英伟达:让我们遇见越来越“大”的GPU
在2024年台北ComputeX大会上,英伟达CEO黄仁勋发表了题为《揭开新工业革命序幕》的演讲。他手持一款游戏显卡(很有可能是4090),自豪地宣称:“这是目前最先进的游戏GPU。”紧接着,他走到一台DGX Blackwell NV72前,再次强调:“这也是一个GPU。”

确实,老黄背后的一整套机柜就像一个强大的"GPU"。与手中的4090相比,DGX Blackwell NV72显得非常庞大。英伟达正通过NVlink、IB和以太网等技术,构建更大规模的"GPU"集群。
英伟达GPU的崛起之路,独步天下的是“规模换性能”的并行计算之道。历经图形渲染、游戏加速与AI领域的广泛运用,其核心理念始终如一:将复杂任务分解为基本算术操作,如加法与乘法,再由高度优化的计算单元进行并行处理,从而挖掘出前所未有的计算潜力。
在CPU领域,英特尔与AMD依然致力于提升单核性能,如架构优化、指令集丰富和频率提升。然而,英伟达却独树一帜,将目光投向并行计算。英伟达GPU的核心竞争力在于其微小核心的协同作业,完美适应深度学习、科学仿真、图像渲染和高性能计算(HPC)等数据密集型任务,展现出卓越的计算效率和灵活性。
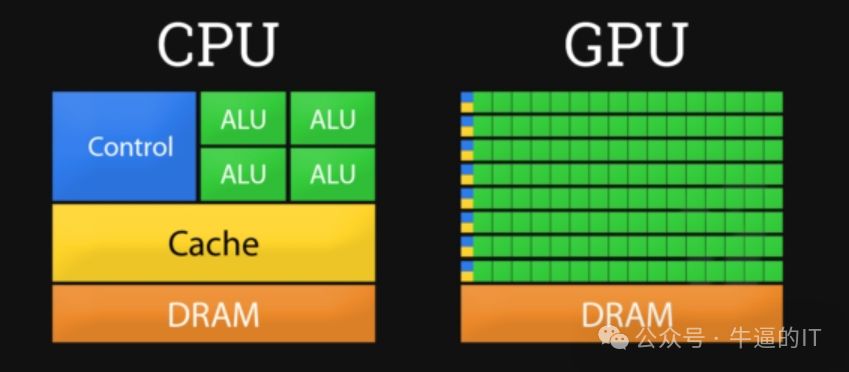
随着摩尔定律逐渐放缓,芯片制程的效益递减,单一GPU的并行计算能力达到极限。然而,英伟达凭借前瞻性视野和创新精神,通过融合高速互联技术,成功构建了多GPU协同计算的桥梁。这不仅突破了单芯片性能的限制,还推动了GPU规模的持续扩张,让我们见证了越来越强大的GPU,预示着超大规模并行计算新时代的到来。
Transformer模型是一种基于自注意力机制的神经网络,它可以处理序列数据,如文本、语音和图像等。在AIGC时代,Transformer模型使得无监督学习成为可能,所需算力不断增长,需要更大的GPU。英伟达并非简单的芯片厂商,持续致力于为客户提供一整套AI解决方案,如Blackwell系列产品。
英伟达的Blackwell B200是一款新型GPU,它由两颗TSMC制造的最大的芯片组成,单个Die晶粒的最大光照面积为10TB。这款芯片拥有前所未有的性能表现和革命性的技术创新,再次证明了英伟达在人工智能领域的领先地位 。
Blackwell B200芯片是英伟达首款采用MCM(Multi-Chip Module,多芯片模块)封装的GPU,集成了惊人的2080亿个晶体管,堪称英伟达迄今为止最为庞大的单一计算单元。
Blackwell架构的GPU采用了四个HBM接口,相比于H100架构采用的六个HBM接口,巧妙地节省了宝贵的芯片空间,而不牺牲存储带宽。自2016年Pascal架构首度亮相以来,GPU算力已从19TFLOPS(FP16)跃升至Blackwell架构的20PFLOPS(FP4),实现了千倍的性能跨越 。
Blackwell架构以六大创新技术,将Hopper平台性能提升至FP8精度的2.5倍。不仅如此,它还支持FP4和FP6精度,使计算效率提升至Hopper平台的5倍。这一突破性进展使Blackwell能够轻松驾驭拥有高达10万亿参数的巨型模型,为人工智能领域带来革命性的进步。

GB200:
由两个B200和一个Grace CPU结合形成,通过900GB/s的超低功耗NVLink芯片间互连技术连接在一起,提供40PFLOPS(FP4)的算力,384GB内存,1.6TB/s带宽。搭载两个GB200的元件作为Blackwell计算节点,18个计算节点在NVLink Switch的支持下构成GB200 NVL72,最终用Quantum InfiniBand交换机连接,配合散热系统组成新一代DGX SuperPod集群。
GB200 NVL72全部采用铜链接用以密集封装、互联GPU,无需采用光学收发器,可以简化操作,同时节省20kw用于计算,大幅提升其AI效能。

NVLink是一种高速互连技术,用于连接GPU和其他设备。第五代NVLink为每个GPU提供了1.8TB/s双向吞吐量,确保最多576个GPU之间的无缝高速通信,适用于最复杂的LLM 。

