win10下github libiec61850库编译调试sntp_example
libiec61850
https://github.com/mz-automation/libiec61850
v1.6
简介
libiec61850 是一个开源(GPLv3)的 IEC 61850 客户端和服务器库实现,支持 MMS、GOOSE 和 SV 协议。它使用 C 语言(根据 C99 标准)实现,以提供最大的可移植性。它可以用于在运行 Linux、Windows 和 MacOS 的嵌入式系统和 PC 上实现符合 IEC 61850 的客户端和服务器应用程序。包含一组简单的示例应用程序,可以作为实现自己的 IEC 61850 兼容设备或与 IEC 61850 设备通信的起点。该库已在许多商业软件产品和设备中得到成功应用。
第三方库
各第三方库的设置参见libiec61850-1.6\third_party下各说明文件
mbedtls-3.6.0
https://github.com/Mbed-TLS/mbedtls
优先使用mbedtls-3.6.0
Mbed TLS 是一个实现加密原语、X.509 证书操作以及 SSL/TLS 和 DTLS 协议的 C 库。
其小巧的代码体积使其适用于嵌入式系统。
sqlite
与写sqlite日志有关
https://sqlite.org/2025/sqlite-amalgamation-3490100.zip
winpcap 与win下运行有关,必须安装WinPcap_4_1_3.exe并重启
https://www.winpcap.org/install/bin/WinPcap_4_1_3.exe
https://www.winpcap.org/install/bin/WpdPack_4_1_2.zip
doxygen
https://www.doxygen.nl/
https://www.doxygen.nl/files/doxygen-1.13.2-setup.exe
linux下编译
linux make编译:
make examples
生成
libiec61850.a
运行测试
cd examples/server_example_basic_io
sudo ./server_example_basic_io
客户端对应程序 iec61850_client_example1
make install //默认安装到.install
make INSTALL_PREFIX=/usr/local install //指定安装目录
安装目标将 API 头文件和静态库复制到单个目录中,
用于头文件(INSTALL_PREFIX/include)
和静态库(INSTALL_PREFIX/lib)。
linux cmake编译:
mkdir build
cd build
cmake …
make
sudo make install
win10下cmake vs编译
cd C:\work\code\iec61850\libiec61850-1.6\winbuild
cmake -G “Visual Studio 17 2022” … -A x64
用vs2022打开winbuild下的sln文件
子工程介绍
hal
作用:libiec61850 的硬件抽象层(Hardware Abstraction Layer)子项目。
该模块封装了与操作系统相关的功能(如线程、套接字、定时器等),
使核心库可以跨平台运行。
在 Windows 下,hal 可能实现为:
基于 Win32 API 的线程和网络接口。
替换 POSIX 兼容层(如 socket() 的 Windows 版本)。
生成路径:libiec61850-1.6\winbuild\hal\Debug
iec61850
核心的静态库
生成路径:libiec61850-1.6\winbuild\src\Debug
doc doc-net
与Doxygen有关,生成路径 libiec61850-1.6\winbuild\doxydoc
ZERO_CHECK
作用:CMake 自动生成的“配置检查”项目。
每次构建时,ZERO_CHECK 会先运行,检查 CMakeLists.txt 或相关文件是否有变更。
如果有变更(如修改了编译选项、添加/删除了源文件),
它会自动重新生成 VS2022 的工程文件(.vcxproj 等)。
ALL_BUILD
作用:CMake 默认生成的“构建所有目标”项目。
RUN_TESTS
作用:运行项目的单元测试(如果项目配置了测试)。
PACKAGE
作用:生成分发包(如 ZIP、NSIS 安装包等)。
典型输出:libiec61850-1.6-win64.zip 或安装程序。
INSTALL
作用:将编译好的文件安装到指定目录(类似 make install)。
r_goose_publisher_example
工程以r_开头的几个sv goose示例程序与mbedtls tls加密库有关
libiec61850-1.6\winbuild\config\stack_config.h 中有提示
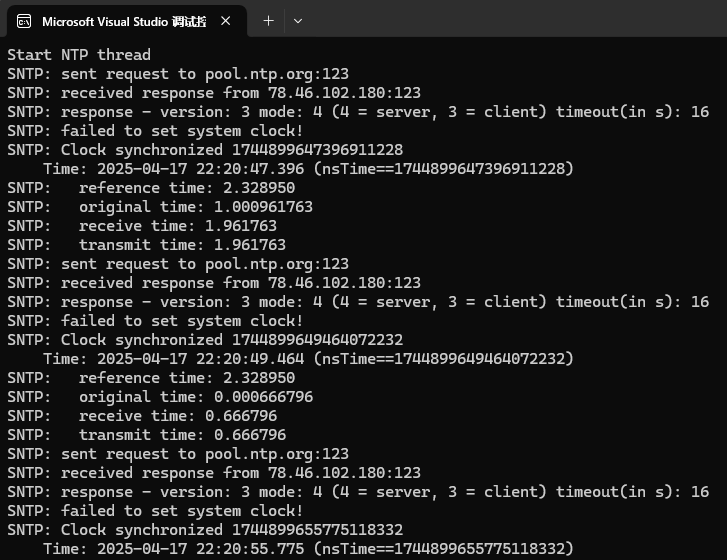
sntp_example
SNTP(简单网络时间协议)是 NTP(Network Time Protocol) 的简化版本,用于在计算机网络中同步设备的系统时间。
轻量级:相比完整的 NTP,SNTP 实现更简单,适合嵌入式系统或轻量级应用。
基于 UDP:默认使用 UDP 端口 123 进行通信。
时间同步:从 SNTP/NTP 服务器获取精确的时间戳(通常来自原子钟或 GPS 时间源)。
sntp_example源码debug
sntp_client.c 代码修改
libiec61850-1.6\src\sntp\sntp_client.c
