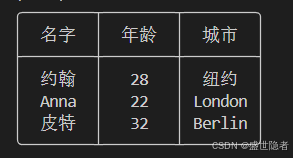
当前位置: 首页 > news >正文 支持中文对齐的命令行表格打印python库——tableprint news 2025/4/26 17:09:32 文章目录 快速入门 还在为表格中含有中文,命令行打印无法对齐而苦恼吗? 还在为冗长的数据添加代码而抓狂吗? tableprint来了!!!,它完美的解决了上述两个问题,快来试试吧!🚀🚀🚀 快速入门 安装pip install tableprint 快速使用import tableprint as tptp.table([["约翰", 28, "纽约"],["Anna", 22, "London"],["皮特", 32, "Berlin"],],["名字", "年龄", "城市"],align='center' ) 输出效果: 查看全文 http://www.xdnf.cn/news/34795.html 相关文章: cesium中postProcessStages全面解析 13.第二阶段x64游戏实战-分析人物等级和升级经验 JNI 学习 Linux基础IO(九)之软链接 洛谷P3373线段树详解【模板】 QML动画--ParticleSystem 构造函数和析构函数 数据结构排序算法全解析:从基础原理到实战应用 LabVIEW 程序维护:为何选靠谱团队? C# 变量||C# 常量 Linux教程-常用命令系列一 定制一款国密浏览器(10):移植SM2算法前,解决错误码的定义问题 如何实现一个MCP server呢? 基于蚁群算法的柔性车间调度最优化设计 mysql的函数(第二期) Linux下 文件的查找、复制、移动和解压缩 spring-batch批处理框架(1) Qt项目——Tcp网络调试助手服务端与客户端 时态--06--现在完成時 GPT-SoVITS 使用指南 【概率论】条件期望 【网络原理】UDP协议 下采样(Downsampling) stm32(gpio的四种输出) c++:线程(std::thread) java怎么找bug?Arthas原理与实战指南 opencv图像旋转(单点旋转的原理) 中国AIOps行业分析 [dp19_01背包] 目标和 | 最后一块石头的重量 II AUTOSAR图解==>AUTOSAR_SWS_IntrusionDetectionSystemManager
文章目录 快速入门 还在为表格中含有中文,命令行打印无法对齐而苦恼吗? 还在为冗长的数据添加代码而抓狂吗? tableprint来了!!!,它完美的解决了上述两个问题,快来试试吧!🚀🚀🚀 快速入门 安装pip install tableprint 快速使用import tableprint as tptp.table([["约翰", 28, "纽约"],["Anna", 22, "London"],["皮特", 32, "Berlin"],],["名字", "年龄", "城市"],align='center' ) 输出效果: