【深度学习】张量计算:爱因斯坦求和约定|tensor系列03

- 博主简介:努力学习的22级计算机科学与技术本科生一枚🌸
- 博主主页: @Yaoyao2024
- 往期回顾:【深度学习】详解矩阵乘法、点积,内积,外积、哈达玛积极其应用|tensor系列02
- 每日一言🌼: “岱宗夫如何?齐鲁青未了。造化钟神秀,阴阳割昏晓。荡胸生曾云,决眦入归鸟。会当凌绝顶,一览众山小。”《望岳》—— 杜甫🌺
0、前言
爱因斯坦求和约定(Einstein Summation,简称 einsum)是一种简洁且功能强大的符号表示法,用于指定复杂的张量运算。在深度学习领域,特别是在 PyTorch 库中,torch.einsum 提供了一种灵活的方式来执行各种张量操作,例如矩阵乘法、点积、批量计算、外积、规约(reduction)、重塑(reshaping)或转置(transposing)等等。
在上篇文章中我们介绍了张量关于”积“的各种操作【深度学习】详解矩阵乘法、点积,内积,外积、哈达玛积极其应用|tensor系列02。也讲了在torch中这些操作的实现方式(各有不同)。
但是实际上,使用torch.einsum 这一个函数,就可以实现上述所有操作。它是对张量计算的一种规定,用简洁的符号来表示各种运算。
下面我们就对爱因斯坦求和约定进行学习吧。
1. 爱因斯坦求和的提出
在线性代数的各种矩阵计算,以及张量的计算中,往往会涉及到很多下标。每个元素的下标标定了一个元素的位置,像工牌号一样,可以唯一确定一个元素。
下面就是一个数学表达式的线性变换,也可以用矩阵来表示。
x 1 = a 11 y 1 + a 12 y 2 + a 13 y 3 x 2 = a 21 y 1 + a 22 y 2 + a 23 y 3 x 3 = a 31 y 1 + a 32 y 2 + a 33 y 3 \mathrm{x^1~=~a_{11}y^1+a_{12}y^2+a_{13}y^3}\\\mathrm{x^2~=~a_{21}y^1+a_{22}y^2+a_{23}y^3}\\\mathrm{x^3~=~a_{31}y^1+a_{32}y^2+a_{33}y^3} x1 = a11y1+a12y2+a13y3x2 = a21y1+a22y2+a23y3x3 = a31y1+a32y2+a33y3
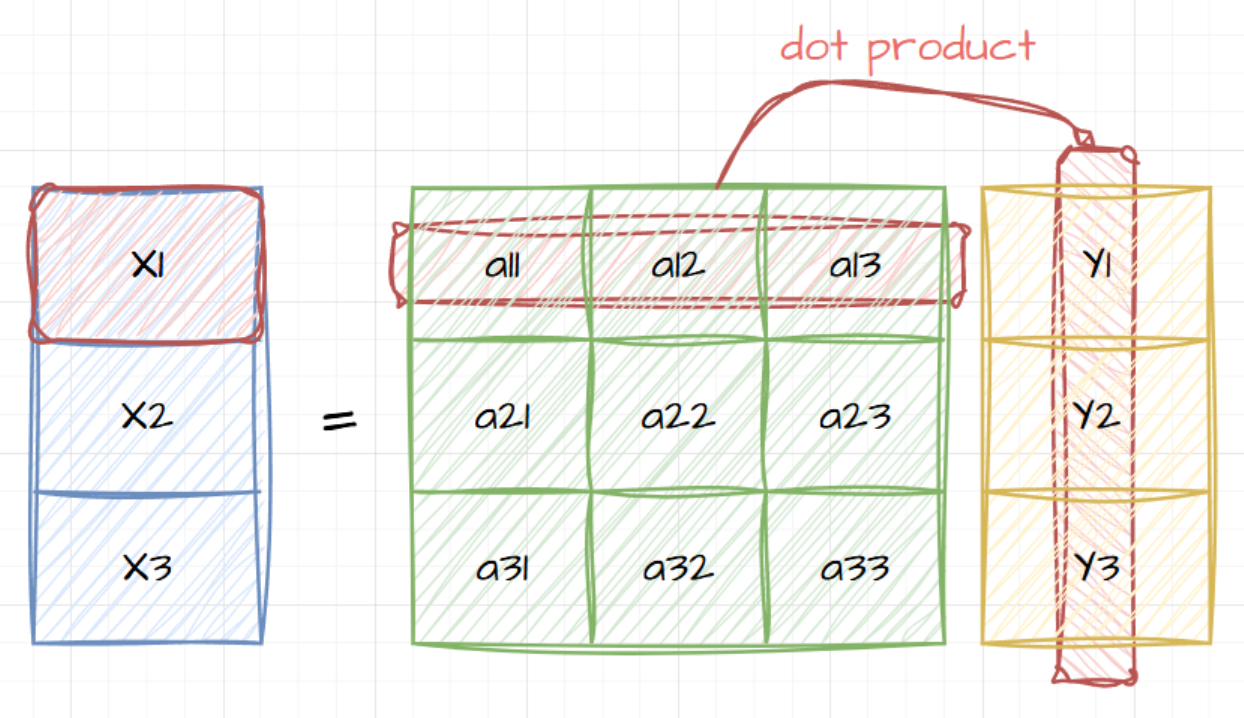
我我们可以看到,表示线性变换的数学表达式还是相当复杂的。也没有办法能够简化一下呢?
观察表达式的每一行,我们可以发现, x x x的上标核 a a a的下标,是一样的,我们把它记为 i i i,则可以写成:
x i = a i 1 y 1 + a i 2 y 2 + a i 3 y 3 ( i = 1 , 2 , 3 ) \mathrm{x^i~=~a_{i1}y^1+a_{i2}y^2+a_{i3}y^3}_{(i=1,2,3)} xi = ai1y1+ai2y2+ai3y3(i=1,2,3)
我们发现,确实简洁了不少,但是那么多的求和,随着矩阵形状的改变,元素增大,那么得写多少个求和。
可以观察到, a a a的第二个下标核 y y y的上标是一致的。根据这个规律,爱因斯坦就地立法,提出:以下化简方式:
可以看到,直接把求和项写成了一项。这个约定就是:
同一项里,如果有重复指标,则自动求和。

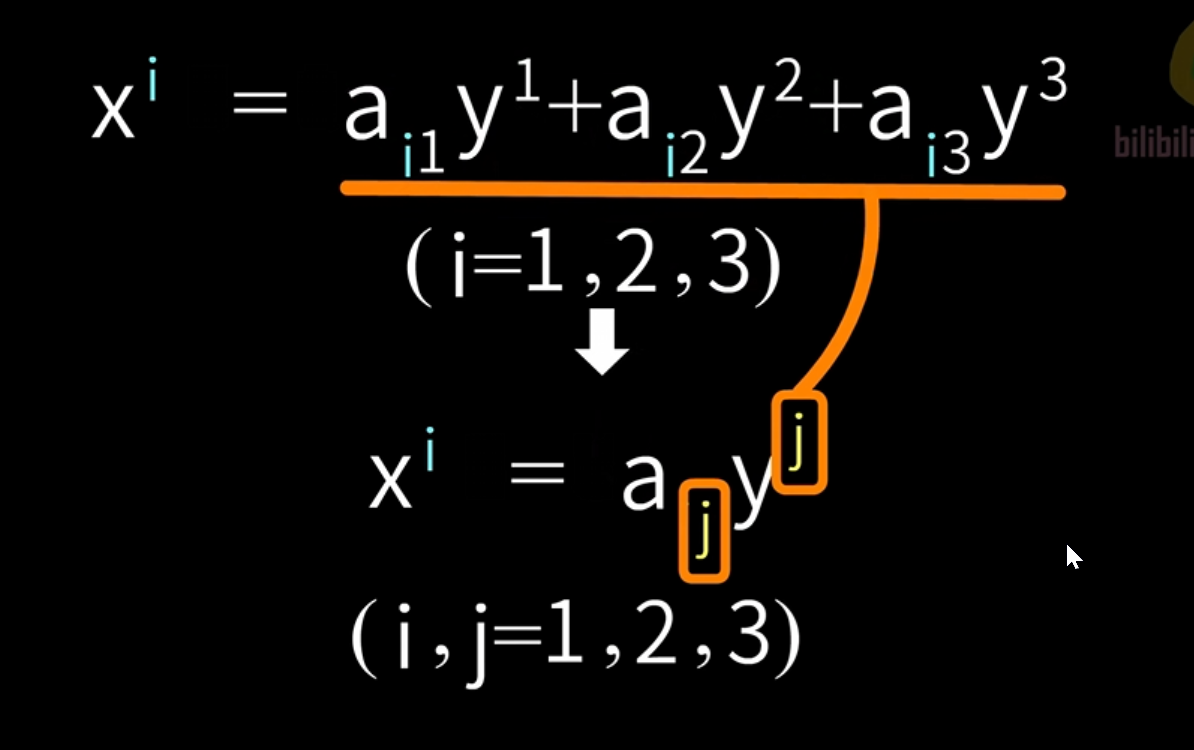

上面我们对爱因斯坦求和是什么,大概有了一个了解。它的提出是为了简化张量计算而做出的一个数学表达上的约定。
下面我们来详细讲解一下。
2. 爱因斯坦求和约定(Einstein Summation Convention)
爱因斯坦求和约定是阿尔伯特·爱因斯坦提出的一种简化张量运算的标记法,其核心思想是:
当表达式中出现重复的下标时,默认对这些下标进行求和。这种表示法可以省略显式的求和符号Σ,使表达式更加简洁。
基本规则:
-
重复下标表示求和:例如矩阵乘法 C i j = A i k B k j C_{ij}=A_{ik}B_{kj} Cij=AikBkj,k是重复下标,表示对k求和。
-
自由下标保留:不重复的下标会保留在结果中。决定新生成矩阵形状和元素位置
-
哑标:重复的求和下标也称为哑标(dummy index),因为它们不出现在最终结果中
判断是否求和的依据是:
- 同一项内重复的下标 → 求和(如
k在Aᵇᵢₖ Bᵇₖⱼ中)。 - 跨张量的相同下标 → 广播对齐(如
b在Aᵇᵢₖ和Bᵇₖⱼ中)。虽然
b也重复出现,但它出现在 不同张量的相同位置(Aᵇᵢₖ和Bᵇₖⱼ的第一个下标都是b),表示按批次独立计算,而非求和。
