Linux工具学习之【gcc/g++】
📘前言
书接上文,我们已经学习了 Linux 中的编辑器 vim 的相关使用方法,现在已经能直接在 Linux 中编写C/C++代码,有了代码之后就要尝试去编译并运行它,此时就可以学习一下 Linux 中的编译器 gcc/g++ 了,我们一般使用 gcc 编译C语言,g++ 编译C++(当然 g++ 也可编译C语言),这两个编译器我们可以当作一个来学习,因为它们的命令选项都是通用的,只是编译对象不同。除了编译器相关介绍外,本文还会库、自动化构建工具、提权等知识,一起来看看吧
📘正文
📖gcc/g++ 命令
在接下来的学习中,我们以 gcc 为例,因为两者选项都是通用的,所以也就相当于间接学习了 g++ ,这个编译器上手还是很简单的,选项也不是很多
注意: 如果命令失效,很有可能是没有下载 gcc/g++ ,需要自行下载安装 gcc 与 g++
📃-o 目标文件
gcc 源文件 默认会将代码编译链接并生成可执行文件 a.out ,当然前提是代码没问题,所以这样看来编译一个文件还是很简单的
$ gcc 源文件 //直接编译源文件,生成默认可执行文件为 a.out
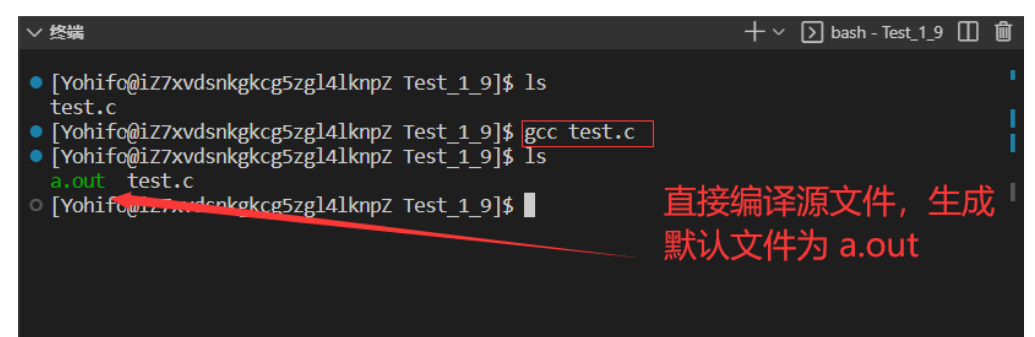
可能有的人不想让它生成默认的 a.out ,想生成为指定文件,没有问题,直接通过 -o 选项就能实现
注意:-o 选项后面必须紧跟生成的目标文件,这个选项可以放在源文件后面,也可以放在前面
$ gcc test.c -o OK //编译生成文件为 OK
$ gcc -o OK test.c //这种写法也是可以的
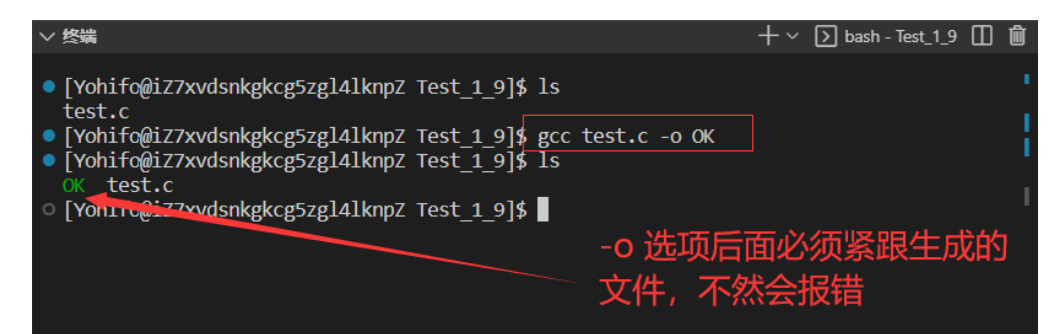
在我们使用 gcc/g++ 时,都可以通过 -o 选项生成指定文件
📃-E 预处理
