【工具】gtest
在写代码的时候大家是怎么判断自己所写的程序运行有没有问题呢?可能是在程序中穿插打印数据,看比对数据是否有问题,这是传统的肉眼观察法。如果代码量并不大,数据量比较少的话是比较好用的。那在数据量庞大时,打印信息一大堆向上闪烁时就比较难办了。
本期介绍单元测试框架GTest,来解决这个问题:
目录
一、gtest安装指令
二、gtest的使用
2.1 头文件的包含
2.2 框架初始化接口
2.3 调用测试样例
2.4 测试用例的编写
2.4.1 TEST宏
2.4.2 断言宏
2.4.3 测试样例
三、事件机制
3.1 全局事件
3.2 TestSuite事件
3.3 TestCase事件
一、gtest安装指令
ubuntu环境下:
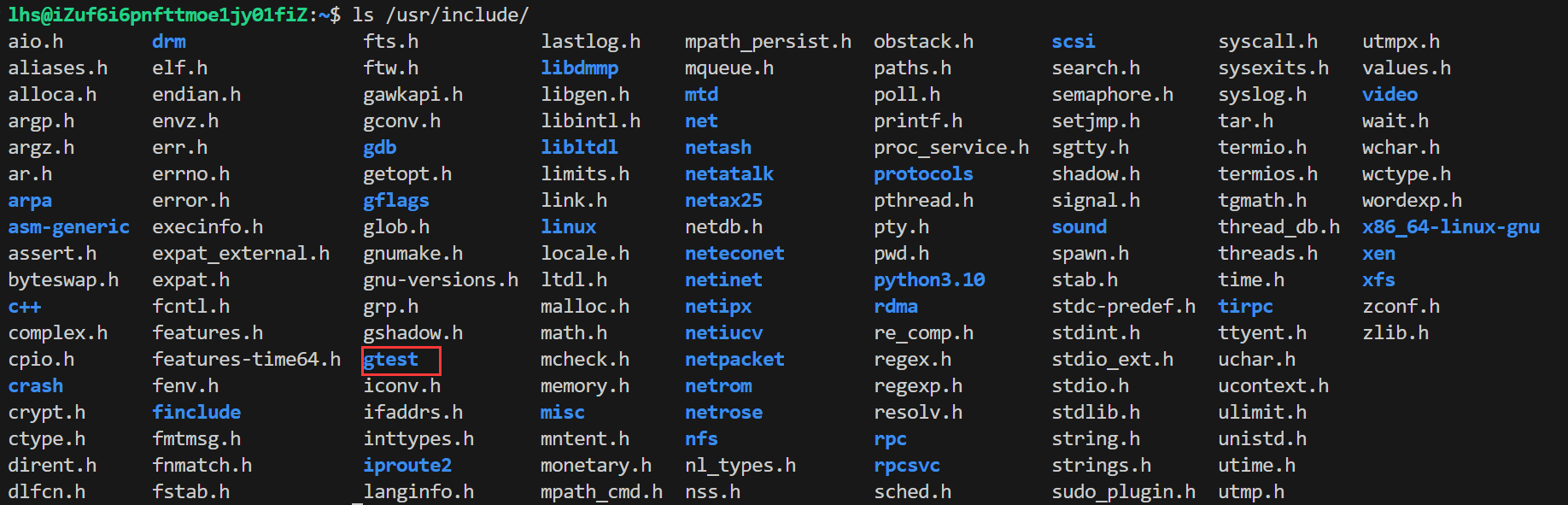
sudo apt-get install libgtest-dev下载完成过后我们会发现在/usr/include/目录下会多出一个gtest的文件:
其次是多出一个libgtest.a的静态库:

二、gtest的使用
2.1 头文件的包含
在C++程序中要想使用gtest框架,先要加上头文件
#include <gtest/gtest.h>2.2 框架初始化接口
testing::InitGoogleTest(&argc, argv);2.3 调用测试样例
RUN_ALL_TESTS();RUN_ALL_TESTS()接口会运行所用测试用例,并且会有返回值:
● 返回 0 表示所有测试成功。
● 返回 1 表示至少有一个测试失败或异常。该返回值通常直接作为
main函数的返回值,以反映测试结果。
该接口的返回值通常会做为main函数的返回值
2.4 测试用例的编写
2.4.1 TEST宏
TEST(test_fixture,test_name)
{...
