数据结构排序算法全解析:从基础原理到实战应用
在计算机科学领域,排序算法是数据处理的核心技术之一。无论是小规模数据的简单整理,还是大规模数据的高效处理,选择合适的排序算法直接影响着程序的性能。本文将深入解析常见排序算法的核心思想、实现细节、特性对比及适用场景,帮助读者全面掌握这一关键技术。
一、排序的本质与应用场景
1. 排序的定义
排序是将一组记录按照某个关键字的大小,按递增或递减顺序排列的过程。例如,将数组[5,3,9,6,2]排序为[2,3,5,6,9],本质上是通过关键字(这里是数值大小)重新组织数据的顺序。
2. 实际应用场景
- 电商平台:按价格、销量、评论数对商品进行排序,提升用户体验。
- 数据库系统:对查询结果排序以满足用户需求(如 “按时间倒序”)。
- 科学计算:预处理数据以加速后续分析(如统计、机器学习模型训练)。
- 竞赛与算法题:排序是解决复杂问题的基础(如贪心、动态规划的前置步骤)。
3.常见的排序算法
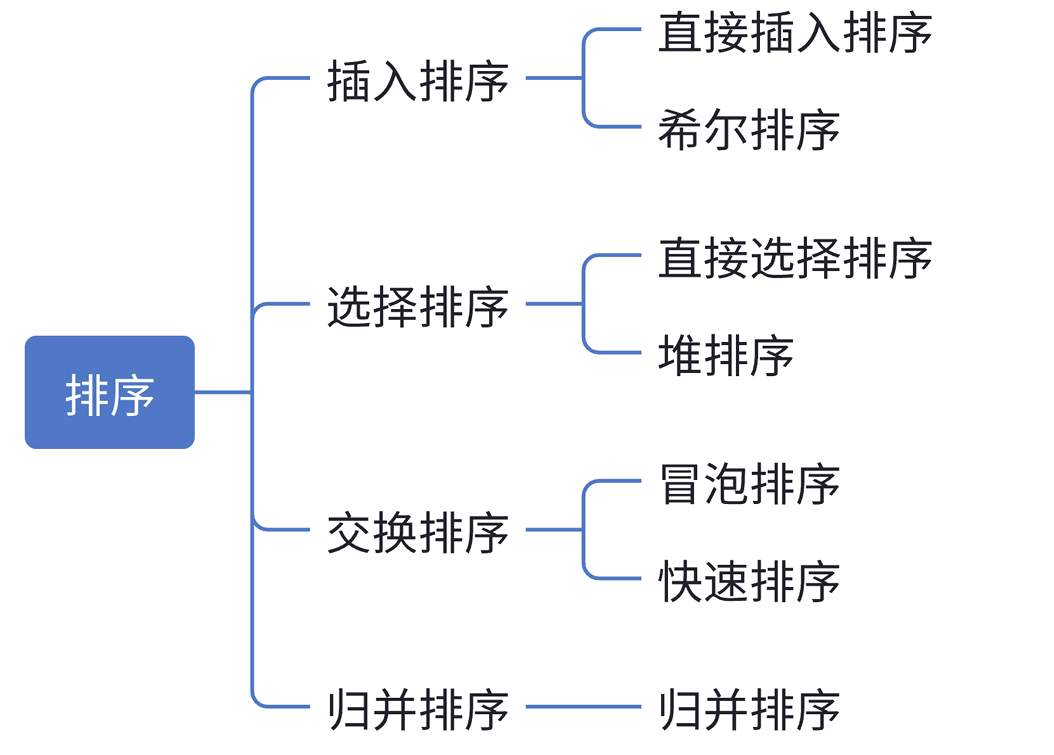
二、插入排序:增量构建有序序列
1. 直接插入排序(Straight Insertion Sort)
核心思想:
将未排序元素逐个插入已排序序列的合适位置,类似整理扑克牌时逐张插入手牌。每次从未排序区间取一个元素,与已排序区间的元素从后向前比较,找到合适位置后插入,后移沿途较大的元素。

算法步骤:
- 假设前 i 个元素已排序,取第 i+1 个元素作为待插入元素。
- 从已排序序列末尾向前搜索,找到第一个比待插入元素大的位置。
- 将该位置之后的元素后移一位,腾出空间插入待插入元素。
- 重复直至所有元素插入完成。
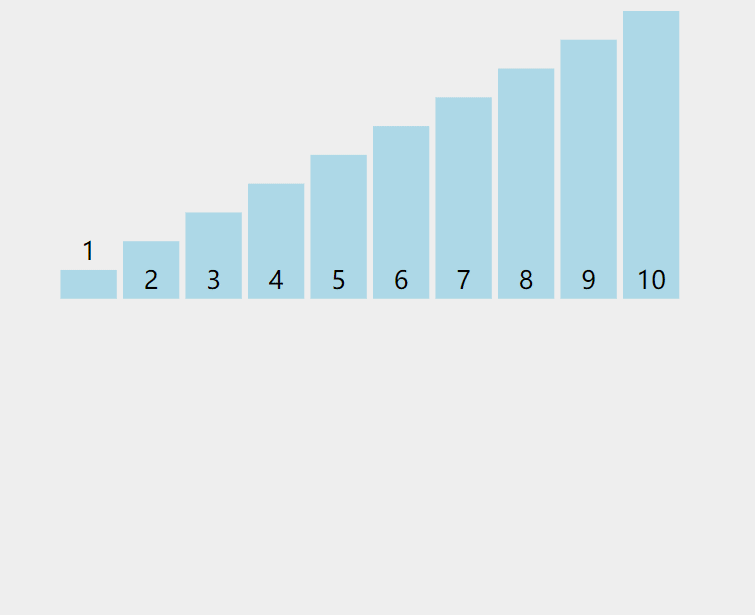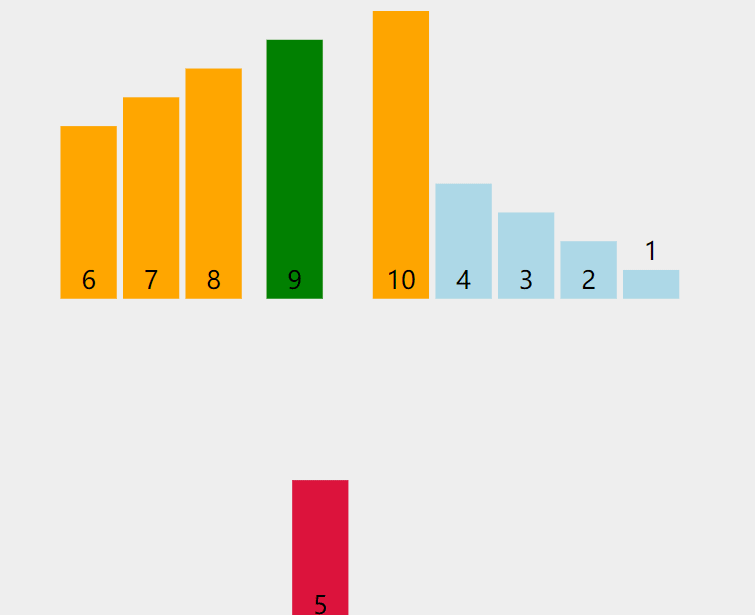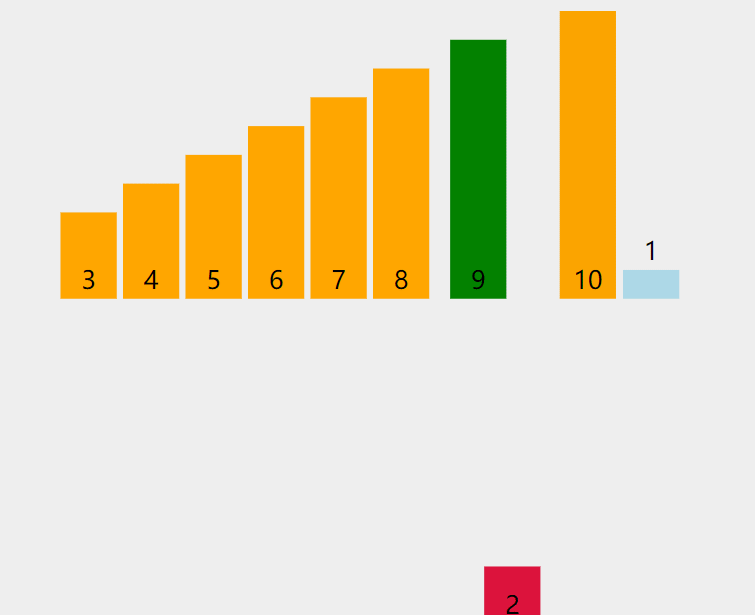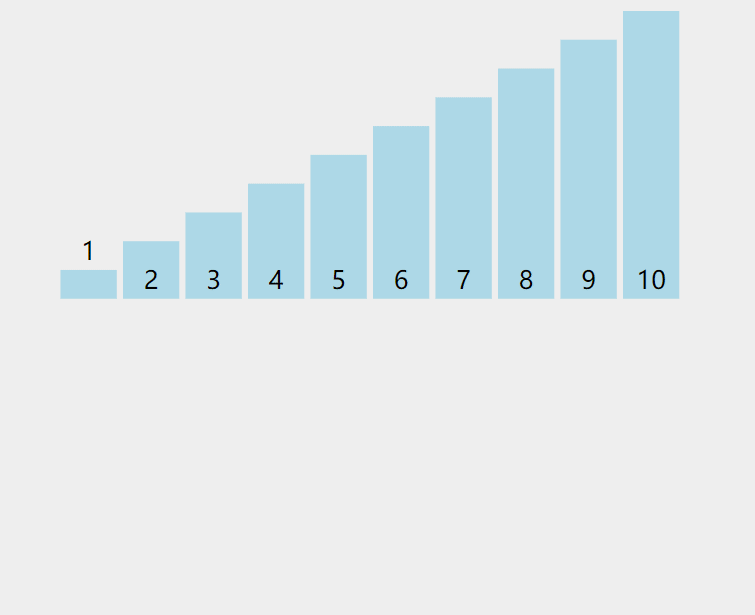
代码实现(C 语言):
void InsertSort(int* a, int n) {for (int i = 0; i < n - 1; i++) {int end = i; // 已排序区间末尾int tmp = a[end + 1]; // 待插入元素while (end >= 0 && a[end] > tmp) { // 向前搜索插入位置a[end + 1] = a[end]; // 元素后移end--;}a[end + 1] = tmp; // 插入到正确位置}
}特性分析:
- 时间复杂度:最好
O(n)(已有序),最坏 / 平均O(n^2)。 - 空间复杂度:
O(1)(原地排序)。 - 稳定性:稳定(相同元素保持原顺序)。
- 适用场景:小规模数据或近乎有序的数组(如有序度 > 80%)。
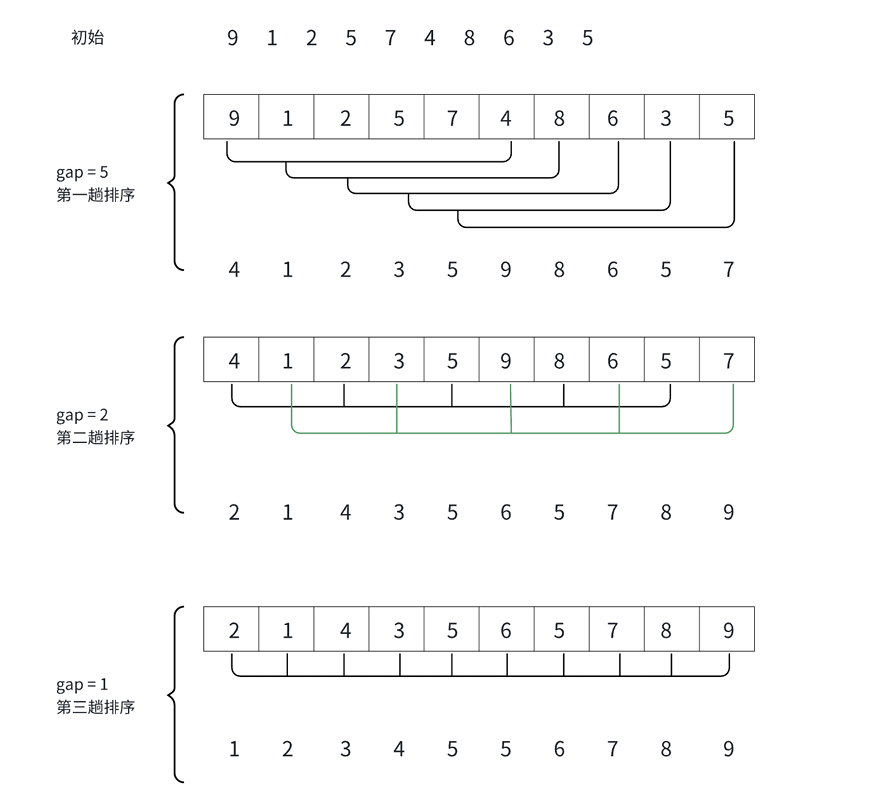
2. 希尔排序(Shell Sort)
核心思想:
通过 “增量序列” 将数组分组,对每组进行插入排序,逐步缩小增量至 1(退化为直接插入排序)。增量序列(如 gap = n/3 + 1)的设计是关键,通过分组预排序使数组更接近有序,提升最终插入效率。
算法步骤:
- 初始化增量
gap = n,通常取gap = n/2或gap = n/3 + 1。 - 按
gap分组(下标相差gap的元素为一组),对每组进行插入排序。 - 更新
gap = gap/3 + 1,重复直至gap = 1。
代码实现(C 语言):
void ShellSort(int* a, int n) {int gap = n; // 初始增量while (gap > 1) {gap = gap / 3 + 1; // 推荐增量序列for (int i = 0; i < n - gap; i++) { // 分组插入排序int end = i;int tmp = a[end + gap]; // 同组待插入元素while (end >= 0 && a[end] > tmp) {a[end + gap] = a[end]; // 组内元素后移end -= gap; // 组内指针前移}a[end + gap] = tmp; // 插入到组内正确位置}}
}特性分析:
- 时间复杂度:平均约
O(n^1.3),优于直接插入排序。 - 空间复杂度:
O(1)。 - 稳定性:不稳定(分组可能打乱相同元素顺序)。
- 适用场景:中等规模数组(
n=100~1000)。
三、选择排序:极值定位的直接策略
1. 直接选择排序(Straight Selection Sort)
核心思想:
每次从未排序区间选择最小(或最大)元素,与区间起点交换,逐步缩小未排序区间。
算法步骤:
- 遍历未排序区间
[i, n-1],记录最小元素下标min_idx。 - 若
min_idx不等于i,交换a[i]与a[min_idx]。 - 重复直至所有元素排序。
代码实现(C 语言):
void SelectSort(int* a, int n) {for (int i = 0; i < n - 1; i++) {int min = i;for (int j = i + 1; j < n; j++) { // 寻找最小值if (a[j] < a[min]) {min = j;}}if (min != i) { // 交换最小值到当前起点swap(&a[i], &a[min]);}}
}这样写效率不是很高,我们可以同时寻找最小值和最大值,寻找到最小值和最大值过后,将其交换到首尾节点,以此类推,这样每次搜索的范围就减少了一半,代码如下:
void SelectSort(int* arr, int n)
{int begin = 0;int end = n - 1;while (begin < end){int mini = begin;int maxi = begin;for (int i = begin + 1; i < end; i++){if (arr[i] < arr[mini]){mini = i;}if (arr[i] > arr[maxi]){maxi = i;}}if (maxi == begin){maxi = mini;}Swap(&arr[mini], &arr[begin]);Swap(&arr[maxi], &arr[end]);begin++;end--;}
}特性分析:
- 时间复杂度:固定
O(n^2)(无论数据是否有序)。 - 空间复杂度:
O(1)。 - 稳定性:不稳定(相同元素相对顺序可能改变)。
- 适用场景:仅用于教学演示,实际中极少使用。
2. 堆排序(Heap Sort)
核心思想:
利用堆(大顶堆 / 小顶堆)的性质,每次取出堆顶元素(最大值 / 最小值),调整堆结构直至排序完成。升序排序建大顶堆,降序建小顶堆。
算法步骤:
- 建堆:从最后一个非叶子节点开始,自底向上调整为大顶堆。
- 排序:交换堆顶与堆尾元素,堆大小减 1,向下调整堆顶,重复直至堆空。
关键代码(向下调整函数):
void AdjustDown(int* a, int n, int parent) {int child = parent * 2 + 1; // 左孩子下标while (child < n) {if (child + 1 < n && a[child + 1] > a[child]) { // 选较大的孩子child++;}if (a[child] > a[parent]) { // 交换父子节点swap(&a[child], &a[parent]);parent = child; // 继续向下调整child = parent * 2 + 1;} else {break; // 已满足堆性质}}
}void HeapSort(int* a, int n) {// 建大顶堆for (int i = n/2 - 1; i >= 0; i--) {AdjustDown(a, n, i);}// 排序过程for (int i = n - 1; i > 0; i--) {swap(&a[0], &a[i]); // 交换堆顶与堆尾AdjustDown(a, i, 0); // 调整剩余堆}
}
除了向下建堆外还可以采用向上建堆,代码如下:
void HPjustUp(HPDataType* arr,int child)
{int parent = (child - 1) / 2;while (child>0){if (arr[child] < arr[parent]){Swap(&arr[child], &arr[parent]);child = parent;parent = (child - 1) / 2;}else{break;}}
}特性分析:
- 时间复杂度:始终
O(n log n)(建堆O(n),每次调整O(log n))。 - 空间复杂度:
O(1)(原地排序)。 - 稳定性:不稳定(堆调整可能交换相同元素)。
- 适用场景:大规模数据且内存受限(如嵌入式设备)。
四、交换排序:通过元素交换实现全局有序
1. 冒泡排序(Bubble Sort)
核心思想:
相邻元素比较,逆序则交换,使较大元素逐步 “冒泡” 到数组末尾。通过标志位优化可提前终止(若某轮无交换,说明已有序)。
算法步骤:
- 遍历数组,比较相邻元素,前大于后则交换。
- 每轮最大元素到达末尾,未排序区间缩小 1。
- 若某轮无交换,提前终止。
优化代码实现:
void BubbleSort(int* a, int n) {for (int i = 0; i < n; i++) {int exchange = 0; // 标志位判断是否有序for (int j = 0; j < n - i - 1; j++) {if (a[j] > a[j + 1]) {swap(&a[j], &a[j + 1]);exchange = 1;}}if (!exchange) break; // 已有序,提前结束}
}
特性分析:
- 时间复杂度:最好
O(n),最坏 / 平均O(n²)。 - 空间复杂度:
O(1)。 - 稳定性:稳定(相同元素保持原顺序)。
- 适用场景:小规模数据或教学演示。
2. 快速排序(Quick Sort)
2.1递归法实现快速排序
核心思想:
分治策略,选择基准值(Pivot),将数组划分为左(<基准)、中(= 基准)、右(> 基准)三部分,递归排序左右子数组。
三种分区实现:
- Hoare 版本(左右指针法):右指针先找小,左指针找大,交换直至相遇,基准值归位。
- 选左端点为基准值,左右指针
left、right分别指向基准值下一个位置和右端点。 right先向左找小于基准的元素,left向右找大于基准的元素,交换两者,直至left >= right。- 交换基准值与
right位置元素,返回基准最终下标。
代码实现
int QuickSort_Find(int* arr, int left, int right)
{int keyi = left; // 基准值left++;while (left <= right){while (left <= right && arr[keyi] < arr[right])// 右指针先找小{right--;}while (left <= right && arr[keyi] > arr[left]) // 左指针找大{left++;}if (left <= right){Swap(&arr[left++], &arr[right--]);// 交换左右找到的逆序对}}Swap(&arr[keyi], &arr[right]);// 基准值归位return right;// 返回基准下标