在C语言学习阶段,我们学习了源文件变成可执行文件的过程,即预处理-编译-汇编-链接,当时因为没有学习Linux,没法很好的展示各个环节的现象,今天可以来详细看看
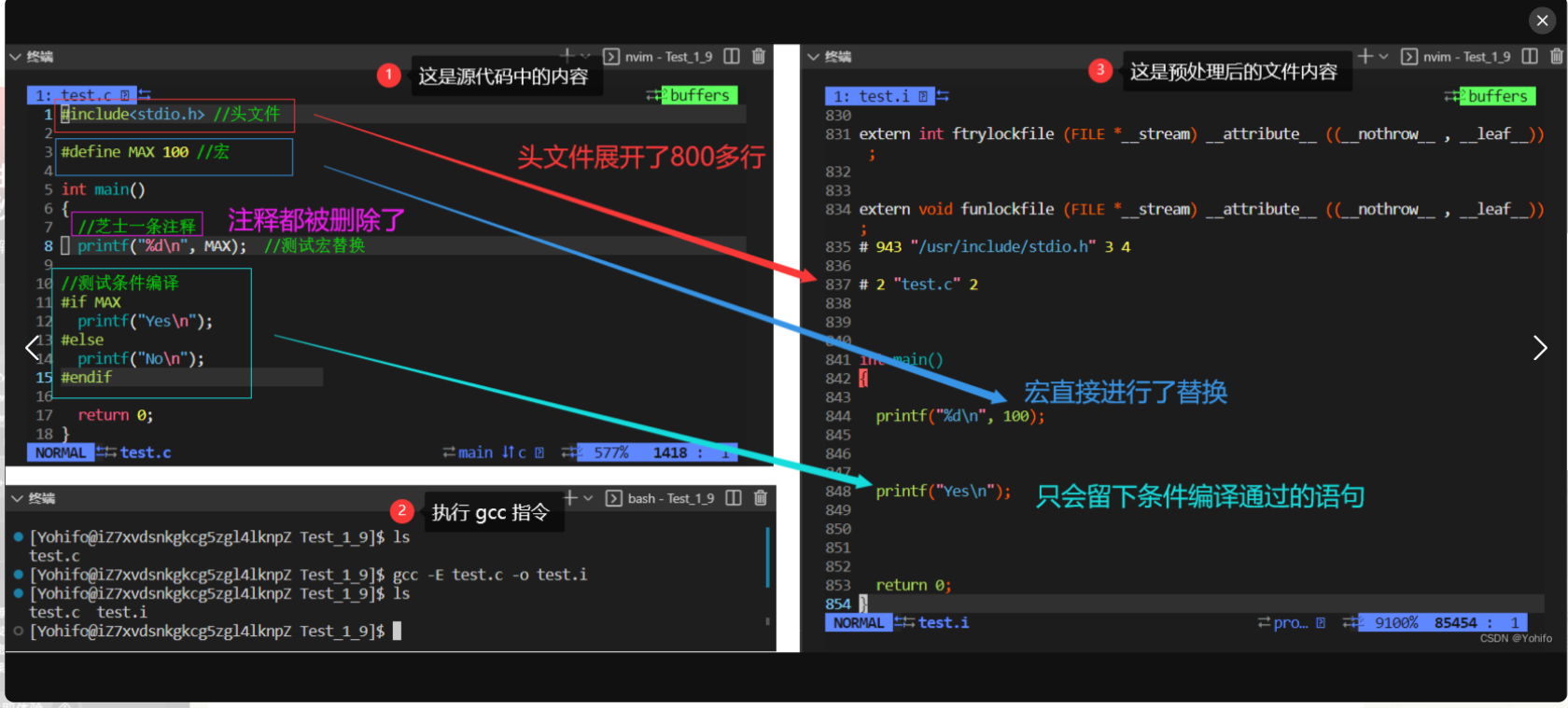
首先是第一步:预处理,又称预编译
会进行头文件展开、删除注释、替换宏、执行条件编译等操作
目的是生成一个纯粹的C代码程序
经过预处理后的文件后缀为 .i
我们可以直接通过 gcc 中的 -E 命令,使编译器在执行完预处理后停下来,配合 -o 生成指定文件,这样我们就可以观察到上面所提到的这些现象了。
$ gcc -E test.c -o test.i //预处理后的文件后缀为 .i 此时仍然是C语言
📃-S 编译
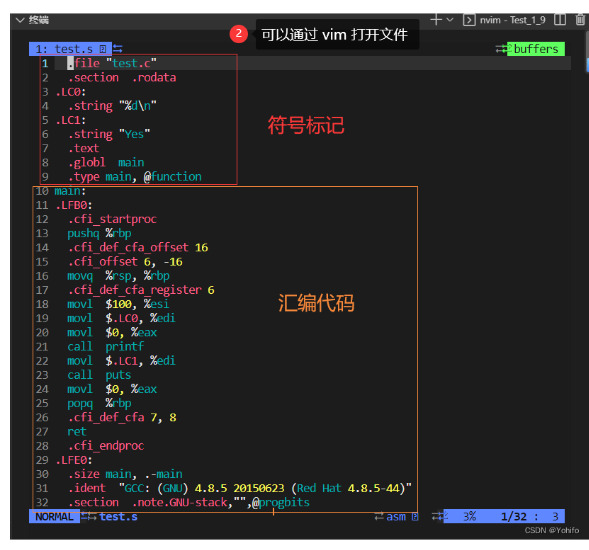
下面进入第二个步骤:编译
进行语法分析、词法分析、语义分析、符号汇总等,然后将合法的代码转为汇编代码
编译目的是生成汇编代码
编译后生成的文件后缀为 .s
编译阶段比较重要的一步就是符号汇总,它会各种符号汇总起来,方便后续符号表的形成,符号表用于各种函数间的相互调用
我们可以通过 -S 选项,使 gcc 在执行完编译阶段后就停下来,配合 -o 生成文件 test.s
$ gcc -S test.c -o test.s //可以直接从 test.c 开始执行,也可以从上一步中的 test.i 执行
📃-c 汇编
接下来进入第三步:汇编
主要任务是将汇编代码转为二进制,并生成符号表
二进制文件的格式是 elf ,此时 vim 查看为乱码
生成的文件后缀为 .o
因为计算机只能看懂二进制,所以将代码转为二进制是必须进行的操作,除此之外,还有一个重要步骤:生成符号表
关于符号表
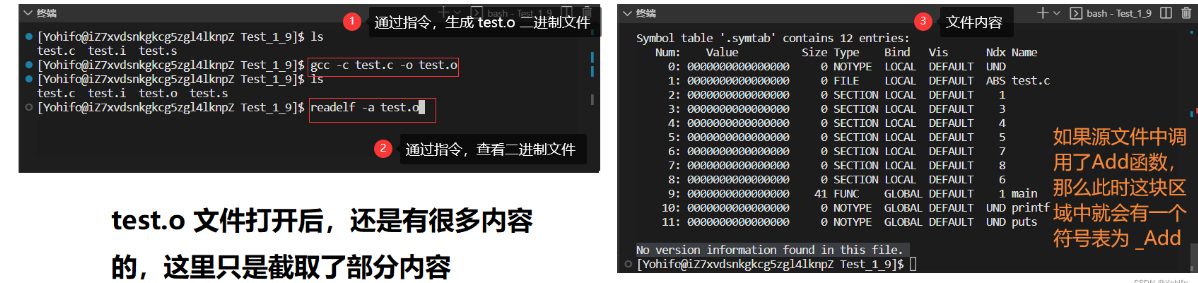
这个东西相当于函数独一无二的地址,在Linux 中,C语言的符号表比较简单,通常是 _函数名,比如 _Add ;C++更详细一些,通常为 _Z函数名长度+函数名+参数1+参数2 ,比如常见的 Add 函数,生成的符号表为 _Z3Addii ,这里的参数是两个整型,这也是C++支持重载,而C语言不支持重载的根本原因,毕竟C语言中两个重名的函数生成的符号表是完全一样的,区分不了
可以通过 -c 选项使 gcc 在执行完汇编阶段后就停下来,指定保存文件为 test.o
查看生成的 test.o 文件,可以用 readelf 这个工具,缺失的可以去下载
$ gcc -c test.c -o test.o //从源文件重新开始编译,生成 test.o 二进制文件
$ gcc -c test.s -o test.o //从上一步中生成的 test.s 文件开始编译,两者效果是一样的//关于查看 elf 格式的文件
$ readelf -a test.o //可以通过软件,观察到符号表等信息
📃gcc 链接
下面是最后一步:链接
进行合并段表、将符号表进行合并和重定位等
将程序运行所需的各种函数链接起来,包括与库函数的链接,Linux 中一般是动态链接,链接后生成可执行文件,此时的文件也是 elf 的格式
gcc 默认生成的可执行文件为 a.out,我们可以指定生成任意文件
$ gcc test.c -o myfile //生成可执行文件为 myfile
$ gcc test.o -o myfile //继上一次生成的二进制文件执行链接,也是没有问题的

📃小结
关于各个命令选项可以巧记为 ESc 这是键盘上的一个键,忘记了可以看看
还有各个选项对应生成的文件后缀为 iso
📖库
1. 标准库的位置:
-
标准库头文件:标准库的头文件(如
stdio.h、string.h、stdlib.h等)通常存放在/usr/include目录下。这些头文件提供了库函数的声明和宏定义,函数的具体实现都在库中了。它们是编写 C 程序时必须包含的文件。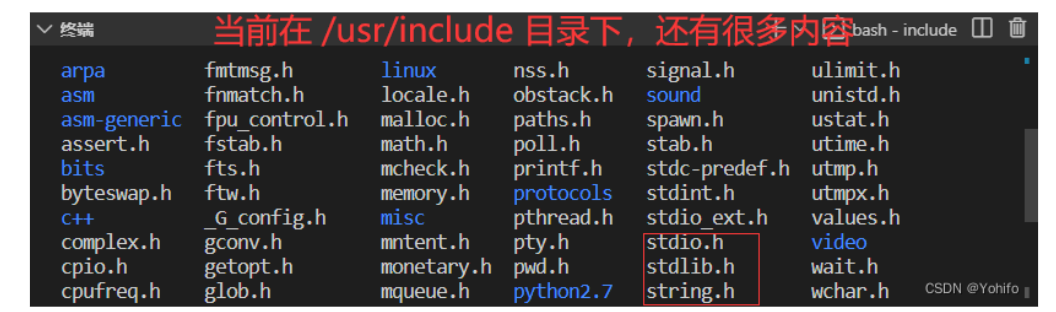
-
标准库的实现:标准库的实际实现(即函数的定义和逻辑)并不在
/usr/include目录下,而是通常存放在系统的库目录中,比如/lib或/usr/lib。这些库可能是 静态库(以.a为扩展名)或 动态库(以.so为扩展名)
📃动态库
动态库 即通过 动态链接 的库,动态库 又称 共享库,因为 动态库 中的内容是被所有程序共享的,简言之 动态库 中的代码只需要存在一份,程序需要使用时,直接通过对应位置调用就行了
Linux 中默认使用 动态链接 的方式,我们可以通过指令 ldd 最终生成的文件 来查看最终生成文件的链接情况
$ ldd 最终生成的文件 //查看文件的链接情况
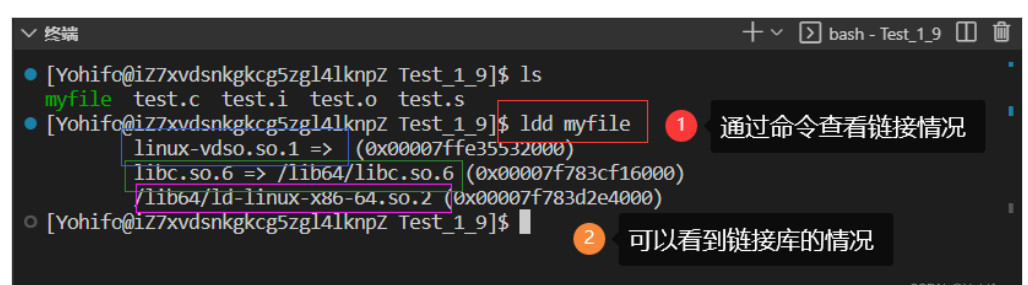
libXXX.so 是动态链接的标志
其中 lib 是前缀
.so 是后缀
去掉前缀与后缀,就是最终调用的库
举例:libc.so 去掉前缀与后缀,最终为 c ,可以看出文件最终调用的是C语言共享库,即 动态链接
动态链接 主要依赖不同函数在库中的位置信息进行调用,只有一份代码库,比较节省空间
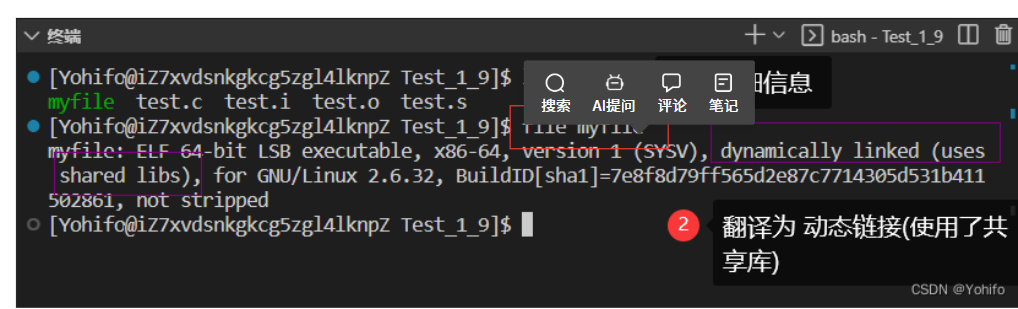
我们还可以通过 file 命令查看文件详细信息
$ file 最终生成的文件 //查看文件的详细情况
 📃静态库
📃静态库
除了 动态库 外,还有 静态库 ,采用 静态链接 的方式;静态链接 不同与 动态链接 共享的方式,如果程序调用 静态库 ,会将自己所需要的代码 拷贝至程序中 ,完成拷贝后,后续不需要再调用 静态库
如果想采用 静态链接 链接的方式编译程序,需要在编译时加上 -static 选项,当然前提是得有 静态库,没有的可以通过 yum install -y glibc-static 下载 静态库