parseResponseMessage中修改如下
if (self->userCallback){if (self->userCallbackParameter) {//add*((uint64_t*)self->userCallbackParameter) = trnsTime + self->lastRequestTimestamp;}self->userCallback(self->userCallbackParameter, true);}
sntp_example.c 代码修改
libiec61850-1.6\examples\sntp_example\sntp_example.c
#include "sntp_client.h"
#include "hal_thread.h"
#include <signal.h>
#include <stdio.h>
#include <time.h>
#include <windows.h>static bool running = true;
static uint64_t g_nsTime = 0;#ifdef _WINDOWS
static BOOL WINAPI sigint_handler(DWORD signal) {if (signal == CTRL_C_EVENT) {printf("Ctrl+C received, exiting ...\n");running = false;return TRUE; // 表示已处理该事件}return FALSE;
}
#else
void sigint_handler(int signalId) {running = false;
}
#endif // _WINDOWSvoid show_time(nsSinceEpoch nsTime) {// 转换为 Windows FILETIME (1601-01-01 为起点,100ns 单位)uint64_t t = (nsTime / 100ULL) + 116444736000000000ULL;FILETIME ft;ft.dwLowDateTime = (uint32_t)(t & 0xffffffff);ft.dwHighDateTime = (uint32_t)(t >> 32);SYSTEMTIME st;// 转换为 SYSTEMTIME (便于读取年月日时分秒)FileTimeToSystemTime(&ft, &st);SYSTEMTIME localSt;// 转换为本地时间SystemTimeToTzSpecificLocalTime(NULL, &st, &localSt);printf(" Time: %04d-%02d-%02d %02d:%02d:%02d.%03d (nsTime==%llu)\n",localSt.wYear, localSt.wMonth, localSt.wDay,localSt.wHour, localSt.wMinute, localSt.wSecond,localSt.wMilliseconds, nsTime);fflush(stdout);
}static void sntpUserCallback(void* parameter, bool isSynced) {if (isSynced) {printf("SNTP: Clock synchronized %llu\n", *(uint64_t*)parameter);show_time(g_nsTime);}else {printf("SNTP: Clock not synchronized\n");}
}int main(int argc, char** argv) {SNTPClient client = SNTPClient_create();SNTPClient_addServer(client, "pool.ntp.org", 123);//"192.168.178.74"SNTPClient_setUserCallback(client, sntpUserCallback, (void*)&g_nsTime);SNTPClient_setPollInterval(client, 16);SNTPClient_start(client);
#ifdef _WINDOWSif (!SetConsoleCtrlHandler(sigint_handler, TRUE)) {printf("Error: Failed to set Ctrl+C handler!\n");}
#elsesignal(SIGINT, sigint_handler);
#endif // _WINDOWSwhile (running) {Thread_sleep(100);}SNTPClient_destroy(client);getchar();return 0;
}
SNTP: Failed to bind to port 123 问题处理
查询123端口被占用问题
libiec61850-1.6\winbuild>netstat -ano | findstr “:123”
UDP 0.0.0.0:123 : 1852
UDP [::]:123 : 1852
libiec61850-1.6\winbuild>tasklist | findstr “1852”
svchost.exe 1852 Services 0 7,204 K
svchost.exe,通常是 w32time 服务。
停用w32time
net stop w32time
sc config w32time start= disabled
恢复w32time
sc config w32time start= auto
net start w32time
运行效果