鸿蒙语言基础
准备工作
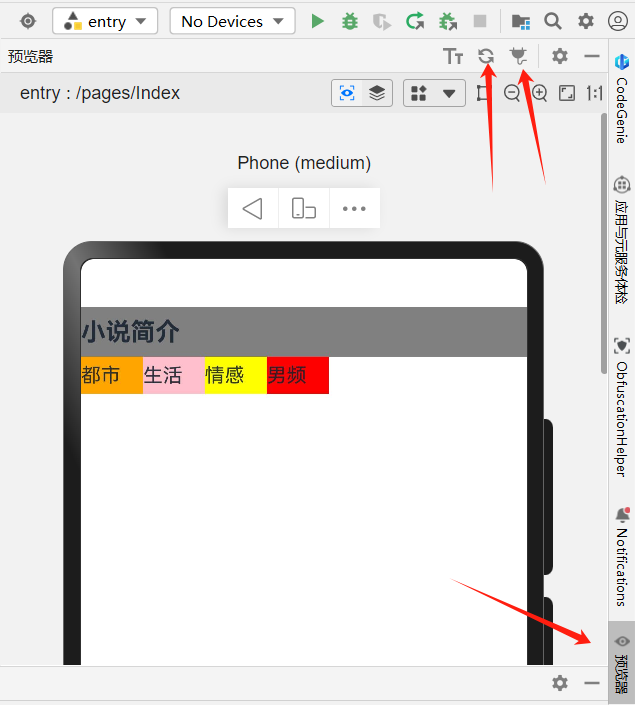
去鸿蒙官网下载开发环境
点击右侧预浏览,刷新和插销按钮,插销表示热更新,常用按钮。
基础语法
string number boolean const常量 数组
let s : string = "1111";
console.log("string", s);let n : number = 1;
console.log("number", n);let bool : boolean = true;const PI= "asdfasdf";
console.log(PI);let numbers = [1, 2, 3, 4, 5, 6];
console.log("arr", numbers);接口
实现接口时,必须实现所有的属性和方法
interface HI{a : string;b : number;c : boolean;sing : (song:string) => void;dance : ()=>void;
}let person: HI = {a : "123",b : 1,c : true,sing : (song:string)=>{console.log("唱首歌", song);},dance : ()=>{}
}
console.log("1", person.a, person.b, person.c);
person.sing("爱的供养");
function fun(){}联合类型
// 1
let judge : number | string = 100;
judge = "A";// 2
let gender : 'man' | 'woman' = 'man';枚举类型
enum ThemeColor {Red = '#ff0f29',Orange = '#ff7110',Green = '#30b30e'
}
let color : ThemeColor = ThemeColor.Red;字符串拼接
字符串+数字
数字+字符串
字符串+ 字符串
只要一边是字符串就是拼接。
模板字符串
``里面可以使用变量,方便多个字符串的拼接。

数字和字符串转换
需要注意的是:
parseInt('1.1a') 直接取整,忽略0.1a
parseFloat('1.1a') 1.1
parseFloat('1.a1') 1
也就是说,parseFloat在遇到非数字时就会截断。


点击事件
.onClick(),参数为一个回调函数
Button('按钮').onClick(()=>{AlertDialog.show({message : '弹窗'})
})状态管理
注意:struct里的变量必须用this访问且不能使用let定义。
小技巧:点击预览器上面的T标志,可以使用鼠标定位元素对应的代码。

数组操作
添加:
arr.unshift(); //从开头增加,返回操作后数组长度
arr.push(); //从结尾增加,返回操作后数组长度
删除:
arr.shift(); //从开头删除,返回删除的项
arr.poll(); //从结尾删除,返回删除的项
在指定位置增加/删除n个元素:
arr.splce(起始位置, 删除个数, 新增元素1, 新增元素2, ...);
if语句
小括号结果不是布尔类型时,会类型转换为布尔值
if(0、空串、null和undefine)这几种均视为false
其他非空值(如对象)均视为true,如空数组和空对象:if( [] )、if( {} )
for...of

对象数组
不能直接使用对象输出,要使用JSON.stringify(对象);
interface Person {name : string,age : number
}
let arr : Person[] = [{name:"111",age: 1},{name:"222", age: 2}
]
console.log("", arr[1]); //[object Object]
for (let item of arr){console.log(JSON.stringify(item));
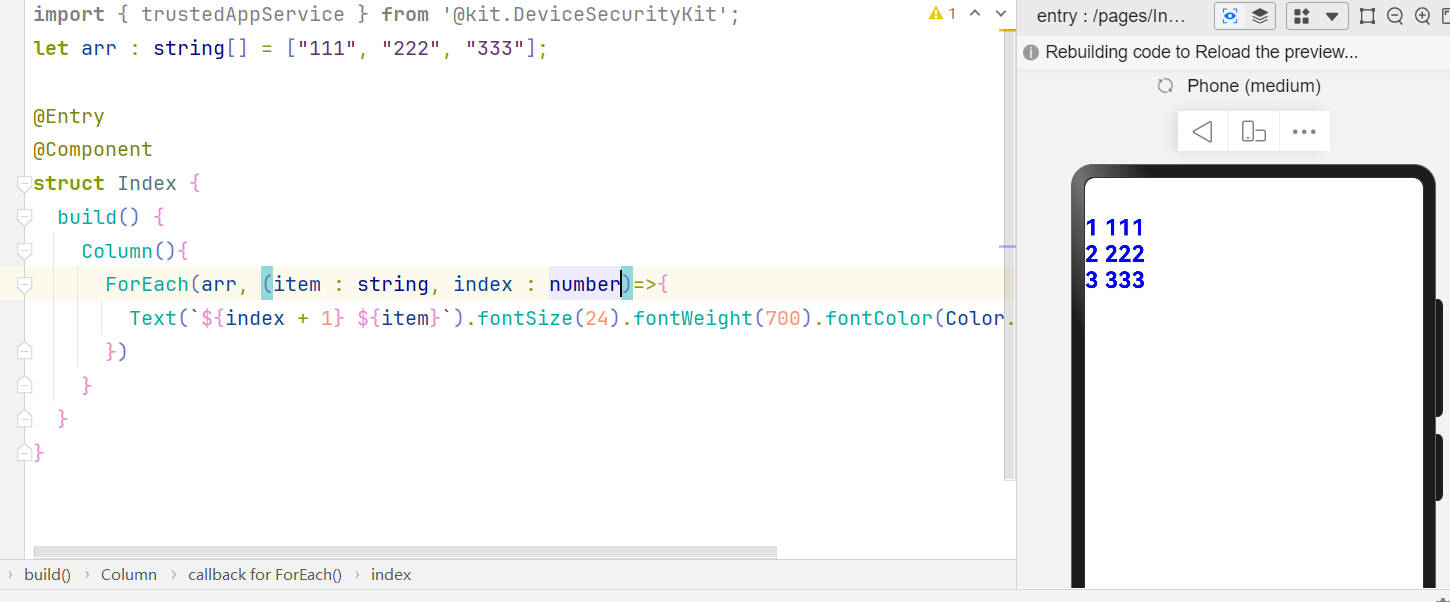
}ForEach—— 渲染控制
注意使用ForEach时,item需要指定类型,index指不定都行,建议写上。
class
类是用于 创建对象 模板。同时类声明也会引入一个 新类型,可定义其 实例属性、方法 和 构造函数。
一般定义更加复杂的类型时就不适用接口了而使用Class。
1、实例属性:在定义class时必须赋初值,或者使用可选链操作符 ?. 来定义属性
2、不同实例,将来需要有不同的字段初始值,就需要通过构造函数实现
构造函数使用关键字:constructor 来定义,在new对象时调用。如果参数多可是传一个对象,这样可以自由顺序赋值。
3、方法:方法的返回值可以写在函数名之后,用冒号隔开,即:这个函数的类型时返回值类型的。
4、静态属性、方法:一般用作工具属性方法,用类名直接调用。
interface IFood {name : string,price : number,desc : string
}class Food {// 1、属性name : stringprice : numberdesc : stringa ?: number// 2、构造constructor(mesObj:IFood) {this.name = mesObj.namethis.price = mesObj.pricethis.desc = mesObj.desc}// 3、方法sayHi(name:string):void{console.log(this.name, name);}// 4、静态属性、方法static num:numberstatic func(){}
}5、继承extend和super关键字
类可以通过 继承 快速获取另外一个类的 字段 和 方法。只支持单一继承。
子类通过 super 可以访问父类的实例字段、实例方法和构造函数。
super.属性
super.方法
super(1, 2) //调用父类构造
6、instanceof 类型检测
实例对象 instanceof 类型
typeof 表达式 : 只能检测简单类型,对象类型结果均为Object。
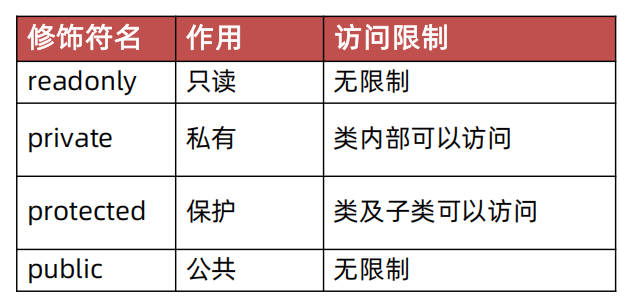
7、修饰符
ArkUI
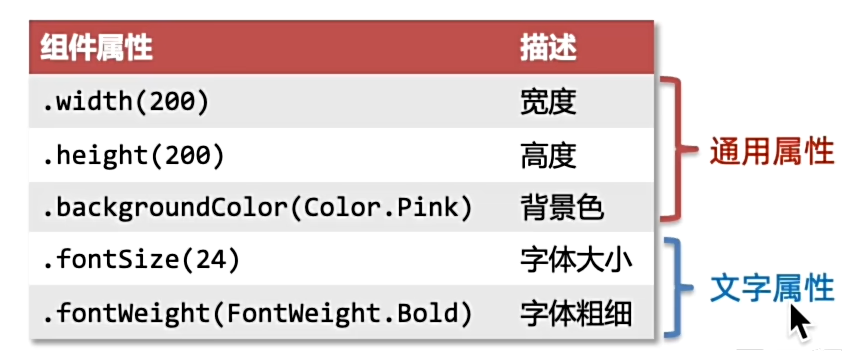
构建页面思路:排版 -> 内容 -> 美化
一般先设置Column为列,Row为行。这两个均为容器组件。
build的最外层只能有一个容器组件,也就是root节点(只能有一个根节点)
设置居左:Column和Row都设置width('100%')
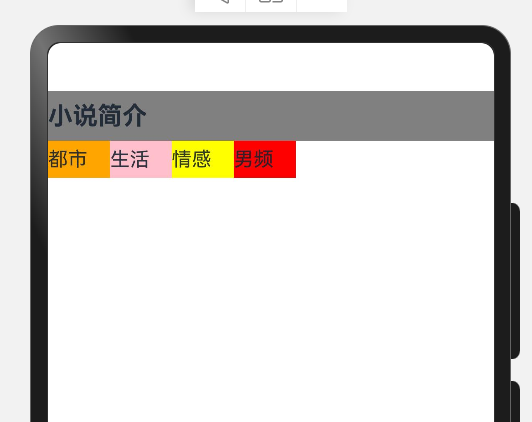
struct Index {@State message: string = 'Hello World';build() {Column(){ //build的最外层只能有一个容器组件,也就是root节点;容器组件//Text为基础组件Text("小说简介").width('100%').fontSize(20).fontWeight(FontWeight.Bold).backgroundColor(Color.Grey).height(40)Row(){Text("都市").width(50).height(30).backgroundColor(Color.Orange)Text("生活").width(50).height(30).backgroundColor(Color.Pink)Text("情感").width(50).height(30).backgroundColor(Color.Yellow)Text("男频").width(50).height(30).backgroundColor(Color.Red)}.width('100%')}.width('100%')}
}显示页面
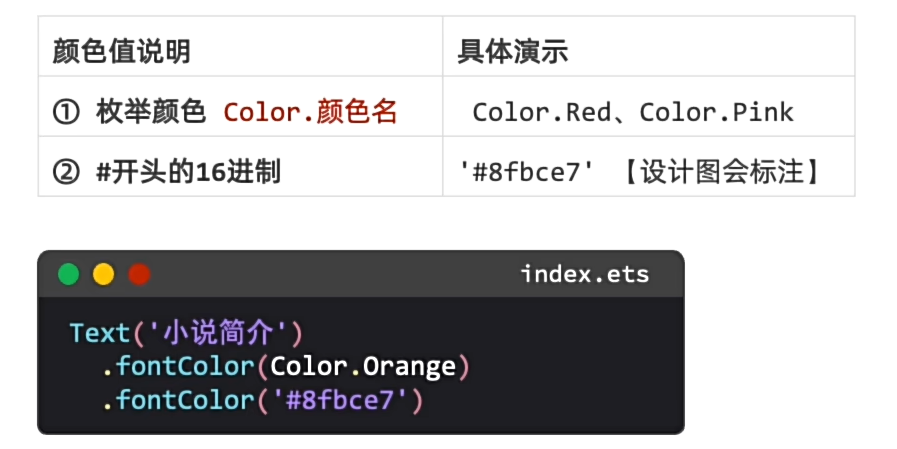
文字色值写法:2种
文字溢出省略、行高