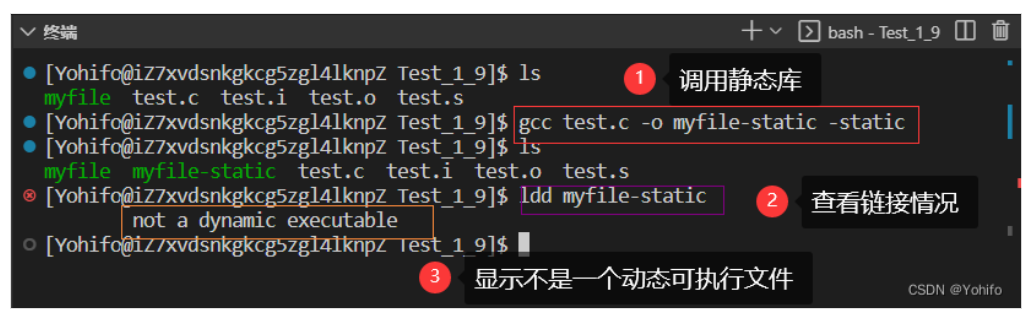
当然我们也可以通过 ldd 最终生成的文件 查看是否为 静态链接
$ yum install -y glibc-static //下载静态库
$ gcc test.c -o myfile-static -static //采取静态链接的方式编译程序
$ ldd 最终生成的文件 //查看文件的链接方式
动态库 vs 静态库的优缺点对比:
| 区别 | 动态库 | 静态库 |
|---|---|---|
| 调用方式 | 通过函数位置(动态链接)进行调用 | 直接将需要的函数拷贝至程序中(静态链接) |
| 依赖性(运行时) | 需要依赖于动态库文件,运行时必须能找到对应的 .so 文件 | 不依赖外部库,程序可以独立运行 |
| 空间占用 | 共享动态库中的代码,多个程序共享同一个库,节省空间 | 每个程序都包含库代码,导致文件较大 |
| 加载速度 | 调用时需要加载库并进行链接,加载速度慢 | 直接运行,程序中已经包含了库的代码,加载速度快 |
| 更新 | 更新库时,无需重新编译程序,方便管理和维护 | 更新库时需要重新编译程序,管理较为繁琐 |
| 版本兼容性 | 可能会遇到版本不兼容问题(“DLL Hell”) | 一旦编译完成,不受库版本变化影响 |
| 内存占用 | 多个程序可以共享同一个库文件,节省内存 | 每个程序都占用一份内存空间 |
动态库的优点:
-
共享代码:动态库可以在多个程序之间共享,节省磁盘空间和内存。对于大型程序和多个程序共享同一个库的情况,动态库非常有用。
-
程序小巧:因为动态库不包含在每个可执行文件中,所以生成的程序文件较小。
-
更新简便:如果库的功能有更新,只需要替换库文件,无需重新编译所有依赖这个库的程序。这使得系统升级和维护更加方便。
-
内存共享:多个程序运行时,可以共享动态库中的代码和数据,节省内存。
