GPT-SoVITS 使用指南
一、简介
TTS(Text-to-Speech,文本转语音):是一种将文字转换为自然语音的技术,通过算法生成人类可听的语音输出,广泛应用于语音助手、无障碍服务、导航系统等场景。类似的还有SVC(歌声转换)、SVS(歌声合成)等。
GPT-SoVITS:是一个开源的TTS(文本到语音)项目,它是基于生成式预训练模型GPT(Generative Pre-trained Transformer)与语音克隆技术SoVITS(Speech-to-Video Voice Transformation System)结合的语音合成工具。这个项目允许用户仅通过少量的样本数据,例如1分钟的音频文件,就可以克隆声音。它支持将汉语、英语、日语三种语言的文本转为克隆声音,并且部署方便,训练速度快,效果显著。
项目地址:https://github.com/RVC-Boss/GPT-SoVITS
在线试用地址(各种游戏600多个角色):AI Hobbyist TTS
官方教程:GPT-SoVITS指南 · 语雀
二、入门指南
详细见官方教程:整合包教程 · 语雀
下载GPT-SoVITS:访问整合包及模型下载链接 · 语雀,下载整合包
解压缩:使用7-Zip解压缩压缩包
运行Web UI:双击go-webui.bat打开,不要以管理员身份运行!打开的bat不可以关闭!这个黑色的bat框就是控制台。
如下图所示,小黑框会显示网址并弹出网页,如果没有弹出网页可以复制http://localhost:9874/到浏览器打开

素材准备:我这里是从喜马拉雅下载的邓紫棋的声音日记。将其保存到本地目录。喜马拉雅-国内专业音频分享平台,随时随地,听我想听!
人声伴奏分离&去混响去延迟:使用UVR5工具处理原音频,如下图一点击“开启人声分离WebUI”后,会弹出下图二网页。
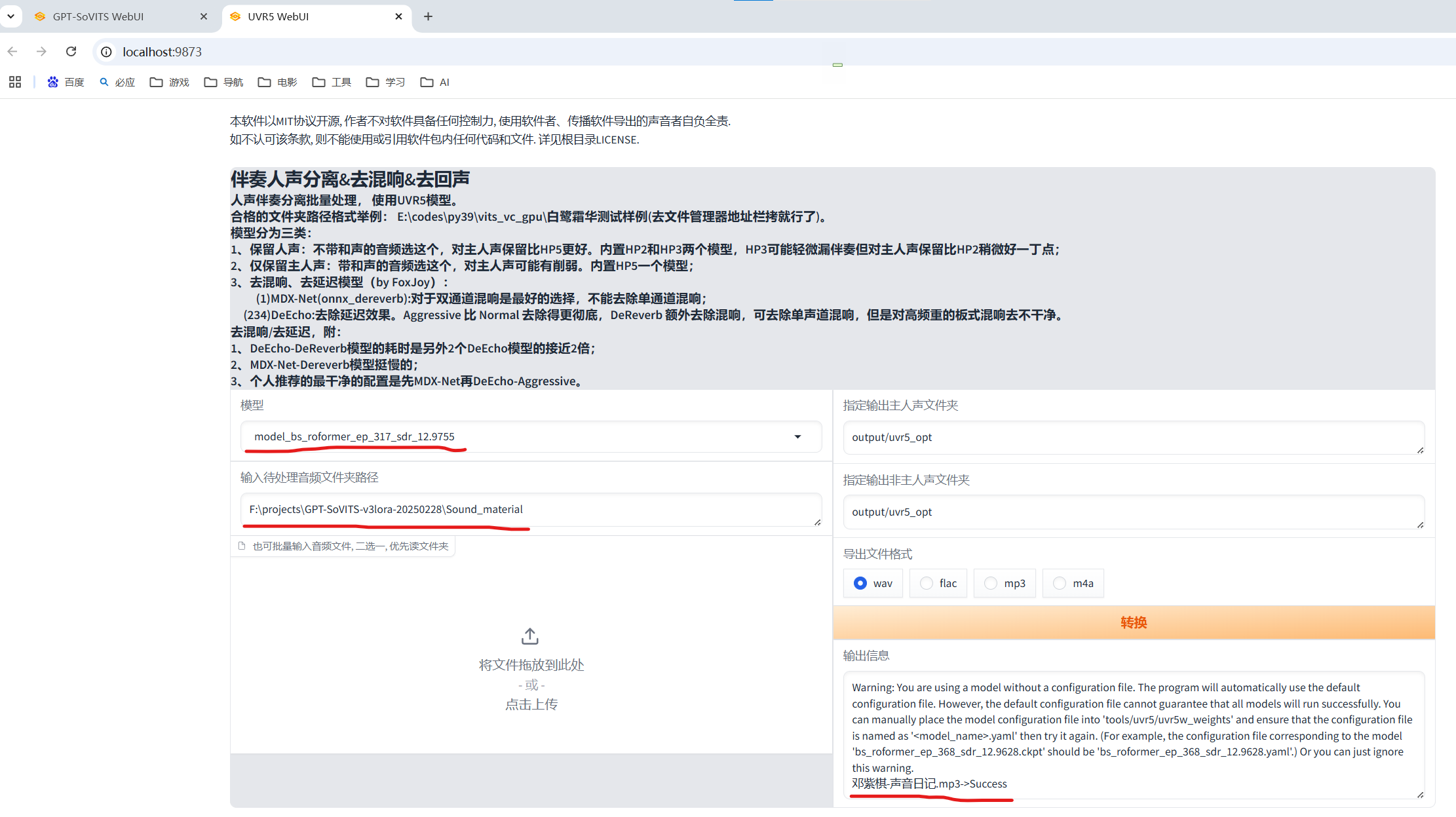
先用model_bs_roformer_ep_317_sdr_12.9755模型(已经是目前最好的模型)处理一遍(提取人声),然后将输出的干声音频再用onnx_dereverb最后用DeEcho-Aggressive(去混响),输出格式选wav。输出的文件默认在GPT-SoVITS-beta\output\uvr5_opt这个文件夹下。处理完的音频(vocal)的是人声,(instrument)是伴奏,(_vocal_main_vocal)的没混响的,(others)的是混响。(vocal)(_vocal_main_vocal)才是要用的文件,其他都可以删除。结束后记得到WebUI关闭UVR5节省显存。
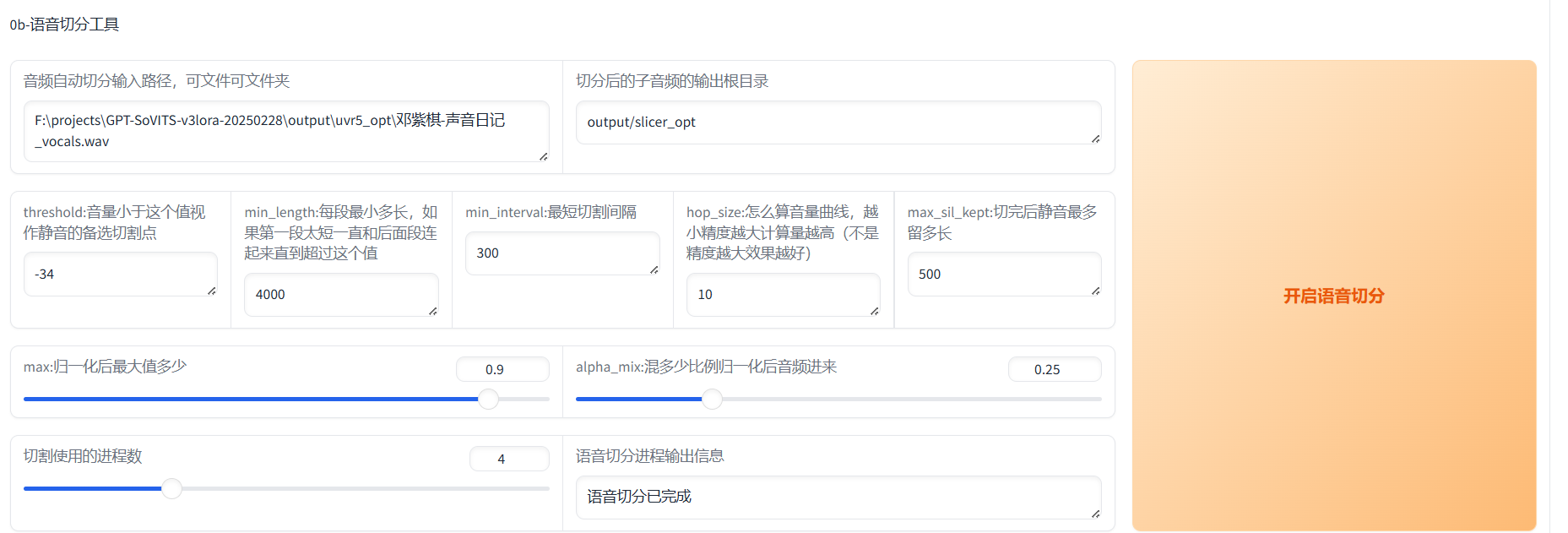
音频切割:作用是去除冗余部分(如静音、背景杂音),保留有效人声;分割语音段落,便于模型学习发音、语调等细节特征。
首先输入原音频的文件夹路径(不要有中文),如果刚刚经过了UVR5处理那么就是uvr5_opt这个文件夹。然后建议可以调整的参数有min_length、min_interval和max_sil_kept单位都是ms。min_length根据显存大小调整,显存越小调越小。