}TEST:主要用来创建一个简单测试, 它定义了一个测试函数, 在这个函数中可以使用任何C++代码并且可以使用框架提供的断言进行检查
TEST_F(test_fixture,test_name)
{...
}TEST_F:主要用来进行多样测试,适用于多个测试场景如果需要相同的数据配置的情况,即相同的数据测不同的行为
2.4.2 断言宏
gtest中的断言的宏可以分为两类:
● ASSERT_系列:如果当前点检测失败则退出当前TEST函数
● EXPECT_系列:如果当前点检测失败则继续往下执行,进行判断下一个检测点
下面是经常使用的断言介绍:
// bool值检查
ASSERT_TRUE(参数),期待结果是true
ASSERT_FALSE(参数),期待结果是false //数值型数据检查
ASSERT_EQ(参数1,参数2),传入的是需要比较的两个数 equal
ASSERT_NE(参数1,参数2),not equal,不等于才返回true
ASSERT_LT(参数1,参数2),less than,小于才返回true
ASSERT_GT(参数1,参数2),greater than,大于才返回true
ASSERT_LE(参数1,参数2),less equal,小于等于才返回true
ASSERT_GE(参数1,参数2),greater equal,大于等于才返回true// bool值检查
EXPECT_TRUE(参数),期待结果是true
EXPECT_FALSE(参数),期待结果是false //数值型数据检查
EXPECT_EQ(参数1,参数2),传入的是需要比较的两个数 equal
EXPECT_NE(参数1,参数2),not equal,不等于才返回true
EXPECT_LT(参数1,参数2),less than,小于才返回true
EXPECT_GT(参数1,参数2),greater than,大于才返回true
EXPECT_LE(参数1,参数2),less equal,小于等于才返回true
EXPECT_GE(参数1,参数2),greater equal,大于等于才返回true2.4.3 测试样例
#include<gtest/gtest.h>
#include<iostream>
#include<string>int add(const int& a,const int& b)
{return a+b;
}
TEST(样例,加法函数的测试)
{ASSERT_EQ(add(10,15),25);//使用ASSERT_EQ检查add(10,15)的返回值是否与25相等ASSERT_LT(add(10,15),10);//使用ASSERT_LT检查add(10,15)的返回值是否比25小std::cout<<"上面ASSERT_LT断言出错,这句话打印不出来"<<std::endl;ASSERT_GE(add(40,7),10);//使用ASSERT_LT检查add(10,15)的返回值是否比25小
