运算,因此类型明确是unsigned long
IMUL rax, qword ptr [rsp]
因为MUL操作符用于无符号整型乘法运算,因此类型明确是signed long型
MOVSS xmm3, qword ptr [rsp] ;是float类型
MOVSD xmm3, qword ptr [rsp] ;是double类型
MOV rax, qword ptr [rsp]
什么类型都可能,取决于后续以rax为操作数的操作
MOVD xmm0, qword ptr[rax]
后续操作MOVD:qword ptr[rax],rax用作地址,它是指向一个8字节的数据的指针,仍不知指向什么类型。
MOVSD xmm3, xmm0
此时确定是double类型,即rsp是一个二维指针,即对应C/C++的double **ptr类型;
paddw mm1, qword ptr [rsp]; 指向组合整数,等同于C的short[4]数组
paddb mm1, qword ptr [rsp]; 指向组合整数,等同于C的char[8]数组
jmp qword ptr [rsp] ; 是地址,可能是指针,包括函数指针类型
jcc qword ptr [rsp] ; 是地址,可能是指针,包括函数指针类型
call qword ptr [rsp] ; 是函数指针
可见,同一个数据在不同形式的指令中,可能表示不同的类型,比如,假设rsp寄存器指向的内存处,长度8字节的内容是0x8123456781234567。比如,在下面的指令中,它会表示不同的类型:
MUL rax, qword ptr [rsp] ; 是uint64_t类型,值是9305357565928097127
IMUL rax, qword ptr [rsp] ; 是int64_t类型,值是-9141386507781454489
MOV rax, qword ptr [rsp] 和 MOV mm0, qword ptr[rax]; 是指针,指向0x8123456781234567内存位置
MOV mm0, qword ptr[rax] ; 是char数组,值是{0x81, 0x23, 0x45, 0x67, 0x81, 0x23, 0x45, 0x67}
MOVSD xmm0, qword ptr [rsp] ; 是double类型,值是-3.5127004713770933e-303,几乎是0.0。
5、如何访问数据
知道数据在哪儿,也知道长度,如何取获取数据呢?尤其是在内存中的数据。是由不同的寻址方式来获取数据,在x86-64处理器中共有下面几种方式:
1、立即数寻址
数据是立即数常数,存在于指令中。比如指令:mov eax, 42,它的指令二进制编码是:b82a000000,其中4字节长度的2a000000,就是立即数42。
C/C++的代码中,这些数据一般对应字面量或者const、constexpr修饰的常量数据。
2、寄存器寻址
数据在寄存器中,这种寻址方式性能很高,因为寄存器都在CPU执行单元内部,访问它们很快。
在C/C++代码中,函数传递参数、返回结果、循环变量、使用register修饰的变量等都是存放在寄存器中,此外,表达式运算产生的中间结果一般也放在寄存器中。
3、内存直接寻址
数据在内存中,直接使用地址的绝对值访问它们,如mov eax, dword ptr [0x7fff324ce00c],从内存位置0x7fff324ce00c处读取4字节的数据。
在C/C++代码中,全局变量、静态变量、函数入口地址可能会用这种寻址方式,但是因为指令编码较长,可能会用下面的内存间接寻址方式,尤其是x86-64处理器的rip相对寻址方式。
4、内存间接寻址
这一类寻址方式最为丰富。
4.1、寄存器间接
形式:[寄存器],如[rax]
在C/C++代码中,指针使用*操作符解引用、通过this指针访问虚函数表地址时,都是这种形式的寻址。
4.2、基址+偏移量
形式:[寄存器±立即数偏移量],如[rbp-16]
也可以把寄存器间接寻址看作是这种寻址方式当偏移量为0时的特例,如[rax]即为[rax+0]
