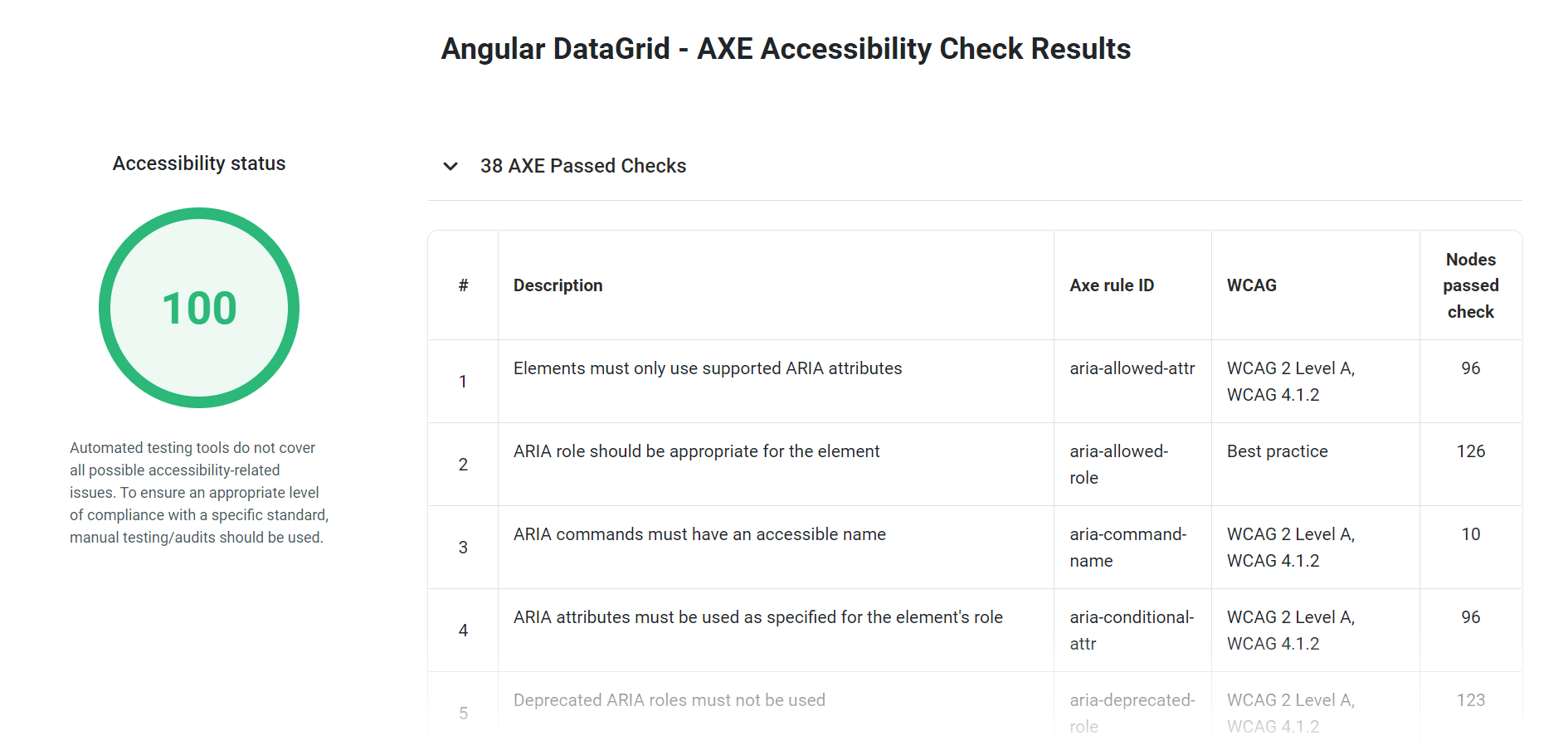
yelp数据集是研究B2C业态的一个很好的数据集,要识别潜在的热门商家是一个多维度的分析过程,涉及用户行为、商家特征和社区结构等多个因素。从yelp数据集里我们可以挖掘到下面信息有助于识别热门商家
用户评分和评论分析
- 评分均值: 商家的平均评分是反映其受欢迎程度的重要指标。较高的平均评分通常意味着顾客满意度高,从而可能成为热门商家。
- 评论数量: 评论数量可以反映商家的活跃度和用户的参与程度。评论数量多的商家更可能受到广泛关注。
用户活跃度
- 用户评分行为: 分析活跃用户(频繁评分的用户)对商家的评分,可以识别出哪些商家在用户群体中更受欢迎。
- 用户影响力: 一些用户的评分会对其他用户的选择产生较大影响(例如,社交媒体影响者)。识别这些高影响力用户对商家的评分可以帮助识别潜在热门商家。
社交网络分析
- 用户与商家的关系网络: 使用图神经网络等算法分析用户与商家之间的关系。商家与许多用户有互动,且用户在网络中有较高影响力的商家,可能会被视为热门商家。
- 社区发现: 通过分析用户和商家之间的关系网络,识别出相似用户群体,进而识别出在这些群体中受欢迎的商家。
多维度评价
- 综合评价: 结合多个指标(如评分、评论数、用户活跃度、地理位置等),使用加权方法或多指标决策模型来综合评估商家的受欢迎程度。
使用的文件
-
yelp_academic_dataset_business.json:- 包含商家的基本信息,如商家 ID、名称、类别、位置等。
-
yelp_academic_dataset_review.json:- 包含用户对商家的评论及评分,可以用来分析商家的受欢迎程度和用户的行为。
-
yelp_academic_dataset_user.json:- 包含用户的基本信息,比如用户 ID、注册时间、评价数量等,可以用来分析用户的活跃度和影响力。
通过图神经网络(GNN)来识别商家的影响力:
先加载必要的库并读取数据文件:
import pandas as pd
import json# 读取数据
with open('yelp_academic_dataset_business.json', 'r') as f:businesses = pd.DataFrame([json.loads(line) for line in f])with open('yelp_academic_dataset_review.json', 'r') as f:reviews = pd.DataFrame([json.loads(line) for line in f])with open('yelp_academic_dataset_user.json', 'r') as f:users = pd.DataFrame([json.loads(line) for line in f])清洗数据以提取有用的信息:
# 过滤出需要的商家和用户数据
businesses = businesses[['business_id', 'name', 'categories', 'city', 'state', 'review_count', 'stars']]
reviews = reviews[['user_id', 'business_id', 'stars']]
users = users[['user_id', 'review_count', 'average_stars']]# 处理类别数据
businesses['categories'] = businesses['categories'].str.split(', ').apply(lambda x: x[0] if x else None)构建商家和用户之间的图,节点为商家和用户,边为用户对商家的评分。
edges = []for _, row in reviews.iterrows():if row['user_id'] in node_mapping and row['business_id'] in node_mapping:edges.append([node_mapping[row['user_id']], node_mapping[row['business_id']]])edge_index = torch.tensor(edges, dtype=torch.long).t().contiguous()return node_mapping, edge_index, total_nodes我们可以通过以下方式计算商家的影响力:
- 用户评分的平均值: 表示商家的受欢迎程度。
- 评论数: 提供商家影响力的直观指标。
business_reviews = reviews.groupby('business_id').agg({'stars': ['mean', 'count']
}).reset_index()
business_reviews.columns = ['business_id', 'average_rating', 'review_count']# 合并商家信息和评论信息
merged_data = businesses.merge(business_reviews, on='business_id', how='left')# 3. 目标变量定义
# 定义热门商家的标准
merged_data['is_popular'] = ((merged_data['average_rating'] > 4.0) &(merged_data['review_count'] > 10)).astype(int)使用 GNN 进一步分析商家的影响力 ,可以构建 GNN 模型并训练。以下是 GNN 模型的基本示例,使用 PyTorch Geometric:
class GNNModel(torch.nn.Module):def __init__(self, num_node_features):super(GNNModel, self).__init__()self.conv1 = GCNConv(num_node_features, 64)self.conv2 = GCNConv(64, 32)self.conv3 = GCNConv(32, 16)self.fc = torch.nn.Linear(16, 1)self.dropout = torch.nn.Dropout(0.3)def forward(self, x, edge_index):x = F.relu(self.conv1(x, edge_index))x = self.dropout(x)x = F.relu(self.conv2(x, edge_index))x = self.dropout(x)x = F.relu(self.conv3(x, edge_index))x = self.fc(x)return x使用模型的输出嵌入来分析商家之间的相似度,识别潜在的热门商家。
