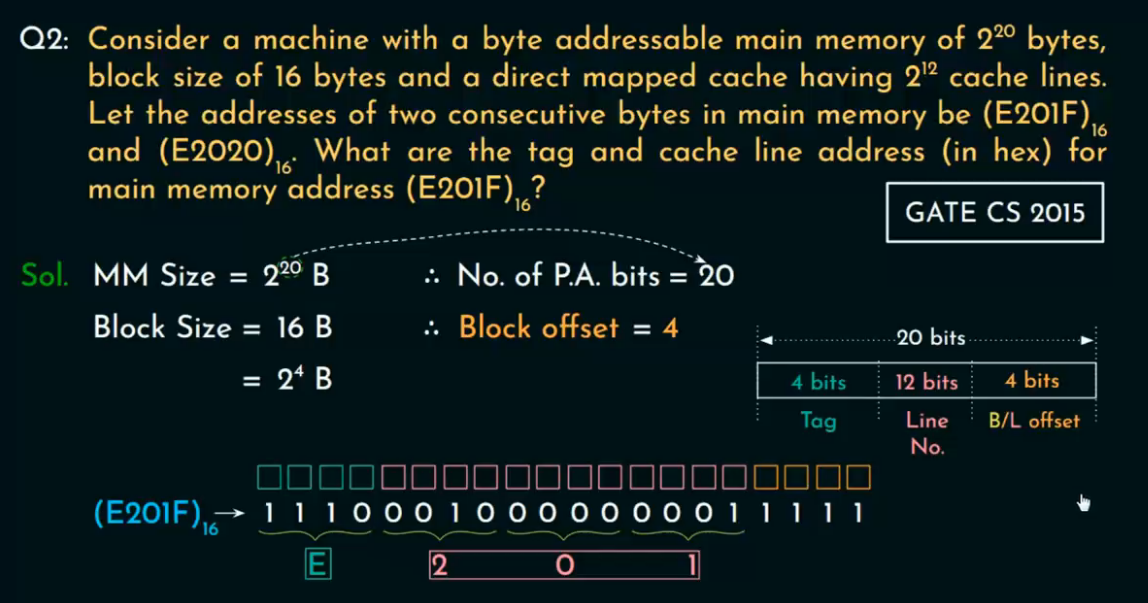
直接映射例题及解析
目录
基本单位换算
例题一
📁 Tag Directory(标签目录) 是什么?
例题二
例题三
例题四
串行访问还是并行访问的选择
例题五
例题六
例题七
🔵 P1:(按行访问)
🔴 P2:(按列访问)
为什么一定会有miss?
为什么按行访问和按列访问的 Miss 不一样?
例题八
地址冲突
在正式解题之前,我们要先理解相关单位和基本概念,建立一个坚实的知识基础。
基本单位换算
这里我们要分清楚两个“进制体系”:
-
十进制单位(以1000为基准,常用于网络带宽等)
-
二进制单位(以1024为基准,常用于内存、缓存容量)
1. 十进制(以1000为基数)
| 中文 | 英文前缀 | 换算关系 | 表示意义 |
|---|---|---|---|
| 千 | Kilo | 1 K = 1000 = 10³ | 一千个单位 |
| 兆 | Mega | 1 M = 1000 K = 10⁶ | 一百万个单位 |
| 吉 | Giga | 1 G = 1000 M = 10⁹ | 十亿个单位 |
这种用法常见于:网络带宽(Mbps)、硬盘厂商标注容量等场景
比如:
-
1 Gbps = 1,000,000,000 bits(十亿位)

2. 二进制(以1024为基数)👉 更常用于内存、缓存
| 中文 | 英文缩写 | 换算关系 | 二进制指数表示 |
|---|---|---|---|
| 千字节 | KB | 1 KB = 1024 Bytes | 2¹⁰ Bytes |
| 兆字节 | MB | 1 MB = 1024 KB = 2²⁰ B | |
| 吉字节 | GB | 1 GB = 1024 MB = 2³⁰ B |
这种定义广泛用于计算机系统、操作系统、编译器、主存/缓存等
比如:
-
1 MB = 1,048,576 Bytes (而不是 1,000,000)
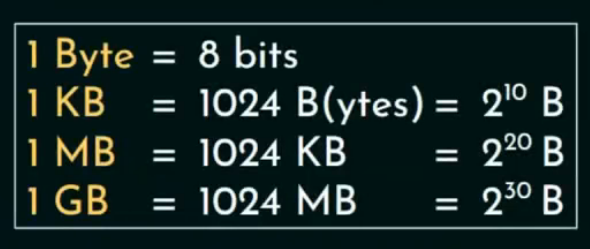
位(bit)和字节(Byte)
| 单位 | 英文 | 大小关系 | 注释 |
|---|---|---|---|
| 位 | bit | 最小单位 | 可取 0 或 1 |