动态库的缺点:
-
加载速度较慢:由于程序在运行时需要加载和链接动态库,调用速度相对较慢,特别是在频繁调用库函数的情况下。
-
运行时依赖性:程序需要在运行时找到并加载正确的动态库版本。如果缺少动态库或版本不兼容,程序可能无法正常运行(例如,缺少
.so文件)。 -
版本问题:如果系统中多个程序依赖于同一个动态库,而库的版本发生变化时,可能会导致“版本不兼容”(DLL Hell)的问题。
静态库的优点:
-
独立性:静态库在编译时就已链接到可执行文件中,程序不依赖外部的库文件,减少了运行时的复杂性。
-
加载速度快:静态库的代码已经包含在程序中,程序启动时不需要额外加载库,加载速度较快。
-
无需担心版本问题:由于静态库在编译时就已经链接到程序,程序和库的版本不会再发生兼容性问题。
静态库的缺点:
-
空间占用大:每个程序都需要包含静态库的副本,因此生成的可执行文件较大,浪费存储空间。
-
更新麻烦:如果需要更新库,必须重新编译程序,这对于大型项目或多个依赖同一库的项目来说,管理和更新较为麻烦。
-
内存占用多:每个运行的程序都加载静态库的代码,占用更多内存,而动态库则可以被多个程序共享内存。
总结:
-
动态库适用于:
-
需要多个程序共享同一份代码库的场景,尤其是在内存和磁盘空间有限的情况下。
-
程序开发周期较长,库需要经常更新,且更新后不想重新编译所有依赖程序的情况。
-
对更新灵活性要求较高,且能够接受可能出现的加载速度和依赖问题。
-
-
静态库适用于:
-
对程序启动速度要求较高,且不依赖外部库的场景。
-
程序体积可以接受,且不需要频繁更新库的情况。
-
独立部署的应用程序,不想担心外部库的兼容性问题。
-
选择使用动态库还是静态库,通常要根据具体项目的需求、系统资源以及维护成本来决定。如果项目中有多个依赖共享的库文件,动态库往往是更好的选择;而如果项目需要更高的执行效率或独立性,静态库可能更适合。