print("Making predictions...")model.eval()with torch.no_grad():predictions = torch.sigmoid(model(data.x.to(device), data.edge_index.to(device))).cpu()# 将预测结果添加到数据框merged_data['predicted_popularity'] = 0.0for _, row in merged_data.iterrows():if row['business_id'] in node_mapping:idx = node_mapping[row['business_id']]merged_data.loc[row.name, 'predicted_popularity'] = predictions[idx].item()# 输出潜在热门商家potential_hot = merged_data[(merged_data['predicted_popularity'] > 0.5) &(merged_data['is_popular'] == 0)].sort_values('predicted_popularity', ascending=False)print("\nPotential Hot Businesses:")print(potential_hot[['name', 'average_rating', 'review_count', 'predicted_popularity']].head())使用上面定义流程跑一下训练, 报错了
Traceback (most recent call last):
File "/opt/miniconda3/envs/lora/lib/python3.10/site-packages/pandas/core/indexes/base.py", line 3805, in get_loc
return self._engine.get_loc(casted_key)
File "index.pyx", line 167, in pandas._libs.index.IndexEngine.get_loc
File "index.pyx", line 196, in pandas._libs.index.IndexEngine.get_loc
File "pandas/_libs/hashtable_class_helper.pxi", line 7081, in pandas._libs.hashtable.PyObjectHashTable.get_item
File "pandas/_libs/hashtable_class_helper.pxi", line 7089, in pandas._libs.hashtable.PyObjectHashTable.get_item
KeyError: 'review_count'
把print('merged_data', merged_data) 加上再试下
[150346 rows x 16 columns]
Index(['business_id', 'name', 'address', 'city', 'state', 'postal_code',
'latitude', 'longitude', 'stars', 'review_count_x', 'is_open',
'attributes', 'categories', 'hours', 'average_rating',
'review_count_y'],
dtype='object')
review_count 列被重命名为 review_count_x 和 review_count_y。这通常是因为在合并过程中,两个 DataFrame 中都存在 review_count 列。为了继续进行需要选择合适的列来作为评论数量的依据。选择 review_count_x 或 review_count_y: 通常,review_count_x 是从 businesses DataFrame 中来的,而 review_count_y 是从 business_reviews DataFrame 中来的。
代码修改下
import torch
import pandas as pd
import numpy as np
import torch.nn.functional as F
from torch_geometric.data import Data
from torch_geometric.nn import GCNConv
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split# 1. 数据加载
def load_data():businesses = pd.read_json('yelp_academic_dataset_business.json', lines=True)reviews = pd.read_json('yelp_academic_dataset_review.json', lines=True)users = pd.read_json('yelp_academic_dataset_user.json', lines=True)return businesses, reviews, users# 2. 数据预处理
def preprocess_data(businesses, reviews):# 聚合评论数据business_reviews = reviews.groupby('business_id').agg({'stars': ['mean', 'count'],'useful': 'sum','funny': 'sum','cool': 'sum'}).reset_index()# 修复列名business_reviews.columns = ['business_id', 'average_rating', 'review_count','total_useful', 'total_funny', 'total_cool']# 合并商家信息# 删除businesses中的review_count列(如果存在)if 'review_count' in businesses.columns:businesses = businesses.drop('review_count', axis=1)# 合并商家信息merged_data = businesses.merge(business_reviews, on='business_id', how='left')# 填充缺失值merged_data = merged_data.fillna(0)return merged_data# 3. 特征工程