| 字节 | Byte | 1 Byte = 8 bits | 一个 ASCII 字符通常是 1 Byte |
📏 容量单位(Capacity Units)
| 单位(中文) | 单位(英文) | 十进制定义 | 二进制定义 |
|---|---|---|---|
| 千字节 | Kilobyte (KB) | 1 KB = 1000 Bytes | 1 KB = 2¹⁰ = 1024 Bytes |
| 兆字节 | Megabyte (MB) | 1 MB = 1000 KB | 1 MB = 2²⁰ = 1,048,576 Bytes |
| 吉字节 | Gigabyte (GB) | 1 GB = 1000 MB | 1 GB = 2³⁰ = 1,073,741,824 Bytes |
| 字节 | Byte (B) | 1 Byte = 8 bits | - |
| 位 | Bit (bit) | 最小的信息单位 | - |
例题一

📘 1. 物理地址(PA, Physical Address)
物理地址是CPU发出访问内存的真实地址。以**位数(bits)**表示其寻址范围:
-
若物理地址有
n位,则最大可寻址空间为2ⁿBytes。
📘 2. 主存大小(MM Size)
题目给出 MM Size = 4GB,也就是:
4 GB = 4 × 2³⁰ B = 2² × 2³⁰ = 2³² Bytes
=> 所以物理地址长度 PA = 32 bits
📘 3. 块大小(Block Size)
每次从内存载入Cache的一单位是一个块(Block):
-
题目中:Block Size = 4 KB = 2¹² Bytes
-
所以:一个Block中的 Block Offset 需要 12 bits 来寻址
📘 4. 缓存大小(Cache Size)
Cache的总容量为:1 MB = 2²⁰ Bytes
因为每个Block为2¹² Bytes,所以Cache中可以容纳的Block数为:
Number of Blocks in Cache = 2²⁰ Bytes / 2¹² Bytes = 2⁸ Blocks
=> Index 位数 = 8 bits
📘 5. 直接映射(Direct Mapping)
在直接映射结构中,一个内存块只能映射到Cache中的某一个固定位置:
-
物理地址 PA 被划分为三个字段:
[ Tag | Index | Block Offset ]
PA Bits Split(物理地址位分割)
我们已经有:
-
总物理地址位数 = 32 bits
-
Block Offset = 12 bits(由 Block Size 决定)
-
Index = 8 bits(由 Cache block 数量决定)
-
所以剩下的是:Tag = 32 - 8 - 12 = 12 bits
| 字段(中文) | 字段(英文) | 位数(bits) | 来源说明 |
|---|---|---|---|
| 标签位 | Tag Bits | 12 bits | PA剩余位 |
| 索引位 | Index Bits | 8 bits | 2⁸ 个block |
| 块内偏移 | Block Offset | 12 bits | 4 KB block |
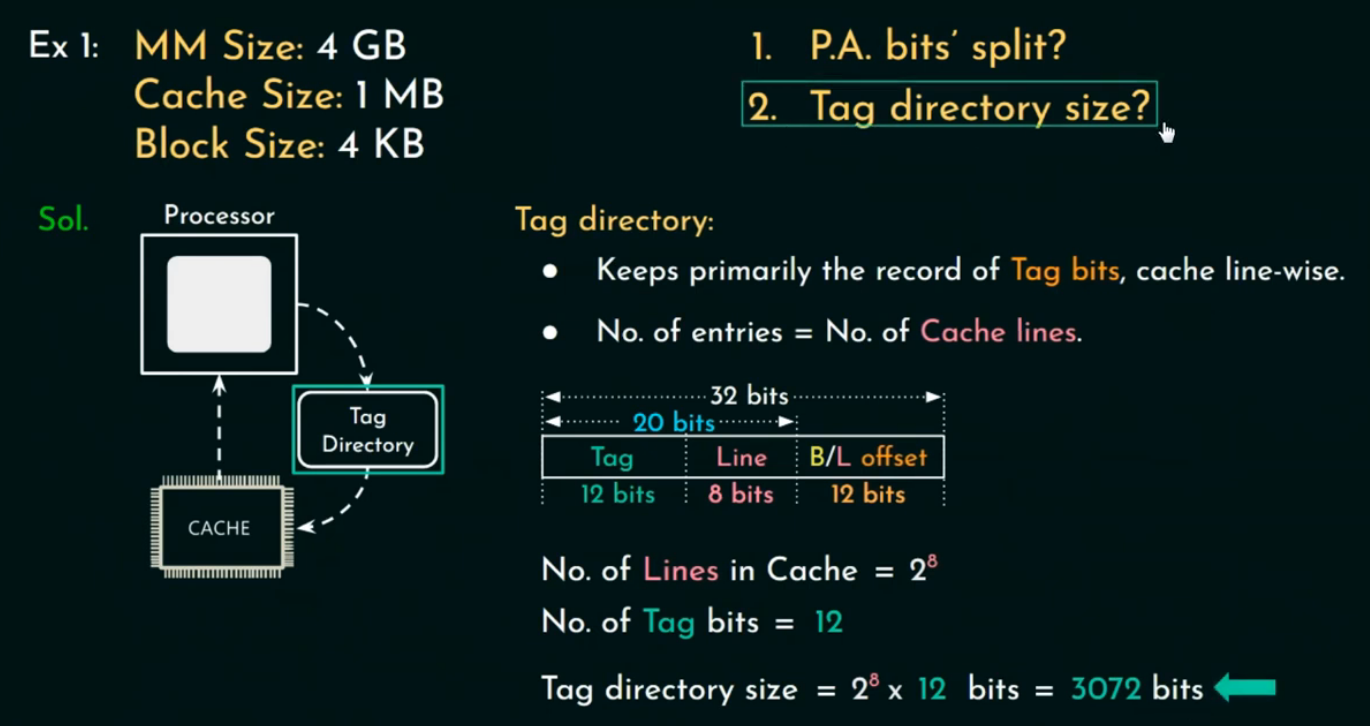
📁 Tag Directory(标签目录) 是什么?
标签目录是缓存中用于记录哪个主存块现在存放在 Cache 的哪个行的标签表。
它确实是“按 cache 行组织”的,也就是:
每一个 Cache Line(缓存行),都对应一条 Tag Directory 的记录!
我们记录的是,当前每个 Cache Line 对应的 Memory Block 的 Tag。
更严谨一点说:
-
主存块数 >> Cache 行数
-
所以多个主存块可能映射到同一个 Cache Line
-
为了区分是谁占了这个 Cache Line,就要存下那个主存块的 “Tag”
每一条记录通常包含:
-
Tag(标签):用来标识当前Cache Block对应的内存块
-
Valid Bit(有效位):表示该块是否有效
-
(可选)Dirty Bit(脏位):在写回法中表示是否被修改
🔸 本题只要求考虑 Tag 本身,忽略 Valid/Dirty 位。
📐 Tag Directory 的大小计算方法
步骤一:计算 Cache 行数(即 Cache lines)
每行存一个 Block:
Cache lines = Cache size / Block size= 2²⁰ / 2¹²= 2⁸