}
TEST(样例,字符串的测试)
{std::string str="Hello";EXPECT_EQ(str,"hello");//使用EXPECT_EQ检查str是否与hello一致std::cout<<"上面EXPECT_EQ断言出错,这句话可以打印出来"<<std::endl;EXPECT_EQ(str,"Hello");//使用EXPECT_EQ检查str是否与Hello一致
}int main(int argc,char* argv[])
{//框架初始化testing::InitGoogleTest(&argc, argv);//开始测试所有单元RUN_ALL_TESTS();return 0;
}运行结果:
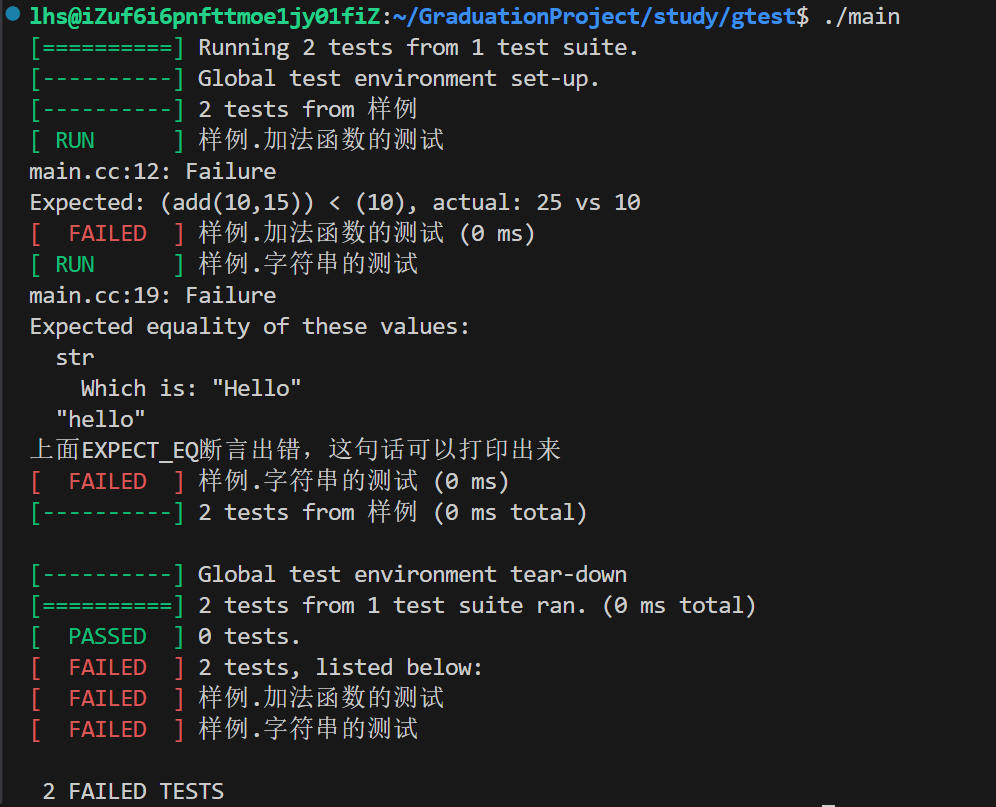
我们可以看到测试结果是哪里出现了错误,错误原因,出错代码所在行,所有的测试用例的总结
一目了然~
三、事件机制
gtest中的事件机制是指在测试前和测试后提供给用户自行添加操作的机制,而且该机制也可以让同一测试套件下的测试用例共享数据。
下面是gtest框架中事件的结构层次:
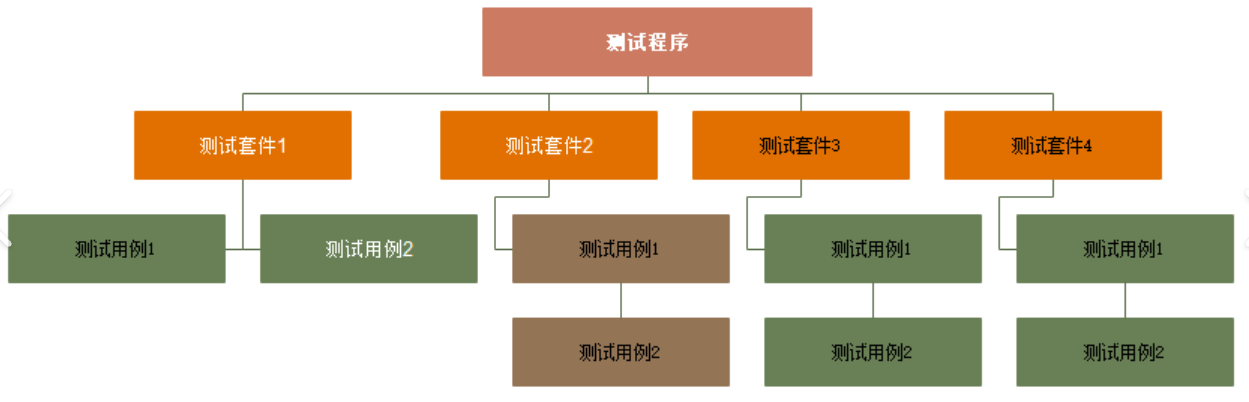
● 测试程序:一个测试程序只有一个main函数,也可以说是一个可执行程序是一个 测试程序。该级别的事件机制是在程序的开始和结束执行
● 测试套件:代表一个测试用例的集合体,该级别的事件机制是在整体的测试案例 开始和结束执行
● 测试用例:该级别的事件机制是在每个测试用例开始和结束都执行
事件机制的最大好处就是能够为我们各个测试用例提前准备好测试环境,并在测试完毕后用于销毁环境,这样有个好处就是如果我们有一端代码需要进行多种不同方法的 测试,则可以通过测试机制在每个测试用例进行之前初始化测试环境和数据,并在测试完毕后清理测试造成的影响。
GTest 提供了三种常见的的事件:
3.1 全局事件
针对整个测试程序。实现全局的事件机制,需要创建一个自己的类,然后继承 testing::Environment 类,然后分别实现成员函数SetUp 和 TearDown,同时在main函数内进行调用testing::AddGlobalTestEnvironment(new MyEnvironment);函数添加全局的事件机制:
#include <iostream>
#include <gtest/gtest.h>
//全局事件:针对整个测试程序,提供全局事件机制,能够在测试之前配置测试环境数据,测试完毕后清理数据
//先定义环境类,通过继承testing::Environment 的派生类来完成
//重写的虚函数接口SetUp会在测试之前被调用;TearDown会在测试完毕后调用
