【RL系列】ReTool: Reinforcement Learning for Strategic Tool Use in LLMs
1. 简介
提出了ReTool,具体contributions:
- 在LLM推理过程中集成了code interpreter execution。并基于自己开发的pipeline构建一批冷启动数据集。
- 在全面的实验后,有几个关键发现:
- 在RL训练后,回复长度相较于开始较少了40%。
- 在训练中,code ratio,code lines和correct code counts都有增加。并且代码调用时间变得更早。
- 在训练中发现有代码自我纠正和自适应工具选择等突发行为,带来tool-augmented reasoning pattern。
2. 方法
2.1 Overview:
训练主要分为两部:
- 通过设计的pipeline搜集一批数据用于cold start SFT。
- tool-using RL训练。
2.2 cold start for tool-integrated reasoning foundation
- 数据搜集:
- 聚合不同数据源的mathematical reasoning数据,然后使用人类专家和deepseek-r1过滤质量低的数据;
- 通过结构化的prompt template(见下图)对过滤后mathematical reasoning数据进行替换,它通过用相应的代码片段及其解释器的执行结果替换可以从代码执行中受益的手动计算步骤,从而修改了原始的思维过程;然后进行format and answer verification(最终答案不对)

- 基于上一步搜集的数据进行SFT(cold start)。
2.3 ReTool:Reinforcement Learning for Strategic Tool Use
- RL Algorithm:PPO,在训练中policy model会结合code sandbox的多轮实时代码执行操作的结果用于生成rollouts。