注意:textOverflow需要传一个对象进去,可以使用lineHeight设置行高。
Text('12345678901234567890123456789012345678901234567890' +'12345678901234567890123456789012345678901234567890').textOverflow({overflow:TextOverflow.Ellipsis}).maxLines(2).lineHeight(30)图片组件
给图片设置一致的宽高比:.aspectRatio(2.4) 宽 / 高
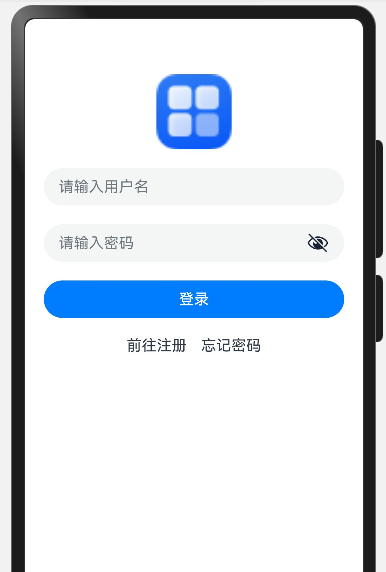
输入框与按钮
调整组件之间的间隙:Column({space:10})

Column({space:10}){TextInput({placeholder:'用户名'})TextInput({placeholder:'密码'}).type(InputType.Password)Button('登录').width(200)
}显示展示:

登录案例
使用column.width('100%')使图片居中;
使用column.padding(20)调整内边距;
使用Column({space : 20}) 和 Row({space : 20})调整元素之间距离。
build() {Column({space:20}){Image($r('app.media.app_icon')).width(80)TextInput({placeholder : "请输入用户名"})TextInput({placeholder : "请输入密码"}).type(InputType.Password)Button("登录").width('100%')Row({space:15}){Text("前往注册")Text("忘记密码")}}.width('100%').padding(20)svg图标
任易放大缩小不失真,可以改颜色。
可以使用官方的图标库进行下载:鸿蒙图标库
https://developer.huawei.com/consumer/cn/design/harmonyos-icon/
布局元素(盒子模型)
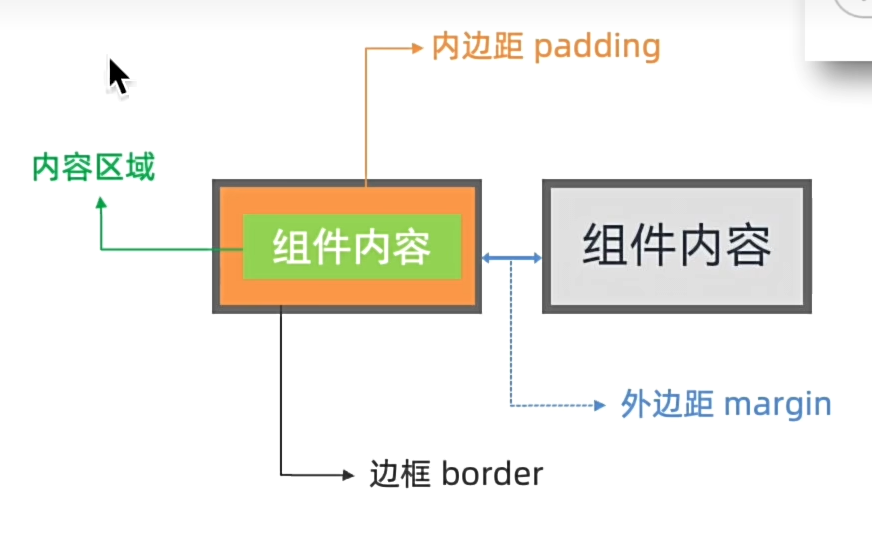
margin - border - padding
传参数{space : 1}也可是设置外边距,但是只能设置统一值,margin可以单独设置;
如果值统一,可以直接设置数值,如果不统一,可以传对象;
border样式有三种:实线、虚线、点线。
build() {Column(){Text('刘备').backgroundColor(Color.Gray).padding(20).margin(20).border({width : 3,color : Color.Blue,style : BorderStyle.Dotted})Text('关羽').backgroundColor(Color.Orange).padding(20).margin(20).border({width : {left:1, top:2, right:3, bottom:4},color : { left:Color.Blue, top:Color.Brown, right:Color.Green, bottom:Color.Red },style : BorderStyle.Solid})Text('张飞').backgroundColor(Color.Pink).padding({left : 20,top : 20,right : 20,bottom : 20}).margin(20)}}设置圆角
Text('刘备').backgroundColor(Color.Gray).padding(20).margin(20).border({width : 3,color : Color.Blue,style : BorderStyle.Dotted
}).borderRadius(30).borderRadius({topLeft:10, topRight:20, bottomLeft:30, bottomRight:40})正圆:width、height均为100,圆角设置为50。
胶囊按钮:width为100,height为50,圆角设置为25。
背景属性

图片:
.backgroundImage($r('app.media.startIcon'))//可以使用一个参数
.backgroundImage($r('app.media.startIcon'), ImageRepeat.XY) //两个参数可以设置平铺
位置:
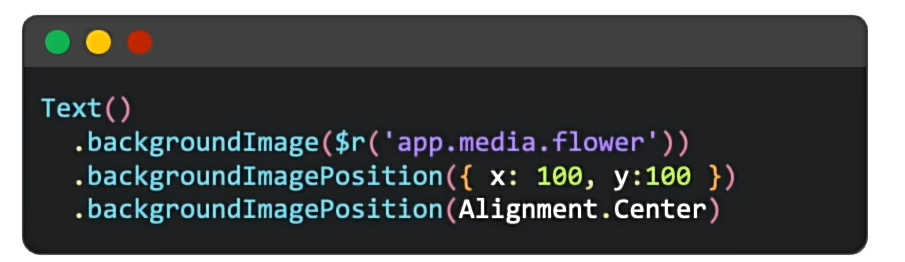
其中的100是虚拟像素,vp。对于不同设备会自动转换,保证不同设备视觉效果一致(推荐)。
可以使用vp2ps()转换,但是现在可能已经直接使用了,不需要转换。
大小(缩放):

组件排布(对齐)——线性布局
justifyContent(FlexAlign.Center);
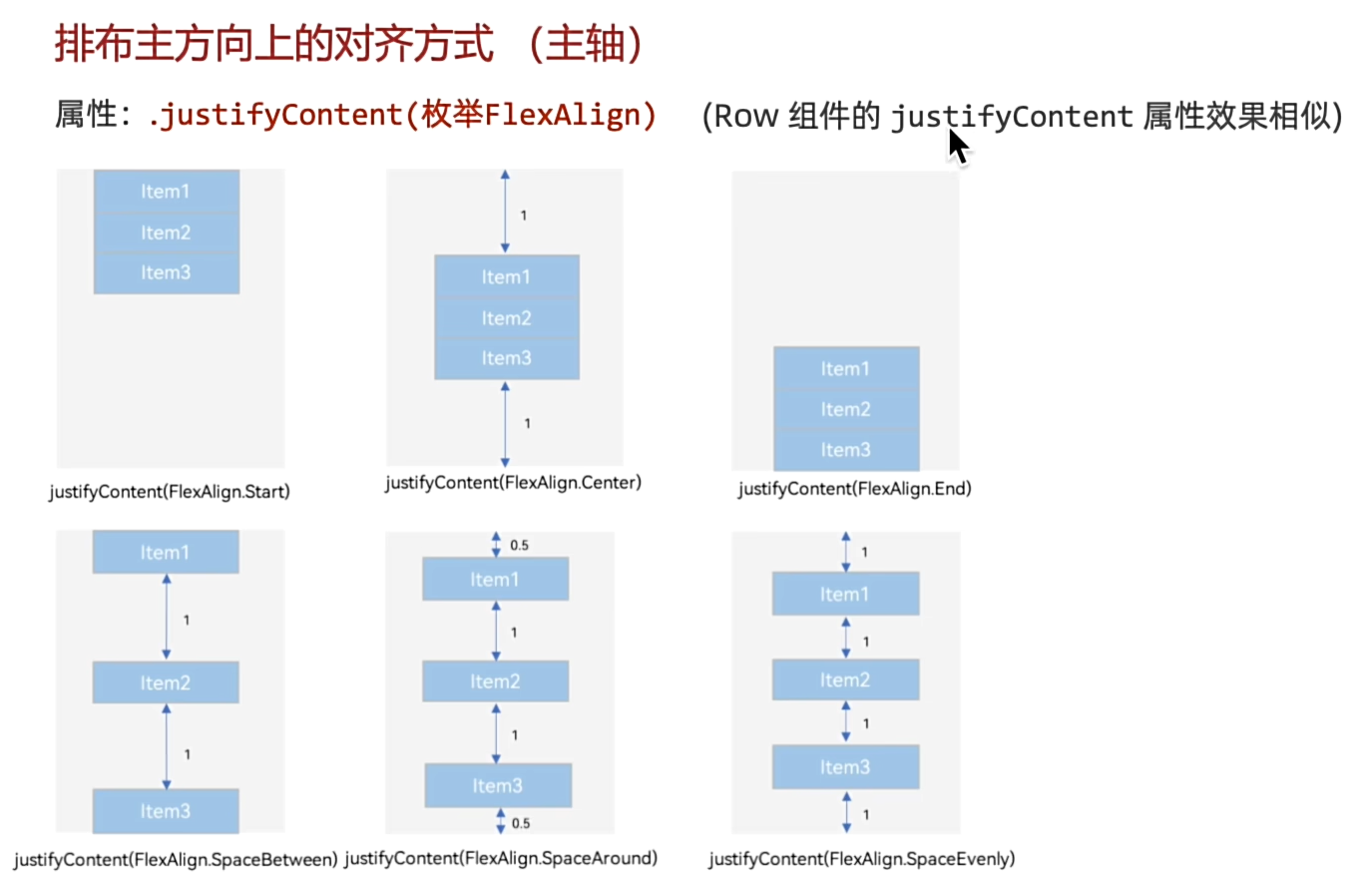
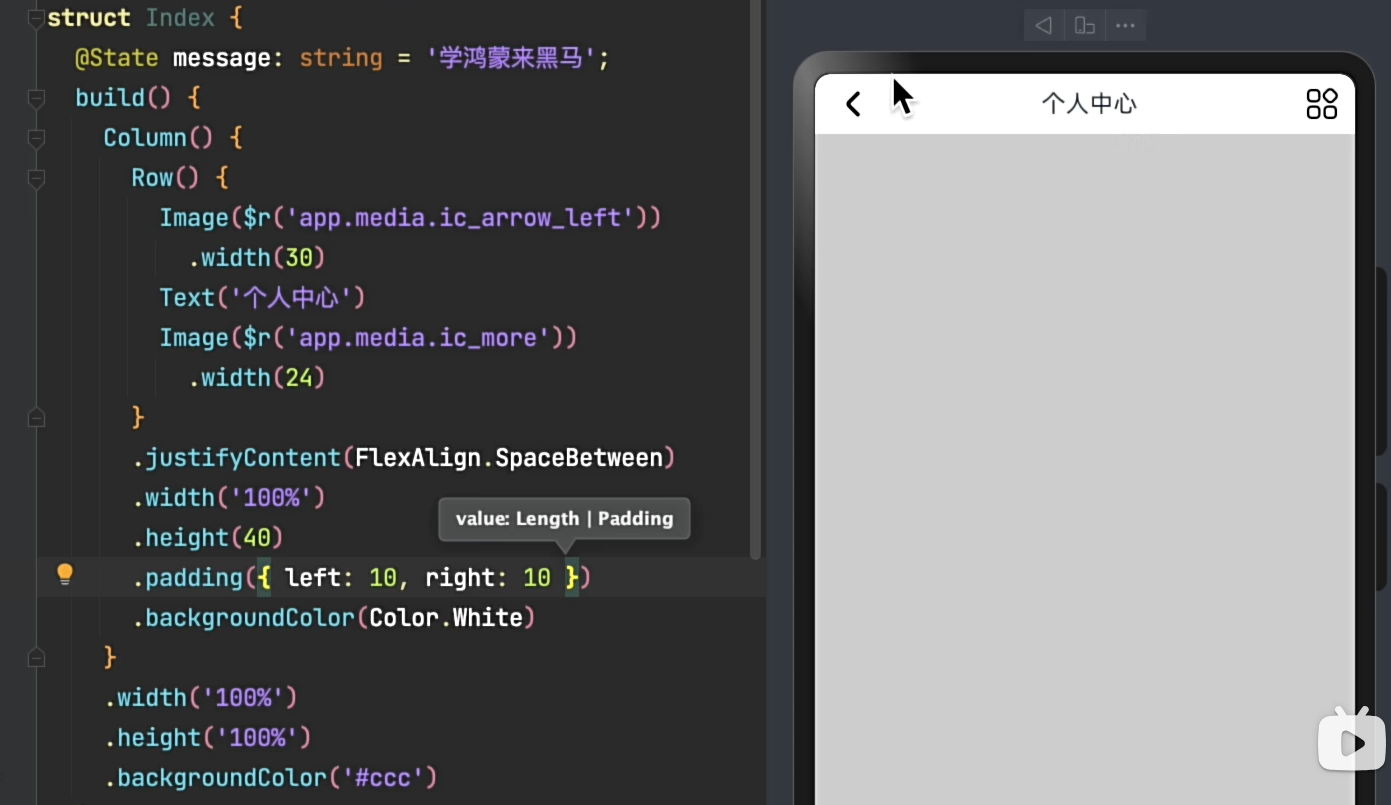
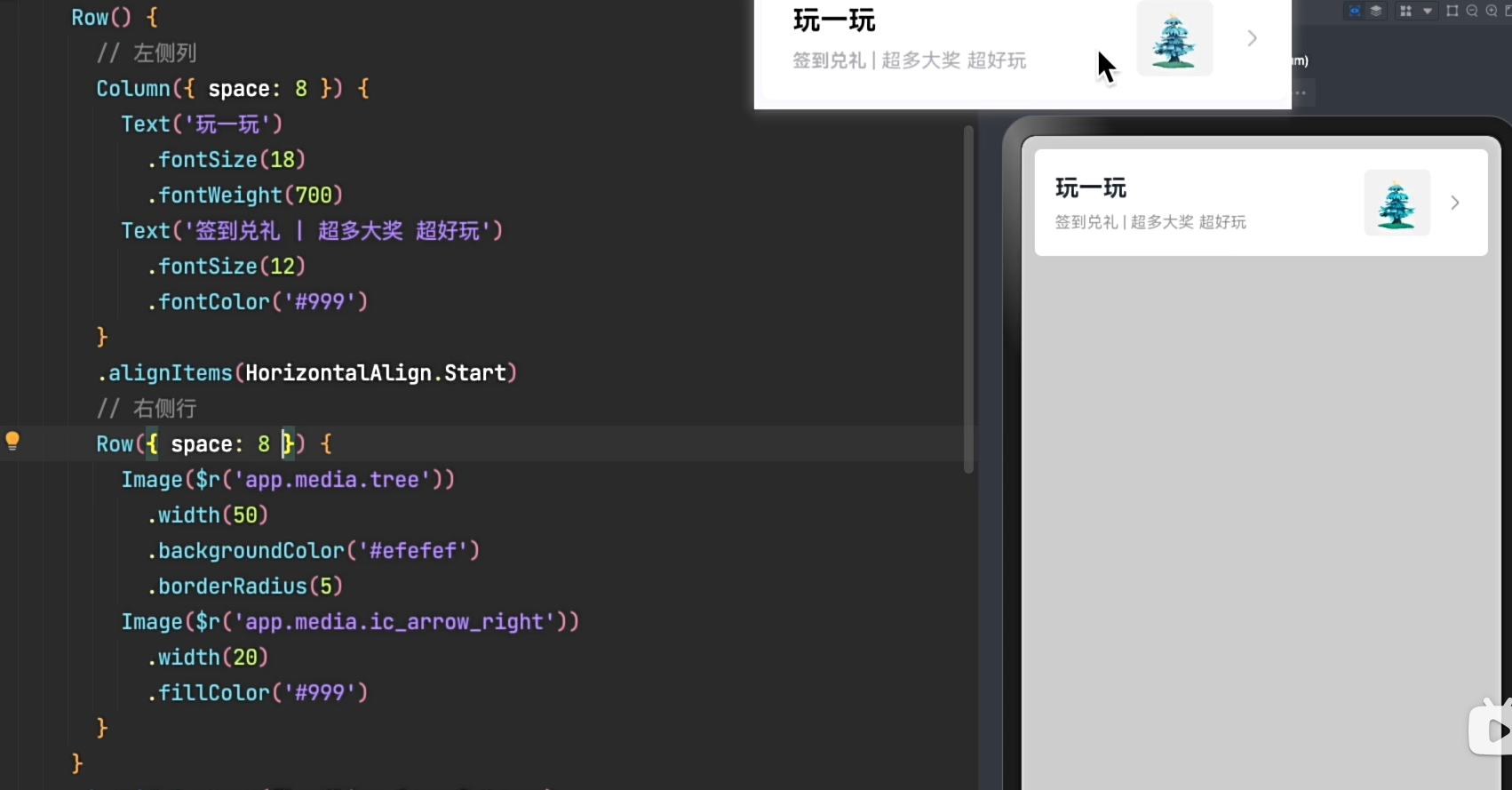
个人中心元素对齐案例:
交叉轴
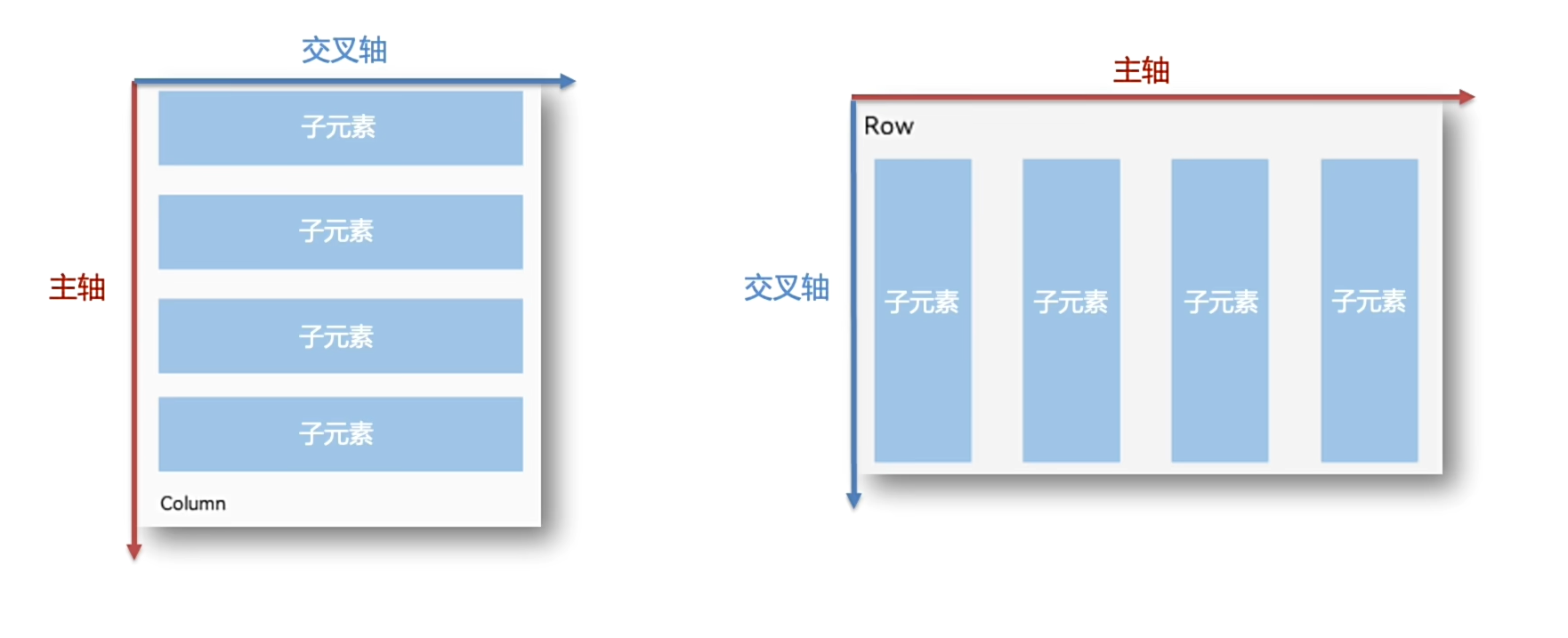
对齐方式:
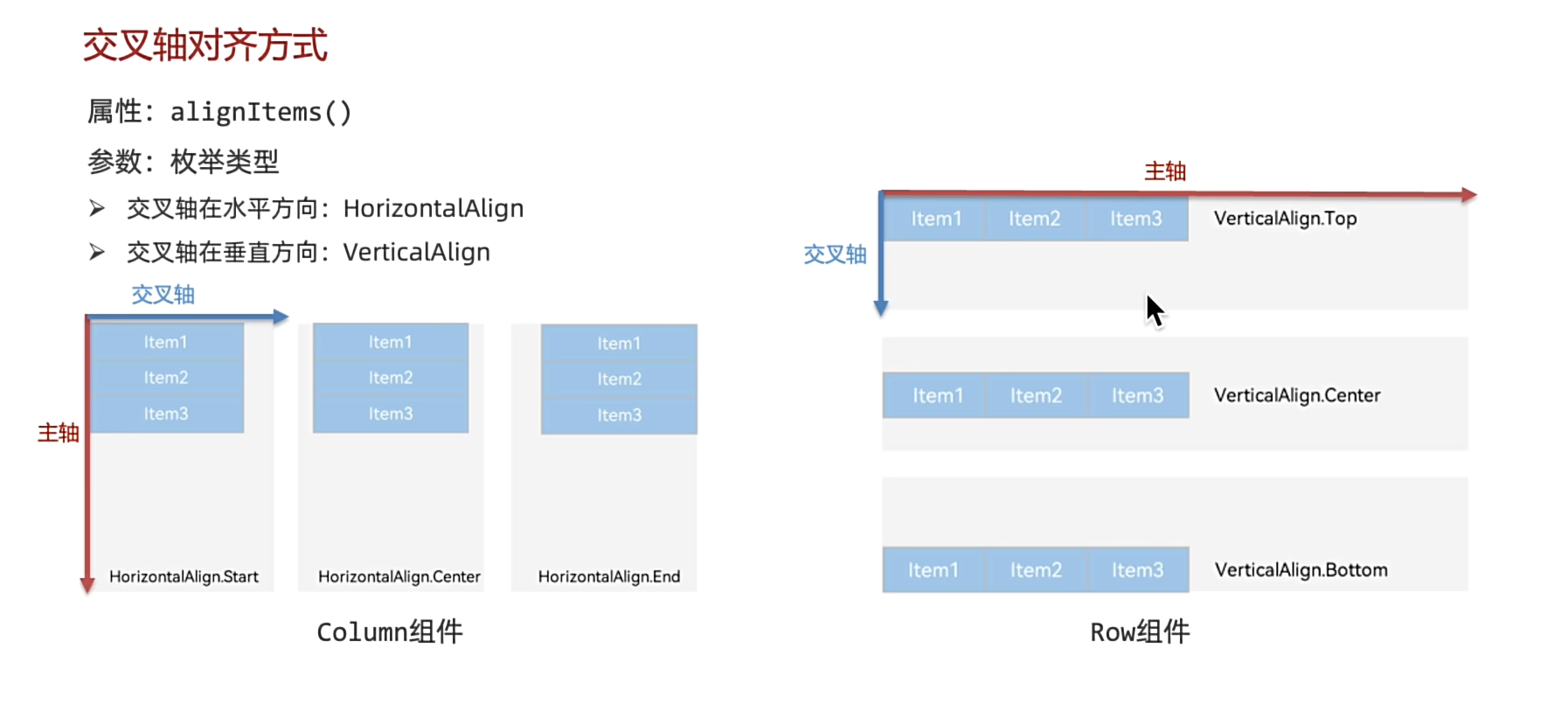
案例:既用到主轴对齐,有用到交叉轴对齐。
自适应伸缩.layoutWeight
按照份数权重,分配剩余空间。
layoutWeight(1),1表示在剩余的空间里占一份,不需要自适应的设置一个固定值即可。
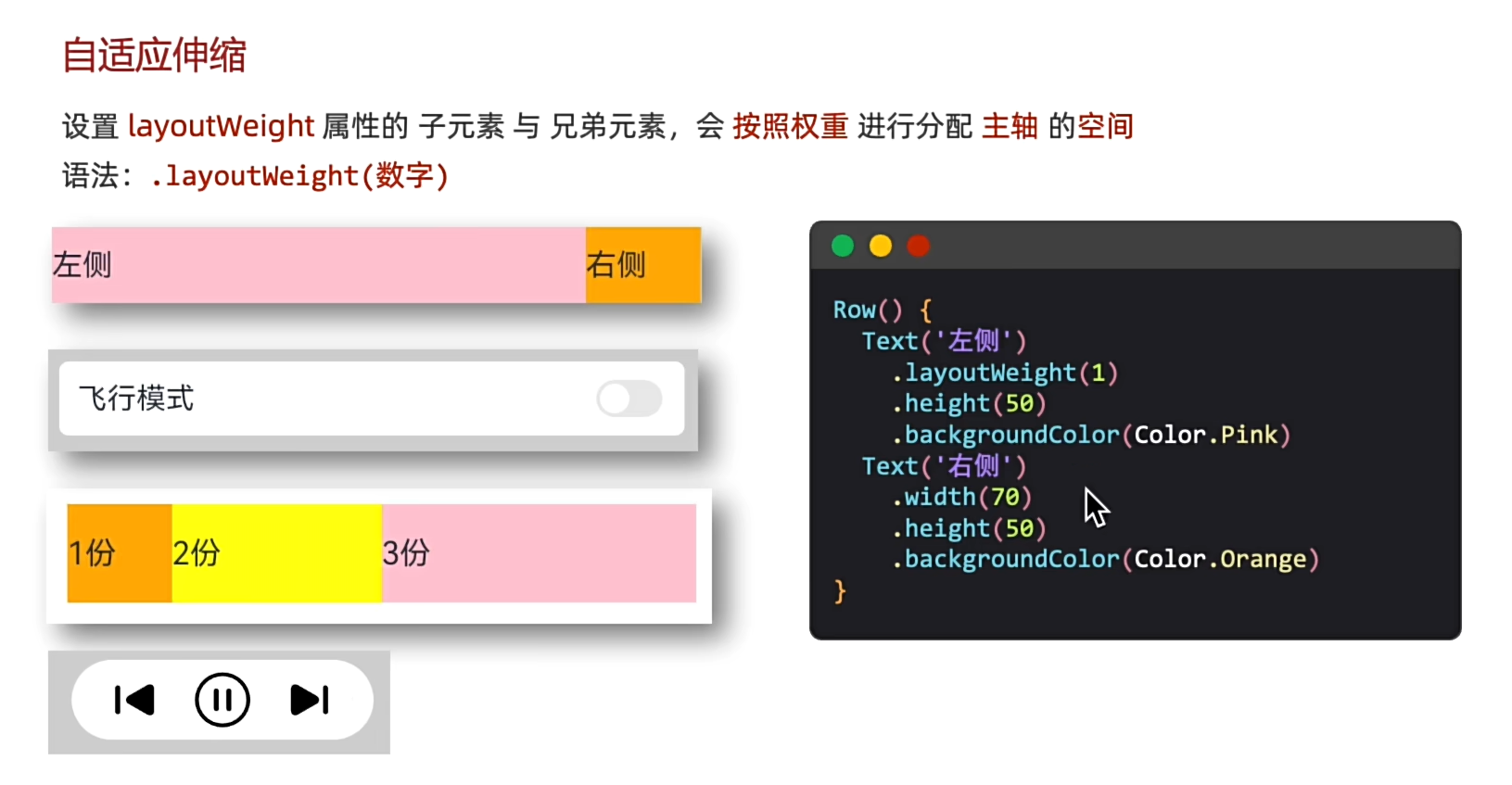
build() {Column(){Row(){Text("1").height(100).backgroundColor(Color.Brown).layoutWeight(1)Text("2").width(100).height(100).backgroundColor(Color.Gray).layoutWeight(1)Text("3").width(100).height(100).backgroundColor(Color.Pink)}}}弹性布局