std::unordered_map<std::string, std::string> dict;
class HashTestEnv : public testing::Environment {
public:
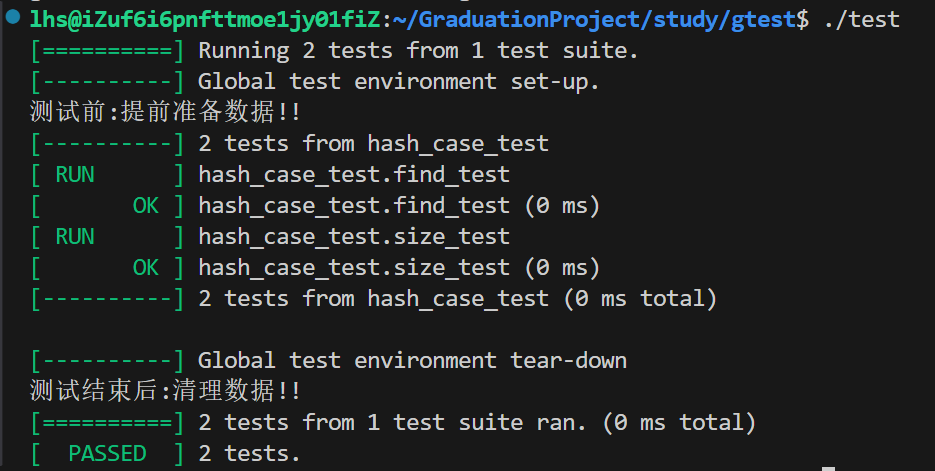
virtual void SetUp() override{ std::cout << "测试前:提前准备数据!!\n"; dict.insert(std::make_pair("Hello", "你好")); dict.insert(std::make_pair("hello", "你好")); dict.insert(std::make_pair("雷吼", "你好")); } virtual void TearDown() override{ std::cout << "测试结束后:清理数据!!\n"; dict.clear(); }
}; TEST(hash_case_test, find_test) { auto it = dict.find("hello"); ASSERT_NE(it, dict.end());
}
TEST(hash_case_test, size_test) { ASSERT_GT(dict.size(), 0);
}
int main(int argc, char *argv[])
{ testing::AddGlobalTestEnvironment(new HashTestEnv ); testing::InitGoogleTest(&argc, argv); return RUN_ALL_TESTS();
}运行结果:
3.2 TestSuite事件
针对一个个测试套件。测试套件的事件机制我们同样需要去创建一个类,继承自 testing::Test,实现两个静态函数 SetUpTestCase和 TearDownTestCase,测试套件的事件机制不需要像全局事件机制一样在main注册,而是需要将我们平时使用的 TEST宏改为TEST_F宏
● SetUpTestCase() 函数是在测试套件第一个测试用例开始前执行
● TearDownTestCase() 函数是在测试套件最后一个测试用例结束后执行
● 需要注意TEST_F的第一个参数是我们创建的类名,也就是当前测试套件的名称, 这样在TEST_F宏的测试套件中就可以访问类中的成员了
#include <iostream>
#include <gtest/gtest.h>
//TestSuite:测试套件/集合进行单元测试,即,将多个相关测试归入一组的方式进行测试,为这组测试用例进行环境配置和清理
//概念: 对一个功能的验证往往需要很多测试用例,测试套件就是针对一组相关测试用例进行环境配置的事件机制
