Python中type()函数的深度探索:类型检查与动态类创建
# Python中type()函数的深度探索:类型检查与动态类创建
在Python的编程世界里,`type()`函数是一个功能强大且用途广泛的工具。它不仅能帮助我们清晰地了解对象的数据类型,还具备动态创建类的神奇能力。今天,让我们一同深入探索`type()`函数这两个主要应用场景的奥秘。
## 一、type()用于返回对象类型
在Python编程过程中,准确掌握对象的类型至关重要。`type()`函数为我们提供了一种极为便捷的方式来实现这一目的。通过将对象作为参数传入`type()`函数,它会迅速返回该对象所属的数据类型。
### 简单数据类型检查示例
```python
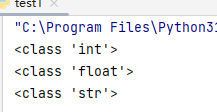
# 检查整数类型
num = 10
print(type(num)) # 输出: <class 'int'>
# 检查浮点数类型
float_num = 3.14
print(type(float_num)) # 输出: <class 'float'>
# 检查字符串类型
string = "Hello, World!"
print(type(string)) # 输出: <class'str'>
```
上述代码展示了`type()`函数对整数、浮点数和字符串这些基本数据类型的检查。每一次调用`type()`函数,都能清晰地获取到对应对象的类型信息,这在调试代码、确保数据处理逻辑正确等方面有着重要作用。
### 复杂数据结构与自定义类的类型检查
```python
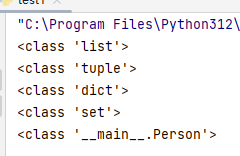
# 检查列表类型
my_list = [1, 2, 3]
print(type(my_list)) # 输出: <class 'list'>
# 检查元组类型
my_tuple = (1, 2, 3)
print(type(my_tuple)) # 输出: <class 'tuple'>
# 检查字典类型
my_dict = {'name': 'John', 'age': 30}
print(type(my_dict)) # 输出: <class 'dict'>
# 检查集合类型
my_set = {1, 2, 3}
print(type(my_set)) # 输出: <class'set'>
# 自定义类
class Person:
def __init__(self, name):
self.name = name
p = Person("Alice")
print(type(p)) # 输出: <class '__main__.Person'>
```
对于列表、元组、字典、集合等复杂数据结构,以及我们自定义的类,`type()`函数同样能准确返回其类型。这使得我们在处理各种数据时,能够随时确认数据的类型,避免因类型不匹配而引发的错误。例如,在编写一个函数时,我们可以在函数内部使用`type()`函数检查传入参数的类型,确保函数能够正确处理不同类型的数据。
## 二、type()作为元类动态创建类
除了用于类型检查,`type()`函数还具备一项强大的功能——动态创建类。这种动态创建类的方式为Python编程带来了极大的灵活性。
### 动态创建类的基本语法与示例
当使用`type()`函数动态创建类时,它需要接收三个参数:类的名称(字符串类型)、基类的元组(可以为空)、类的属性字典。以下是一个简单的示例:
```python
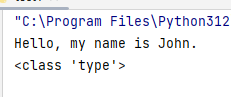
# 定义类的属性和方法
def say_hello(self):
print(f"Hello, my name is {self.name}.")
# 使用type()动态创建类
Person = type('Person', (), {'name': 'John','say_hello': say_hello})
# 创建Person类的实例
p = Person()
# 调用实例的方法
p.say_hello() # 输出: Hello, my name is John.
# 检查类的类型
print(type(Person)) # 输出: <class 'type'>
```
在这个例子中,我们通过`type()`函数创建了一个名为`Person`的类。`Person`类有一个属性`name`和一个方法`say_hello`。创建类的实例`p`后,能够顺利调用`say_hello`方法,这充分展示了`type()`函数动态创建类的功能。同时,我们还可以看到`Person`类的类型是`type`,这表明它是由`type`元类创建的。
### 第二个参数的具体用处
在动态创建类时,`type()`函数的第二个参数——基类元组,发挥着至关重要的作用。
#### 实现类的继承
```python
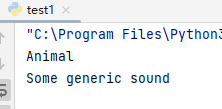
# 定义一个基类
class Animal:
def __init__(self):
self.species = "Animal"
def make_sound(self):
print("Some generic sound")
# 使用type()动态创建一个继承自Animal的类
Dog = type('Dog', (Animal,), {})
# 创建Dog类的实例
dog = Dog()
# 访问从基类继承的属性
print(dog.species) # 输出: Animal
# 调用从基类继承的方法
dog.make_sound() # 输出: Some generic sound
```
通过将基类`Animal`作为元组的元素传入`type()`函数的第二个参数,我们创建的`Dog`类成功继承了`Animal`类的属性和方法。这使得`Dog`类的实例`dog`能够访问`species`属性并调用`make_sound`方法,体现了继承在代码复用方面的优势。
#### 多继承的实现
Python支持多继承,即一个类可以同时继承多个父类的属性和方法。`type()`函数的第二个参数为实现多继承提供了便利。
```python
# 定义第一个基类
class Flyable:
def fly(self):
print("I can fly!")
# 定义第二个基类
class Swimmable:
def swim(self):
print("I can swim!")
# 使用type()动态创建一个多继承的类
Duck = type('Duck', (Flyable, Swimmable), {})
# 创建Duck类的实例
duck = Duck()
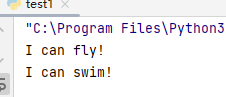
# 调用从不同基类继承的方法
duck.fly() # 输出: I can fly!
duck.swim() # 输出: I can swim!
```
在这个示例中,`Duck`类通过`type()`函数的第二个参数同时继承了`Flyable`和`Swimmable`两个基类。因此,`Duck`类的实例`duck`可以调用来自不同基类的`fly`和`swim`方法,展示了多继承为类的功能扩展带来的强大能力。
#### 构建自定义基类层次结构
```python
# 定义一个基类
class LivingBeing:
def __init__(self):
self.alive = True
# 定义一个中间基类,继承自LivingBeing
class Mammal(LivingBeing):
def __init__(self):
super().__init__()
self.has_fur = True
# 使用type()动态创建一个继承自Mammal的类
Cat = type('Cat', (Mammal,), {})
# 创建Cat类的实例
cat = Cat()
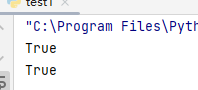
# 访问从基类继承的属性
print(cat.alive) # 输出: True
print(cat.has_fur) # 输出: True
```
通过合理利用`type()`函数的第二个参数,我们可以构建复杂的基类层次结构。在这个例子中,`Cat`类通过继承`Mammal`类,间接继承了`LivingBeing`类的属性。这使得`Cat`类的实例`cat`能够访问来自不同层次基类的`alive`和`has_fur`属性,展示了通过动态创建类构建灵活类层次结构的可能性。
`type()`函数在Python编程中是一个不可或缺的工具。无论是进行简单的数据类型检查,还是通过动态创建类构建复杂的面向对象系统,它都能发挥巨大的作用。深入理解和熟练运用`type()`函数,将有助于我们编写出更加健壮、灵活和高效的Python代码。希望通过今天的分享,大家对`type()`函数有了更全面、深入的认识,在未来的编程实践中能够充分挖掘它的潜力。