- Reward Design:详细公式见下图
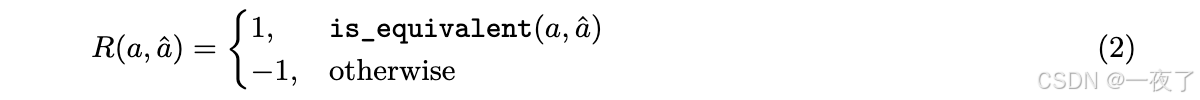
- Rollout with interleaved code execution:
- rollout生成是用带一个code sandbox的policy model,会包含text,code snippets和real-time interpreter feedback。在具体的prompt中(见下图),会用
标记生成的code。在rollout过程中,policy modle生成text-based reasoning,当被检测到,生成暂停,生成的代码会被解析并传到code sandbox中去执行,执行完成后,执行结果会被包在中,然后继续生成,直到提供final answer或一个新的code snippet。最终的轨迹是:text-based reasoning + code + sandbox feedback + …+ final answer

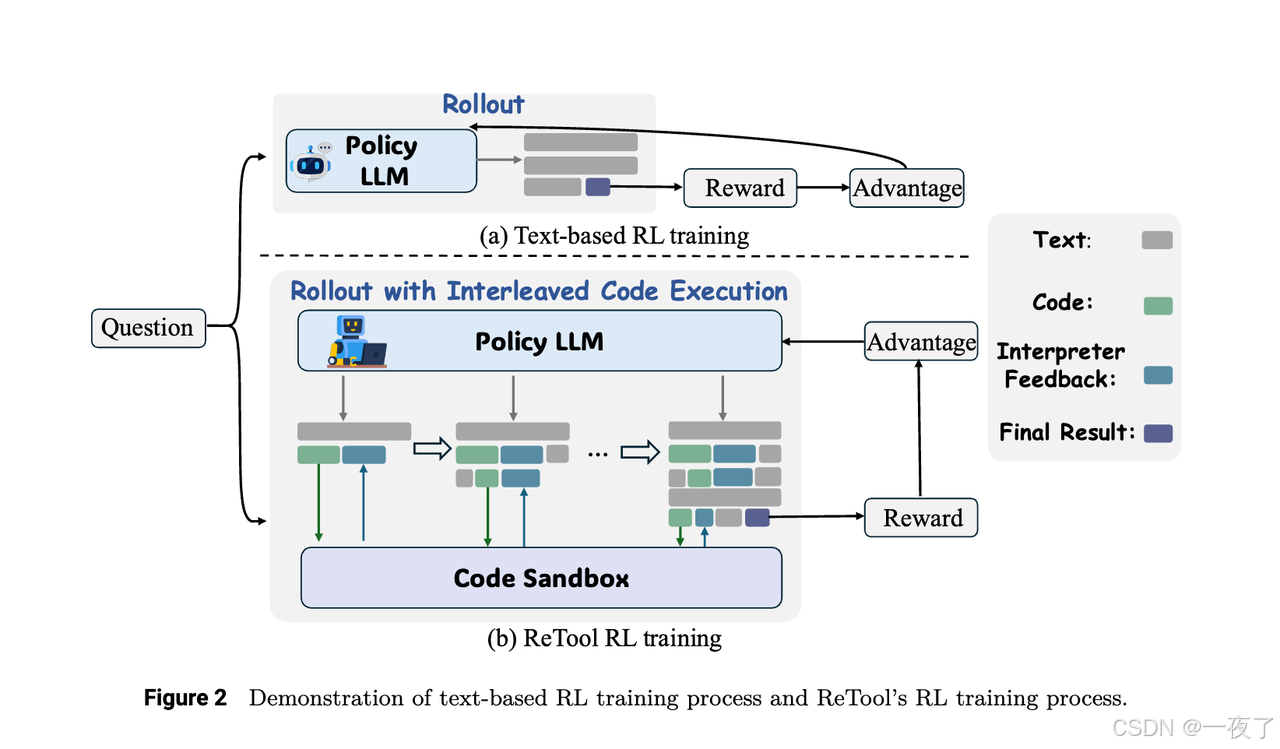
- rollout生成是用带一个code sandbox的policy model,会包含text,code snippets和real-time interpreter feedback。在具体的prompt中(见下图),会用
- 训练细节:
- 在训练中,loss计算会maskfeedback output
- 在训练中增加KV-cache:当被监测到,在code执行前会cache所有的KV-cache
- Sandbox Construction:为了加速训练过程,沙盒是异步的。
3. 实验
-
Setting:
- 使用VeRL框架
- 算法:PPO
- AdamW
- LR:1e-6
- expected maximum:16384
- mini-batch size:512
- KL coefficient:0
- backbone:Qwen2.5-32B-Instruct
-