上图中123和线性布局基本一样,重点在4.布局换行中使用弹性布局。
单行或者单列的情况,还是优先使用线性布局(线性布局底层就是根据Flex去设计的。),而且还做了性能优化。
Flex布局:伸缩布局。当子盒子的总和溢出父盒子,默认进行压缩显示。
适用的情况:如上图阶段选择案例,多行且不规则排列的场景。
Flex是伸缩布局:
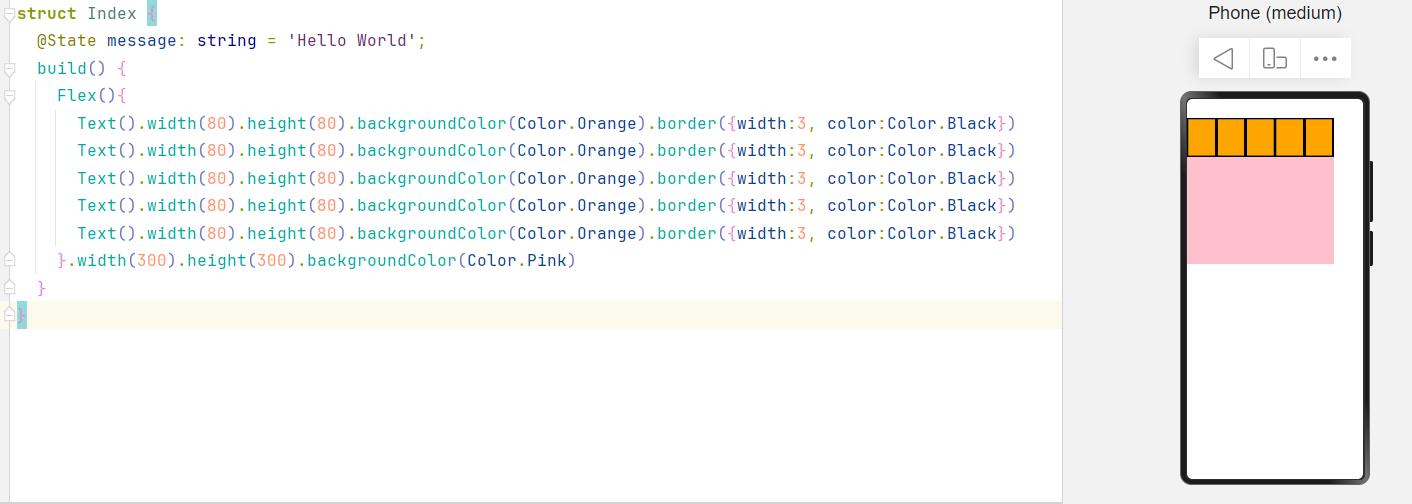
设置wrap后:

绝对定位和层级.position

默认后面的元素层级高于前面的元素,可以使用zIndex调整层级,使用zIndex时其他元素默认为0级。

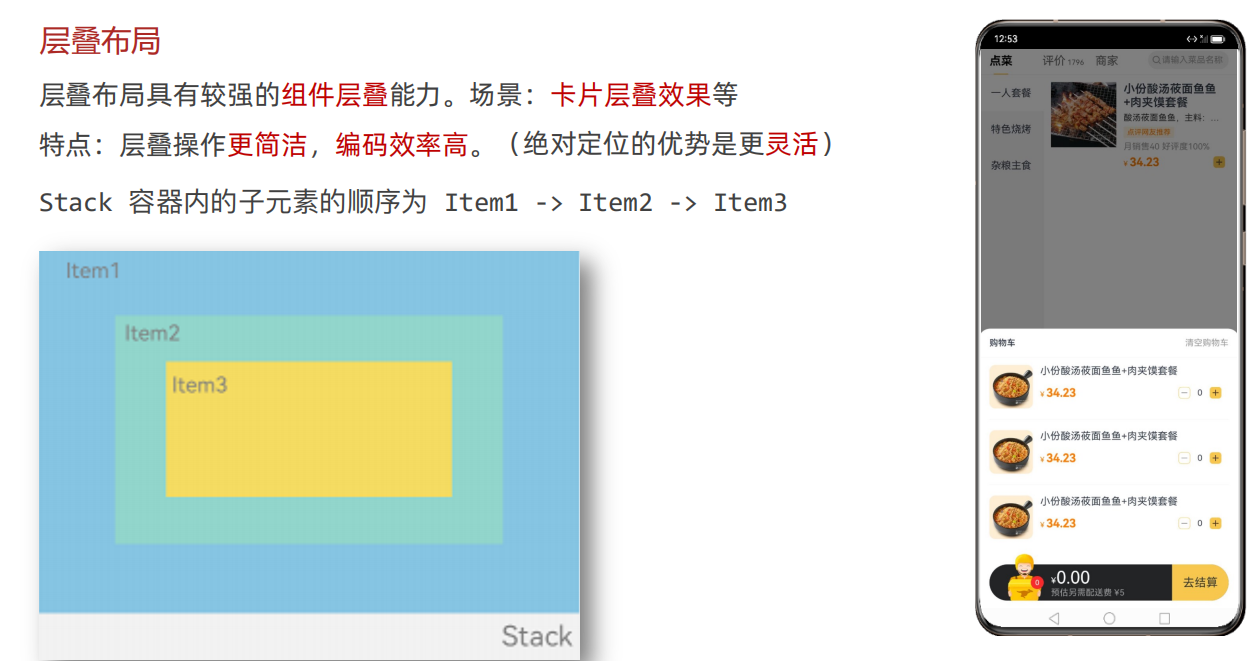
层叠布局
小技巧:使用Ctrl+p在参数传对象时,可以直接看到对象的参数类型。
在使用绝对定位比较麻烦的时候,可以使用层叠布局,使得代码更简洁。


弹簧组件Blank
Blank()在两个组件之间添加,撑开中间的空间。
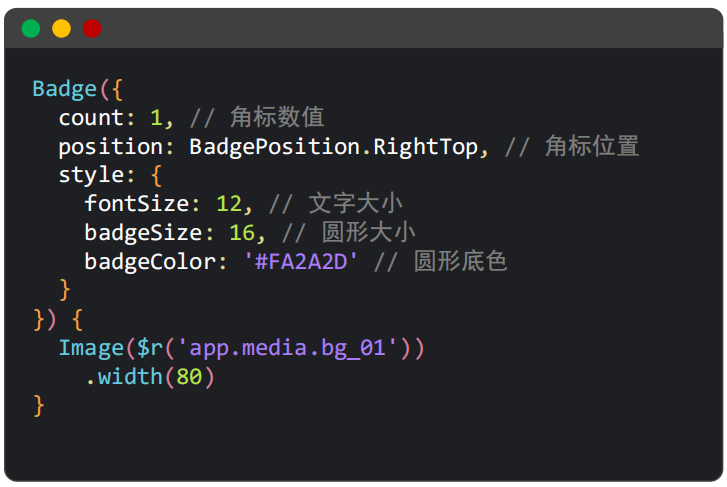
Badge角标组件
用Badge包裹在需要角标的组件外。
Badge组件只能将角标放在右上、中左、中右三个位置,其他位置需要角标可以使用绝对定位来做。
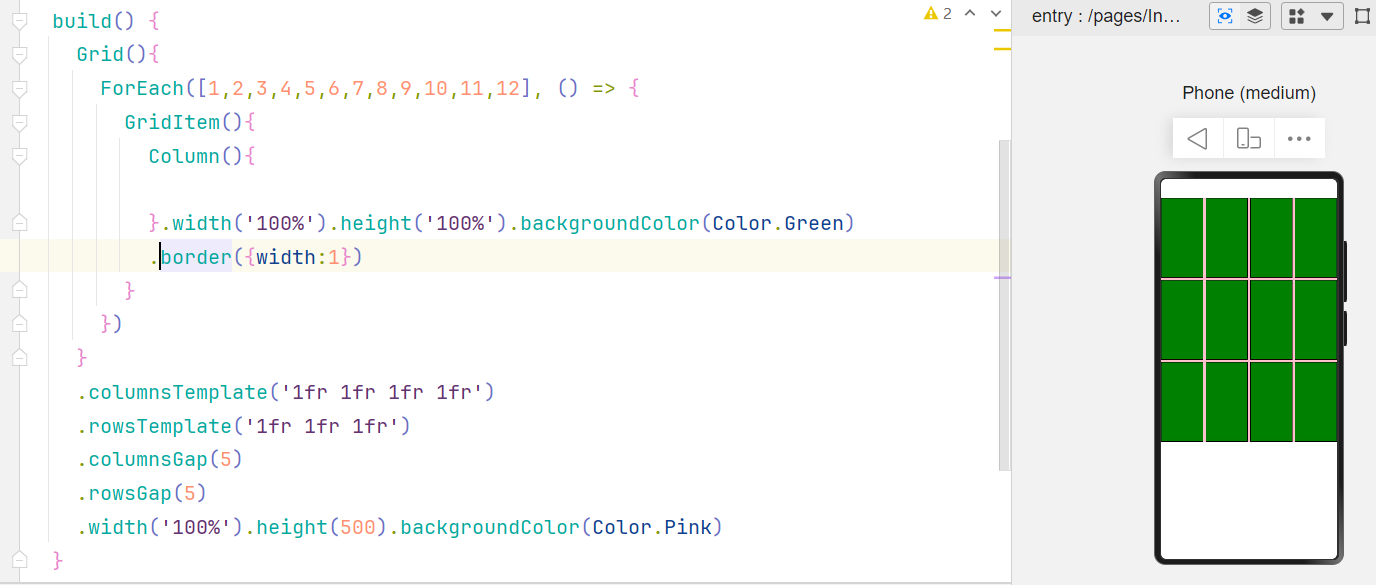
网格布局Grid
GridItem中只能有且只有一个子元素,即代码中的Column;
1fr调整分几份;
Gap调整中间的间隙。
图中的左边缝隙最大,是视觉效果,图片放大后并无差异。
蒙层设置
使用层叠布局Stack,点击立即抽卡,提高蒙层的zIndex。设置透明度和动画缩放。

抽卡完整功能代码
注意随机抽卡中,修改对象数组中对象的某个值,需要修改整个对象,即arr[index] = {},重新传入一个对象,这是因为监听一个变量消耗的性能很高,对象中的数据很多的话会浪费性能。
在验证是否集齐6张卡片的时候,可以使用假设成立法,for之前定义一个flag,for中count均>0那么修改flag,最后给外部的isget(获得大奖)变量赋值。
// 定义接口 (每个列表项的数据结构)
interface ImageCount {url: stringcount: number
}// 0 1 2 3 4 5
// [0,1) * 6 => [0,6)
// 求随机数: Math.random
// 向下取整: Math.floor
// console.log('随机数', Math.floor(Math.random() * 6))@Entry
@Component
struct Index {// 随机的生肖卡序号 0-5@State randomIndex: number = -1 // 表示还没开始抽// 基于接口, 准备数据@State images: ImageCount[] = [{ url: 'app.media.bg_00', count: 0 },{ url: 'app.media.bg_01', count: 0 },{ url: 'app.media.bg_02', count: 0 },{ url: 'app.media.bg_03', count: 0 },{ url: 'app.media.bg_04', count: 0 },{ url: 'app.media.bg_05', count: 0 }]// 控制遮罩的显隐@State maskOpacity: number = 0 // 透明度@State maskZIndex: number = -1 // 显示层级// 控制图片的缩放@State maskImgX: number = 0 // 水平缩放比@State maskImgY: number = 0 // 垂直缩放比// 控制中大奖遮罩的显隐@State isGet: boolean = false@State arr: string[] = ['pg', 'hw', 'xm'] // 奖池@State prize: string = '' // 默认没中奖build() {Stack() {// 初始化的布局结构Column() {Grid() {ForEach(this.images, (item: ImageCount, index: number) => {GridItem() {Badge({count: item.count,position: BadgePosition.RightTop,style: {fontSize: 14,badgeSize: 20,badgeColor: '#fa2a2d'}}) {Image($r(item.url)).width(80)}}})}.columnsTemplate('1fr 1fr 1fr').rowsTemplate('1fr 1fr').width('100%').height(300).margin({ top: 100 })Button('立即抽卡').width(200).backgroundColor('#ed5b8c').margin({ top: 50 }).onClick(() => {// 点击时, 修改遮罩参数, 让遮罩显示this.maskOpacity = 1this.maskZIndex = 99// 点击时, 图片需要缩放this.maskImgX = 1this.maskImgY = 1// 计算随机数 Math.random() [0,1) * (n + 1)this.randomIndex = Math.floor(Math.random() * 6)})}.width('100%').height('100%')// 抽卡遮罩层 (弹层)Column({ space: 30 }) {Text('获得生肖卡').fontColor('#f5ebcf').fontSize(25).fontWeight(FontWeight.Bold)Image($r(`app.media.img_0${this.randomIndex}`)).width(200)// 控制元素的缩放.scale({x: this.maskImgX,y: this.maskImgY}).animation({duration: 500})Button('开心收下').width(200).height(50).backgroundColor(Color.Transparent).border({ width: 2, color: '#fff9e0' }).onClick(() => {// 控制弹层显隐this.maskOpacity = 0this.maskZIndex = -1// 图像重置缩放比为 0this.maskImgX = 0this.maskImgY = 0// 开心收下, 对象数组的情况需要更新, 需要修改替换整个对象// this.images[this.randomIndex].count++this.images[this.randomIndex] = {url: `app.media.img_0${this.randomIndex}`,count: this.images[this.randomIndex].count + 1}// 每次收完卡片, 需要进行简单的检索, 判断是否集齐// 需求: 判断数组项的count, 是否都大于0, 只要有一个等于0,就意味着没集齐let flag: boolean = true // 假设集齐// 验证是否集齐for (let item of this.images) {if (item.count == 0) {flag = false // 没集齐break // 后面的没必要判断了}}this.isGet = flag// 判断是否中奖了, 如果是 需要抽奖if (flag) {let randomIndex: number = Math.floor(Math.random() * 3)this.prize = this.arr[randomIndex]}})}.justifyContent(FlexAlign.Center).width('100%').height('100%')// 颜色十六进制色值,如果是八位,前两位,就是透明度.backgroundColor('#cc000000')// 设置透明度.opacity(this.maskOpacity).zIndex(this.maskZIndex)// 动画 animation, 当我们元素有状态的改变,可以添加animation做动画.animation({duration: 200})// 抽大奖的遮罩层if (this.isGet) {Column({ space: 30 }) {Text('恭喜获得手机一部').fontColor('#f5ebcf').fontSize(25).fontWeight(700)Image($r(`app.media.${this.prize}`)).width(300)Button('再来一次').width(200).height(50).backgroundColor(Color.Transparent).border({ width: 2, color: '#fff9e0' }).onClick(() => {this.isGet = falsethis.prize = ''this.images = [{ url: 'app.media.bg_00', count: 0 },{ url: 'app.media.bg_01', count: 0 },{ url: 'app.media.bg_02', count: 0 },{ url: 'app.media.bg_03', count: 0 },{ url: 'app.media.bg_04', count: 0 },{ url: 'app.media.bg_05', count: 0 }]})}.justifyContent(FlexAlign.Center).width('100%').height('100%').backgroundColor('#cc000000')}}}
}Swiper轮播组件——轮播图
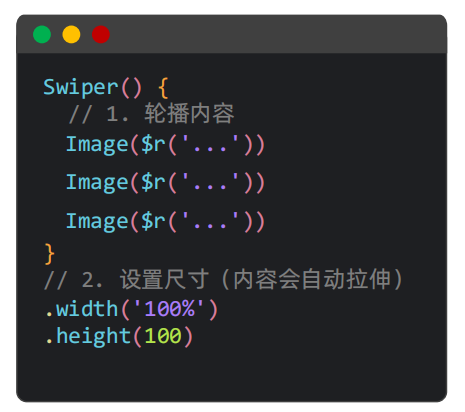
一、基础用法
切记不要在内层设置尺寸,要在Swiper设置。
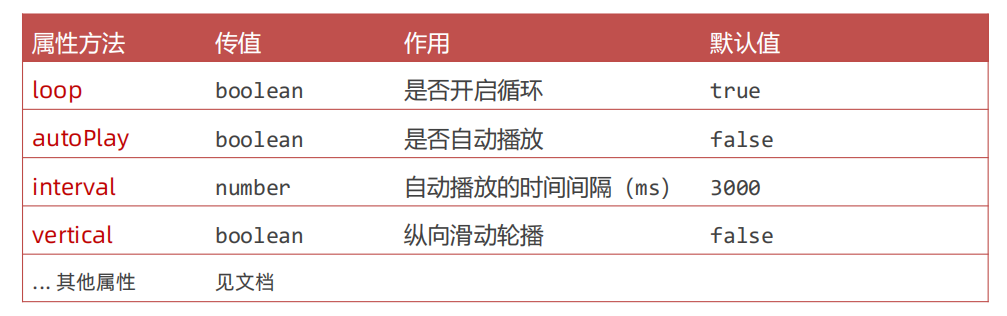
二、常用属性
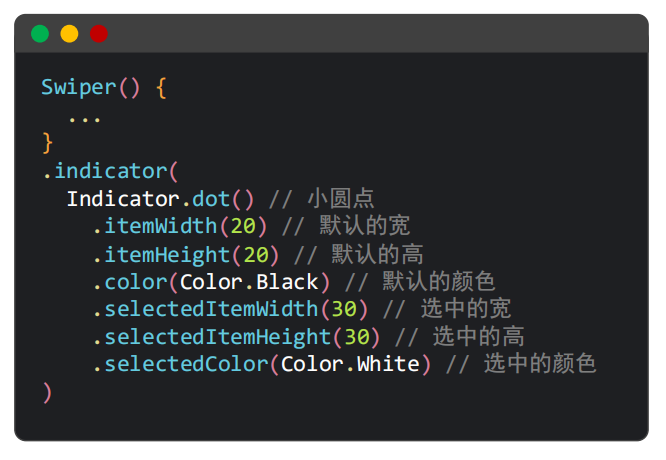
三、自定义属性
自定义圆点,indicator传true/false为打开关闭圆点,前三个设置默认状态下圆点,后三个设置选中状态下圆点。
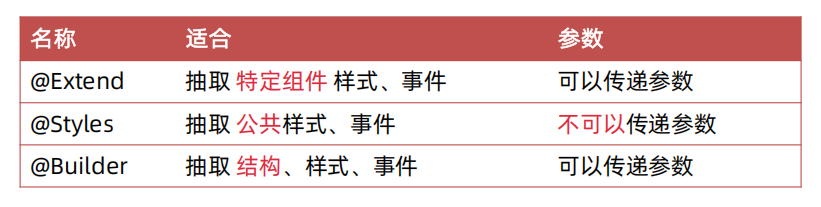
样式和结构的重用
@Extend:针对组件(样式、事件)进行扩展实现复用效果。
可以传参,只能全局定义。
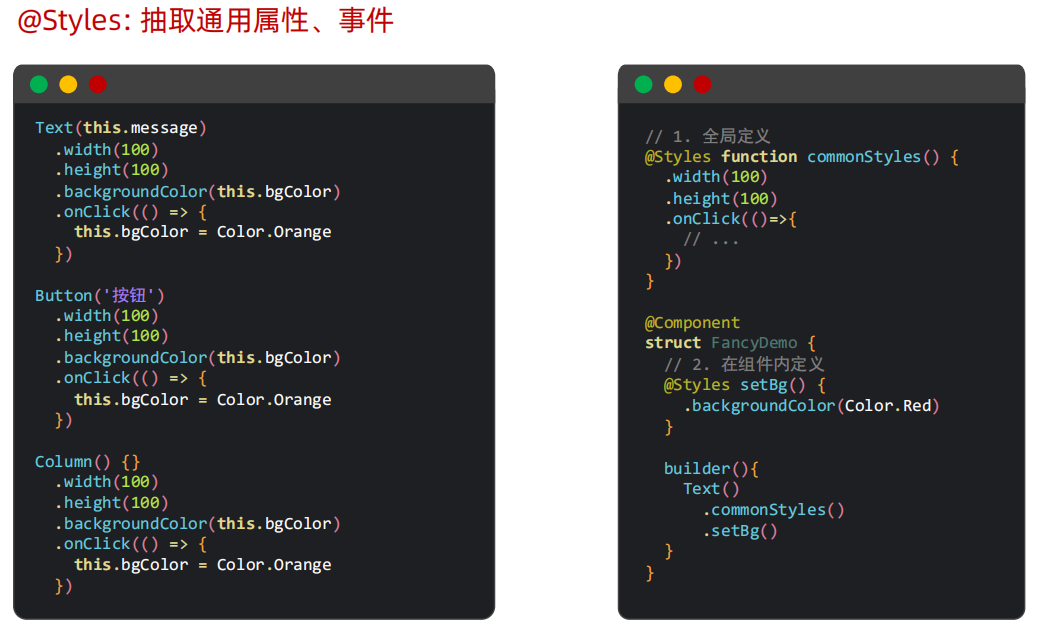
@Styles: 抽取通用属性、事件 实现复用效果。
不可以传参,可以在struct内编写,此时不用加function
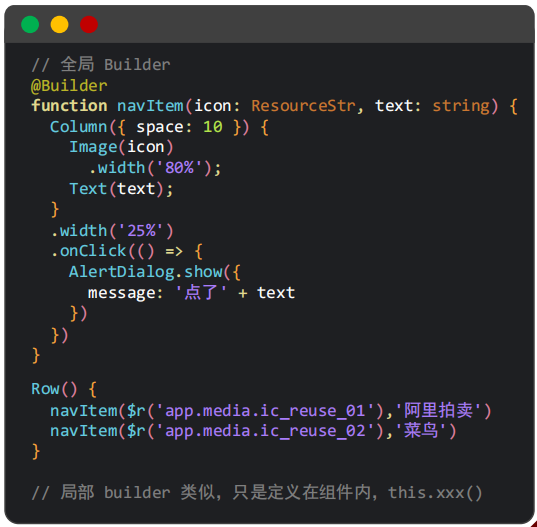
@Builder:自定义构建函数(针对结构、样式、事件进行扩展实现复用)。
可以传参、需要访问内部状态可以在局部定义、可以写结构。
也可以自定义组件来实现,比较简单的可以使用@Builder
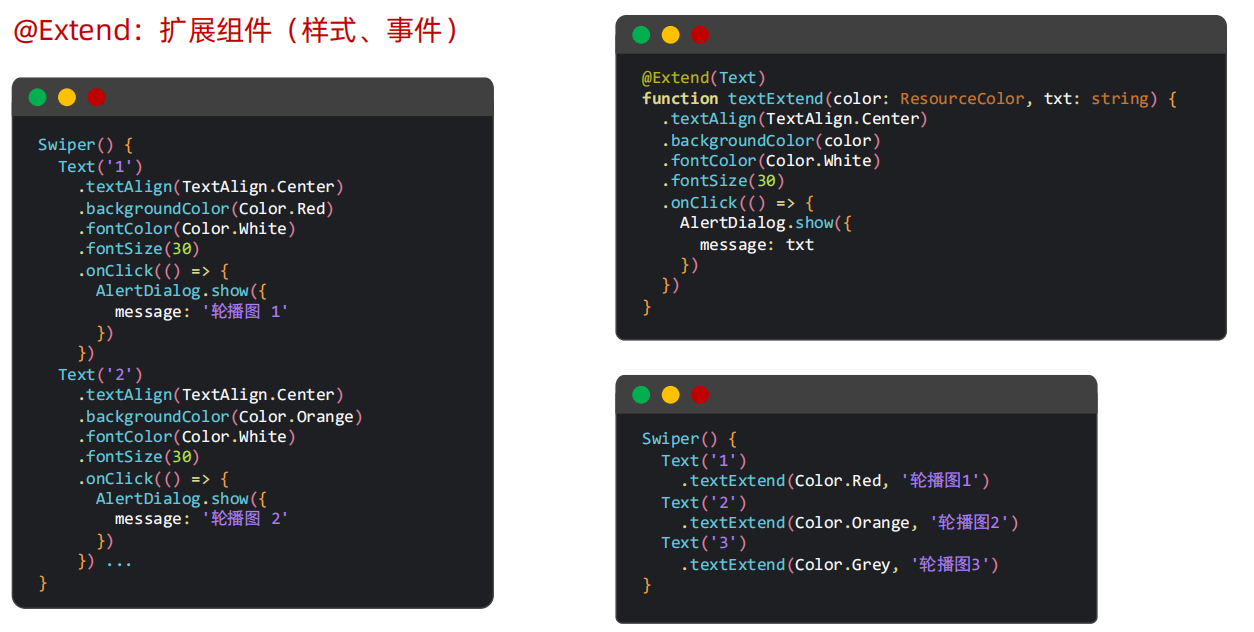
可以全局定义,也可以在组件内定义。 如果需要访问内部效果,必须在组件内定义,这样才能通过this访问到自己的状态。
不同的是,不用点,直接写函数,如下图navItem。可以理解为一个轻量的组件封装。
Scroll
一、核心用法
Scroll内部只支持一个子组件。
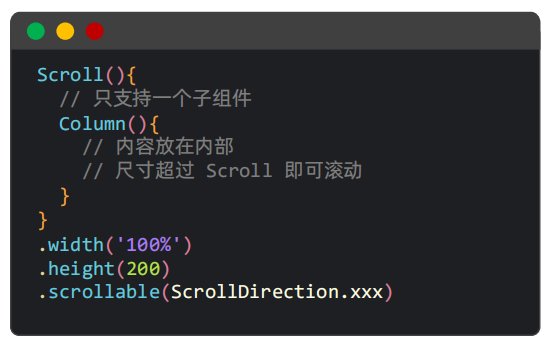
二、常见属性

Scroll(){}
.scrollable(ScrollDirection.Vertical) //纵向滑动
.scrollBar(BarState.Auto) //on一直显示 off隐藏 auto滑动时显示
.scrollBarColor(Color.Orange) //颜色
.scrollBarWidth(20) //宽度
.edgeEffect(EdgeEffect.Spring) //效果三、控制器(返回页面顶部、获取滚动距离)
返回页面顶部;获取滚动距离。
三步走:
1、创建scroller对象;
2、将对象和Scroll绑定;
3、this.scroller.scrollEdge(Edge.Top)。 //也可以用start,效果一样
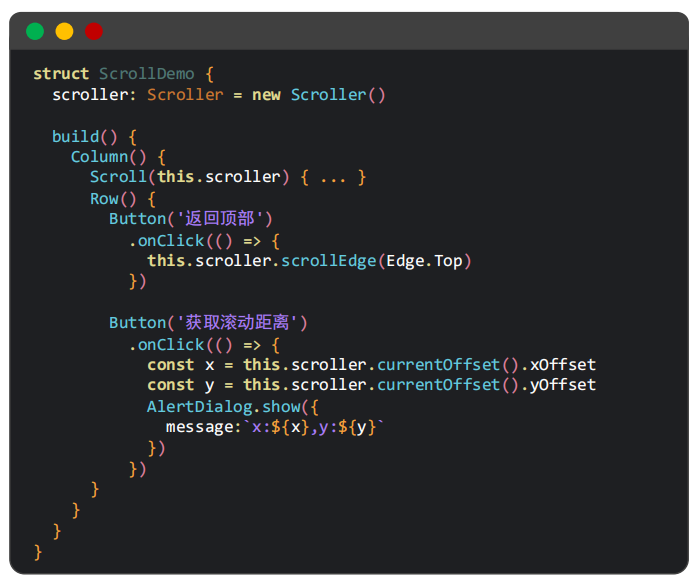
四、事件
案例:超过400显示,反之隐藏。设置一个@state变量存储Y的偏移量,在onscroll中赋值。
if (偏移量 > 400) {
小火箭组件
}
因为添加@state后这个变量就是一个实时变化的值,所以if可以直接写在这里。
Scroll(){}
.onScroll((x, y) => { //滚动时,会一直触发});TabBar组件
基本用法和属性
barPosition :调整位置 开头 或 结尾 (参数)
vertical :调整导航 是否垂直
scrollable :是否 手势滑动 切换
animationDuration :点击滑动动画时间
@Entry
@Component
struct Index {build() {Tabs({barPosition:BarPosition.End}){TabContent(){Text("首页内容")}.tabBar("首页")TabContent(){Text("推荐内容")}.tabBar("推荐")TabContent(){Text("发现内容")}.tabBar("发现")TabContent(){Text("我的内容")}.tabBar("我的")}.vertical(false).scrollable(true).animationDuration(0)}
}滚动导航栏
.barMode(BarMode.Scrollable) //BarMode.Fixed 默认值 固定
自定义TabBar(加图片等)
这样可以在自定义的函数中加入图片、结构(column)等。
可以传参数。

高亮切换
监听事件有两个:
点击和滑动都触发:onChange(event: (index: number) => void)
只有点击都触发:onTabBarClick(event: (index: number) => void)
1、通过Tabs(){}.onChange获取index,赋值给外部的selectIndex
2、给自定义TabBar增加参数:index,高亮的图片
3、在自定义TabBar中增加比较语句,与selectIndex相等的话就文字变色,切换高亮图片。
小米有品案例

对于这种中间有特殊结构的,再重新自动以一个TabBar放在中间即可。
自定义组件
1、基本使用
由框架直接提供的称为 系统组件,由开发者定义的称为 自定义组件。
和空项目给出的是一样的,空项目多一个@Entry,可以复制一下直接改名字即可。
使用自定义组件:HelloComponent()
// 定义
@Component
struct HelloComponent {// 状态变量@State message:string =''build(){// .... 描述 UI}
}2、自定义组件可以使用通用样式、通用事件
HelloComponent().width().onClick()
在单独的文件中写事件,添加export导出,export struct HelloComponent{}
如果想要单独预览组件,可以使用 @Preview 进行装饰
3、状态变量、成员变量(可赋值为函数),外部可传参覆盖
成员函数不可覆盖。
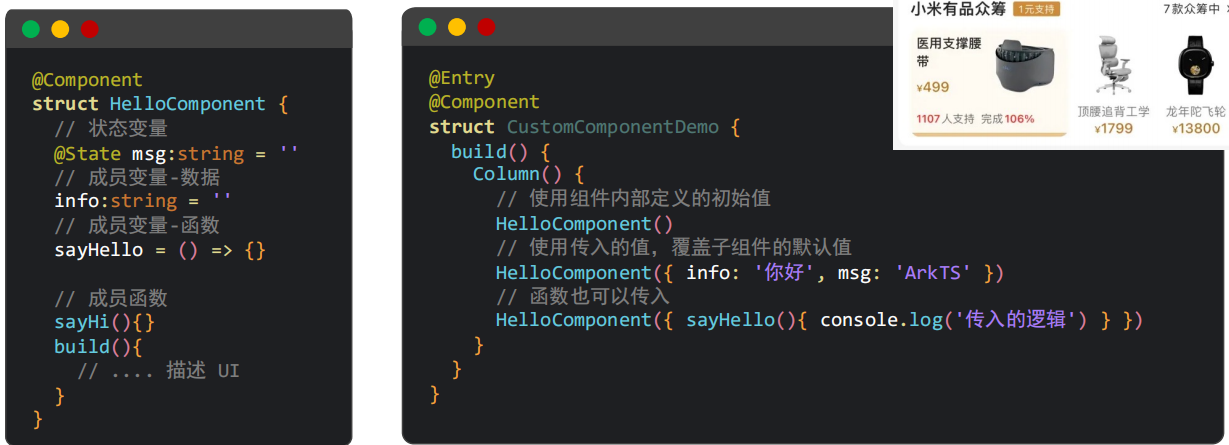
4、@BuilderParam传UI
3中,自定义组件传递文本参数;如果内部结构有所不同那么就不能直接复用,BuilderParam可以传递内部结构。
状态管理-@state
当运行时的 状态变量 变化,带来UI的重新渲染,在ArkUI中统称为 状态管理机制。
变量必须被 装饰器 装饰才可以成为状态变量。