def engineer_features(merged_data):# 确保使用正确的列名创建特征merged_data['engagement_score'] = (merged_data['total_useful'] +merged_data['total_funny'] +merged_data['total_cool']) / (merged_data['review_count'] + 1) # 加1避免除零# 定义热门商家merged_data['is_popular'] = ((merged_data['average_rating'] >= 4.0) &(merged_data['review_count'] >= merged_data['review_count'].quantile(0.75))).astype(int)return merged_data# 4. 图构建
def build_graph(merged_data, reviews):# 创建节点映射business_ids = merged_data['business_id'].unique()user_ids = reviews['user_id'].unique()# 修改索引映射,确保从0开始node_mapping = {user_id: i for i, user_id in enumerate(user_ids)}# 商家节点的索引接续用户节点的索引business_start_idx = len(user_ids)node_mapping.update({business_id: i + business_start_idx for i, business_id in enumerate(business_ids)})# 获取节点总数total_nodes = len(user_ids) + len(business_ids)# 创建边edges = []for _, row in reviews.iterrows():if row['user_id'] in node_mapping and row['business_id'] in node_mapping:edges.append([node_mapping[row['user_id']], node_mapping[row['business_id']]])edge_index = torch.tensor(edges, dtype=torch.long).t().contiguous()return node_mapping, edge_index, total_nodesdef prepare_node_features(merged_data, node_mapping, num_user_nodes, total_nodes):feature_cols = ['average_rating', 'review_count', 'engagement_score']# 确保所有特征列都是数值类型for col in feature_cols:merged_data[col] = merged_data[col].astype(float)# 标准化特征scaler = StandardScaler()merged_data[feature_cols] = scaler.fit_transform(merged_data[feature_cols])# 创建特征矩阵,使用总节点数num_features = len(feature_cols)x = torch.zeros(total_nodes, num_features, dtype=torch.float)# 用户节点特征(使用平均值)mean_values = merged_data[feature_cols].mean().values.astype(np.float32)x[:num_user_nodes] = torch.tensor(mean_values, dtype=torch.float)# 商家节点特征for _, row in merged_data.iterrows():if row['business_id'] in node_mapping:idx = node_mapping[row['business_id']]feature_values = row[feature_cols].values.astype(np.float32)if not np.isfinite(feature_values).all():print(f"警告: 发现无效值 {feature_values}")feature_values = np.nan_to_num(feature_values, 0)x[idx] = torch.tensor(feature_values, dtype=torch.float)return xdef main():print("Starting the program...")# 设置设备device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')print(f"Using device: {device}")# 加载数据print("Loading data...")businesses, reviews, users = load_data()# 预处理数据print("Preprocessing data...")merged_data = preprocess_data(businesses, reviews)merged_data = engineer_features(merged_data)# 构建图print("Building graph...")node_mapping, edge_index, total_nodes = build_graph(merged_data, reviews)num_user_nodes = len(reviews['user_id'].unique())# 打印节点信息print(f"Total nodes: {total_nodes}")print(f"User nodes: {num_user_nodes}")print(f"Business nodes: {total_nodes - num_user_nodes}")print(f"Max node index