}void QuickSort(int* arr, int left, int right)
{if (left >= right){return;}int keyi = QuickSort_Find1(arr, left, right);QuickSort(arr, left, keyi-1);QuickSort(arr, keyi+1, right);
}- 挖坑法:基准值形成 “坑”,左右指针交替填充,最终填入基准值。
创建左右指针。首先从右向左找出比基准小的数据,找到后立即放入左边坑中,当前位置变为新 的"坑",然后从左向右找出比基准大的数据,找到后立即放入右边坑中,当前位置变为新的"坑",结束循环后将最开始存储的分界值放入当前的"坑"中,返回当前"坑"下标(即分界值下标)
- 选左端点为基准值,记录为
key,形成 “坑” 位置left。 right向左找小于key的元素,填入坑位,新坑为right。left向右找大于key的元素,填入新坑,新坑为left。- 重复直至
left == right,填入key,返回坑位下标。

- 前后指针法(Lomuto):前指针标记小于基准的末尾,后指针遍历交换,基准值与前指针交换。
创建前后指针,从左往右找比基准值小的进行交换,使得小的都排在基准值的左边。
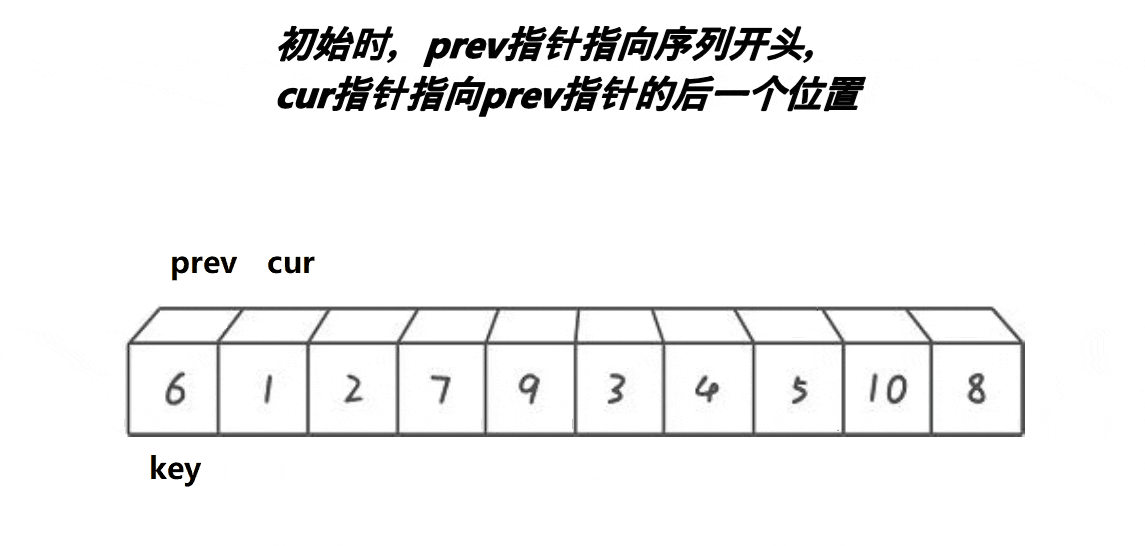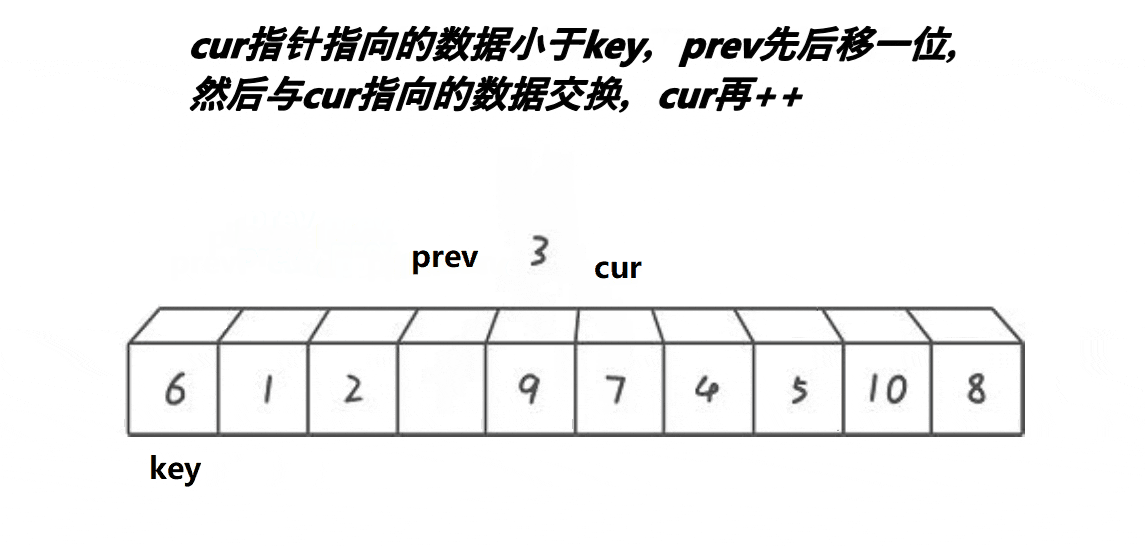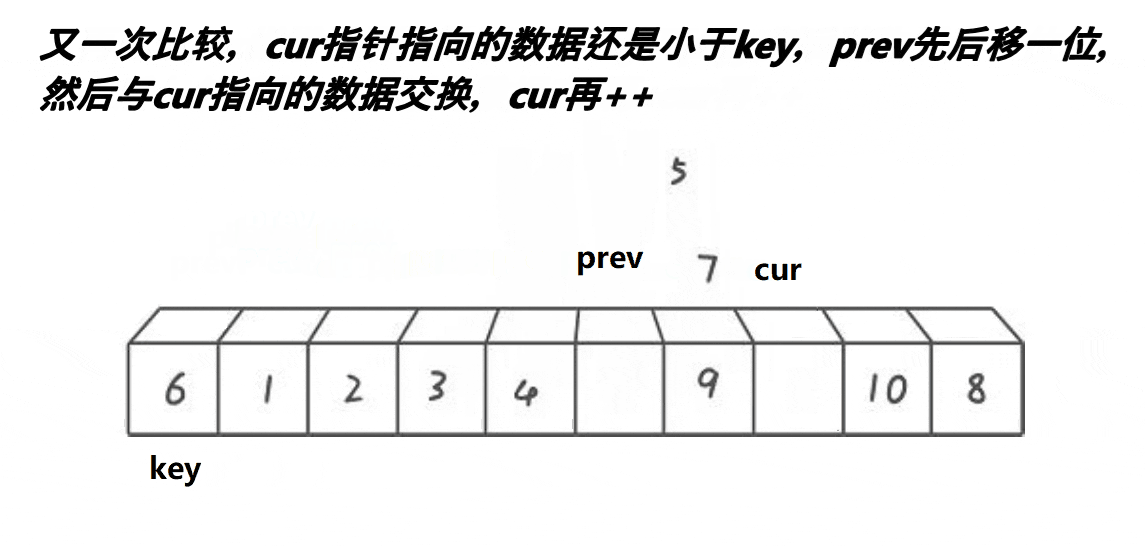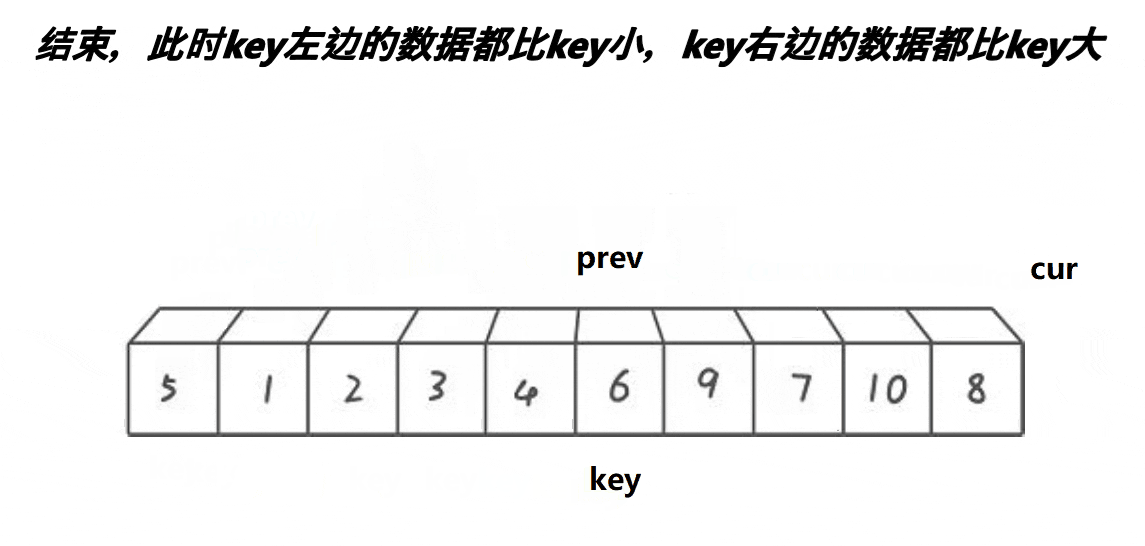
代码实现:
int QuickSort_Find(int* arr, int left, int right)
{int keyi = left;int prev = left;int cur = prev + 1;while (cur <= right){if (arr[cur] < arr[keyi] && ++prev != cur){Swap(&arr[prev], &arr[cur]);}cur++;}Swap(&arr[keyi], &arr[prev]);return prev;
}
void QuickSort(int* arr, int left, int right)
{if (left >= right){return;}int keyi = QuickSort_Find(arr, left, right);QuickSort(arr, left, keyi-1);QuickSort(arr, keyi+1, right);
}2.2迭代法实现快速排序
快速排序的递归实现简洁高效,但在处理大规模数据时可能因递归深度过大导致栈溢出(如最坏情况下递归深度达 O(n))。迭代实现通过显式使用栈(Stack)模拟递归过程,避免了这一问题,更适合工程环境中的稳健性要求。以下是基于 Lomuto 分区方案(前后指针法)的迭代实现详解。
1. 核心思想:栈模拟递归分区
- 递归转迭代:
递归版本中,每次分区后自动压栈(系统栈)处理左右子区间;迭代版本需手动维护一个栈,显式存储待排序的区间[left, right]。 - 栈操作逻辑:
- 初始时将整个数组区间
[begin, end]压栈(注意栈的后进先出特性,先压右端点,再压左端点)。 - 循环取栈顶区间,进行分区操作,得到基准位置
keyi。 - 将左右子区间(若有效)压栈,继续处理直至栈空。
- 初始时将整个数组区间
2. 算法步骤(基于 Lomuto 分区)
- 初始化栈:压入初始区间
[left, right](注意顺序:先压右端点,再压左端点)。 - 循环处理栈内区间:
- 弹出栈顶元素,得到当前处理区间
[begin, end]。 - 执行分区操作(选择
begin为基准值,通过前后指针法划分区间)。 - 记录基准位置
keyi,将左右子区间(若长度大于 1)压栈(先压右子区间,再压左子区间,确保左子区间先处理)。
- 弹出栈顶元素,得到当前处理区间
- 分区逻辑:
prev指针标记小于基准值的末尾,初始为begin。cur指针从begin+1开始遍历,若arr[cur] < arr[begin],则prev++并交换arr[prev]与arr[cur]。- 遍历结束后,交换基准值
arr[begin]与arr[prev],使基准值归位。
3. 代码实现(C 语言,含栈结构体定义,完整代码见附录)
// 栈结构体定义(假设已实现基础栈操作)
typedef struct Stack {int* data;int top;int capacity;
} Stack;// 栈初始化、压栈、弹栈等函数(此处省略具体实现,需确保栈操作正确)
void StackInit(Stack* st);
void StackPush(Stack* st, int value);
int StackPop(Stack* st);
int StackTop(Stack* st);
bool StackEmpty(Stack* st);
void StackDestroy(Stack* st);void QuickSort(int* arr, int left, int right)
