7、langChain和RAG实战:基于LangChain和RAG的常用案例实战
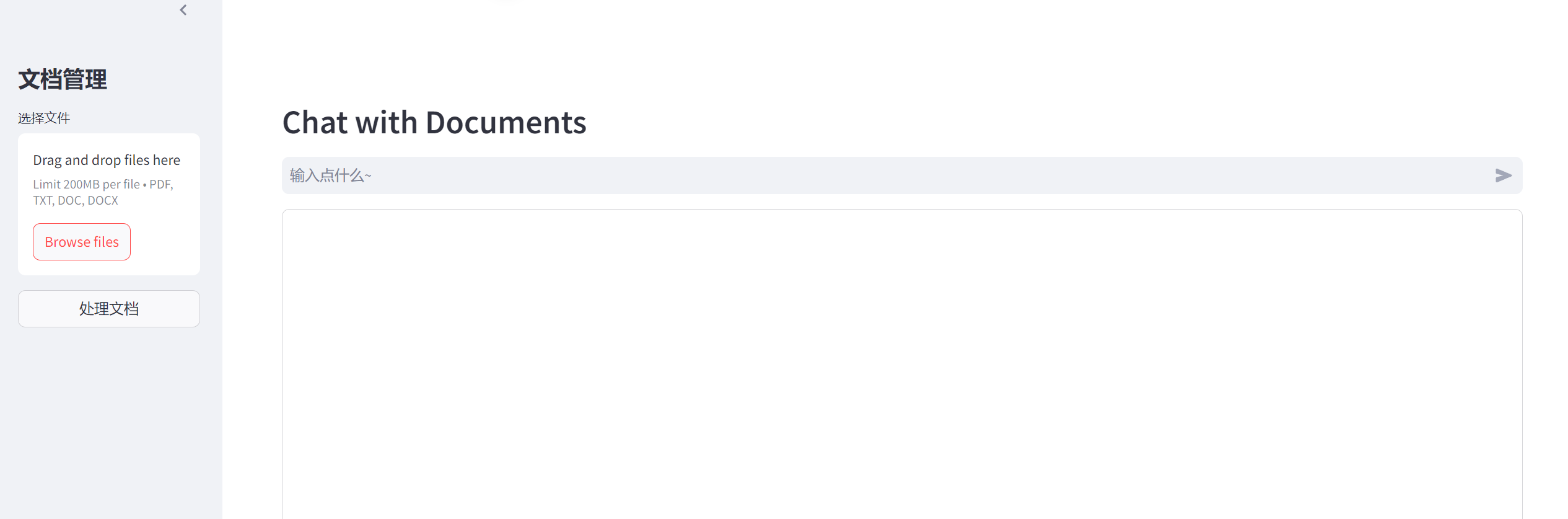
PDF 文档问答ChatBot
本地上传文档
- 支持 pdf
- 支持 txt
- 支持 doc/docx
问答页面
python环境
- 新建一个
requirements.txt文件
streamlit
python-docx
PyPDF2
faiss-cpu
langchain
langchain-core
langchain-community
langchain-openai
- 然后安装相应的包
pip install -r requirements.txt -U
代码
创建一个 pdf_search.py 文件, 把下边的复制进去
注意:配置好OPEN_API 接口地址和密钥的环境变量
#示例:pdf_search.py
# 导入Streamlit库,用于创建Web应用
import streamlit as st
# 导入递归字符文本分割器,用于将文档分割成小块
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 导入FAISS向量存储,用于存储和检索文档嵌入
from langchain_community.vectorstores import FAISS
# 导入OpenAI聊天模型
from langchain_openai import ChatOpenAI
# 导入OpenAI嵌入模型,用于生成文本嵌入
from langchain_openai import OpenAIEmbeddings
# 导入Document类,用于封装文档内容和元数据
from langchain_core.documents import Document
# 导入对话检索链,用于处理对话和检索
from langchain.chains import ConversationalRetrievalChain
# 导入docx库,用于处理Word文档
import docx
# 导入PyPDF2库,用于处理PDF文档
from PyPDF2 import PdfReader# 设置页面配置,包括标题、图标和布局
st.set_page_config(page_title="文档问答", page_icon=":robot:", layout="wide")# 设置页面的CSS样式
st.markdown("""<style>
.chat-message {padding: 1.5rem; border-radius: 0.5rem; margin-bottom: 1rem; display: flex
}
.chat-message.user {background-color: #2b313e
}
.chat-message.bot {background-color: #475063
}
.chat-message .avatar {width: 20%;
}
.chat-message .avatar img {max-width: 78px;max-height: 78px;border-radius: 50%;object-fit: cover;
}
.chat-message .message {width: 80%;padding: 0 1.5rem;color: #fff;
}
.stDeployButton {visibility: hidden;}
#MainMenu {visibility: hidden;}
footer {visibility: hidden;}.block-container {padding: 2rem 4rem 2rem 4rem;
}.st-emotion-cache-16txtl3 {padding: 3rem 1.5rem;
}
</style>
# """,unsafe_allow_html=True,
)# 定义机器人消息模板
bot_template = """
<div class="chat-message bot"><div class="avatar"><img src="https://cdn.icon-icons.com/icons2/1371/PNG/512/robot02_90810.png" style="max-height: 78px; max-width: 78px; border-radius: 50%; object-fit: cover;"></div><div class="message">{{MSG}}</div>
</div>
"""# 定义用户消息模板
user_template = """
<div class="chat-message user"><div class="avatar"><img src="https://www.shareicon.net/data/512x512/2015/09/18/103160_man_512x512.png" ></div> <div class="message">{{MSG}}</div>
</div>
"""# 从PDF文件中提取文本
def get_pdf_text(pdf_docs):# 存储提取的文档docs = []for document in pdf_docs:if document.type == "application/pdf":# 读取PDF文件pdf_reader = PdfReader(document)for idx, page in enumerate(pdf_reader.pages):docs.append(Document(# 提取页面文本page_content=page.extract_text(),# 添加元数据metadata={"source": f"{document.name} on page {idx}"},))elif document.type == "application/vnd.openxmlformats-officedocument.wordprocessingml.document":# 读取Word文档doc = docx.Document(document)for idx, paragraph in enumerate(doc.paragraphs):docs.append(Document(# 提取段落文本page_content=paragraph.text,# 添加元数据metadata={"source": f"{document.name} in paragraph {idx}"},))elif document.type == "text/plain":# 读取纯文本文件text = document.getvalue().decode("utf-8")docs.append(Document(page_content=text, metadata={"source": document.name}))return docs# 将文档分割成小块文本
def get_text_chunks(docs):# 创建文本分割器text_splitter = RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=0)# 分割文档docs_chunks = text_splitter.split_documents(docs)return docs_chunks# 创建向量存储
def get_vectorstore(docs_chunks):# 创建OpenAI嵌入模型embeddings = OpenAIEmbeddings()# 创建FAISS向量存储vectorstore = FAISS.from_documents(docs_chunks, embedding=embeddings)return vectorstore# 创建对话检索链
def get_conversation_chain(vectorstore):# 创建OpenAI聊天模型llm = ChatOpenAI(model="gpt-4o")conversation_chain = ConversationalRetrievalChain.from_llm(llm=llm,# 使用向量存储作为检索器retriever=vectorstore.as_retriever(),# 返回源文档return_source_documents=True,)return conversation_chain