min_interval根据音频的平均间隔调整,如果音频太密集可以适当调低。max_sil_kept会影响句子的连贯性,不同音频不同调整,不会调的话保持默认。其他参数不建议调整。点击开启语音切割,马上就切割好了。默认输出路径在output/slicer_opt。
音频降噪:可消除背景噪声(如杂音、电流声、环境音),保留纯净人声,并增强语音的清晰度。
如果你觉得你的音频足够清晰可以跳过这步(我这里下载的音频没杂音,跳过),降噪对音质的破坏挺大的,谨慎使用。输入刚才切割完音频的文件夹,默认是output/slicer_opt文件夹。然后点击开启语音降噪。默认输出路径在output/denoise_opt。

打标:打标就是给每个音频配上文字,这样才能让AI学习到每个字该怎么读。这里的标指的是标注。
如果你上一步切分了或者降噪了,那么已经自动帮你填充好路径了。然后选择达摩ASR或者fast whisper。达摩ASR只能用于识别汉语和粤语,效果也最好。fast whisper可以标注99种语言,是目前最好的英语和日语识别,模型尺寸选large,语种选auto自动。whisper可以选择精度,建议选float16,float16比float32快。然后点开始语音识别就好了,默认输出是output/asr_opt这个路径。
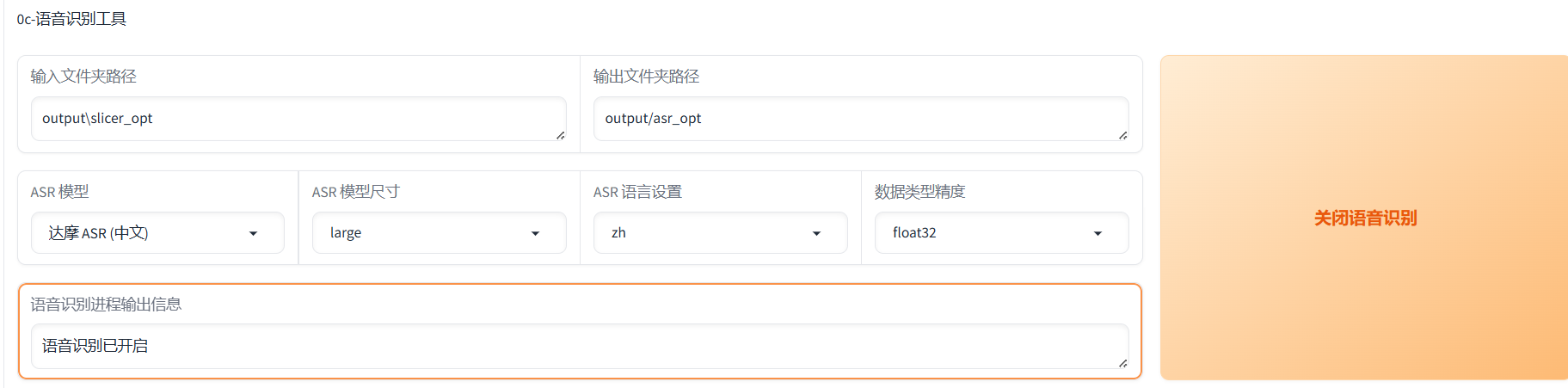
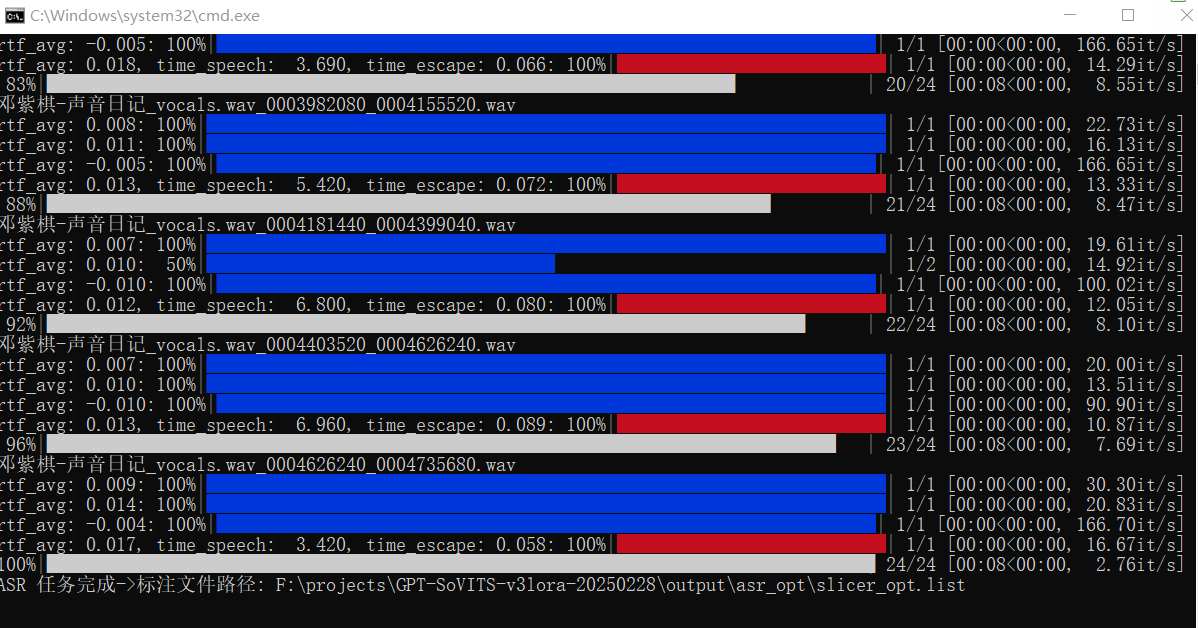
控制台的log如下,显示ASR任务完成就是成功了
校对标注:语音识别完成后,点击“开启音频标注WebUI”。这里会弹出SubFix操作界面(是一个专为轻松编辑与修改音频字幕而设计的Web工具。它使用户能够实时查看更改,并方便地合并、分割、删除和编辑音频的字幕。)

如下图所示,对语音识别出来的字幕进行手工校验修改
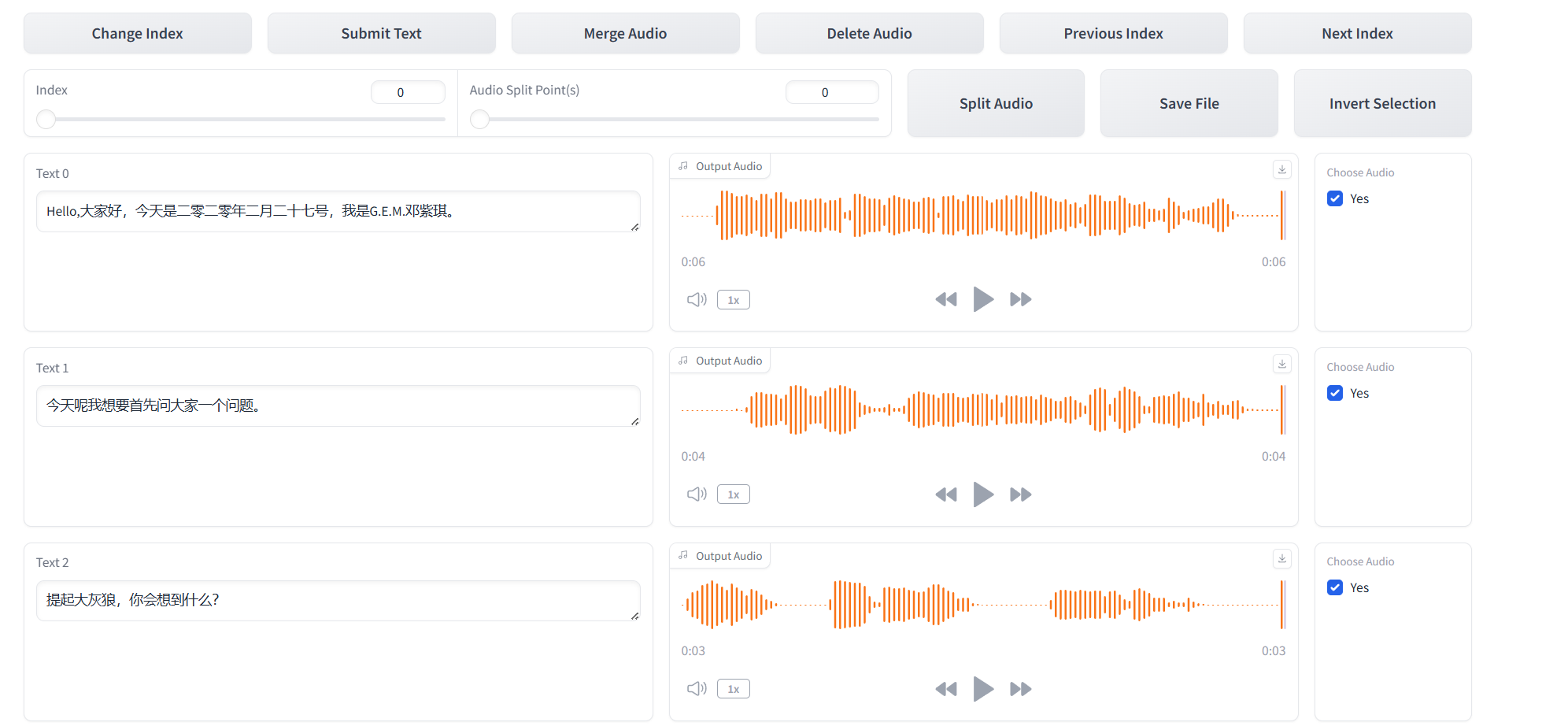
修改完没问题的话,在“Choose Audio”那里打个勾,整页校验完后,点“Submit Text”保存。
然后点“Next Index”跳转到下一页进行校验。直到全部校验完成。
