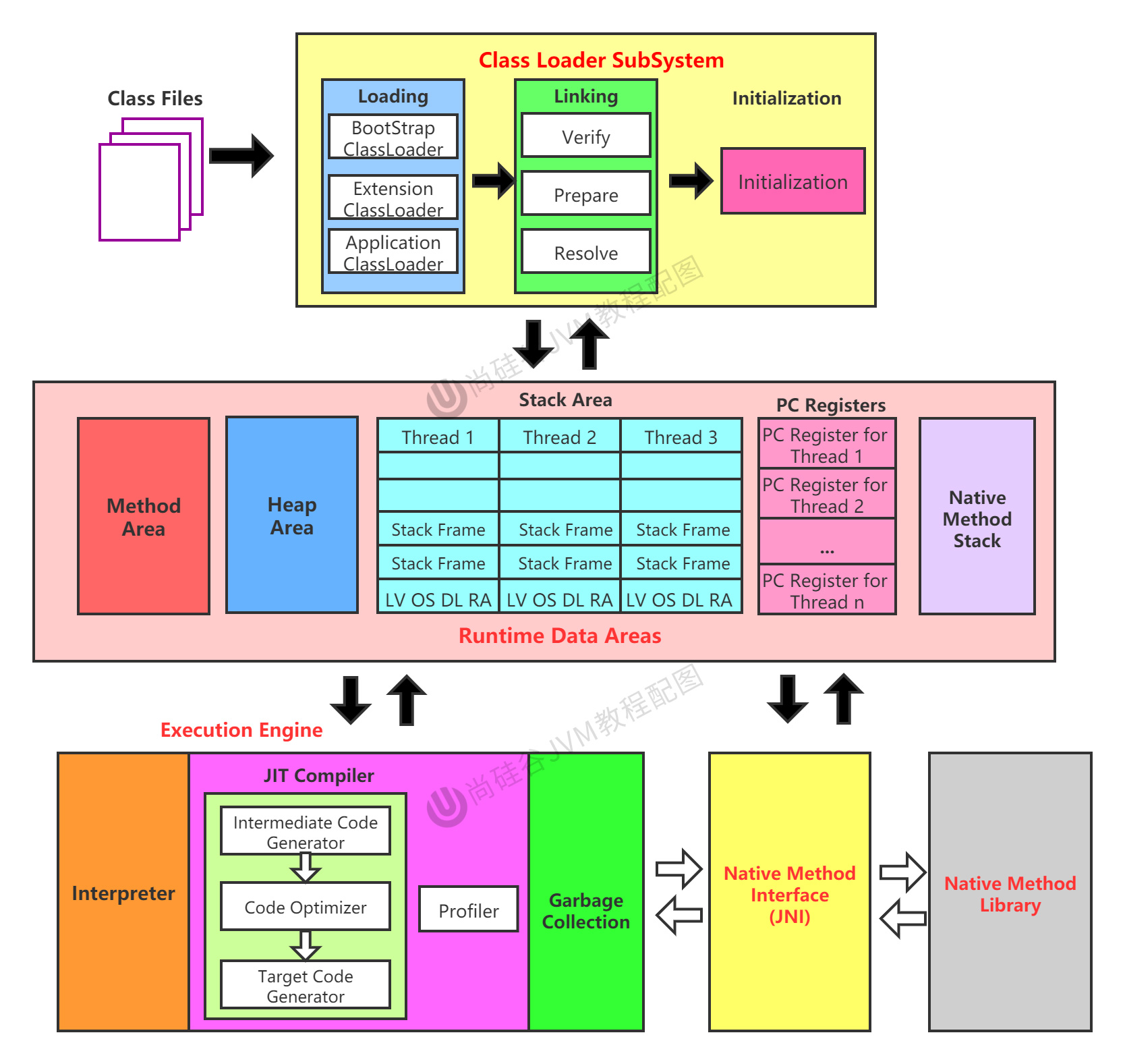
1. 前言
本篇博客是个人的经验之谈,不是普适的解决方案。阅读本篇博客的朋友,可以参考这里的写法,如有不同的见解和想法,欢迎评论区交流。如果此篇博客对你有帮助,感谢点个赞~
2. 场景
我们讨论在单体项目,单个实例中的定时任务相关问题。暂时先不讨论单体项目多副本的情况,也不讨论分布式定时任务。针对分布式定时任务,下一篇博客中再详细讨论。
开发中遇到的场景是:一个单体项目,就比如一个后台管理系统需要多个定时任务去做一些业务处理。比如如下两个定时任务(以下定时任务是随便写的,目的是模拟系统中存在不同的定时任务,不需要纠结任务的合理性):
(1)每隔10秒从网络上获取某些产品信息;
(2)每隔3秒统计新注册的用户;
3. 需求实现
3.1 实现方式一
3.1.1 代码
有了如上两个定时任务的需求,首先想到了SpringBoot中可以使用 @Scheduled 快速开启一个定时任务。代码如下:
import lombok.extern.slf4j.Slf4j;
import org.springframework.scheduling.annotation.EnableScheduling;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;@EnableScheduling
@Component
@Slf4j
public class MyJob {// 每隔2秒从网络上获取某些产品信息@Scheduled(cron = "*/2 * * * * ?")public void getProductInfo() throws InterruptedException {log.info("定时任务 - 从网络上获取某些产品信息");// 模拟业务耗时操作Thread.sleep(5000);}// 每隔3秒统计新注册的用户@Scheduled(cron = "*/3 * * * * ?")public void userJob() throws InterruptedException {log.info("定时任务 - 统计新注册的用户");// 模拟业务耗时操作Thread.sleep(1000);}}3.1.2 结果分析
对上述定时任务的执行结果进行分析如下:

3.2 实现方式二
3.2.1 代码
在上述 <实现方式一> 的基础上进行改进,给每次触发的定时任务分配一个线程去执行。注意:是每次触发定时任务时,给其分配一个线程,不要理解成给某个定时任务方法单独分配一个线程。再详细一些的解释:比如 "获取产品信息" 这个定时任务方法,每隔2秒触发一次,我们要实现的目标是:每隔2秒触发时,都为其分配一个线程去执行。
要实现上述需求,可以定义一个线程池,每次定时任务触发时,从线程池中分配一个线程去执行当前的定时任务。我们可以把线程池的一些配置信息放到配置文件中,如下是自定义线程池的代码:
3.2.1.1 线程池的配置
在配置文件中指定线程池参数的配置信息,在实际生产环境中,如果需要修改线程池参数配置,修改配置文件即可。
# 自定义线程池相关配置(这里的线程池参数配置需要根据不同系统进行制定,这里只是一个示例)
custom:thread:core-pool-size: 20maximum-pool-size: 50queue-capacity: 10000keep-alive-time: 10name-prefix: "scheduled-thread-"3.2.1.2 配置类
和配置文件中以 customer.thread 开头的配置信息进行绑定
package com.shg.distributed.lock.component;import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;/*** @DESCRIPTION: 和自定义线程池相关的配置项,比如配置线程池的核心线程数* 最大线程数、阻塞队列的容量大小、非核心线程的存活时间等* @USER: shg* @DATE: 2024/06/24*/
@Data
@ConfigurationProperties(prefix = "custom.thread")