{Stack ST;StackInit(&ST); // 初始化StackPush(&ST, right); // 先压右端点,再压左端点StackPush(&st, left);StackPush(&ST, left);while (!StackEmpty(&ST)){int begin = StackTop(&ST);// 取出左端点StackPop(&ST);int end = StackTop(&ST); // 取出右端点StackPop(&ST);int keyi = begin; // 基准值下标(左端点)int prev = begin;// 前指针:标记小于基准的末尾int cur = prev + 1; // 后指针:遍历未排序区间while (cur <= end){if (arr[cur] < arr[keyi] && ++prev != cur)// 发现更小元素,前指针右移,非自身时交换(避免无意义交换){Swap(&arr[prev], &arr[cur]);// 交换到prev位置}cur++;// 后指针继续右移}Swap(&arr[keyi], &arr[prev]); // 基准值归位到prev位置,此时arr[prev]是基准值// 压栈顺序:先右子区间,再左子区间(保证左子区间先被处理)// 右子区间:[prev+1, end]keyi = prev;if (keyi + 1 < end){StackPush(&ST, end);StackPush(&ST, keyi+1);}// 左子区间:[begin, prev-1]if (begin < keyi - 1){StackPush(&ST, keyi - 1);StackPush(&ST, begin);}}StackDestroy(&ST);// 释放栈内存
}4. 关键细节解析
- 栈容量初始化:
栈的初始容量可以根据数据规模设置(如right - left + 1),避免动态扩容带来的性能损耗。 - 分区优化:
- 代码中
if (prev != cur)避免了元素与自身交换(当cur追上prev时,交换无意义)。 - 基准值固定为左端点,实际工程中应添加 随机化基准值 逻辑(如随机选择基准并与左端点交换),避免最坏情况
O(n²)。
- 代码中
- 压栈顺序:
由于栈是后进先出,先压右子区间[prev+1, end],再压左子区间[begin, prev-1],确保左子区间先被处理(与递归的深度优先顺序一致)。
5. 迭代 vs 递归:优缺点对比
| 特性 | 递归实现 | 迭代实现 |
|---|---|---|
| 实现复杂度 | 简洁(系统栈自动管理区间) | 较复杂(需手动维护栈结构) |
| 栈溢出风险 | 高(最坏递归深度 O(n)) | 低(栈容量可控,或使用循环队列优化) |
| 空间效率 | 平均 O(log n)(系统栈) | 平均 O(log n)(用户栈,常数因子略大) |
| 调试难度 | 易(递归调用栈清晰) | 较难(需跟踪栈内区间状态) |
| 适用场景 | 小规模数据或教学演示 | 大规模数据或生产环境(稳健性优先) |
6. 工程优化建议
- 随机化基准值:
在分区前随机选择基准值,避免有序数组导致的最坏情况:// 随机化基准值(在分区前调用) int RandomPivot(int* arr, int begin, int end) {srand(time(NULL)); // 初始化随机种子(仅需调用一次)int pivot = begin + rand() % (end - begin + 1); // 生成[begin, end]随机下标Swap(&arr[begin], &arr[pivot]); // 交换到左端点,作为基准值return begin; } - 小规模区间切换插入排序:
当区间长度小于阈值(如 16)时,切换为插入排序,减少递归 / 迭代开销:#define INSERTION_SORT_THRESHOLD 16if (end - begin + 1 <= INSERTION_SORT_THRESHOLD) {InsertSort(arr + begin, end - begin + 1); // 插入排序子数组continue; } - 尾递归优化:
迭代实现本质是尾递归优化的结果,确保每次仅处理一个子区间,另一个子区间通过栈延迟处理,减少栈空间占用。
迭代实现的快速排序通过显式栈管理,在保持平均 O(n log n) 效率的同时,避免了递归栈溢出的风险,是生产环境中的可靠选择。理解其核心逻辑(栈模拟递归、分区策略、基准值优化)能帮助我们更好地应对大规模数据排序需求。结合随机化基准值和插入排序切换等优化,迭代快排能在工程中发挥出卓越的性能。
特性分析
- 时间复杂度:平均
O(n log n),最坏O(n²)(可通过随机化基准值优化)。 - 空间复杂度:递归栈平均
O(log n),最坏O(n)(非递归实现可避免栈溢出)。 - 稳定性:不稳定(相同元素可能跨区交换)。
- 适用场景:大规模数据的通用排序(工程首选,平均效率最高)。
五、归并排序:稳定排序的分治方案
核心思想:
分治策略,递归分解数组为子数组,排序后合并(二路归并),确保合并后的数组有序。合并时借助临时数组存储中间结果。
算法步骤:
- 分解:递归将数组分成左右两半,直至子数组长度为 1(已有序)。
- 合并:双指针遍历左右子数组,按顺序合并到临时数组,再拷贝回原数组。
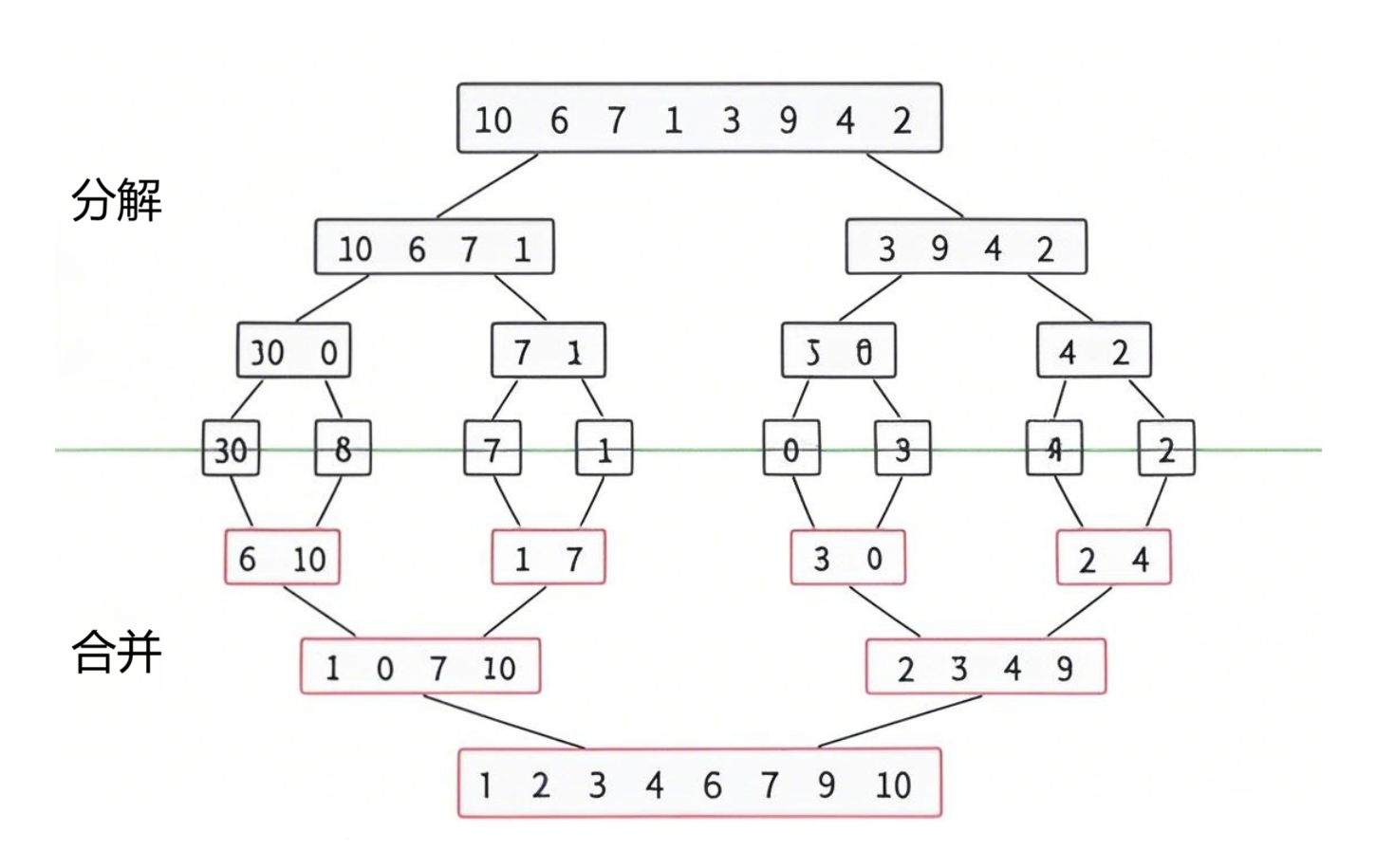
合并逻辑(关键函数):
void _MergeSort(int* arr, int left, int right, int* tmp)