优势
-
简洁表达复杂的张量运算
-
直观展示张量运算的维度变化
-
统一表示多种线性代数运算
3. torch.einsum()函数
PyTorch中的torch.einsum()函数实现了爱因斯坦求和约定,可以高效地执行各种张量运算。
3.0 函数介绍
函数签名:
torch.einsum(equation, *operands)
equation: 描述运算的字符串,使用逗号分隔输入张量的下标,箭头后是输出下标operands: 输入张量序列
基本语法规则:
- 输入张量的下标用逗号分隔
- 箭头->后面是输出张量的下标
- 重复下标表示求和(收缩)
- 省略箭头和输出下标时,按输入下标顺序输出所有不重复的下标
...的作用:
| 场景 | 使用 ... | 显式写法 |
|---|---|---|
| 基本矩阵乘 | '...ij,...jk->...ik' | 'bij,bjk->bik' |
| 4D输入 | 同上,自动适配 | 'nbij,nbjk->nbik' |
| 向量点积 | '...i,...i->...' | 'bi,bi->b' |
下面我们将在具体的张量操作中,来认识爱因斯坦求和以及torch.einsum()的使用
3.1 矩阵转置
数学表达式:
B j i = A i j B_{ji}=A_{ij} Bji=Aij
没有重复的下标出现在同一项里面,所以这里的下标表示的就是本身的含义,也就是自由下标(无哑标)。
代码:
import torchA = torch.randn(3, 4)
B = torch.einsum('ij->ji', A) # 等同于A.T
3.2. 矩阵乘法
数学表达式:
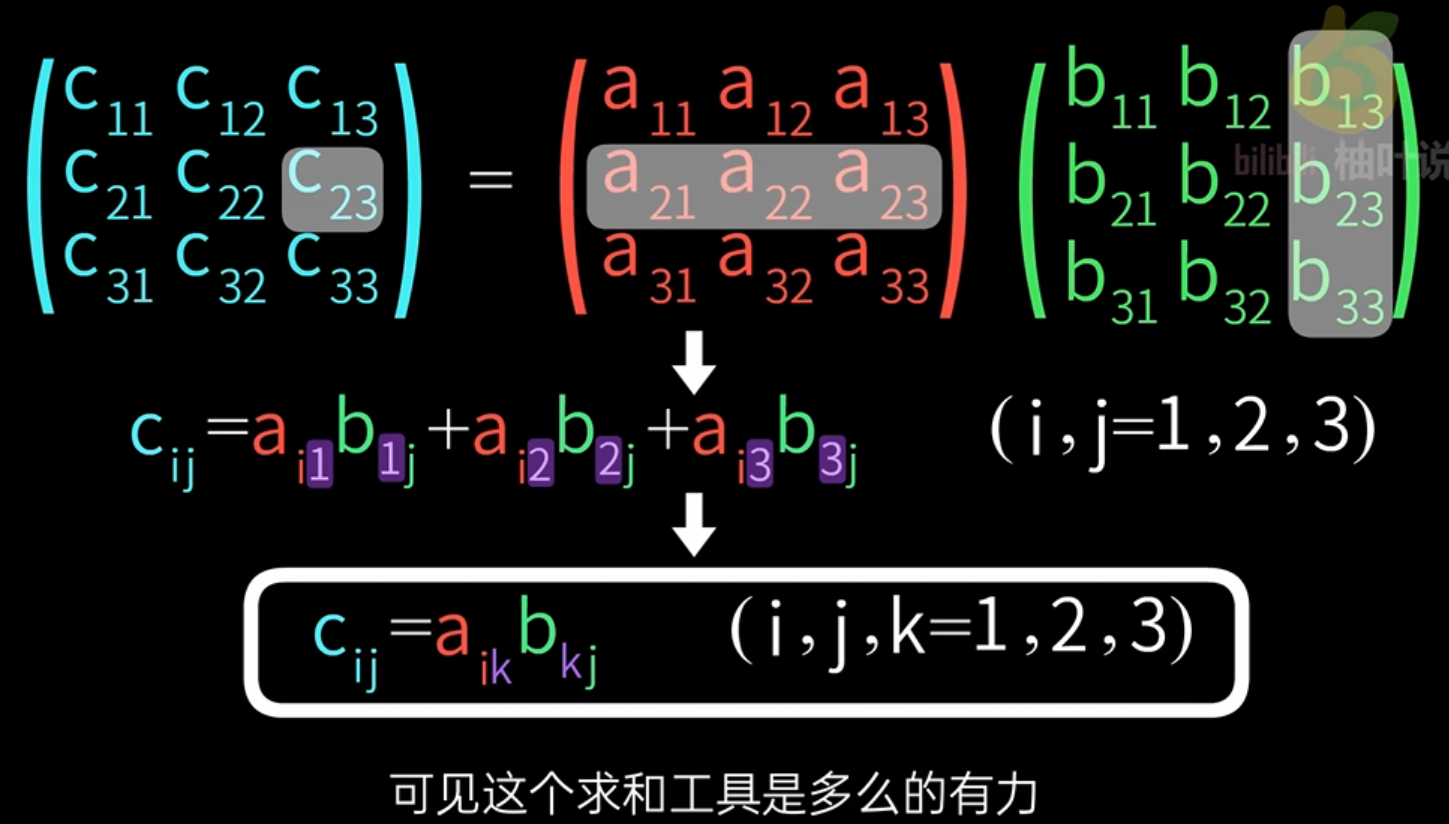
代码:
import torchA = torch.tensor([[a11, a12, a13],[a21, a22, a23],[a31, a32, a33]])B = torch.tensor([[b11, b12, b13],[b21, b22, b23],[b31, b32, b33]])# 使用einsum实现矩阵乘法