public class ThreadPoolConfigProperties {private int corePoolSize;private int maximumPoolSize;private int queueCapacity;private int keepAliveTime;private String namePrefix;}3.2.1.3 自定义线程池类
package com.shg.distributed.lock.component;import org.springframework.boot.context.properties.EnableConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.annotation.EnableAsync;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;import java.util.concurrent.Executor;
import java.util.concurrent.ThreadPoolExecutor;@Configuration
@EnableConfigurationProperties({ThreadPoolConfigProperties.class})
public class ScheduledThreadPool {private final ThreadPoolConfigProperties threadPoolConfigProperties;public ScheduledThreadPool(ThreadPoolConfigProperties threadPoolConfigProperties) {this.threadPoolConfigProperties = threadPoolConfigProperties;}@Bean(name = "asyncServiceExecutor")public Executor asyncServiceExecutor() {//阿里巴巴编程规范:线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。//SpringBoot项目,可使用Spring提供的对 ThreadPoolExecutor 封装的线程池 ThreadPoolTaskExecutor:ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();//配置核心线程数executor.setCorePoolSize(threadPoolConfigProperties.getCorePoolSize());//配置最大线程数executor.setMaxPoolSize(threadPoolConfigProperties.getMaximumPoolSize());//配置队列大小executor.setQueueCapacity(threadPoolConfigProperties.getQueueCapacity());// 非核心线程的存活时间executor.setKeepAliveSeconds(threadPoolConfigProperties.getKeepAliveTime());//配置线程池中的线程的名称前缀executor.setThreadNamePrefix(threadPoolConfigProperties.getNamePrefix());// rejection-policy:当pool已经达到max size的时候,如何处理新任务// 1、CallerRunsPolicy:不在新线程中执行任务,而是由调用者所在的线程来执行。// "该策略既不会抛弃任务,也不会抛出异常,而是将任务回推到调用者。"顾名思义,在饱和的情况下,调用者会执行该任务(而不是由多线程执行)// 2、AbortPolicy:拒绝策略,直接拒绝抛出异常//executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());executor.setRejectedExecutionHandler(new ThreadPoolExecutor.AbortPolicy());//执行初始化executor.initialize();return executor;}