{if (left >= right) //分解数组{return;}int mid = (left + right) / 2;_MergeSort(arr, left, mid, tmp);_MergeSort(arr, mid+1, right, tmp);int begin1 = left, end1 = mid;int begin2 = mid + 1, end2 = right;int index = begin1;while (begin1 <= end1 && begin2 <= end2) // 合并左右子数组{if (arr[begin1] > arr[begin2]){tmp[index++] = arr[begin2++];}else{tmp[index++] = arr[begin1++];}}while (begin1 <= end1){tmp[index++] = arr[begin1++];}while (begin2 <= end2){tmp[index++] = arr[begin2++];}memcpy(&arr[left], &tmp[left], sizeof(int) * (right - left + 1)); // 拷贝回原数组
}
void MergeSort(int* a, int n) {int* tmp = (int*)malloc(n * sizeof(int));_MergeSort(a, 0, n - 1, tmp); // 递归分解free(tmp);
}
特性分析:
- 时间复杂度:始终
O(n log n)(不依赖数据初始状态)。 - 空间复杂度:
O(n)(需要临时数组)。 - 稳定性:稳定(合并时保留相同元素原顺序)。
- 适用场景:稳定性要求高的场景(如多关键字排序)或链表排序。
六、非比较排序:计数排序(Counting Sort)
核心思想:
利用统计频率的方式,将元素按值出现的次数直接映射到目标位置,适用于值域范围较小的整数排序。
算法步骤:
- 确定值域:找到最小值
min和最大值max,计算范围range = max - min。 - 统计频率:创建计数数组
count,记录每个值的出现次数。 - 回填数组:按值从小到大,根据计数次数将元素填回原数组,保证稳定性。
代码实现:
void CountSort(int* arr, int n)
{int max = arr[0];int min = arr[0];int i = 1;while (i < n) // 找值域范围{if (arr[i] > max){max = arr[i];}if (arr[i] < min){min = arr[i];}i++;}int range = max - min + 1;int* count = (int*)calloc(range, sizeof(int)); // 初始化计数数组if (count == NULL){perror("calloc fail");exit(1);}for (i = 0; i < n; i++) // 统计频率{count[arr[i] - min]++;}int index = 0;for (i = 0; i < range; i++) // 按值顺序回填{while (count[i]--){arr[index++] = i + min;}}}
特性分析:
- 时间复杂度:o(n+range)(
k为值域范围,线性时间)。 - 空间复杂度:o(range)(依赖值域,稀疏数据可能浪费空间)。
- 稳定性:稳定(按值顺序填充,保留原顺序)。
- 适用场景:值域小的整数排序(如 0-100 分成绩排序)。
七、算法对比与选型指南
| 算法 | 时间复杂度 | 空间复杂度 | 稳定性 | 典型场景 |
|---|---|---|---|---|
| 直接插入排序 | O (n²)(平均) | O(1) | 稳定 | 小规模 / 近乎有序数组 |
| 希尔排序 | O (n^1.3)(平均) | O(1) | 不稳定 | 中等规模数组 |
| 堆排序 | O (n log n)(固定) | O(1) | 不稳定 | 大规模数据 / 内存受限场景 |
| 快速排序 | O (n log n)(平均) | O(log n) | 不稳定 | 通用大规模排序(首选) |
| 归并排序 | O (n log n)(固定) | O(n) | 稳定 | 稳定性要求高 / 链表排序 |
| 计数排序 | O (n + k)(线性) | O(k) | 稳定 | 值域小的整数排序(k 较小) |
注:稳定性是假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排序算法是稳定的;否则称为不稳定的。
选型建议
- 小规模数据:直接插入排序(简单高效,近乎有序时最优)。
- 大规模数据:
- 优先快速排序(平均效率最高,需随机化基准值防最坏情况)。
- 稳定性优先选归并排序,内存紧张选堆排序。
- 特殊场景:
- 整数且值域小:计数排序(线性时间,如成绩、年龄排序)。
- 链表排序:归并排序(无需随机访问,递归更自然)。
结语
排序算法是数据结构的核心基础,每种算法都体现了不同的设计思想:插入排序的增量构建、快速排序的分治分区、计数排序的统计映射等。理解它们的核心逻辑、复杂度特性及适用场景,是在实际开发中做出正确选择的关键。从基础的 O(n²) 算法到高效的 O(n log n) 算法,再到突破比较限制的线性排序,排序算法的演进史也是计算机科学优化思维的缩影。掌握这些知识,不仅能写出更高效的代码,还能培养 “根据问题特性选择合适工具” 的工程思维。
附录
1.比较相同数据各排序算法运行时间的代码
//test.c
void TestOP()