在C/C++中,访问局部变量、数组元素或者结构成员时常见这种寻址方式,常用于基址的寄存器多是rax、rbx、rbp、rsp,使用它们指令编码较短,在C++中,如果出现rdi作为基址寄存器,很可能是通过this指针在访问对象的数据成员。其中寄存器rbp用作访问函数栈帧的基址、rsp用作栈顶基址,差不多是所有编译器的标准用法了。
4.3、基址+变址
形式:[基址寄存器±变址寄存器] ,如[rbx+rsi]
用作基址寄存器常见有rbx、rbp,变址寄存器常见有rsi、rdi,当然所有寄存器都可以用作它们。
在C/C++中,使用下标变量来访问char、uint8_t等单字节数据组成的数组时,就是这种寻址方式,其中数组起始位置是基址寄存器,而下标是变址寄存器。
4.4、基址+变址因子
形式:[基址寄存器±变址寄存器立即数因子] ,立即数因子只能是2的次幂,如[rbx+rsi*4]
在C/C++中,使用下标变量来访问short、int、float等多字节数据组成的数组时,就是这种寻址方式,其中数组起始位置是基址寄存器,而下标是变址寄存器,立即数因子就是数组元素的长度,比如对于数组:int ar[],立即数因子就是sizeof(int)=4。
4.5、基址+变址因子+偏移量
形式:[基址寄存器±变址寄存器立即数因子±立即数偏移量] ,立即数因子只能是2的次幂,如[rbx+rsi*4]。
在C/C++中,使用下标变量来访问结构数组中某个结构中的数据成员,就是这种寻址方式,其中数组起始位置是基址寄存器,而下标是变址寄存器,因子就是结构的长度,偏移量是数据在结构中的偏移量。
4.6、基址+变址+偏移量
形式:[基址寄存器±变址寄存器±立即数偏移量] ,如[rbx+rsi+8]
在C/C++中,使用下标变量来访问结构数组中某个结构的数据成员,如果没有使用4.5的寻址方式(因为变址因子只能使用1、2、4、8等有限的几个值),就使用两条指令来寻址,先计算出变址*因子的值放在变址寄存器中,其中数组起始位置是基址寄存器,而下标位置就是变址寄存器,偏移量是数据在结构中的偏移量。
比如:
// size是16字节
struct pointer {int x; // 偏移量0int64_t z; // 偏移量8
};long foo(pointer a[], int x) {return a[x].z;
}
可以这样寻址:
foo(pointer*, int):movsx rsi, esisal rsi, 4 ; 单独计算变址的值mov rax, QWORD PTR [rsi+8+rdi]ret
也可以:
foo(pointer*, int):movsx rsi, esiadd rsi, rsi ; 翻倍,这样rsi*8就是rsi*16mov eax, DWORD PTR [rdi+rsi*8+8]ret 0
4.7、rip间接寻址
形式:[rip±立即数偏移量],比如[rip - 0x33538]
现代操作系统中,进程的内存布局模型都是flat平坦模式,即所有的代码和数据都不再分段管理,而是在同一个地址空间内统一编址,这样就使用指令指针寄存器rip来访问数据,在指令访问内存数据时,所执行的位置处(即RIP的值)加上和目标地址的距离——偏移量,就能访问到目标地址处的内存数据。在C、C++访问全局变量、static变量、动态加载的函数和全局变量时,都可以使用这种方式来寻址。
最后
虽然在前面我把数据分成了三部分进行说明,实际上它们三者是同时密切联系在一起的。在一条指令中,同时表示了这三部分的信息,比如下面的指令:
add edx, DWORD PTR [rdi+4+rsi*8]
1、源数据位于内存中,是一个“基址+变址*因子+偏移量”的寻址方式,位置是经过基址寄存器rdi和变址寄存器rsi运算后的内存地址,数据长度是4字节(dword ptr指示),而地址数据存放在寄存器rdi中,它的长度是8字节,相当于rdi对应C/C++中的指针类型;
2、目的数据位于寄存器edx中,它的长度是4字节
3、指令操作符是add,是算数加法操作,因此源数据和目的数据都是整型数,但是有符号还是无符号数仍不知道。
差不多是类似于下面形式的C/C++代码结构:
struct strct {int x;int z;
};.....
strct ar[M];
int index;
int sum;
...
sum += ar[index].z;
其中ar是一个结构数组,rdi=&ar,rsi=index,edx=sum。