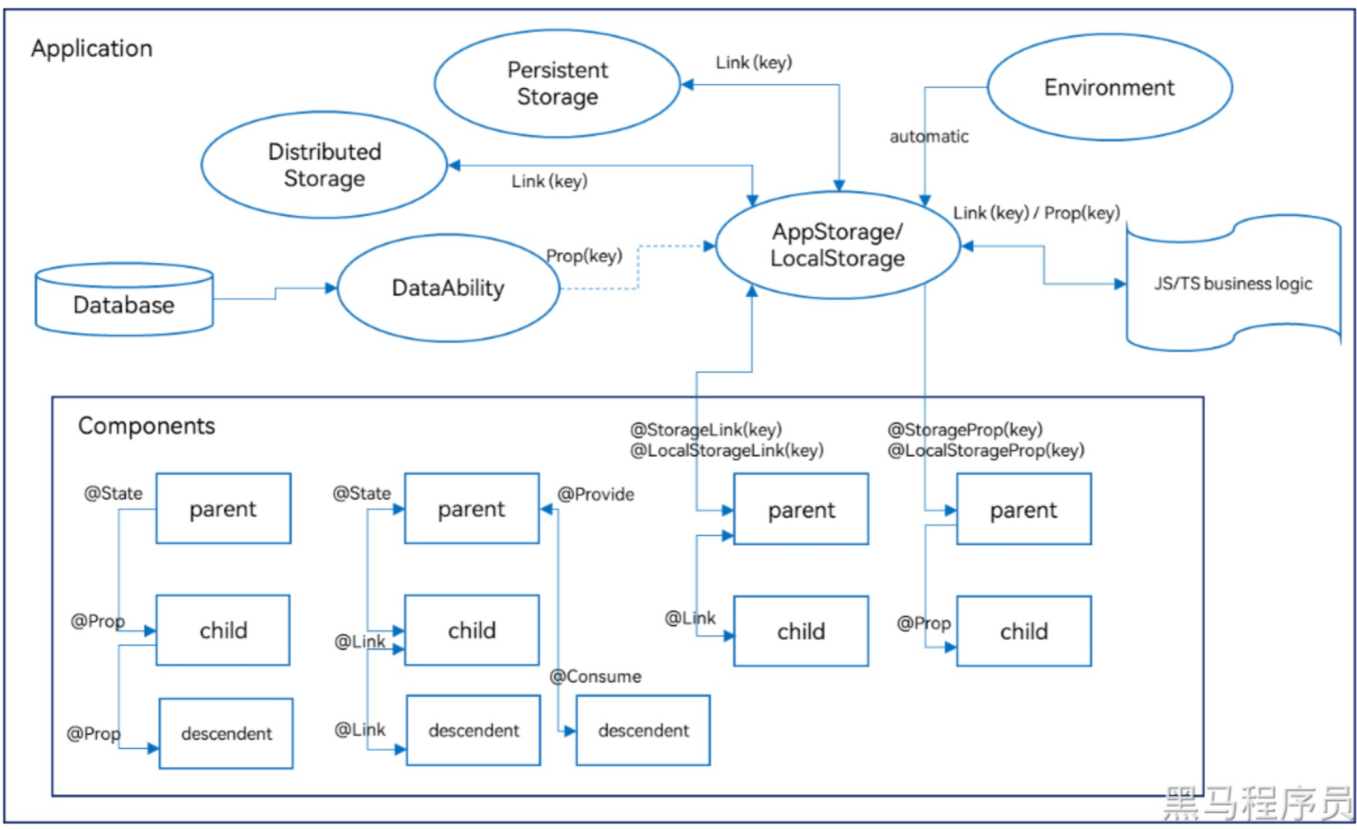
@State自己的状态
注意:不是所有的状态变量改变都会引起界面的刷新的,只有被框架观察到的修改才会引起UI刷新。
1. boolean、string、number类型时,可以观察到数值的变化
2. class或者Object时,可观察 自身的赋值 的变化, 第一层属性赋值的变化,即Object.keys(observedObject.toString()) 返回的属性。
class Car {name:string = ""
}
class Person{name:string = ""car:Car = {name:""}
}@Entry
@Component
struct Index {@State person : Person = {name:'jack',car:{name:'bigCar'}
}build() {Column(){Button("button").onClick(()=>{this.person.car.name = "smallCar"})Text(JSON.stringify(this.person)).fontSize(20)Text(Object.keys(this.person).toString())}}
}@Prop-父子单向
在使用自定义组件时,子组件想使用父组件的@state变量,只通过传值的方式,当父组件变量变化时,子组件变量值是无法改变的,也就无法重新渲染UI界面。
给子组件中的变量添加@Prop,这样在进行传值时(通过子组件参数),父组件值修改,子组件的值也会修改
如果想要在子组件中修改父组件的值,需要在子组件汇总添加一个函数并由父组件调用赋值,这样这个函数在子组件中调用时,就修改了父组件的@state,但是这样本质上还是在父组件中修改;可以选择在传值时添加一个参数,将这个参数赋值给父组件的@state变量,然后在子组件调用时传参,这样就实现了在子组件中改变父组件@state变量。
父组件中传递的函数要是用箭头函数,因为只有这样this才指向父组件,不然this就会指向子组件。
@Component
struct sonCom {@Prop info:stringchanInfo = (newInfo:string)=>{ //需要通过父组件的函数来修改}build() {Column(){Text(this.info)Button().onClick(()=>{this.chanInfo("son222")})}}
}@Entry
@Component
struct FatherCom {@State info:string = "111"build() {Column(){Text(this.info)Button().onClick(()=>{this.info = "father222"})sonCom({info:this.info,chanInfo:(newInfo:string)=>{ //这里需要的是一个箭头函数,不然this就是子组件的this了// 这里使用了一个小技巧,使得可以再子组件中赋值。this.info = newInfo //如果写成固定值,那么本质上还是在父组件中修改。}}).width('80%').height(200).backgroundColor(Color.Orange)}.width('100%').height(300).backgroundColor(Color.Pink)}
}@Link双向同步
适应@Link可以实现父组件和子组件的双向同步。
父组件@State变量修改,子组件对应的被@Link修饰的变量也修改;在子组件内修改,父组件变量也会改变。
@Provide 和 @Consume
同@Link一样,数据可以双向联动,而且可以跨层级双向联动。
比如父组件使用@Provide修饰,孙组件中使用@Consume修饰,任意处更改此变量,所有组件中有这个变量的,这个变量值都会改变。
被它们修饰的变量名必须一致。
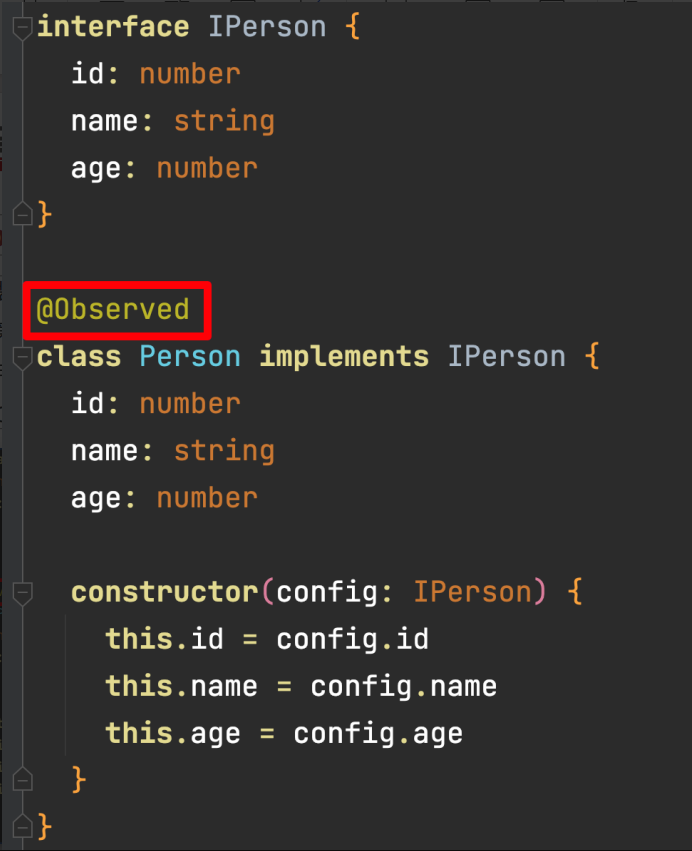
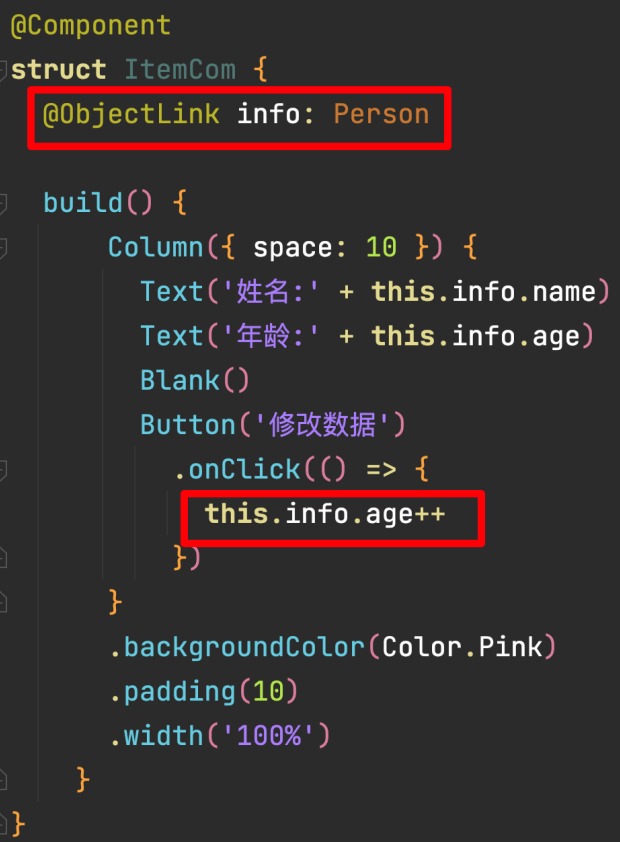
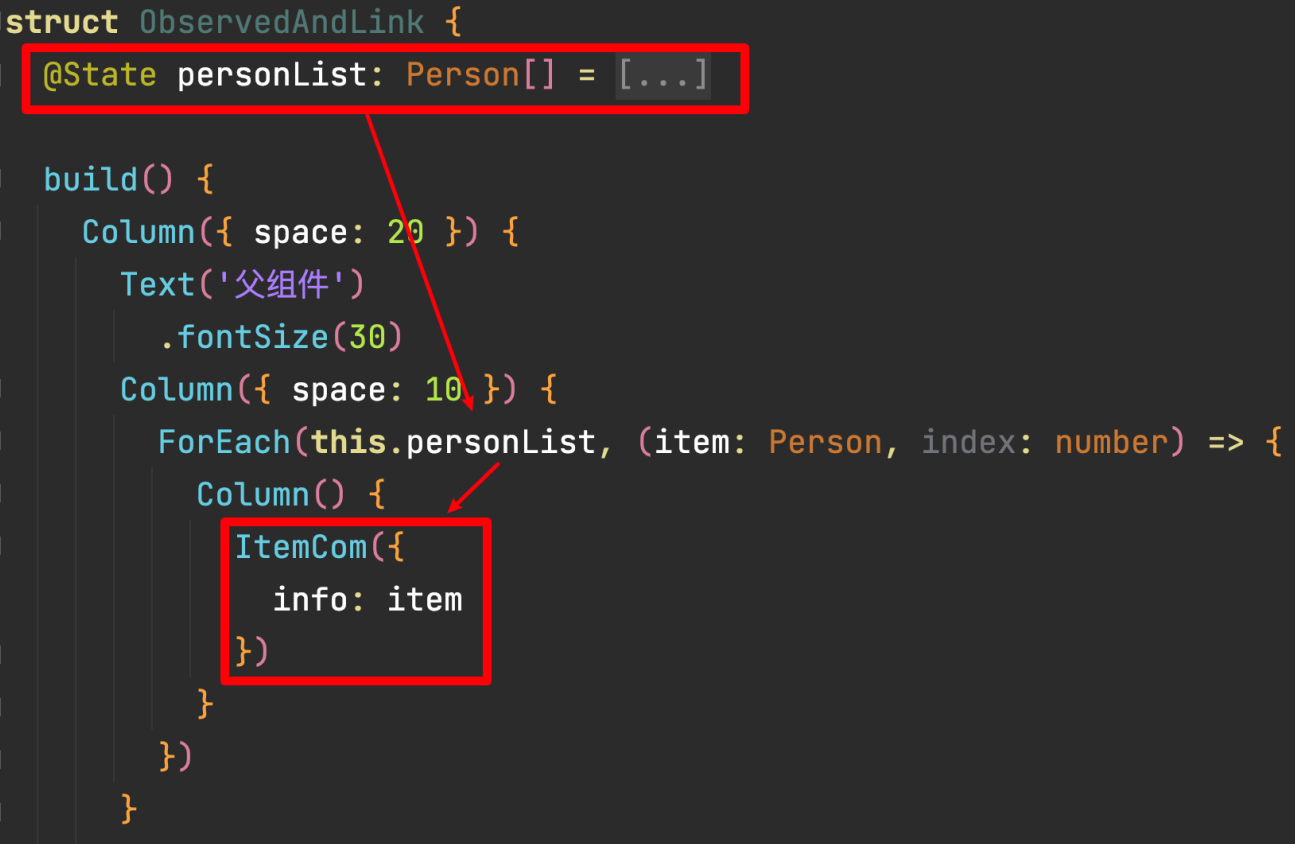
@Observed 和 @ObjectLink
装饰器仅能观察到第一层的变化。对于多层嵌套的情况,比如对象数组等。
他们的第二层的属性变化是无法观察到的。这就引出了@Observed/@ObjectLink装饰器。
作用:用于在涉及嵌套对象或数组的场景中进行双向数据同步
注意:@ObjectLink修饰符不能用在Entry修饰的组件中
@Observed只能对class进行装饰,在类定义的时候添加@Observed装饰器。此时这个类实例化出来的所有对象都会被自动添加setter和getter函数,来监视他的状态。
在非Enter修饰的组件中,使用@ObjectLink修饰的对象,可以自动更新。
属性更新的逻辑:当我们@Observed装饰过的数据,属性改变时,就会监听到;遍历依赖它的@ObjectLink包装类,通知数据更新。
如何证明能见听到呢?在带有Enter的父组件中调用函数打印没有带@ObjectLink包装类的变量,值也会改变,只是不更新UI界面。
当带有Enter的父组件中也有这个变量时,因为“@ObjectLink修饰符不能用在Entry修饰的组件中”,所以需要包一层。也就是再自定义一个组件,使用@ObjectLink修饰变量。
路由
页面路由指的是在应用程序中实现不同页面之间的跳转,以及数据传递。
1、创建页面
两种方式:
1、使用page创建页面,可以直接添加配置文件
2、使用ArkTs创建文件,需要在下方的resources文件夹profile文件中main_pages.json添加此文件,这样才能正常使用路由功能。
2、页面跳转和后退
两种方法,还有一个back手动返回。