{srand(time(0));const int N = 200000;int* a1 = (int*)malloc(sizeof(int) * N);int* a2 = (int*)malloc(sizeof(int) * N);int* a3 = (int*)malloc(sizeof(int) * N);int* a4 = (int*)malloc(sizeof(int) * N);int* a5 = (int*)malloc(sizeof(int) * N);int* a6 = (int*)malloc(sizeof(int) * N);int* a7 = (int*)malloc(sizeof(int) * N);int* a8 = (int*)malloc(sizeof(int) * N);for (int i = 0; i < N; ++i){a1[i] = rand();a2[i] = a1[i];a3[i] = a1[i];a4[i] = a1[i];a5[i] = a1[i];a6[i] = a1[i];a7[i] = a1[i];a8[i] = a1[i];}int begin1 = clock();InsertSort(a1, N);int end1 = clock();int begin2 = clock();ShellSort(a2, N);int end2 = clock();int begin3 = clock();SelectSort(a3, N);int end3 = clock();int begin4 = clock();HeapSort(a4, N);int end4 = clock();int begin5 = clock();QuickSort(a5, 0, N - 1);int end5 = clock();int begin6 = clock();MergeSort(a6, N);int end6 = clock();int begin7 = clock();BubbleSort(a7, N);int end7 = clock();int begin8 = clock();CountSort(a8, N);int end8 = clock();printf("InsertSort:%d\n", end1 - begin1);printf("ShellSort:%d\n", end2 - begin2);printf("SelectSort:%d\n", end3 - begin3);printf("HeapSort:%d\n", end4 - begin4);printf("QuickSort:%d\n", end5 - begin5);printf("MergeSort:%d\n", end6 - begin6);printf("BubbleSort:%d\n", end7 - begin7);printf("CountSort:%d\n", end8 - begin8);free(a1);free(a2);free(a3);free(a4);free(a5);free(a6);free(a7);free(a8);
}2.栈的代码
//Stack.h
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>
// 支持动态增长的栈
typedef int STDataType;
typedef struct Stack
{STDataType* arr;int top; // 栈顶int capacity; // 容量
}Stack;
// 初始化栈
void StackInit(Stack* ps);
// 入栈
void StackPush(Stack* ps, STDataType data);
// 出栈
void StackPop(Stack* ps);
// 获取栈顶元素
STDataType StackTop(Stack* ps);
// 获取栈中有效元素个数
int StackSize(Stack* ps);
// 检测栈是否为空,如果为空返回非零结果,如果不为空返回0
bool StackEmpty(Stack* ps);
// 销毁栈
void StackDestroy(Stack* ps);
//Stack.c
#define _CRT_SECURE_NO_WARNINGS 1
#include"Stack.h"
// 初始化栈
void StackInit(Stack* ps)
{ps->arr = NULL;ps->capacity = ps->top = 0;
}
// 入栈
void StackPush(Stack* ps, STDataType data)
{assert(ps);if (ps->capacity == ps->top){int newcapacity = ps->capacity == 0 ? 4 : 2 * ps->capacity;STDataType* tmp = (STDataType*)realloc(ps->arr, newcapacity * sizeof(STDataType));if (tmp == NULL){perror("realloc fail");exit(1);}ps->arr = tmp;ps->capacity = newcapacity;}ps->arr[ps->top++] = data;}
// 检测栈是否为空,如果为空返回非零结果,如果不为空返回0 bool StackEmpty(Stack* ps)
{assert(ps);return ps->top == 0;
}
// 出栈
void StackPop(Stack* ps)
{assert(!StackEmpty(ps));--ps->top;
}
// 获取栈顶元素