英伟达针对大型人工智能工厂的数据高效交换需求,巧妙地将InfiniBand的卓越性能融入以太网架构中。在数据中心环境中,特别是面对人工智能工厂场景,GPU间数据交互频繁且密集,远超与外部互联网用户通信需求。
在AI训练过程中,GPU不仅要收集部分结果,还需进行规约和重新分配,这种工作模式催生了高度突发性的网络流量。因此,确保网络中最后一个数据包的准时到达变得至关重要。然而,传统的以太网架构并未针对这种低延迟需求进行专项优化。
GPU(图形处理单元)是AI计算的关键技术之一。在AI大模型算力的概念中,GPU在其中的核心作用和工作原理被深入探讨。
为了解决这一难题,英伟达巧妙地运用了四种关键技术:RDMA(远程直接内存访问)、先进的拥塞控制机制、自适应路由技术和噪声隔离技术。这些技术的综合应用,不仅显著提升了网络的整体性能,还大幅降低了延迟,使得网络成本在数据中心整体运营成本中几乎可以忽略不计。
英伟达(NVIDIA)的Spectrum-X以太网技术,如同AI领域的"黑科技",为人工智能工厂注入了强大的生命力。作为全球首个专为AI设计的以太网网络平台,其卓越性能较传统网络平台提升高达1.6倍,令人叹为观止。Spectrum-X能显著加速AI工作负载的处理、分析与执行效率,从而极大地推动了AI解决方案的开发和部署速度,让我们在AI领域中迈出了关键一步。
目前,英伟达的Spectrum-X平台已经推出了速度惊人的Spectrum-X800版本,其传输速率高达每秒51.2Tbps,并配备了256个端口。展望未来,英伟达计划在未来几年内推出更多强大的产品。首先是预计将拥有512个端口的Spectrum-X800 Ultra,然后是性能更为卓越的X1600版本。
这些新产品针对不同的应用场景进行了优化。X800和X800 Ultra主要服务于大规模GPU集群的需求,而X1600则是为处理数百万级GPU的超级计算环境而设计。这些产品的性能之强大,确实让人印象深刻。
Blackwell是英伟达的一款AI产品,标志着生成式AI时代的到来和新工业革命的开始。Blackwell平台通过GPU、CPU、NV Link、网卡以及连接所有GPU的大型高速交换机,可以组成超大型GPU集群。
Blackwell GPU的核心是B200芯片,这款芯片拥有2080亿个晶体管,采用台积电定制的4NP工艺制造。B200芯片将两个die连接成一个统一的GPU,通信速度可达10TB/秒。 它使用192GB的HBM3E内存,具有极高的内存带宽和数据处理能力。
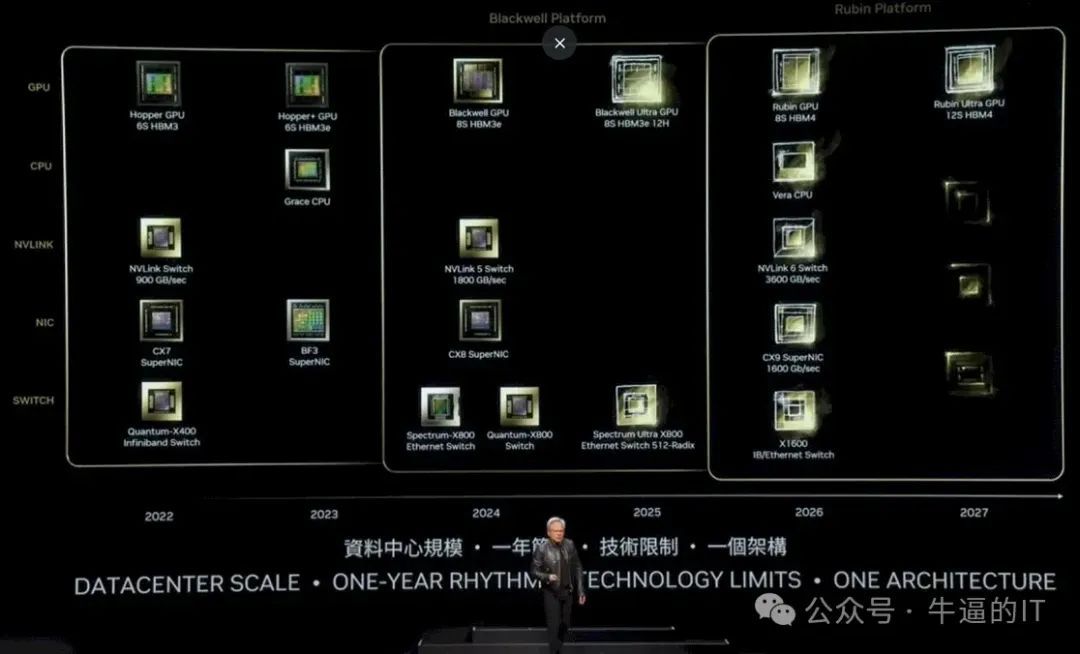
英伟达GPU的演进之路:遵循年年升级节奏,融合台积电先进工艺、封装、存储和光学技术,追求极致性能。软件生态持续壮大,支持向后兼容,与现有软件架构相融。让我们共同期待GPU从“大”到“更大”的华丽蜕变。
- 2024年Blackwell芯片现已开始投产;
- 2025年,Blackwell将推出8S HBM3e 12H Ultra GPU,引领高性能计算新时代。
- 2026年,推出Rubin GPU(8S HBM4);
- 在2027年,我们将推出革命性的Rubin Ultra GPU(12S HBM4),这款强大的处理器基于先进的Arm Vera CPU,并配备了高速的NVLink 6 Switch(3600GB/s),为用户带来前所未有的计算性能和流畅体验。
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-