C = torch.einsum('ik,kj->ij', A, B)
3.3 向量内积(点积)
数学表达式:
给定两个向量:
a = [a₁, a₂, a₃]
b = [b₁, b₂, b₃]
内积计算:
c = a₁b₁ + a₂b₂ + a₃b₃
爱因斯坦约定
c = aᵢbᵢ (i=1,2,3)
- 重复下标i表示求和
- 无自由下标→输出为标量
代码:
torch.einsum实现
a = torch.tensor([a1, a2, a3])
b = torch.tensor([b1, b2, b3])
c = torch.einsum('i,i->', a, b) # 结果为标量
计算过程可视化(从爱因斯坦表达式推出它在干嘛):
展开求和:
torch.einsum('i,i->', a, b)= aᵢbᵢ (重复下标代表求和)= ∑aᵢbᵢ (i=1,2,3)= a₁b₁ + a₂b₂ + a₃b₃
3.4 向量外积
数学表达式:
给定两个向量:
a = [a₁, a₂]
b = [b₁, b₂, b₃]
外积结果矩阵:
C = [a₁b₁ a₁b₂ a₁b₃][a₂b₁ a₂b₂ a₂b₃]
爱因斯坦约定
Cᵢⱼ = aᵢbⱼ (i=1,2; j=1,2,3)
- 无重复下标→无求和
- 两个自由下标→输出矩阵
代码:
torch.einsum实现
a = torch.tensor([a1, a2])
b = torch.tensor([b1, b2, b3])
C = torch.einsum('i,j->ij', a, b) # 2x3矩阵
计算过程可视化
C₁₁ = a₁b₁ C₁₂ = a₁b₂ C₁₃ = a₁b₃
C₂₁ = a₂b₁ C₂₂ = a₂b₂ C₂₃ = a₂b₃
3.5 批量矩阵乘法
数学表达式:
给定两个批量矩阵:
A形状(batch,3,4) = [ [A⁰₁₁...A⁰₁₄], ..., [A⁰₃₁...A⁰₃₄] ][ [A¹₁₁...A¹₁₄], ..., [A¹₃₁...A¹₃₄] ]...