//用法: 先定义环境类,继承于 testing::Test 基类, 重写两个静态函数SetUpTestCase/TearDownTestCase进行环境的配置和清理
class HashTestEnv1 : public testing::Test { public: static void SetUpTestCase() { std::cout << "环境1第一个TEST之前调用\n"; } static void TearDownTestCase() { std::cout << "环境1最后一个TEST之后调用\n"; } public: std::unordered_map<std::string, std::string> dict;
}; // 注意,测试套件使用的不是TEST了,而是TEST_F, 而第一个参数名称就是测试套件环境类名称
// main函数中不需要再注册环境了,而是在TEST_F中可以直接访问类的成员变量和成员函数
TEST_F(HashTestEnv1, insert_test) { std::cout << "环境1,中间insert测试\n";dict.insert(std::make_pair("Hello", "你好")); dict.insert(std::make_pair("hello", "你好")); dict.insert(std::make_pair("雷吼", "你好")); auto it = dict.find("hello"); ASSERT_NE(it, dict.end());
}
TEST_F(HashTestEnv1, sizeof) { std::cout << "环境1,中间size测试\n"; ASSERT_GT(dict.size(), 0);
} int main(int argc, char *argv[])
{ testing::InitGoogleTest(&argc, argv); return RUN_ALL_TESTS();
} 运行结果:
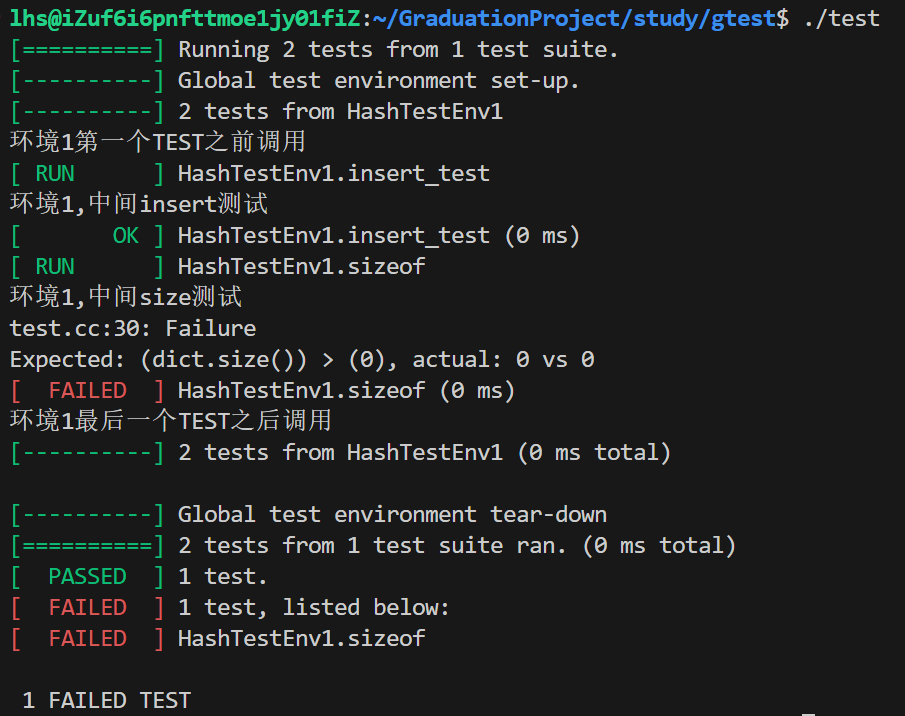
能够看到在上例中,有一个好处,就是将数据与测试结合到同一个测试环境类中了, 这样与外界的耦合度更低,代码也更清晰。 但是同样的,我们发现在两个测试用例中第二个测试用例失败了,这是为什么呢?这就涉及到了TestCase事件的机制:
3.3 TestCase事件
针对一个个测试用例。测试用例的事件机制的创建和测试套件的基本一样,不同地方 在于测试用例实现的两个函数分别是SetUp和TearDown, 这两个函数也不是静态函数
● SetUp()函数是在一个测试用例的开始前执行
● TearDown()函数是在一个测试用例的结束后执行