STDataType StackTop(Stack* ps)
{assert(!StackEmpty(ps));return ps->arr[ps->top - 1];
}
// 获取栈中有效元素个数
int StackSize(Stack* ps)
{assert(!StackEmpty(ps));return ps->top;}
// 销毁栈
void StackDestroy(Stack* ps)
{if (ps->arr != NULL)free(ps->arr);ps->arr = NULL;ps->capacity = ps->top = 0;
}
3.所有排序算法的代码
//sort.h
#pragma once
#include<stdio.h>
#include<assert.h>
#include<stdlib.h>
#include<time.h>
#include<string.h>// 插入排序
void InsertSort(int* a, int n);// 希尔排序
void ShellSort(int* a, int n); //直接选择排序
void SelectSort(int*arr, int n);//堆排序
void HeapSort(int* arr, int n);//快速排序
void QuickSort(int* arr, int left, int right);//归并排序
void MergeSort(int* arr, int n);//冒泡排序
void BubbleSort(int* arr, int n);//计数排序
void CountSort(int* arr, int n);//Sort.c
#define _CRT_SECURE_NO_WARNINGS 1
#include"Sort.h"
#include"Stack.h"
void Swap(int* a, int* b)
{int tmp = *a;*a = *b;*b = tmp;
}
void InsertSort(int* arr, int n)
{for (int i = 0; i < n - 1; i++){int end = i;int tmp = arr[end + 1];while (end >= 0){if (arr[end] > tmp){arr[end + 1] = arr[end];end--;}else{break;}}arr[end + 1] = tmp;}
}
void ShellSort(int* arr, int n)
{int gap = n;while (gap > 1){gap = gap / 3 + 1;for (int i = 0; i < n - gap; i++){int end = i;int tmp = arr[end + gap];while (end >= 0){if (arr[end] > tmp){arr[end + gap] = arr[end];end -= gap;}else{break;}}arr[end+gap] = tmp;}}
}void SelectSort(int* arr, int n)
{int begin = 0;int end = n - 1;while (begin < end){int mini = begin;int maxi = begin;for (int i = begin + 1; i < end; i++){if (arr[i] < arr[mini]){mini = i;}if (arr[i] > arr[maxi]){maxi = i;}}if (maxi == begin){maxi = mini;}Swap(&arr[mini], &arr[begin]);Swap(&arr[maxi], &arr[end]);begin++;end--;}
}
void HPjustDown(int* arr, int parent, int n)
{int child = parent * 2 + 1;while (child < n){if (child + 1 < n && arr[child] > arr[child + 1]){child++;}if (arr[child] < arr[parent]){Swap(&arr[child], &arr[parent]);parent = child;child = parent * 2 + 1;}else{break;}}
}
void HeapSort(int* arr, int n)
{for (int i = (n - 2) / 2; i >= 0; i--){HPjustDown(arr, i, n);}int tmp = n - 1;while (tmp){Swap(&arr[0], &arr[tmp]);HPjustDown(arr, 0, tmp);tmp--;}
}
//int QuickSort_Find1(int* arr, int left, int right)
//{
// int keyi = left;
// left++;
// while (left <= right)
// {
// while (left <= right && arr[keyi] < arr[right])
// {
// right--;
// }
// while (left <= right && arr[keyi] > arr[left])
// {
// left++;
// }
// if (left <= right)
// {
// Swap(&arr[left++], &arr[right--]);
// }
// }
// Swap(&arr[keyi], &arr[right]);
// return right;
//}
//int QuickSort_Find2(int* arr, int left, int right)
//{
// int keyi = left;
// int prev = left;
// int cur = prev + 1;
// while (cur <= right)
// {
// if (arr[cur] < arr[keyi] && ++prev != cur)
// {
// Swap(&arr[prev], &arr[cur]);
// }
// cur++;
// }
// Swap(&arr[keyi], &arr[prev]);
// return prev;
//}
//void QuickSort(int* arr, int left, int right)
//{
// if (left >= right)
// {
// return;
// }
// int keyi = QuickSort_Find1(arr, left, right);
// QuickSort(arr, left, keyi-1);
// QuickSort(arr, keyi+1, right);
//}
void QuickSort(int* arr, int left, int right)
{Stack ST;StackInit(&ST);StackPush(&ST, right);StackPush(&ST, left);while (!StackEmpty(&ST)){int begin = StackTop(&ST);StackPop(&ST);int end = StackTop(&ST);StackPop(&ST);int keyi = begin;int prev = begin;int cur = prev + 1;while (cur <= end){if (arr[cur] < arr[keyi] && ++prev != cur){Swap(&arr[prev], &arr[cur]);}cur++;}Swap(&arr[keyi], &arr[prev]);keyi = prev;if (keyi + 1 < end){StackPush(&ST, end);StackPush(&ST, keyi+1);}if (begin < keyi - 1){StackPush(&ST, keyi - 1);StackPush(&ST, begin);}}StackDestroy(&ST);
}
void _MergeSort(int* arr, int left, int right, int* tmp)
{if (left >= right){return;}int mid = (left + right) / 2;_MergeSort(arr, left, mid, tmp);_MergeSort(arr, mid+1, right, tmp);int begin1 = left, end1 = mid;int begin2 = mid + 1, end2 = right;int index = begin1;while (begin1 <= end1 && begin2 <= end2){if (arr[begin1] > arr[begin2]){tmp[index++] = arr[begin2++];}else{tmp[index++] = arr[begin1++];}}while (begin1 <= end1){tmp[index++] = arr[begin1++];}while (begin2 <= end2){tmp[index++] = arr[begin2++];}//for (int i = left; i <= right; i++)//{// arr[i] = tmp[i];//}memcpy(&arr[left], &tmp[left], sizeof(int) * (right - left + 1));
}
void MergeSort(int* arr, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);_MergeSort(arr, 0, n - 1, tmp);free(tmp);
}
void BubbleSort(int* arr, int n)
{for (int i = 0; i < n; i++){for (int j = 0; j < n - i - 1; j++){if (arr[j] > arr[j + 1]){Swap(&arr[j + 1], &arr[j]);}}}
}
void CountSort(int* arr, int n)
{int max = arr[0];int min = arr[0];int i = 1;while (i < n){if (arr[i] > max){max = arr[i];}if (arr[i] < min){min = arr[i];}i++;}int range = max - min + 1;int* count = (int*)calloc(range, sizeof(int));if (count == NULL){perror("calloc fail");exit(1);}for (i = 0; i < n; i++){count[arr[i] - min]++;}int index = 0;for (i = 0; i < range; i++){while (count[i]--){arr[index++] = i + min;}}}