B形状(batch,4,5) = [ [B⁰₁₁...B⁰₁₅], ..., [B⁰₄₁...B⁰₄₅] ][ [B¹₁₁...B¹₁₅], ..., [B¹₄₁...B¹₄₅] ]...
批量矩阵乘法结果:
Cᵇᵢⱼ = Σₖ Aᵇᵢₖ Bᵇₖⱼ
爱因斯坦约定
Cᵇᵢⱼ = Aᵇᵢₖ Bᵇₖⱼ (b=1...batch; i=1,2,3; j=1...5; k=1...4)
-
重复下标k表示求和
-
自由下标b,i,j→输出形状(batch,3,5)
-
k是求和下标(哑标):
因为它出现在 同一个<张量乘法项>内 的重复维度(Aᵇᵢₖ和Bᵇₖⱼ中的k),表示需要沿该维度求和。 -
b是批处理下标:
虽然b也重复出现,但它出现在 不同张量的相同位置(Aᵇᵢₖ和Bᵇₖⱼ的第一个下标都是b),表示按批次独立计算,而非求和。
代码:
torch.einsum实现
A = torch.randn(10, 3, 4) # 10个3x4矩阵
B = torch.randn(10, 4, 5) # 10个4x5矩阵
C = torch.einsum('bik,bkj->bij', A, B) # 输出10个3x5矩阵#也可以用...进行维度自动匹配
C = torch.einsum('...ik,...kj->bij', A, B) 计算过程可视化:
对于每个批次b:
Cᵇ₁₁ = Aᵇ₁₁Bᵇ₁₁ + Aᵇ₁₂Bᵇ₂₁ + Aᵇ₁₃Bᵇ₃₁ + Aᵇ₁₄Bᵇ₄₁
Cᵇ₁₂ = Aᵇ₁₁Bᵇ₁₂ + Aᵇ₁₂Bᵇ₂₂ + Aᵇ₁₃Bᵇ₃₂ + Aᵇ₁₄Bᵇ₄₂
...
Cᵇ₃₅ = Aᵇ₃₁Bᵇ₁₅ + Aᵇ₃₂Bᵇ₂₅ + Aᵇ₃₃Bᵇ₃₅ + Aᵇ₃₄Bᵇ₄₅
3.6 张量缩并(Tensor Contraction)
数学表达式:
给定两个张量:
A形状(2,3,4): A₁₁₁ A₁₁₂ ... A₁₁₄A₁₂₁ ... A₁₃₄...A₂₃₁ ... A₂₃₄B形状(4,5,6):B₁₁₁ ... B₁₅₆...B₄₅₁ ... B₄₅₆
在第三个维度上缩并:
Cᵢⱼₖₗ = Σₘ Aᵢⱼₘ Bₘₖₗ
爱因斯坦约定
Cᵢⱼₖₗ = Aᵢⱼₘ Bₘₖₗ (i=1,2; j=1,2,3; k=1...5; l=1...6; m=1...4)
- 重复下标m表示求和
- 自由下标i,j,k,l→输出形状(2,3,5,6)
代码:
torch.einsum实现
A = torch.randn(2, 3, 4)
B = torch.randn(4, 5, 6)
C = torch.einsum('ijm,mkl->ijkl', A, B) # 输出2x3x5x6张量
计算过程可视化:
固定i,j,k,l(自由下标,决定新生成矩阵形状和元素的位置)时(也就是向量的点积了):
例如C₁₂₃₄ = A₁₂₁B₁₃₄ + A₁₂₂B₂₃₄ + A₁₂₃B₃₃₄ + A₁₂₄B₄₃₄
3.6 广播的元素级乘法运算
a = torch.arange(6).reshape(2, 3)
b = torch.arange(3)
result = torch.einsum('ij,j->ij', a, b) # Broadcast and multiply
print(result)
相当于是给a的第i行第j列,与b的j行做了点积,每一行都是这样。所以这个运算的效果相当于是给b做了个广播,广播成3×3然后和a作乘法了。
从这里来看,爱因斯坦求和也是可以实现广播操作的~
3.7 沿指定维度求和(Reduction)
数学表达式:
给定一个三维张量 T ∈ R 2 × 3 × 4 T\in\mathbb{R}^{2\times3\times4} T∈R2×3×4, 其元素表示为 T i j k T_{ijk} Tijk(其中 i = 1 , 2 , j = 1 , 2 , 3 , k = 1 , 2 , 3 , 4 i=1,2,j=1,2,3,k=1,2,3,4 i=1,2,j=1,2,3,k=1,2,3,4)。我们需要沿着第二个维度( j j j维度)进行求和,对矩阵进行压缩(Reduction),得到一个新的二维张量: S ∈ R 2 × 4 S\in\mathbb{R}^{2\times4} S∈R2×4,其:
S i k = ∑ j T i j k S_{ik}=\sum_jT_{ijk} Sik=j∑Tijk
根据爱因斯坦求和约定,上述求和操作可以表示为:
S i k = T i j k ( 对 j 求和 ) S_{ik}=T_{ijk}\quad(\text{对 }j\text{ 求和}) Sik=Tijk(对 j 求和)
- 输入张量: T i j k T_{ijk} Tijk(三维)
- 输出张量: S i k S_{ik} Sik(二维)
- 下标角色:
- i , k i, k i,k:自由下标(出现在输入和输出中)
- j j j:求和下标(哑标)(仅出现在输入中)
代码:
因此,einsum 表达式为:
result = torch.einsum('ijk->ik', tensor)
3.8 注意力机制
Transformer和AlphaFold等模型中注意力机制的核心计算步骤。流程分为三个阶段:
- 计算原始注意力分数(Query-Key点积 + 缩放)
- Softmax归一化(得到注意力权重)
- 加权求和Value向量(生成最终输出)
1. 阶段一:计算原始注意力分数
数学表达式:
raw_attn q k = Q q ⋅ K k c = ∑ c Q q c K k c c \text{raw\_attn}_{qk} = \frac{Q_q \cdot K_k}{\sqrt{c}} = \frac{\sum_{c} Q_{qc} K_{kc}}{\sqrt{c}} raw_attnqk=cQq⋅Kk=c∑cQqcKkc
其中:
- Q ∈ R q × c Q \in \mathbb{R}^{q \times c} Q∈Rq×c:查询矩阵(q个查询向量,每个维度c)
- K ∈ R k × c K \in \mathbb{R}^{k \times c} K∈Rk×c:键矩阵(k个键向量,每个维度c)
代码:
einsum实现
raw_attn = torch.einsum('qc,kc->qk', Q, K) / math.sqrt(Q.shape[-1])
- 下标解析:
qc:Q的维度(查询数×特征维度)kc:K的维度(键数×特征维度)->qk:输出形状(每个查询与每个键的点积)
- 缩放:除以 c \sqrt{c} c防止点积值过大(梯度稳定)
计算示例:
假设:
- Q = [ 1 2 3 4 ] , K = [ 0 1 1 0 ] , c = 2 Q=\begin{bmatrix}1&2\\3&4\end{bmatrix},K=\begin{bmatrix}0&1\\1&0\end{bmatrix},c=2 Q=[1324],K=[0110],c=2
- 计算:
raw_attn 00 = 1 × 0 + 2 × 1 2 = 2 2 = 2 raw_attn 01 = 1 × 1 + 2 × 0 2 = 1 2 raw_attn 10 = 3 × 0 + 4 × 1 2 = 4 2 = 2 2 raw_attn 11 = 3 × 1 + 4 × 0 2 = 3 2 \begin{aligned}&\text{raw\_attn}_{00}=\frac{1\times0+2\times1}{\sqrt{2}}=\frac2{\sqrt{2}}=\sqrt{2}\\&\text{raw\_attn}_{01}=\frac{1\times1+2\times0}{\sqrt{2}}=\frac1{\sqrt{2}}\\&\text{raw\_attn}_{10}=\frac{3\times0+4\times1}{\sqrt{2}}=\frac4{\sqrt{2}}=2\sqrt{2}\\&\text{raw\_attn}_{11}=\frac{3\times1+4\times0}{\sqrt{2}}=\frac3{\sqrt{2}}\end{aligned} raw_attn00=21×0+2×1=22=2raw_attn01=21×1+2×0=21raw_attn10=23×0+4×1=24=22raw_attn11=23×1+4×0=23
最终得到 r a w _ a t t n ∈ R 2 × 2 \mathrm{raw\_attn}\in\mathbb{R}^{2\times2} raw_attn∈R2×2
raw_attn = [ 2 1 2 2 2 3 2 ] \text{raw\_attn}=\begin{bmatrix}\sqrt2&\frac1{\sqrt2}\\2\sqrt2&\frac3{\sqrt2}\end{bmatrix} raw_attn=[2222123]
2. 阶段二:Softmax归一化
数学表达式:
attn q k = softmax ( raw_attn q ) k = exp ( raw_attn q k ) ∑ j = 1 k exp ( raw_attn q j ) \text{attn}_{qk} = \text{softmax}(\text{raw\_attn}_{q})_k = \frac{\exp(\text{raw\_attn}_{qk})}{\sum_{j=1}^k \exp(\text{raw\_attn}_{qj})} attnqk=softmax(raw_attnq)k=∑j=1kexp(raw_attnqj)exp(raw_attnqk)
给定一个查询 q q q对应的原始注意力分数向量 r a w _ a t t n q ∈ R k \mathrm{raw\_attn}_q\in\mathbb{R}^k raw_attnq∈Rk,Softmax计算步骤如下:
数学步骤:
-
指数化:对每个分数取指数
e x p _ a t t n q k = exp ( r a w _ a t t n q k ) exp\_attn_{qk} = \exp(\mathrm{raw\_attn}_{qk}) exp_attnqk=exp(raw_attnqk) -
求和:计算每一个查询
q对应的所有指数分数的和s u m q = ∑ j = 1 k exp ( raw_attn q j ) sum_q = \sum_{j=1}^k \exp(\text{raw\_attn}_{qj}) sumq=j=1∑kexp(raw_attnqj)
-
归一化:每个指数值除以总和
a t t n q k = exp ( r a w _ a t t n q k ) s u m \mathrm{attn}_{qk}=\frac{\exp(\mathrm{raw}\_\mathrm{attn}_{qk})}{\mathrm{sum}} attnqk=sumexp(raw_attnqk)
代码:
沿键维度(dim=1)归一化:每个查询对应的所有键的分数转换为概率分布
attn = torch.softmax(raw_attn, dim=1)
- 输出性质:
- 每行和为1(概率分布)
- 突出最大值(如输入
[3,1]→ 输出[0.88, 0.12])
3. 阶段三:加权求和Value向量
数学表达式:
r e s u l t q d = ∑ k = 1 K a t t n q k V k d \mathrm{result}_{qd}=\sum_{k=1}^K\mathrm{attn}_{qk}V_{kd} resultqd=k=1∑KattnqkVkd
- V ∈ R k × d V\in\mathbb{R}^{k\times d} V∈Rk×d:值矩阵(k个值向量,每个维度d)
- 物理意义:用注意力权重对值向量加权平均
代码:
result = torch.einsum('qk,kd->qd', attn, V)
- 下标解析:
qk:注意力权重矩阵(查询数×键数)kd:值矩阵(键数×值维度)->qd:输出形状(查询数×值维度)
计算示例:
假设:
- a t t n = [ 0.8 0.2 0.5 0.5 ] , V = [ 1 3 2 4 ] \mathrm{attn}=\begin{bmatrix}0.8&0.2\\0.5&0.5\end{bmatrix},V=\begin{bmatrix}1&3\\2&4\end{bmatrix} attn=[0.80.50.20.5],V=[1234]
- 计算: r e s u l t 00 = 0.8 × 1 + 0.2 × 2 = 1.2 r e s u l t 01 = 0.8 × 3 + 0.2 × 4 = 3.2 \mathrm{result}_{00}=0.8\times1+0.2\times2=1.2\\\mathrm{result}_{01}=0.8\times3+0.2\times4=3.2 result00=0.8×1+0.2×2=1.2result01=0.8×3+0.2×4=3.2
最终得到 r e s u l t ∈ R 2 × 2 \mathrm{result}\in\mathbb{R}^{2\times2} result∈R2×2
4. 易错点:重复下标一定求和?
终极答案:位置决定命运(下标角色的黄金法则)
在表达式 Cᵇᵢⱼ = Aᵇᵢₖ Bᵇₖⱼ 中,下标的命运由它的出现位置决定:
1. 求和下标(哑标)的特征⭐
- 必须同时出现在两个相乘的张量中
- 必须出现在每个张量的不同维度位置
- 不会出现在输出下标中
如何判断爱因斯坦表达式中的下标是否是哑标?