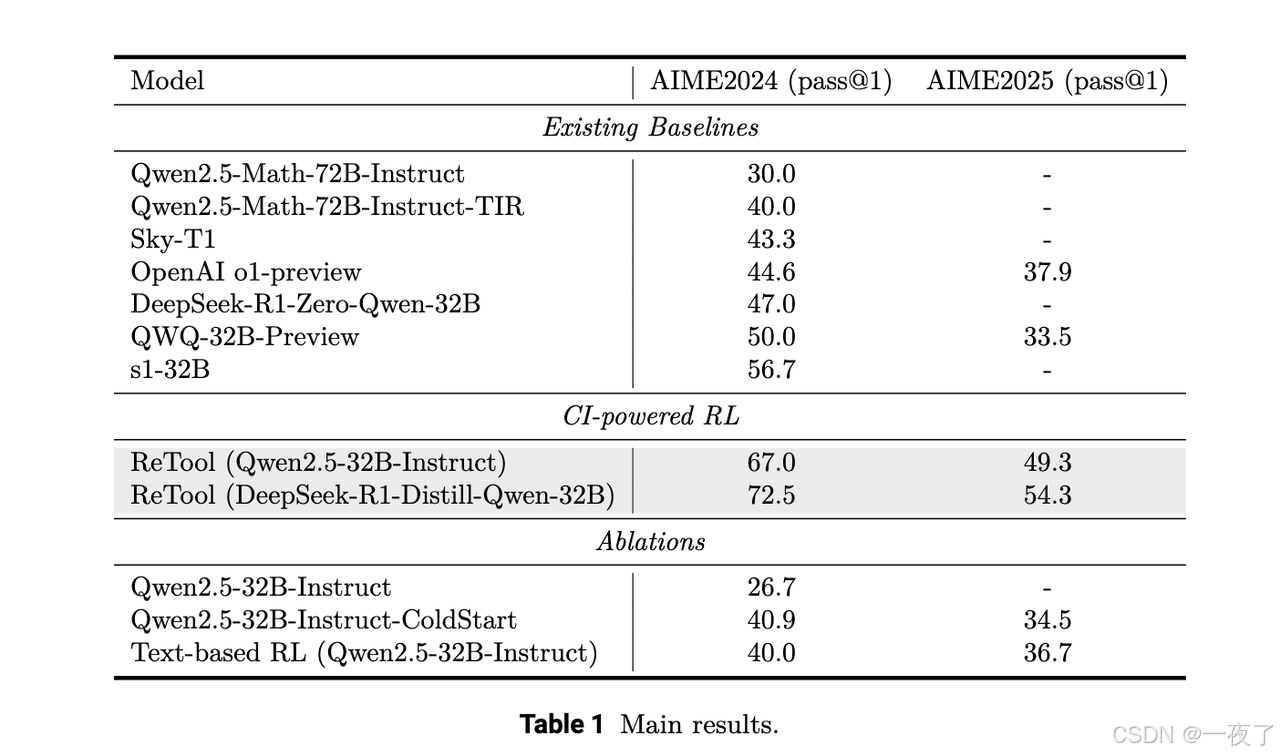
Main Results
-
Cognitive Analysis:
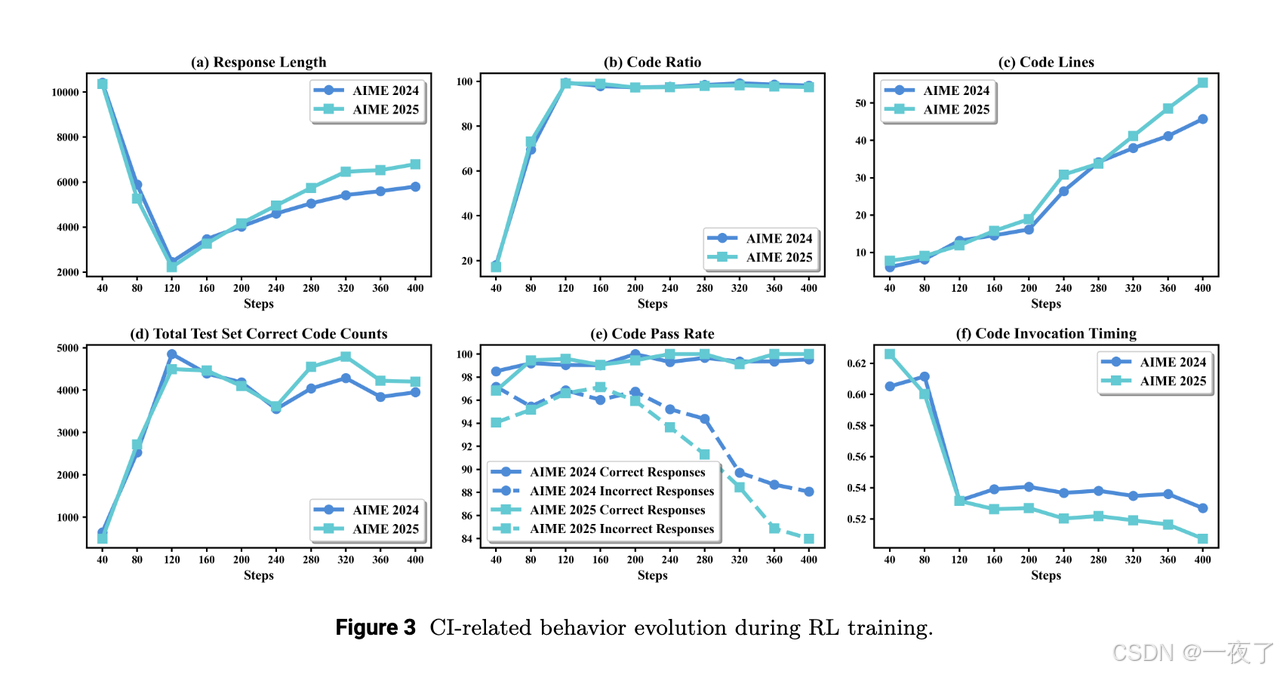
- response length:初始下降,后面增加,最终回复长度平均下降40%。
- code ratio:回复中包含code的占比是增加的。最后占比98%。
- code lines:生成代码行数(一定程度反映生成代码的复杂度)增加,在训练结束时,代码行数是初始的5倍。
- Total Test Set Correct Code Counts:测试集上的总正确代码数是增加的。
- Code Pass Rate:在正确回复中,最后一个代码通过比例不断升高。在错误回复中,最后一个代码通过率不断下降。说明代码执行结果影响推理过程和最后结果。
- Code Invocation Timing:计算代码调用时间。决定于代码起始位置 / 回复总长度。这个指标反映response中代码调用时间。

4. 总结
- 训练过程和目前开源的一些tool-based RL框架实现的基本差不多,主要区别是ReTool只调用了code interpreter execution。其他框架调用的工具会更多点。然后就是一些标签不一样,这里用的是<code></code> ,<interpreter></interpreter>,有些框架用的是<action></action>,<obversation></observation>,本质上是一样的。
- reward包含format reward和outcome reward,没有process-supervised reward。且outcome reward也比较简单。
- 在RL训练前,会有一个cold start阶段(SFT)。
- 会有一个数据构建的pipeline。
- 训练中会有多个监测指标,比如说回复长度(下降,整体降40%),code ratio(占比增加,最后98%),code lines(增加,最后是初始5倍)等。