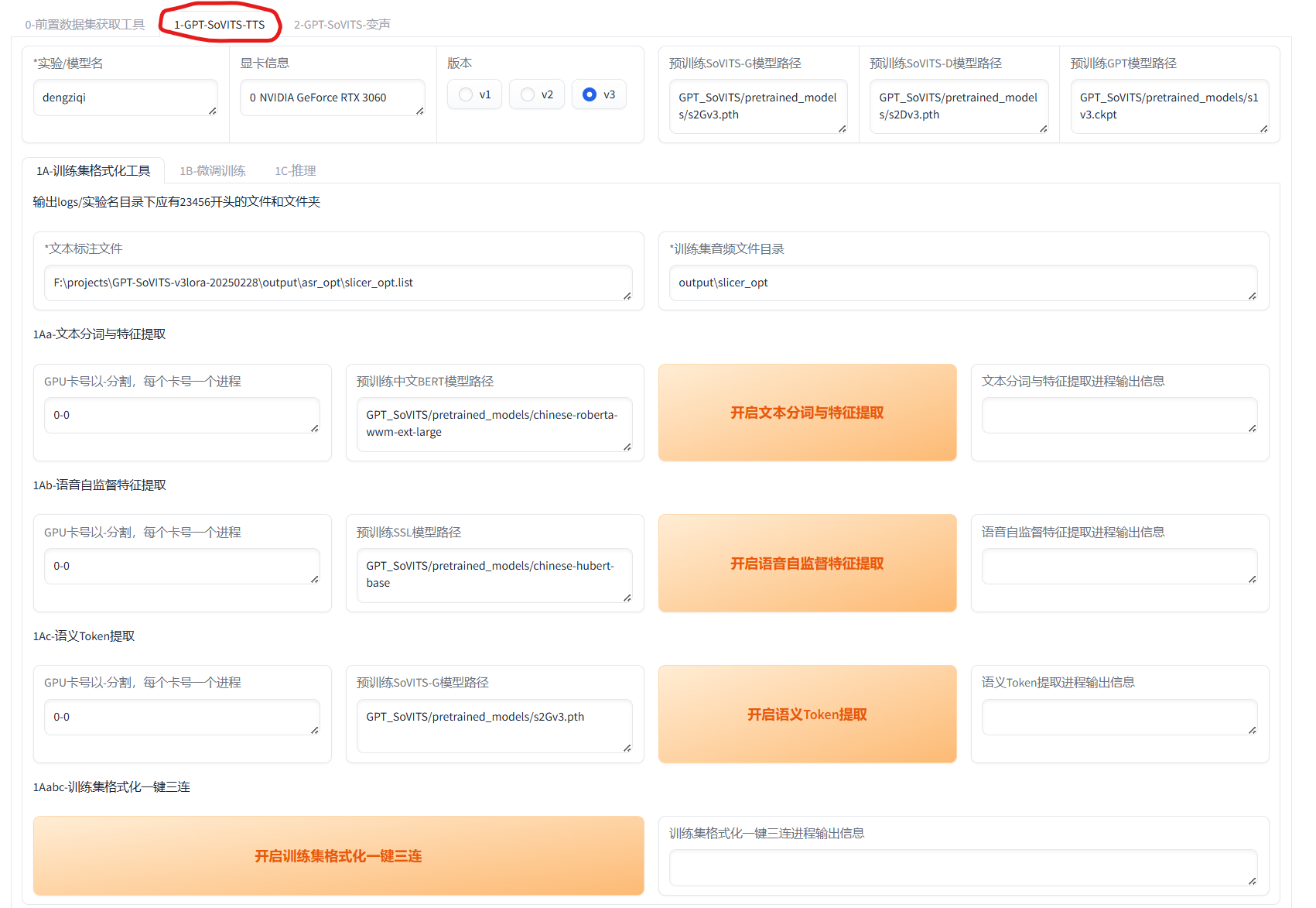
模型训练:来到第二个界面,输入模型名称,然后点击“开启训练集格式化一键三连”(这个会将原始音频及标注数据转化为模型训练所需的标准化格式,确保数据的高效利用与模型稳定学习)
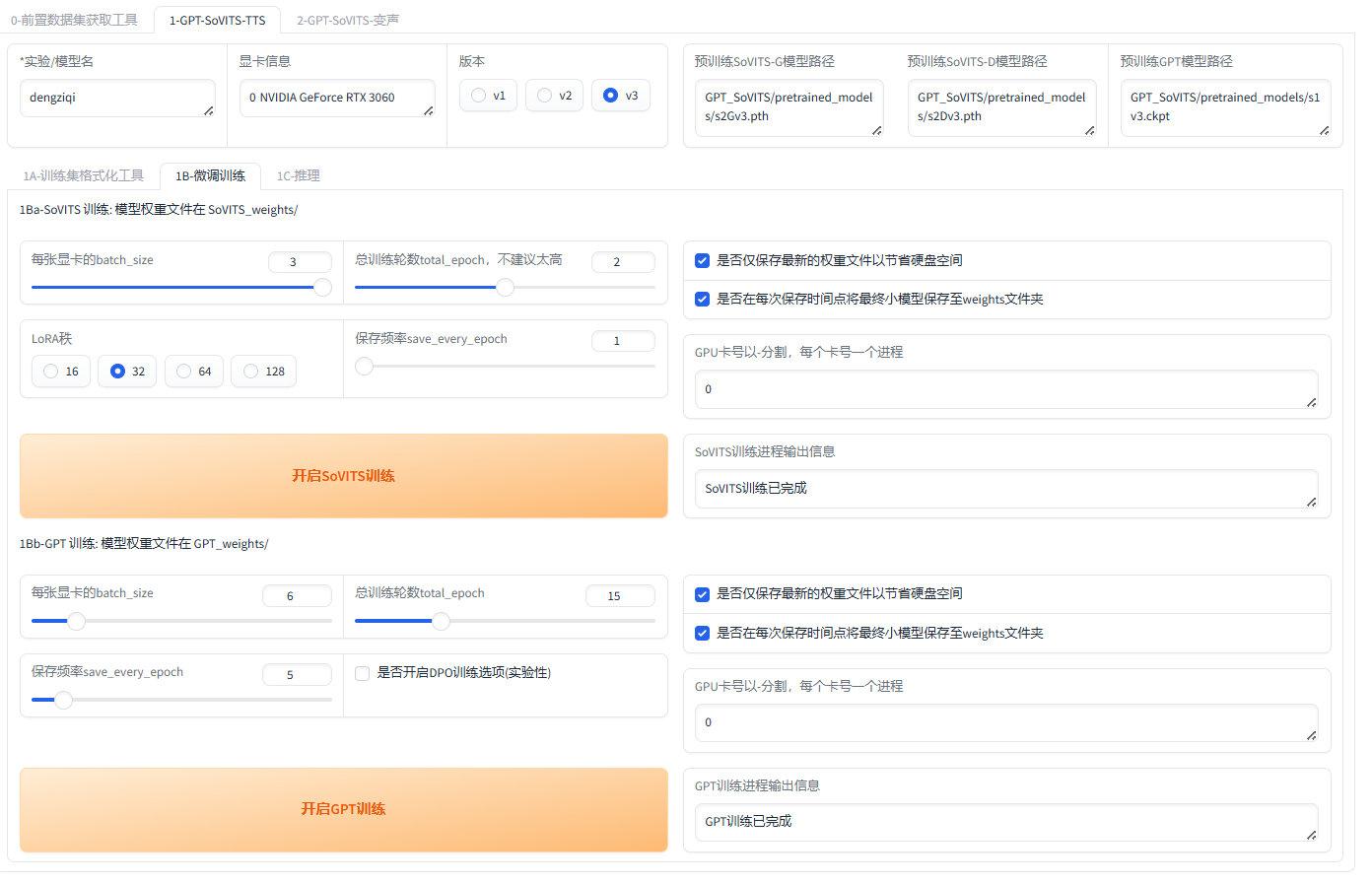
微调训练:如下图开启SoVITS及GPT训练,并等待训练完成。
我这里是用的V3,所以等训练完成后可以在两个V3目录看到已经训练好的模型。
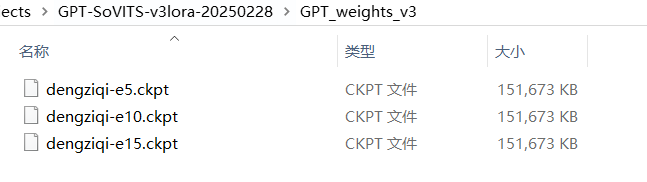

注意:模型这里的e代表轮数,s代表步数。解释如下:
轮数(Epoch):模型完整遍历整个训练数据集的次数。
-
轮数越多,模型对数据的学习越充分,但过度增加可能导致过拟合(训练集表现好,泛化能力差)。
-
通常需结合验证集效果(如损失值、语音质量)动态调整,选择最佳轮数。
步数(Steps):每轮(Epoch)中模型参数更新的次数,由批次大小(Batch Size)决定。
