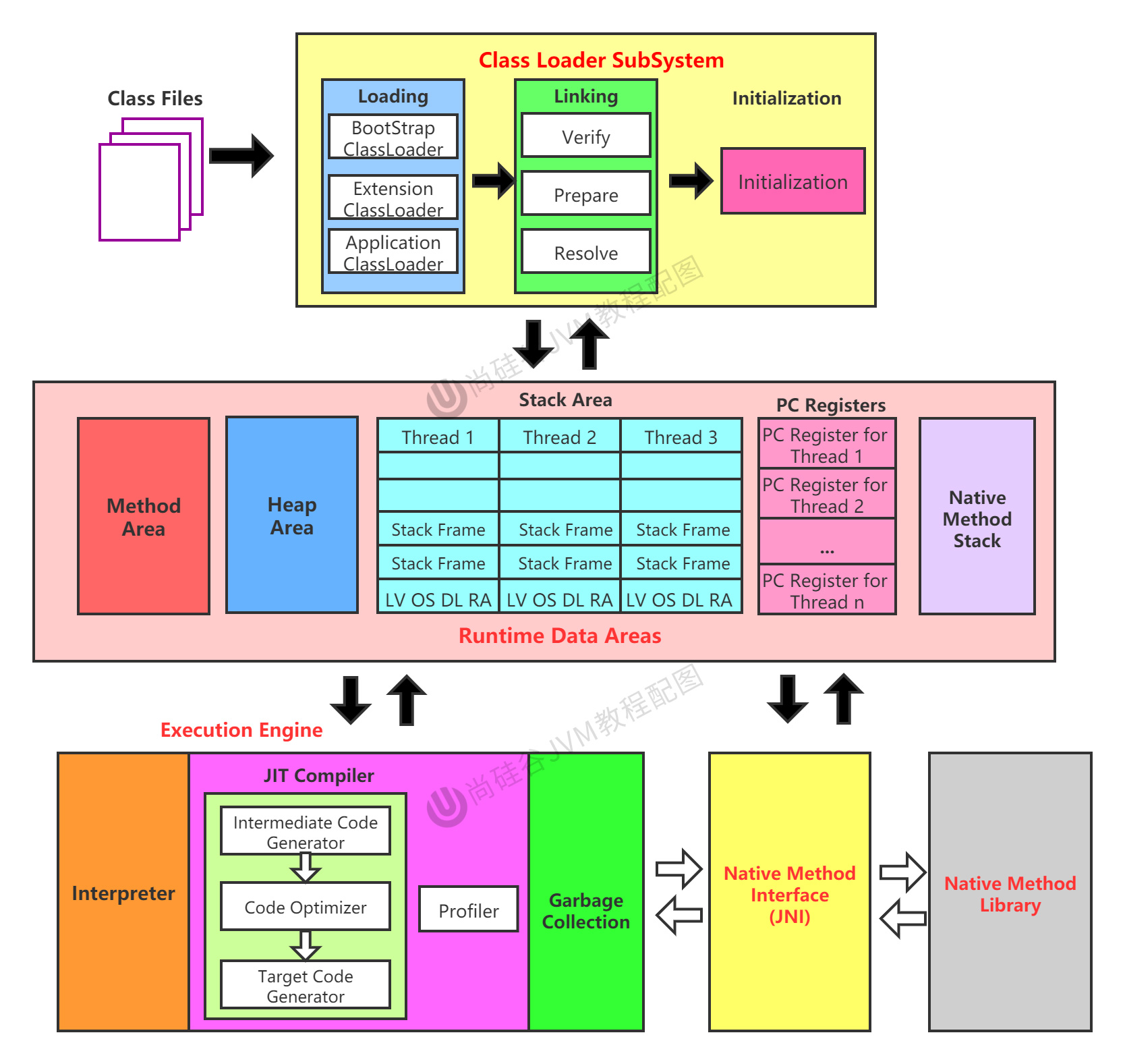
在很多时候,构建并优化完模型并不代表这个问题就被解决了。事实上,很多时候,在第一次优化结束并进行预测时,其与真实值之间的误差都会提醒你这个模型需要继续优化。那么,我们应该怎么优化它呢?
选择更多的样本数据放入训练集是一个方法,毕竟,结果误差可能是因为有意料之外的特征没有考虑到,而纳入更多的数据进入数据集可以帮助计算机在特征分析上有更广阔的视角。但事实上,很多时候选取更大的训练集不会有很好的实际作用。当然了,像人为地去对特征量做增加或减少,增加多项式特征,调整正则化参数的大小也是很有效的方法,选择的方向是重中之重,选择对的方向可以事半功倍,但我们该怎么能知道哪个方向是有效的呢?
评估算法(Evaluating hypothesis)
在选择方向之前,跟去看病一样,医生给药单之前会诊断病因,我们在选择优化方向之前也要评估一下我们的算法,看看是哪里出了问题,这有助于我们选择好的方向去优化。
在之前,我们提到单单根据误差来判断选择的参数是好是坏并不绝对,有可能会因为过拟合的原因导致在将其应用到新样本时不匹配。原先我们通过观察假设函数的图像来判断,但通常来说,对于特征量不止一个的例子,这种做法变得很难甚至不可能做到。
以之前线性回归的房价为例子,假设训练集中有10个样本,我们将其分为两部分:训练集和测试集,一般分割比例为7:3,最好是进行随机选择而不是直接按照前后顺序分割,可以在分割前将数据打乱进行随机分布来达到这个效果。我们在训练并测试线性回归算法时,通常会按照以下步骤进行:
-
对训练集进行学习得到参数
,也就是最小化训练误差
,这里的训练集是进行分割后,用70%的数据量进行学习的。
-
将第一步得到的参数带入测试集的代价函数来计算测试的误差
如果换成逻辑回归的分类问题,步骤也是一样的,只不过比起线性回归,逻辑回归在第二步计算的误差可以用另一个错误度量法来表明,区别在于后者是以预测正确和预测错误的情况数量作为基准来计算。
模型选择、训练、验证和测试集(model selection and training/validation/test sets)
假设我们要选择能最好拟合数据的多项式次数,我们该选择哪个次数呢?我们用 d表示选择的多项式次数,如果我们对次数1-10的假设函数全都做了一边测试,筛选出了一个最好的,假设
,那么我们是不是就能认为应该用5次项的参数来拟合呢?实际上,反思我们这一系列做法,我们通过训练集得到的参数用于测试集,再用测试集得到的误差来判断怎么优化,但实际上在同一组数据上得出的结果再次应用在自己数据本身,这本就会让结果偏好一些,毕竟其特征完美符合原来的数据,但我们真正关心的是其在新样本上的表现。

将数据集分成训练集、验证集和测试集

用计算训练集得出的参数运用到验证集中,测试集也是
还是跟上述说的一样分割数据集,不同的是,我们在数据集多分割出一个交叉验证集,训练集、验证集和测试集比例为6:2:2,步骤也是在计算训练集和测试集中间加入一个计算验证集的误差,然后将计算得到的验证集误差用于评判用哪个次数的多项式。这样做的好处就是避免了将测试集用于判断用哪个函数进行拟合,毕竟用结果验证结果跟作弊并没有什么区别。
视频参考链接:第61讲 诊断偏差与方差_哔哩哔哩_bilibili