}
3.2.1.4 主启动类
主启动类上主要是标注:@EnableAsync 和 @EnableScheduling注解
package com.shg.distributed.lock;import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.scheduling.annotation.EnableAsync;
import org.springframework.scheduling.annotation.EnableScheduling;
@EnableAsync
@EnableScheduling
@SpringBootApplication
public class DistributedLockApplication {public static void main(String[] args) {SpringApplication.run(DistributedLockApplication.class, args);}}3.2.2 结果分析
对上述定时任务的执行结果分析如下:

4. 存在的问题
4.1 问题分析
现在思考一个问题:"获取产品" 这个定时任务触发后,执行业务需要耗时5秒钟,但是定时任务是每隔2秒执行一次。如果每次定时任务被触发执行时,都为其分配一个线程。则会出现如下情况:
(1)15:21:50秒时刻触发一次定时任务,从线程池中拿一个线程 T1 开始处理业务逻辑;
(2)15:21:52秒时刻又触发执行定时任务,从线程池中拿一个线程 T2 开始处理业务逻辑(此时肯定拿不到线程 T1,因为 T1 线程还在处理第一个定时任务);
(3)15:21:54秒时刻又触发执行定时任务,从线程池中拿一个线程 T3 开始处理业务逻辑(此时肯定拿不到线程 T1和T2,因为 T1 和 T2线程都在处理各自的定时任务中的业务逻辑);
(4)15:21:55秒时刻,T1线程的业务逻辑处理完毕,T1线程释放,归还给线程池
(5)15:21:56秒时刻又触发执行定时任务,从线程池中拿一个线程 T4 开始处理业务逻辑(此时肯定拿不到线程T2 和 T3, 因为 T2 和 T3线程都在处理各自的定时任务中的业务逻辑);
代码示例和输出结果如下:

4.2 问题解决
上面分析了 <当定时任务触发的时间间隔比处理业务耗时要小> 这种情况。大白话解释就是:上一个定时任务还没执行完成,下一个定时任务又开始了。
而在实际的业务逻辑中,当一个定时任务触发执行后,下一次定时任务需要等到上一个定时任务执行完毕之后,才能开始执行。
此时,我们就可以在定时任务触发时,为其加一把锁,如果成功获取到锁,则开始执行,执行完毕之后,就释放锁。如果在一个定时任务执行过程中,又触发了一次定时任务,此时是获取不到锁的,这个定时任务就不会执行业务逻辑了。
进一步说明加锁后的效果,让打印信息更详细一些,注意图中每对【开始】-【结束】之间相差刚好是5秒。如下图:

5. 总结
以上我们从一个需求出发,讨论了
(1)直接使用@Scheduled注解开启一个定时任务的方式及其遇到的问题;
(2)接着针对(1)中的问题,我们自定义了线程池,让每次触发的定时任务,在不同的线程中执行,避免了一个项目中多个定时任务都在同一个线程中执行,导致定时任务阻塞的问题;
(3)针对(2),如果一个定时任务没有执行完毕,下一个定时任务又开启了这种不合理的逻辑,我们通过简单的加锁方式解决了此问题。
但是要注意,这里我们只是讨论并解决了 【单体项目-部署单个实例】中的定时任务的一些问题,并没有解决【单体项目-多副本实例】和【分布式项目中定时任务】的定时任务相关问题。
接下来的博客会对【单体项目-多副本实例】和【分布式项目中定时任务】进行讨论。主要讨论如下问题:
(1)如何给定时任务添加分布式锁;
(2)如何给定时任务添加的分布式锁进行续期;
(3)其他一些衍生问题...
如果此篇文章对你有些许启发和帮助,感谢点个赞~