也就是说,在TestSuite/TestCase事件中,每个测试用例,虽然它们同用同一个事件 环境类,可以访问其中的资源,但是本质上每个测试用例的环境都是独立的,这样我 们就不用担心不同的测试用例之间会有数据上的影响了,保证所有的测试用例都使用 相同的测试环境进行测试。
//TestCase:测试用例的单元测试,即针对每一个测试用例都使用独立的测试环境数据进行测试
//概念:它是针对测试用例进行环境配置的一种事件机制
//用法:先定义环境类,继承于 testing::Test 基类, 在环境类内重写SetUp/TearDown接口
#include<gtest/gtest.h>
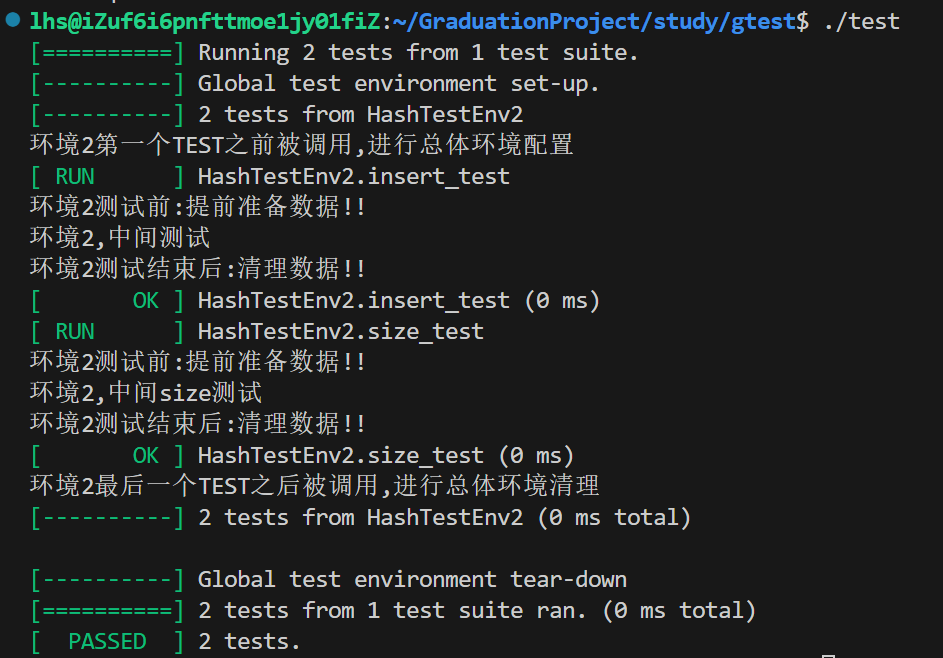
#include<iostream>class HashTestEnv2 : public testing::Test { public: static void SetUpTestCase() { std::cout << "环境2第一个TEST之前被调用,进行总体环境配置\n"; } static void TearDownTestCase() { std::cout << "环境2最后一个TEST之后被调用,进行总体环境清理\n"; } virtual void SetUp() override{ std::cout << "环境2测试前:提前准备数据!!\n"; dict.insert(std::make_pair("bye", "再见")); dict.insert(std::make_pair("see you", "再见")); } virtual void TearDown() override{ std::cout << "环境2测试结束后:清理数据!!\n"; dict.clear();} public: std::unordered_map<std::string, std::string> dict; }; TEST_F(HashTestEnv2, insert_test) { std::cout << "环境2,中间测试\n"; dict.insert(std::make_pair("hello", "你好")); ASSERT_EQ(dict.size(), 3);
} TEST_F(HashTestEnv2, size_test) { std::cout << "环境2,中间size测试\n"; auto it = dict.find("hello"); ASSERT_EQ(it, dict.end()); ASSERT_EQ(dict.size(), 2);
} int main(int argc, char *argv[])
{ testing::InitGoogleTest(&argc, argv); RUN_ALL_TESTS(); return 0;
} 运行结果: