deepspeed 滴 ZERO 介绍
我们来详细介绍一下 DeepSpeed ZeRO 的第一阶段:ZeRO-1 (ZeRO-Stage 1)。

背景:传统数据并行 (Data Parallelism - DP) 的显存瓶颈
在理解 ZeRO-1 之前,需要先了解传统数据并行(例如 PyTorch 的 DistributedDataParallel - DDP)的内存消耗情况。在 DDP 中,每个 GPU(或进程)都会:
- 复制完整的模型参数 (Parameters): 所有权重和偏置。
- 复制完整的优化器状态 (Optimizer States): 例如 Adam 优化器需要存储每个参数的动量 (Momentum) 和方差 (Variance)。如果使用 FP32 精度,优化器状态通常是模型参数大小的 2 倍。
- 存储自己计算出的梯度 (Gradients): 大小与模型参数相同。
- 存储前向传播产生的激活值 (Activations): 用于反向传播计算梯度。
这导致了巨大的内存冗余,特别是优化器状态和梯度在所有 GPU 上都被完整地复制了一份。对于非常大的模型,仅仅是模型参数和优化器状态就可能撑爆单个 GPU 的显存。
ZeRO-1 的核心思想:分区优化器状态 (Partitioning Optimizer States)
ZeRO-1 的目标是消除优化器状态的冗余存储,从而显著降低每个 GPU 上的显存占用。它的核心机制是:
- 分区 (Partitioning): 将整个模型的优化器状态(例如 Adam 的动量和方差)分割成 N 份,其中 N 是数据并行的 GPU 数量(world_size)。
- 分布 (Distribution): 每个 GPU 只存储和管理其中 1/N 的优化器状态。
- 分工更新 (Distributed Update): 每个 GPU 只负责更新其所持有的那部分优化器状态对应的模型参数。
ZeRO-1 的工作流程详解
让我们一步步分解 ZeRO-1 在训练迭代中的工作方式:
- 前向传播 (Forward Pass):
- 与标准 DDP 相同:每个 GPU 仍然持有完整的模型参数副本。
- 每个 GPU 处理输入数据的一个分片(mini-batch slice)。
- 计算损失,并存储所需的激活值。
- 内存占用:参数 + 激活值
- 反向传播 (Backward Pass):
- 与标准 DDP 相同:每个 GPU 基于其本地的激活值和模型参数,计算出对应输入分片的完整梯度副本。
- 内存占用:参数 + 激活值 + 梯度
- 梯度聚合 (Gradient Averaging):
- 与标准 DDP 相同:使用 All-Reduce 操作,将所有 GPU 上计算出的梯度进行求和与平均。
- 完成此步骤后,每个 GPU 仍然持有完整的、聚合后的梯度副本。
- 内存占用:参数 + 激活值 + 聚合后的梯度
- 优化器步骤 (Optimizer Step - ZeRO-1 的关键区别):
- 分区更新: 现在,每个 GPU 拥有完整的聚合梯度,但只拥有 1/N 的优化器状态。
- 每个 GPU i (rank i) 使用完整的聚合梯度,但只对其负责的那 1/N 部分参数执行优化器更新(例如 Adam 更新)。它使用自己本地存储的优化器状态分区来完成这个计算。
- 这个更新操作直接修改了 GPU i 本地存储的完整模型参数副本中对应的那一部分。
- 并行性: 所有 GPU 同时、并行地执行各自负责的参数更新计算。
- 内存占用(在此阶段): 参数(部分被更新) + 激活值(可能已释放部分) + 聚合后的梯度(计算后可释放) + 分区的优化器状态
- 参数同步 (Parameter Synchronization):
- 由于每个 GPU 在步骤 4 中只更新了完整参数副本中的一部分,为了让所有 GPU 在下一次迭代开始前拥有完全一致的、更新后的完整模型参数,理论上需要一个同步步骤。
- 但请注意: 在优化器步骤完成后,需要显式的 All-Gather 操作来重新组合参数。
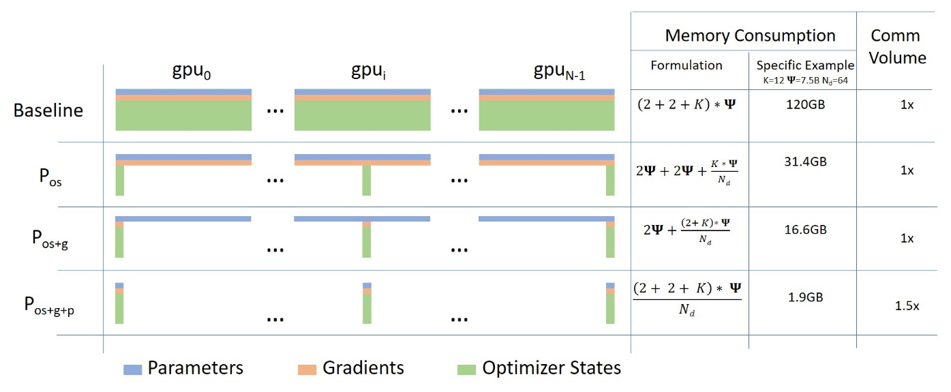
ZeRO-1 的显存节省
- 主要节省: 来自优化器状态。原来每个 GPU 需要存储大小为 O 的优化器状态,现在只需要存储 O / N。
- 参数和梯度: ZeRO-1 不分区参数或梯度。它们仍然在每个 GPU 上完整复制。
- 相比标准 DDP (FP32):
- DDP 显存 ≈ P (参数) + P (梯度) + O (优化器状态,Adam FP32 时 ≈ 2P) + A (激活值) ≈ 4P + A
- ZeRO-1 显存 ≈ P (参数) + P (梯度) + O / N (分区优化器状态,Adam FP32 时 ≈ 2P / N) + A (激活值) ≈ 2P + (2P / N) + A
- 节省量: 大约为 O * (1 - 1/N)。如果使用 Adam (O ≈ 2P),节省量约为 2P * (1 - 1/N)。当 GPU 数量 N 很大时,优化器状态的显存占用接近于零,总显存占用接近 2P + A。因此,相对于 4P + A 的 DDP,ZeRO-1 可以提供显著的显存降低(理论上接近 2 倍,如果优化器状态是主要瓶颈)。
ZeRO-1 的优点
- 显著降低显存: 特别是对于使用 Adam/AdamW 等需要存储多份状态的优化器时效果明显。
- 保持计算效率: 优化器计算本身被分散到各个 GPU,是并行的。
- 通信开销与 DDP 相似: 主要的通信开销仍然是梯度的 All-Reduce 操作,与标准 DDP 基本相同。它没有引入像 ZeRO-3 那样昂贵的参数收集通信。
- 实现相对简单: 是 ZeRO 系列中最简单的一个阶段。
ZeRO-1 的局限性
- 未分区参数和梯度: 模型参数和梯度的冗余存储问题没有解决。对于参数本身就非常巨大的模型,ZeRO-1 可能仍然不足以将其放入显存。
- 梯度 All-Reduce 仍是瓶颈: 和 DDP 一样,训练速度仍然受限于梯度聚合的通信带宽和延迟。
何时使用 ZeRO-1?
- 当你的模型可以装入单个 GPU 显存,但加上优化器状态(尤其是 Adam)后就装不下了。
- 作为从标准 DDP 过渡到更高级 ZeRO 阶段的第一步。
- 当你希望获得显著的显存节省,但又不想引入 ZeRO-2 或 ZeRO-3 可能带来的额外通信开销时。
总结
ZeRO-1 是 DeepSpeed ZeRO 优化的第一个阶段,它通过分区优化器状态来消除内存冗余,显著降低了训练大规模模型所需的显存,同时保持了与传统数据并行相似的通信模式和计算效率。它是解决大模型训练显存瓶颈的有效手段,尤其是在使用 Adam 等复杂优化器时。
ZERO2
分区梯度
优化后单gpu显存占用:2x + (2x + 12x)/N,x为模型参数量,N为gpu数量,12x为优化器状态占用,混合精度训练。
ZERO3
分区模型权重
优化后单gpu显存占用:(2x + 2x + 12x)/N,x为模型参数量,N为gpu数量,12x为优化器状态占用,混合精度训练。