所以 Cache 有 256 行(2⁸)
步骤二:Tag 位数计算
-
物理地址总长:32 bits
-
Block Offset = 12 bits(由块大小决定)
-
Index = 8 bits(由 Cache 行数决定)
Tag 位数 = 32 - Index - Block Offset= 32 - 8 - 12= 12 bits
步骤三:Tag Directory 大小
只记录 Tag 位(不考虑 Valid/Dirty):
Tag Directory size = Number of cache lines × Tag bits= 2⁸ × 12 bits= 256 × 12 = 3072 bits= 384 Bytes
例题二

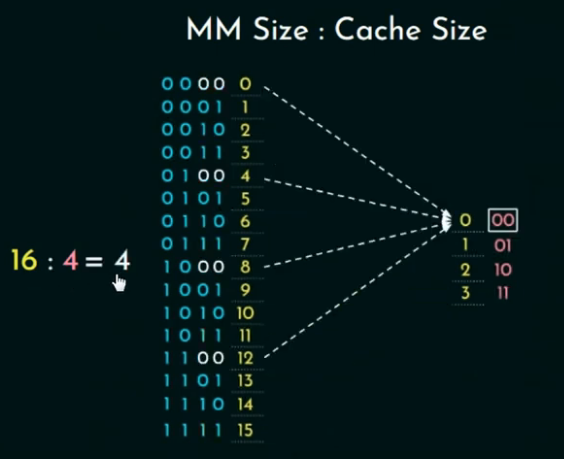
因为 Block Size = Line Size,你可以直接用下面这个公式算:
Tag 位数 = log₂(MM Size / Cache Size)
因为由MM Size : Cache Size 的值,我们可以知道映射到Cache某一行(line)的有多少块(Block)。
上图的实例表明,4个块映射到同一行。
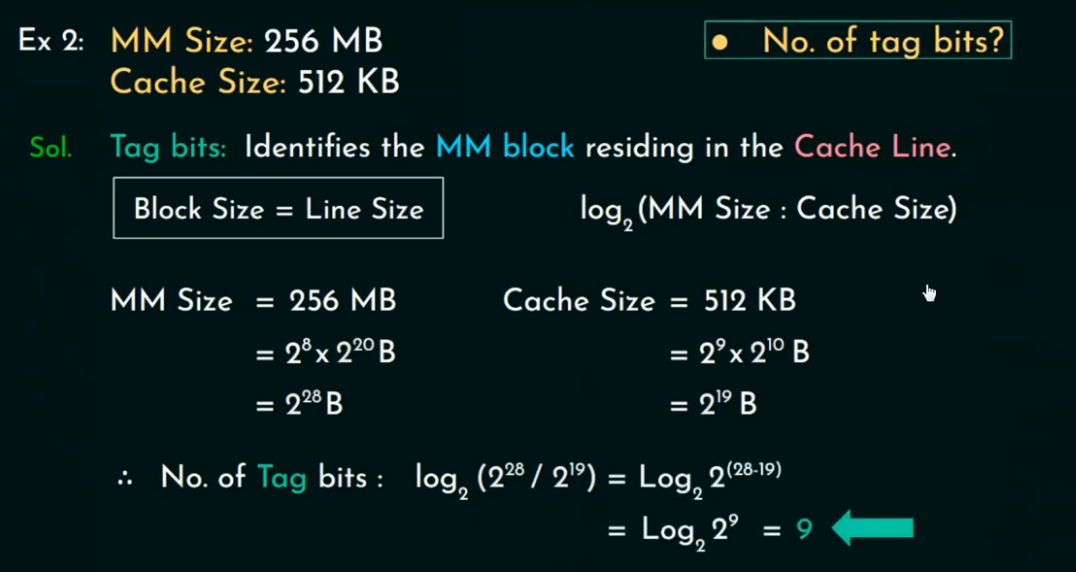
例题三

例题四
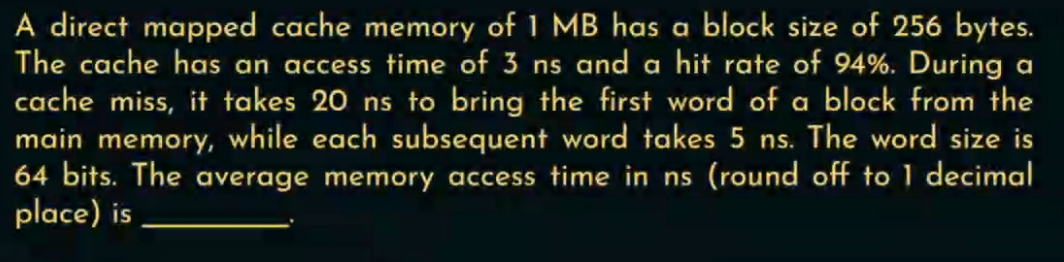
一个直接映射缓存(Direct Mapped Cache)大小为 1MB,块大小为256字节(Bytes)。
-
缓存命中时的访问时间是 3纳秒(ns)。
-
缓存命中率为 94%。
-
当发生 缓存未命中(miss) 时:
-
第一个字从主存中传输需要 20ns
-
其余每个字的传输时间为 5ns/字
-
-
一个字(Word)的大小是 64位 = 8字节
问题: 求平均内存访问时间(Average Memory Access Time, AMAT),精确到小数点后1位。
串行访问还是并行访问的选择
在计算主存访问时间时,如果题目中给出的是:
-
“first word takes X ns”
-
“each subsequent word takes Y ns”
就要问自己:
❓ 是并行加载所有字,还是一个接一个串行加载?
这道题的正确思路是:
🔸 这是串行传输(Serial Transfer)!
理由如下:
-
题目中明确说:
-
第一字传输用 20ns
-
后续每字用 5ns
-
-
如果是并行传输,那就应该是一次性所有字只用最长那个时间。但这里强调“每个”说明是串行!
关于这方面(串行访问与并行访问)的具体内容,可以在这篇文章中查看:
计算机组成与体系结构:内存接口(Memory Interface)-CSDN博客

例题五

例题六

例题七
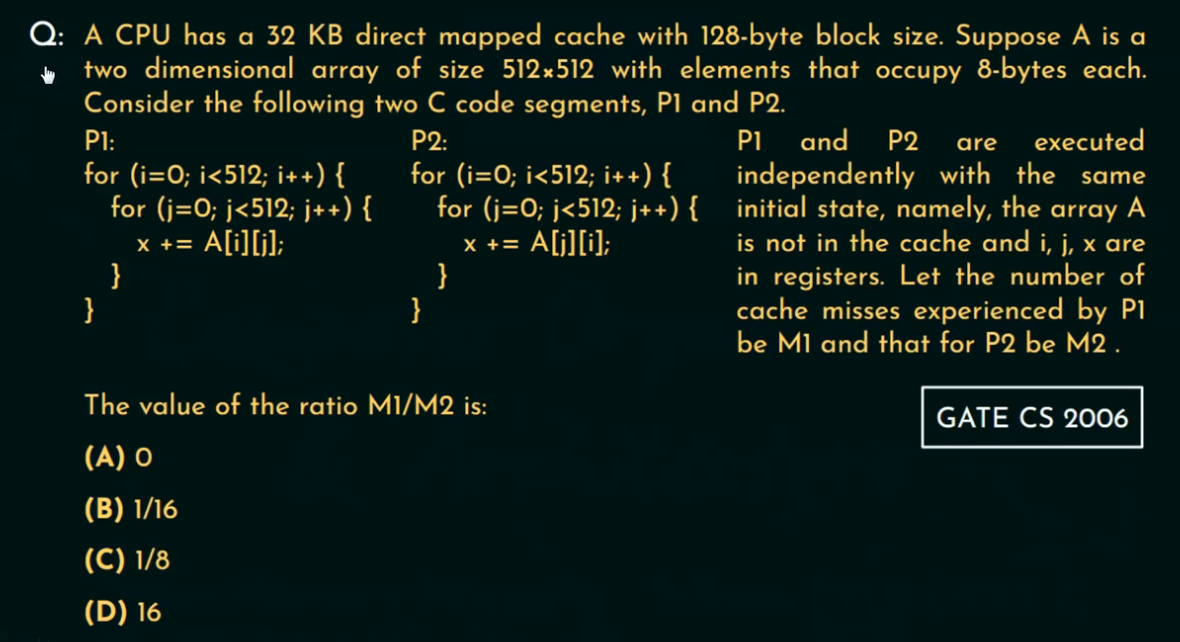
一台 CPU 配备了一个32KB大小的直接映射(Direct-Mapped)缓存,块大小为128字节。
现在有一个二维数组 A,尺寸是512 × 512,每个元素占用8字节。
考虑下面两个独立执行的 C 代码段 P1 和 P2:
P1:按 行优先(row-major)顺序访问数组。
P2:按 列优先(column-major)顺序访问数组。
初始条件: A数组一开始不在缓存中,i、j、x 都在寄存器中。
问题:
执行P1时,缓存未命中次数记为 M1。执行P2时,缓存未命中次数记为 M2。
计算并选择 M1/M2 的值

一个 Cache Block 可存储:
128 Bytes / 8 Bytes per element = 16 elements
即一个块可以装下连续16个元素(在内存中连续的)。
🔵 P1:(按行访问)
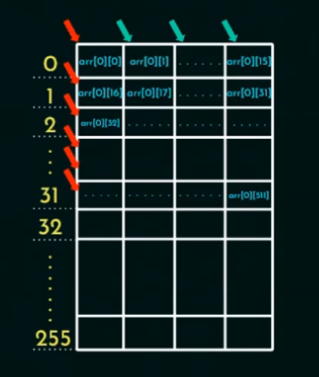
特点:
-
内存是行优先存储(Row-Major),
-
A[i][j]和A[i][j+1]在内存中是连续的。 -
一个 Cache Block 可以放下 16 个元素。
一次 miss 后,可以利用的连续缓存:
-
第一次访问
A[i][0]:miss -
然后
A[i][1]~A[i][15]:全是 hit!(因为它们都在同一个缓存块中) -
直到访问到
A[i][16],再 miss。
所以:
每访问 16 个元素只 miss 1 次
每一行有 512 个元素,划分成:512 / 16 = 32块
每一行就有 32 次 miss。
M1 = 512 × 32 = 16,384 次
🔴 P2:(按列访问)
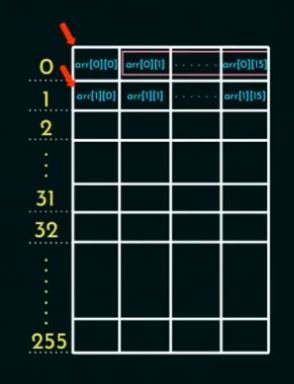
特点:
-
列优先访问,但是内存按行优先存储。
-
A[j][i]与A[j+1][i]在内存中 不连续。 -
A[0][i]和A[1][i]分别在不同的行,相隔 512×8=4096 Bytes。 -
它们肯定不在同一个 Cache Block。
所以:
-
每访问一个元素
A[j][i],都会导致 一次 miss! -
因为访问的是不同缓存块(地址跳得太大),缓存局部性被破坏了。
全局总miss:
-
总访问次数 = 512 × 512 = 262,144 次
-
每次都 miss
所以:
M2 = 262,144 次
为什么一定会有miss?
实际上 miss 并不是一定存在的,它取决于当时 Cache 里的数据和你访问的数据是不是吻合。
但是,在某些特定情况下,一开始访问必然会miss,比如:
特别情况:
-
题目明确说了:"数组A一开始不在缓存中"。
-
所以当我们第一次访问数组A的任意元素时,必然miss!
-
后续如果继续访问已经加载到Cache里的数据,就可能hit。
为什么按行访问和按列访问的 Miss 不一样?
这要结合访问方式来看:
在按行访问(P1)时:
-
因为元素在内存中是连续的。
-
一个 Cache Block 可以放 16 个元素。
-
第一个元素 miss,后面 15 个元素 hit(空间局部性好)。
-
所以不是每次访问都 miss,每16个元素只miss 1次。
在按列访问(P2)时:
-
访问顺序是跳着走的:
-
A[0][i]→A[1][i]→A[2][i]……
-
-
每次跳跃4096 Bytes(因为数组按行存,每行512×8=4096 Bytes)。
-
跳得太远,Cache块根本无法覆盖这么远的跨度。
-
而且是直接映射缓存,不同地址很容易映射到同一个Cache行,导致原来装的数据被替换掉。
因此在列访问中:
每次访问基本都是新的块,所以每次访问都会miss!
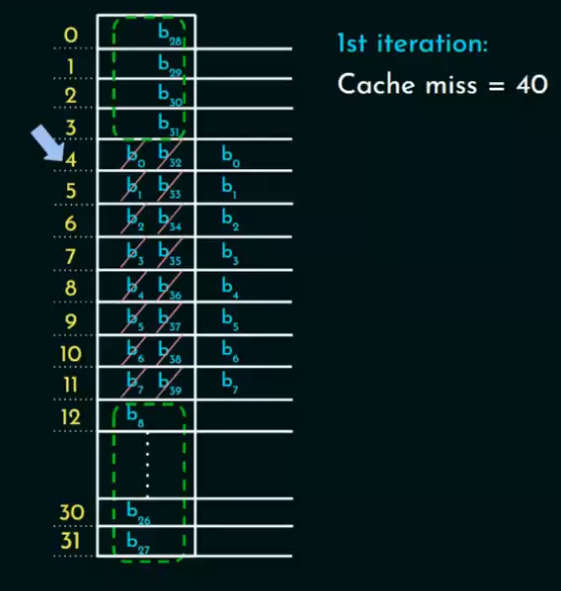
例题八

考虑一台主存为 2^16 字节、按字节寻址(byte-addressable)的计算机。
系统中使用一个直接映射(Direct Mapped)数据缓存,缓存由32行(lines)组成,每行大小为64字节。
有一个大小为 50×50 的二维字节数组,存储在主存中,从地址 1100H(十六进制)开始。
假设:
-
数据缓存初始为空。
-
完整访问这个数组两遍。
-
在两次访问之间,缓存内容不会变化(不会刷新)。
问题:
i. 访问两遍数组,总共有多少次缓存未命中(Cache Miss)?
选项:
-
(A) 40
-
(B) 50
-
(C) 56
-
(D) 59
ii. 在第二次访问数组时,会替换缓存中哪些行?
选项:
-
(A) line 4 到 line 11
-
(B) line 4 到 line 12
-
(C) line 0 到 line 7
-
(D) line 0 到 line 8
基础参数

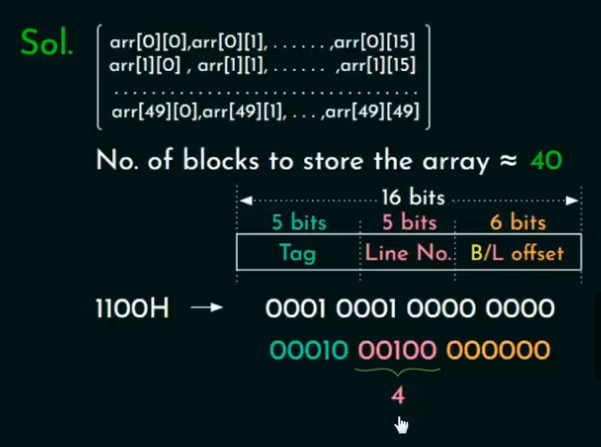
第一次访问:
从地址1100H 开始,依次访问 2500个元素。
因为一个 Cache Block 装64个字节,
-
向上取整 → 需要 40个块(因为最后一块可能不满,但仍然需要加载)。
所以第一次访问会造成 40次miss(每次加载一个新的缓存块)。
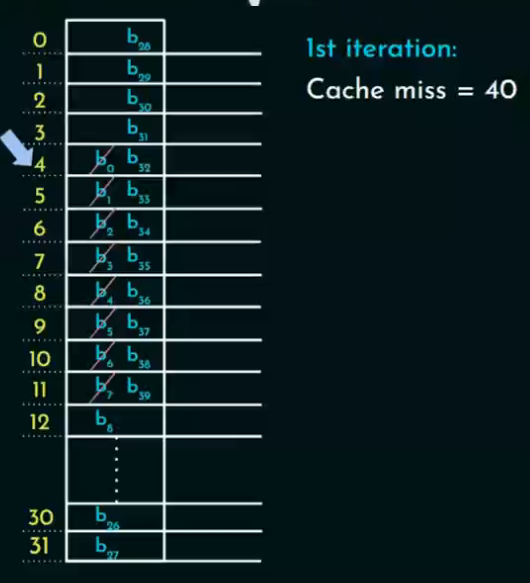
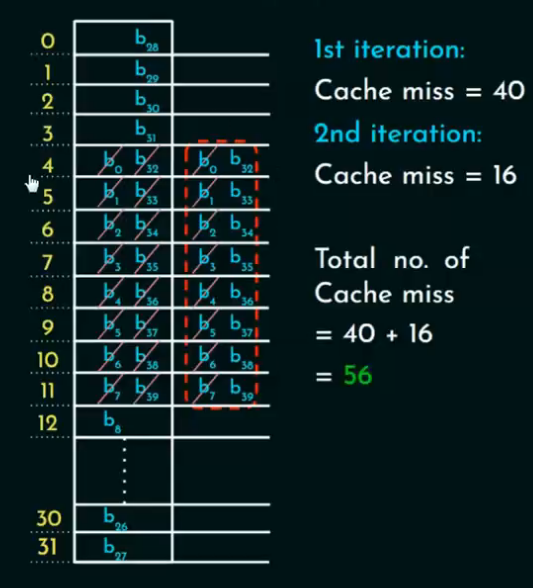
地址冲突
第二次访问:
-
由于"缓存内容不会变化",所以如果之前访问的数据仍然在 Cache 中,就不会miss。
-
但是!因为是直接映射,地址冲突可能导致 Cache Line 被替换!