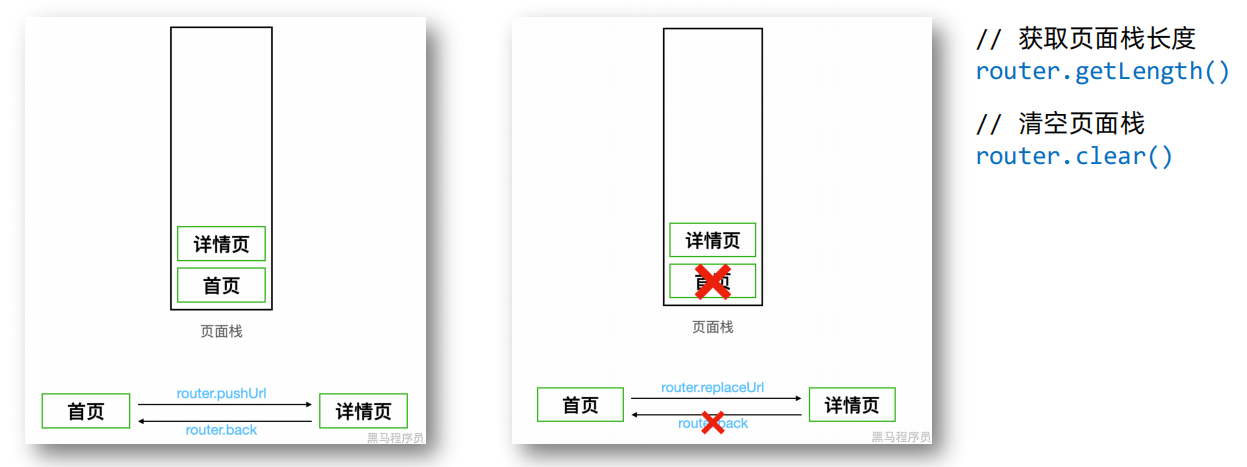
3、页面栈
页面栈是用来存储程序运行时页面的一种 数据结构,遵循 先进后出 的原则
页面栈的最大容量为 32 个页面
案例:都使用pushUrl,跳转几个页面再使用getLength就是1+n;
如果C和D之间反复跳转,也会计算数量;
使用replaceUrl在CD之间跳转,不会增加页面栈长度。点击返回按钮时,如果上一层是B,那么直接返回B。
4、路由模式
路由提供了两种不同的跳转模式
1. Standard:无论之前是否添加过,一直添加到页面栈【默认常用】
2. Single:如果目标页面已存在,会将已有的最近同url页面移到栈顶【看情况使用】
在第二个参数设置 【路由模式】
router.pushUrl(options, mode)
router.pushUrl({url:"pages/default",params:{username:this.username}
}, router.RouterMode.Single)5、跳转传参
index中的text : $$this.username,$$是双向绑定。在ArkUI框架中,$$this 是一种特殊的语法符号,主要用于按引用传递当前组件实例的上下文。在代码示例中,$$this.username 的作用是将当前组件(Index组件)的 @State 变量 username 以引用传递的方式绑定到 TextInput 组件上。
aboutToAppear已进入页面就会执行的函数——声明周期函数(钩子)
const params = router.getParams()获取数据,需要进行类型断言,自定义一个和index中相同的类型,然后就可以使用params.变量获取数据了。这是因为在default中不知道传递过来的数据是什么格式的。
钩子(Hook):在编程中,"钩子"(Hook)是一种通过拦截系统或应用程序的事件、函数调用或消息传递,从而修改或扩展其行为的技术。其核心价值在于允许开发者在不修改原有代码的情况下,插入自定义逻辑,实现对程序行为的监控、增强或重定向。
index页面
import { router } from '@kit.ArkUI'@Entry
@Component
struct Index {@State username : string = ""build() {Column(){Text("Index页面").width(300).height(100).fontSize(30)TextInput({text : $$this.username,placeholder : '请输入用户名'}).height(100).fontSize(30)Button("跳转到默认").width(300).height(100).fontSize(30).onClick(()=>{router.pushUrl({url:"pages/default",params:{username:this.username}}, router.RouterMode.Single)})}.width('100%')}
}default页面
import { router } from '@kit.ArkUI';
interface ParamsObj {username : string
}
@Entry
@Component
struct Default {@State message:string = '默认页面';@State username:string = "";aboutToAppear(): void {console.log(JSON.stringify(router.getParams()))const params = router.getParams() as ParamsObjthis.username = params.usernameconsole.log("this.username---", this.username)}build() {RelativeContainer() {Text(this.message + this.username).id('DefaultHelloWorld').fontSize($r('app.float.page_text_font_size')).fontWeight(FontWeight.Bold).alignRules({center: { anchor: '__container__', align: VerticalAlign.Center },middle: { anchor: '__container__', align: HorizontalAlign.Center }})Button("back").onClick(()=>{router.back()}).width(300).height(100).fontSize(30)}.height('100%').width('100%')}
}生命周期
组件 和 页面 在创建、显示、销毁的这一整个过程中,会自动执行 一系列的【生命周期钩子】
其实就是一系列的【函数】,让开发者有机会在特定的阶段运行自己的代码
区分 页面 和 组件:@Entry
aboutToAppear:创建组件实例后执行,可以修改状态变量
aboutToDisappear:组件实例销毁前执行,不允许修改状态变量
onPageShow:页面每次显示触发(路由过程、应用进入前后台)
onPageHide:页面每次隐藏触发(路由过程、应用进入前后台)
onBackPress:点击返回触发(return true 阻止返回键默认返回效果)
仅@Entry修饰的页面组件生效
下面的两个案例下载了一起,分别说明一下:
一、点击切换子组件显示控制子组件的显示。默认是显示的,所以输出顺序为:(只写了aboutToAppear和aboutToDisappear两个)
Index - aboutToAppear SonCom - aboutToAppear
再次点击输出:SonCom - aboutToDisappear
二、点击跳转页面跳转到登录页面,登录页面里有一个登录子组件。
初始化后显示:Index - aboutToAppear
点击“跳转页面”后显示:
Login - aboutToAppear
LoginSon - aboutToAppear
Login - onPageShow
点击返回按钮后:
Login - onPageHide
Login - aboutToDisappear
LoginSon - aboutToDisappear
这里需要注意的是,跳转到Login时先创建组件实例,再创建子组件实例,再显示页面。
back时Login页面先隐藏,组件实例销毁函数被调用,此时发现还有子组件,所以先销毁子组件,所有出现了点打印Login的aboutToDisappear后打印LoginSon的aboutToDisappear的情况。


Index页面
import { router } from '@kit.ArkUI'@Component
struct SonCom {aboutToAppear(): void {console.log("SonCom - aboutToAppear")}aboutToDisappear(): void {console.log("SonCom - aboutToDisappear")}build() {Column(){Text("我是子组件")}.width(200).height(200).border({width:3}).margin(20)}
}@Entry
@Component
struct Index {@State show:boolean = trueaboutToAppear(): void {console.log("Index - aboutToAppear")}aboutToDisappear(): void {console.log("Index - aboutToDisappear")}build() {Column(){Text("组件生命周期").fontSize(40)Button("切换子组件显示").onClick(()=>{this.show = !this.show})if (this.show){SonCom()}Button("跳转页面").onClick(()=>{router.pushUrl({url:"pages/Login"})})}}
}Login页面
import { router } from '@kit.ArkUI';
@Component
struct LoginSon {aboutToAppear(): void {console.log("LoginSon - aboutToAppear")}aboutToDisappear(): void {console.log("LoginSon - aboutToDisappear")}onPageShow(): void {console.log("LoginSon - onPageShow")}onPageHide(): void {console.log("LoginSon - onPageHide")}build() {}
}
@Entry
@Component
struct Login {aboutToAppear(): void {console.log("Login - aboutToAppear")}aboutToDisappear(): void {console.log("Login - aboutToDisappear")}onPageShow(): void {console.log("Login - onPageShow")}onPageHide(): void {console.log("Login - onPageHide")}onBackPress(): boolean | void {// 自己手写返回的代码,将来定制返回的逻辑router.back()}build() {Row(){Text("登录").fontSize(50)LoginSon()}}
}