-
计算公式:
Steps per Epoch = 训练集样本总数 / Batch Size -
步数反映单轮训练中模型参数优化的粒度,与计算资源消耗直接相关。
-
Batch Size较小时,单轮步数增多,训练更精细但耗时更长;Batch Size较大时,步数减少,但需更高显存。
在线推理:如下图所示,先点击“刷新模型路径”,然后下拉选择模型。
模型选择好后,点击“开启TTS推理WebUI”,过一会会自动打开在线推理的界面。如果没跳出来的话, 复制http://localhost:9872/到浏览器打开。
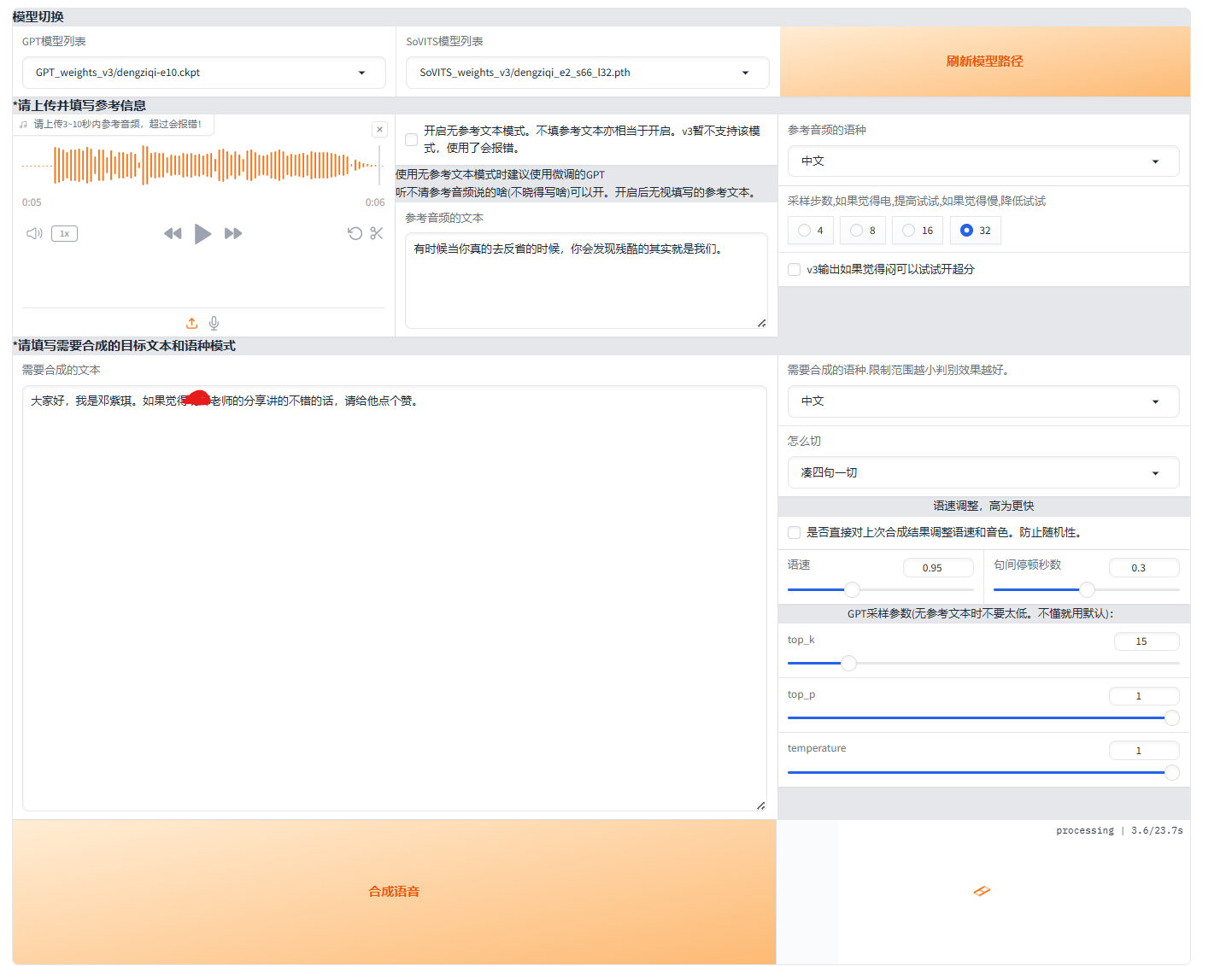
如上图所示,上传一段参考音频及对应的文本信息(会学习语速和语气,建议是数据集中的音频),然后输入要合成的文本,点击“合成语音”,过几秒右下角输出的语音就会生成出来了。
至此,我们的语音模型就完成并可以在线调用了。
top_k、top_p 和 temperature参数讲解
(1) temperature(温度)
-
作用:控制生成结果的随机性。
-
值越大(>1):概率分布更平滑,生成结果更多样、随机,可能出现意想不到的语调或发音(适合需要创造性的场景)。
-
值越小(<1):概率分布更尖锐,生成结果更保守、稳定,贴近训练数据分布(适合追求自然度和一致性的场景)。
-
默认值:通常为
1.0。
-
(2) top_k
-
作用:限制采样范围,仅从概率最高的前
k个候选 token 中选择。-
值越大(如100):采样范围广,生成多样性高,但可能引入不合理的发音。
-
值越小(如5):采样范围窄,生成更保守,但可能导致语音单调。
-
默认值:通常为
5。
-
(3) top_p(核采样)
-
作用:动态选择累积概率达到
p的候选 token 集合。-
值越大(如0.9):允许更多低概率 token 参与采样,生成多样性高。
-
值越小(如0.5):仅保留高概率 token,生成更稳定。
-
默认值:通常为
1.0(即不启用,若设为<1会覆盖top_k)。
-
三、其他的TTS项目分享
Spark-TTS
ChatTTS