in mapping: {max(node_mapping.values())}")# 准备特征print("Preparing node features...")x = prepare_node_features(merged_data, node_mapping, num_user_nodes, total_nodes)# 准备标签print("Preparing labels...")labels = torch.zeros(total_nodes)business_mask = torch.zeros(total_nodes, dtype=torch.bool)for _, row in merged_data.iterrows():if row['business_id'] in node_mapping:idx = node_mapping[row['business_id']]labels[idx] = row['is_popular']business_mask[idx] = True# 创建图数据对象data = Data(x=x, edge_index=edge_index)# 初始化模型print("Initializing model...")model = GNNModel(num_node_features=x.size(1)).to(device)# 训练模型print("Training model...")train_model(model, data, labels, business_mask, device)# 预测print("Making predictions...")model.eval()with torch.no_grad():predictions = torch.sigmoid(model(data.x.to(device), data.edge_index.to(device))).cpu()# 将预测结果添加到数据框merged_data['predicted_popularity'] = 0.0for _, row in merged_data.iterrows():if row['business_id'] in node_mapping:idx = node_mapping[row['business_id']]merged_data.loc[row.name, 'predicted_popularity'] = predictions[idx].item()# 输出潜在热门商家potential_hot = merged_data[(merged_data['predicted_popularity'] > 0.5) &(merged_data['is_popular'] == 0)].sort_values('predicted_popularity', ascending=False)print("\nPotential Hot Businesses:")print(potential_hot[['name', 'average_rating', 'review_count', 'predicted_popularity']].head())# 6. GNN模型定义
class GNNModel(torch.nn.Module):def __init__(self, num_node_features):super(GNNModel, self).__init__()self.conv1 = GCNConv(num_node_features, 64)self.conv2 = GCNConv(64, 32)self.conv3 = GCNConv(32, 16)self.fc = torch.nn.Linear(16, 1)self.dropout = torch.nn.Dropout(0.3)def forward(self, x, edge_index):x = F.relu(self.conv1(x, edge_index))x = self.dropout(x)x = F.relu(self.conv2(x, edge_index))x = self.dropout(x)x = F.relu(self.conv3(x, edge_index))x = self.fc(x)return x# 7. 训练函数
def train_model(model, data, labels, business_mask, device, epochs=100):optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)criterion = torch.nn.BCEWithLogitsLoss()model.train()for epoch in range(epochs):optimizer.zero_grad()out = model(data.x.to(device), data.edge_index.to(device))loss = criterion(out[business_mask], labels[business_mask].unsqueeze(1).to(device))loss.backward()optimizer.step()print(f'Epoch [{epoch + 1}/{epochs}], Loss: {loss.item():.4f}')if __name__ == "__main__":main()开始正式训练,先按照epoch=100做迭代训练测试,loss向收敛方向滑动

识别出热门店铺
Potential Hot Businesses:
name average_rating review_count predicted_popularity
100024 Mother's Restaurant -0.154731 41.821089 0.999941
31033 Royal House 0.207003 40.953749 0.999933
113983 Pat's King of Steaks -0.361171 34.103369 0.999805
64541 Felix's Restaurant & Oyster Bar 0.389155 32.023360 0.999725
42331 Gumbo Shop 0.340872 31.517411 0.999701











![[笔记] Centos7 安装 Docker 和 Docker Compose 及 Docker 命令大全](https://i-blog.csdnimg.cn/direct/a2056f1cc67645c691741f33e56f434d.png)