浅谈 MySQL 日志的原理
前言
在 MySQL 的内部机制中,日志系统扮演着至关重要的角色。它不仅是数据库可靠性和一致性的基石,也是许多高级特性(如事务、崩溃恢复和主从复制)的核心支撑。
本文将深入剖析 MySQL 的日志系统,帮助读者理解其设计原理和实际价值。
MySQL 的日志类型
MySQL 的日志系统由多种日志组成,每种日志都有其特定的职责:
-
重做日志(Redo Log):InnoDB 存储引擎层生成的物理日志,记录对页的修改,保证了事务的持久性,主要用于崩溃恢复。
-
回滚日志(Undo Log):InnoDB 存储引擎层生成的逻辑日志,记录修改前的数据状态,实现了事务的原子性,用于事务回滚和 MVCC 实现。
-
二进制日志(Binary Log):Server 层生成的逻辑日志,记录对数据库内容的修改,用于数据备份和主从复制。
-
中继日志(Relay Log):用于主从复制场景,从库通过 I/O 线程复制主库的 binlog 后在本地生成的日志。
-
慢查询日志(Slow Query Log):记录执行时间超过阈值的 SQL 语句,用于性能分析和优化。
这些日志协同工作,共同保障了 MySQL 的数据安全和功能实现。
Redo Log:持久性
Redo Log 的本质
Redo Log 是物理日志,记录了对数据页的实际修改,例如"在 X 页面的 Y 偏移量处写入了值 Z"。这种物理记录使得崩溃恢复变得高效和可靠。
为什么需要 Redo Log?
当我们理解了 InnoDB 的缓冲池(Buffer Pool)设计,就能更好地理解 Redo Log 的价值:
-
解决持久性问题:Buffer Pool 提高了读写效率,但基于内存,如果断电,内存中还未刷盘的数据就会丢失。Redo Log 通过先记录修改,再在合适时机刷新数据页到磁盘,解决了这个问题。
-
提升写入性能:通过 WAL(Write-Ahead Logging)技术,将随机写转变为顺序写,显著提高了写入性能。
Redo Log 的工作流程
- 事务执行时,对数据的修改首先更新在 Buffer Pool 中(同时标记为脏页)。
- 同时,生成对应的 Redo Log 记录,写入 Redo Log Buffer。
- 根据参数设置,在合适的时机将 Redo Log 持久化到磁盘。
- 后台线程定期将 Buffer Pool 中的脏页刷新到数据文件。
这种"先写日志,再写数据"的模式,就是 WAL 技术的核心思想。
Redo Log 的持久化策略
通过 innodb_flush_log_at_trx_commit 参数控制 Redo Log 的持久化策略:
- 值为 1:每次事务提交时立即刷盘(fsync),最安全但性能开销最大。(默认值)
- 值为 2:每次提交写入操作系统缓存,后台线程每秒将日志刷盘,性能与安全性折中。
- 值为 0:仅写入 redo log buffer,由后台线程每秒刷盘一次,性能最好但可能丢失事务。
Redo Log 的物理结构
Redo Log 采用环形结构,由一组固定大小的文件组成。当写到文件末尾时,会循环回到开头,覆盖旧的日志。这要求在覆盖前,对应的脏页必须已经刷新到磁盘。
Undo Log:原子性与隔离性
Undo Log 的本质
Undo Log 是逻辑日志,记录了事务执行前的数据状态,使得事务能够回滚到执行前的状态。
Undo Log 的双重角色
-
实现事务回滚:当事务需要回滚时,通过 Undo Log 恢复数据到事务开始前的状态。
-
支持 MVCC:多版本并发控制机制依赖 Undo Log 构建数据的历史版本,实现非锁定读,从而支持不同的事务隔离级别。
Undo Log 的工作流程
- 事务开始前,记录要修改的数据的原始值到 Undo Log。
- 执行修改操作,更新数据。
- 如果事务需要回滚,则使用 Undo Log 中的数据恢复原始值。
- 如果事务提交,Undo Log 不会立即删除,而是在不再被任何事务使用后由后台线程清理。
MVCC 与 Undo Log
在 MVCC 机制中,每个事务开始时会被分配一个 ID。当事务需要读取数据时:
- 在可重复读隔离级别下,事务只能看到它开始前已提交的事务所做的修改。
- 如果一行数据被其他事务修改但未提交,或者是在该事务开始后被修改并提交的,则通过 Undo Log 找到该行数据在事务开始时的版本。
这种基于 Undo Log 的快照读取机制,使得多个事务能够并发执行而不会相互阻塞。
Binary Log:逻辑变更
BinLog 的本质
Binlog 是 Server 层生成的逻辑日志,记录了数据库执行的所有变更操作,是主从复制和数据恢复的核心。
BinLog 的三种格式
-
STATEMENT 格式:记录的是 SQL 语句本身。优点是日志量小,缺点是可能导致主从不一致(如使用 UUID()、NOW() 等函数时)。
-
ROW 格式:记录的是数据行的变化。优点是保证主从一致性,缺点是日志量大。
-
MIXED 格式:默认使用 STATEMENT 格式,在某些情况下自动切换到 ROW 格式。
BinLog 的写入流程
- 事务执行过程中,生成的 Binlog 先存放在 Binlog Cache 中。
- 事务提交时,将 Binlog Cache 中的内容写入 Binlog 文件。
- 根据
sync_binlog参数决定是否立即刷新到磁盘:- 值为 1:每次事务提交都刷新,最安全但性能最低。
- 值为 0:由文件系统决定何时刷新,性能最高但最不安全。
- 值为 N:每 N 个事务刷新一次,平衡了性能和安全性。
Binlog 与主从复制
在主从复制架构中,Binlog 承担着传递变更的角色:
- 主库执行事务并记录 Binlog。
- 从库的 I/O 线程读取主库的 Binlog,并写入本地的 Relay Log。
- 从库的 SQL 线程读取 Relay Log,并在从库上执行。
两阶段提交:确保数据一致性
为什么需要两阶段提交?
在 MySQL 开启 Binlog 的情况下,既有 Redo Log 又有 Binlog,这两者必须保持一致。如果在提交过程中发生崩溃,可能导致 Redo Log 和 Binlog 状态不一致。
两阶段提交的流程
-
Prepare 阶段:
- 将事务的 XID(内部事务标识)写入 Redo Log。
- 将 Redo Log 状态设置为 prepare。
- 将 Redo Log 持久化到磁盘。
-
Commit 阶段:
- 将事务的 XID 和数据变更写入 Binlog。
- 将 Binlog 持久化到磁盘。
- 将 Redo Log 状态设置为 commit。
崩溃恢复的逻辑
如果在两阶段提交过程中发生崩溃,MySQL 重启后会进行如下恢复:
- 扫描 Redo Log,找到所有处于 prepare 状态的事务。
- 对于每个 prepare 状态的事务,检查 Binlog 中是否存在对应的事务记录:
- 如果存在,说明事务已经完成了 Binlog 写入,将事务提交。
- 如果不存在,说明事务在 Binlog 写入前崩溃,将事务回滚。
这种恢复机制确保了 Redo Log 和 Binlog 的一致性,从而保证了数据的一致性。
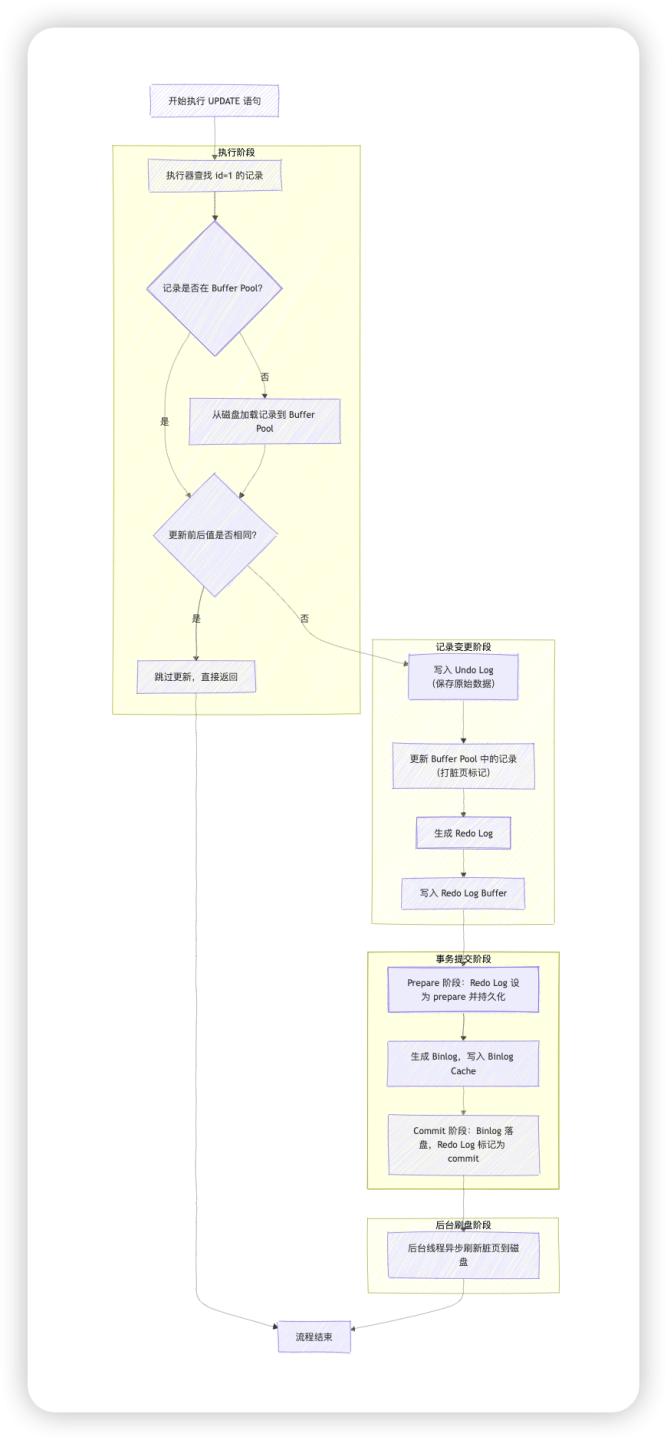
完整的更新流程
当执行一条 UPDATE 语句时,MySQL 内部发生了什么?以 UPDATE t_user SET name = '张三' WHERE id = 1; 为例:
-
执行阶段:
- 执行器通过存储引擎接口查找 id=1 的记录。
- 如果记录在 Buffer Pool 中,直接返回;否则,从磁盘加载到 Buffer Pool。
- 判断更新前后的值是否相同,如果相同则不更新;如果不同则继续。
-
记录变更:
- 先记录对应的 Undo Log,保存修改前的值。
- 在 Buffer Pool 中更新记录(标记为脏页)。
- 生成对应的 Redo Log,记录物理修改。
- 将 Redo Log 写入 Redo Log Buffer。
-
事务提交:
- Prepare 阶段:将 Redo Log 设置为 prepare 状态,并持久化到磁盘。
- 生成对应的 Binlog,写入 Binlog Cache。
- Commit 阶段:将 Binlog 持久化到磁盘,然后将 Redo Log 状态设置为 commit。
-
后台刷盘:
- Buffer Pool 中的脏页会在之后由后台线程刷新到磁盘。
Double Write Buffer:页完整性的保障
为什么需要 Double Write Buffer?
MySQL 中的页默认大小是 16KB,而操作系统的页通常是 4KB。这意味着 MySQL 在将一个页写入磁盘时,需要执行多次操作系统级别的写入。如果在这个过程中发生崩溃,可能导致页面损坏,而这种损坏是无法通过 Redo Log 恢复的。
Double Write Buffer 的工作原理
- 在将脏页写入数据文件前,InnoDB 首先将其写入 Double Write Buffer(一个共享表空间)。
- Double Write Buffer 包含内存部分和磁盘部分。
- 脏页先复制到内存中的 Double Write Buffer(大约 2MB)。
- 内存中的 Double Write Buffer 写入磁盘上的 Double Write 区域(顺序写入)。
- 再将脏页写入实际的数据文件(随机写入)。
崩溃恢复与 Double Write Buffer
如果在写入过程中崩溃,可能发生以下情况:
- 崩溃发生在步骤 4 之前:没有任何影响,可以通过 Redo Log 恢复。
- 崩溃发生在步骤 4 之后,步骤 5 之前:可以从 Double Write 区域恢复完整的页。
- 崩溃发生在步骤 5 过程中:可以从 Double Write 区域恢复完整的页,然后应用 Redo Log。
这种机制确保了即使在写入过程中发生崩溃,也不会导致页面损坏,从而保障了数据的完整性。
值得深入思考的问题
- Undo Log 与 Redo Log 在事务中各负责什么?为什么一个保障原子性,一个保障持久性?
- MVCC 是如何借助 Undo Log 实现非锁定读的?这对并发性能有何影响?
- 在高并发系统中,如何配置 innodb_flush_log_at_trx_commit 和 sync_binlog 来平衡性能与数据安全?
- 为什么 MySQL 需要同时使用 Redo Log 和 Binlog?它们在主从复制和崩溃恢复中分别承担了什么角色?
- InnoDB 为什么要设计 Double Write Buffer?这和页写入失败有关吗?
结语
MySQL 的日志系统是其可靠性和性能的基石。通过深入理解各种日志的原理和作用,我们可以更好地优化数据库性能,确保数据安全。
在实际应用中,需要根据业务需求和系统特点,合理配置日志参数,在数据安全和性能之间找到平衡点。
参考资料
- MySQL 日志:undo log、redo log、binlog 有什么用?
- Java 面试指南 - MySQL 日志
- MySQL 官方文档