对于任意爱因斯坦求和表达式(单张量或多张量),求和下标必须满足:
- 必要条件:输入中出现但输出中不出现(否则是自由下标)
- 充分条件(多张量时追加):
- 在所有输入张量中都出现
- 在不同张量的不同维度位置
具体来说:
-
单张量操作(如矩阵求和、迹运算):
- 唯一判定标准:输入有但输出无的下标即为哑标(必须求和)。
- 其他两个特征不适用。
-
多张量操作(如矩阵乘法 A i k B k j A_{ik}B_{kj} AikBkj):
- 需同时满足:
- 出现在所有输入张量中(特征1)
- 在不同张量的不同维度位置(特征2)
- 不在输出中(特征3)
- 需同时满足:
以 k 为例:
Aᵇᵢₖ Bᵇₖⱼ↑ ↑不同位置(A的第3维,B的第2维)
k 在A中是第3个下标,在B中是第2个下标 → 满足"不同位置"条件 → 需要求和
总结表格:🌟
| 场景 | 求和下标判定依据 |
|---|---|
| 单张量操作 | 输入有、输出无的下标(必须求和) |
| 多张量操作 | 输入有(所有张量)、输出无 + 在不同张量的不同维度位置 |
| 非法情况 | 下标在输入张量的相同位置出现,或出现在输出中却试图求和 |
2. 批处理下标(非求和)的特征
- 出现在两个张量的相同维度位置
- 必须出现在输出下标中
以 b 为例:
Aᵇᵢₖ Bᵇₖⱼ↑ ↑相同位置(都是第1维)
b 在A和B中都是第1个下标 → 满足"相同位置"条件 → 保持独立不求和
三维动画演示(想象这个场景)
假设我们有两个立方体:
- 立方体A:轴为 b(批次)× i(行)× k(列)
- 立方体B:轴为 b(批次)× k(行)× j(列)
计算时:
- 沿着
k方向(两个立方体的不同轴)进行纤维(fiber)的点积 → 需要求和 - 沿着
b方向保持各层独立 → 不求和
数学证明(为什么这样设计?)
爱因斯坦约定本质上是以下运算的简写:
for b in range(batch):for i in range(3):for j in range(5):C[b,i,j] = sum(A[b,i,k] * B[b,k,j] for k in range(4))
k对应最内层的sum()→ 必须求和b对应最外层的循环 → 保持独立
常见误区纠正
❌ 误区:“重复出现就要求和”
✅ 正解:“跨张量且不同位置的重复才求和”
实战测试
判断下面哪些下标会被求和:
-
einsum('abc,cde->abe', X, Y)- 求和下标:
c(X的第3维,Y的第1维) - 批处理下标:无(因为没有跨张量重复的其他下标)
- 求和下标:
-
einsum('bik,bkj->bikj', A, B)- 求和下标:无(虽然
k重复,但出现在输出中) - 批处理下标:
b(相同位置)
- 求和下标:无(虽然
为什么这样设计?(设计哲学)
-
位置差异暗示运算意图:
- 不同位置:暗示矩阵乘法类的收缩操作
- 相同位置:暗示并行/广播操作
-
与张量积的自然对应:
A ⊗ B 的下标排列总是保持输入张量的原始顺序
如果您还是觉得反直觉…
可以记住这个万能判断法则:
- 写下所有输入张量的维度标记
- 用箭头连接相同的字母
- 横向连接(跨张量):求和
- 纵向连接(同张量):保留
示例:
A: b--i--k\ \
B: b--k--j
横向的 k 需要求和,纵向的 b 保持独立。
5. 总结理解模式
对于任何张量运算,都可以按照以下模式理解:
- 写出完整数学表达式:明确每个元素的求和关系
- 识别下标类型:
- 重复下标(哑标):将被求和的维度
- 自由下标:决定输出形状的维度
- 转换为einsum表示法:
- 输入张量的下标用逗号分隔
- 箭头后是输出下标
- 实现计算可视化:固定自由下标,展开哑标的求和过程
这种思维方法可以推广到任何维度的张量运算,是理解和实现复杂神经网络操作的有力工具。
参考
- 【【从0开始学广义相对论02】嫌矩阵运算难写?看看爱因斯坦怎么做的:Einstein求和约定】 (这篇文章中的黑底图片和部分内容参考与本视频,感谢博主
- 感谢DeepSeek,豆包