【学习笔记】机器学习(Machine Learning) | 第六周|过拟合问题
机器学习(Machine Learning)
简要声明
基于吴恩达教授(Andrew Ng)课程视频
BiliBili课程资源
文章目录
- 机器学习(Machine Learning)
- 简要声明
- 摘要
- 过拟合与欠拟合问题
- 一、回归问题中的过拟合
- 1. 欠拟合(Underfit)
- 2. 刚好拟合(Just right)
- 3. 过拟合(Overfit)
- 二、分类问题中的过拟合
- 1. 欠拟合(Underfit)
- 2. 刚好拟合(Just right)
- 3. 过拟合(Overfit)
- 三、过拟合的原因及解决方法
- 过拟合原因
- 解决方法
- 解决过拟合问题
- 一、收集更多训练数据
- 二、选择特征
- 三、正则化
- 四、过拟合解决方法总结
- 正则化的应用
- 一、带正则化的代价函数
- 二、正则化线性回归
- 三、正则化逻辑回归
- 四、正则化参数的选择
- 五、正则化方法对比
摘要
本文介绍了机器学习中的过拟合和欠拟合问题,通过回归和分类问题展示了不同拟合程度的表现。针对过拟合问题,提出了增加训练数据、特征选择、正则化等解决方法,并讨论了正则化在线性回归和逻辑回归中的应用,包括带正则化的代价函数和梯度下降更新规则。最后,对比了正则化方法的优缺点,强调合理应用正则化技术对提高模型泛化能力的重要性。
过拟合与欠拟合问题
在机器学习中,过拟合是一个常见的问题,它导致模型在训练数据上表现很好,但在新的、未见过的数据上表现不佳。以下是对过拟合问题的详细探讨。
一、回归问题中的过拟合
考虑一个简单的回归问题,尝试用不同复杂度的模型来拟合数据。
1. 欠拟合(Underfit)
- 模型表达式: y = w 1 x + b y = w_1x + b y=w1x+b
- 特征:仅使用输入变量的一次项。
- 表现:模型无法很好地拟合训练数据,存在高偏差(high bias)。
2. 刚好拟合(Just right)
- 模型表达式: y = w 1 x + w 2 x 2 + b y = w_1x + w_2x^2 + b y=w1x+w2x2+b
- 特征:使用输入变量的一次项和二次项。
- 表现:模型很好地拟合了训练数据,具有良好的泛化能力(generalization)。
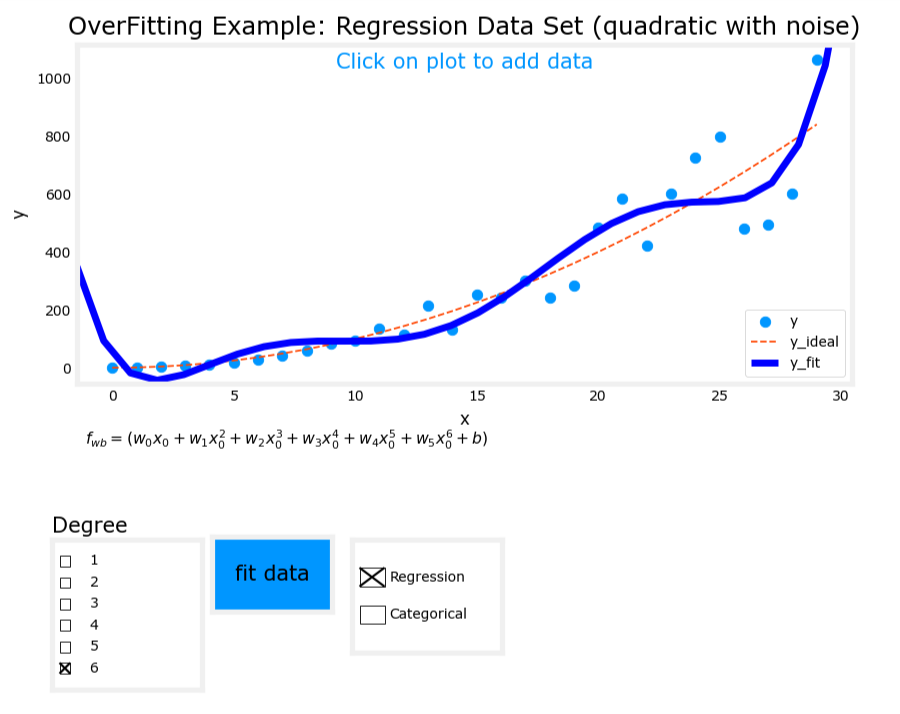
3. 过拟合(Overfit)
- 模型表达式: y = w 1 x + w 2 x 2 + w 3 x 3 + w 4 x 4 + b y = w_1x + w_2x^2 + w_3x^3 + w_4x^4 + b y=w1x+w2x2+w3x3+w4x4+b
- 特征:使用了过多的高次项。
- 表现:模型在训练数据上拟合得非常好,但存在高方差(high variance),泛化能力差。
图像对比
欠拟合
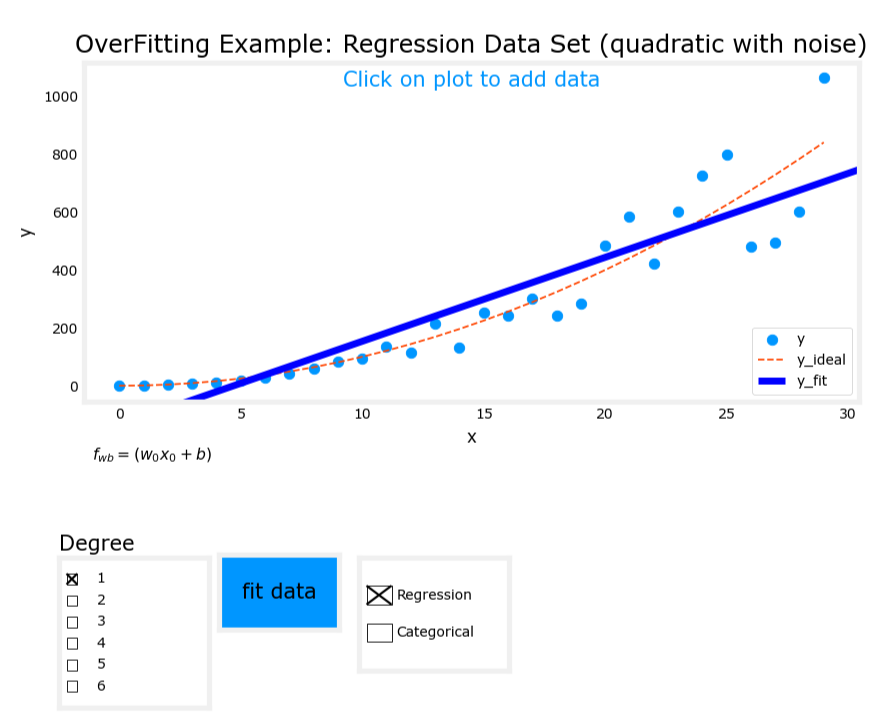
刚好拟合
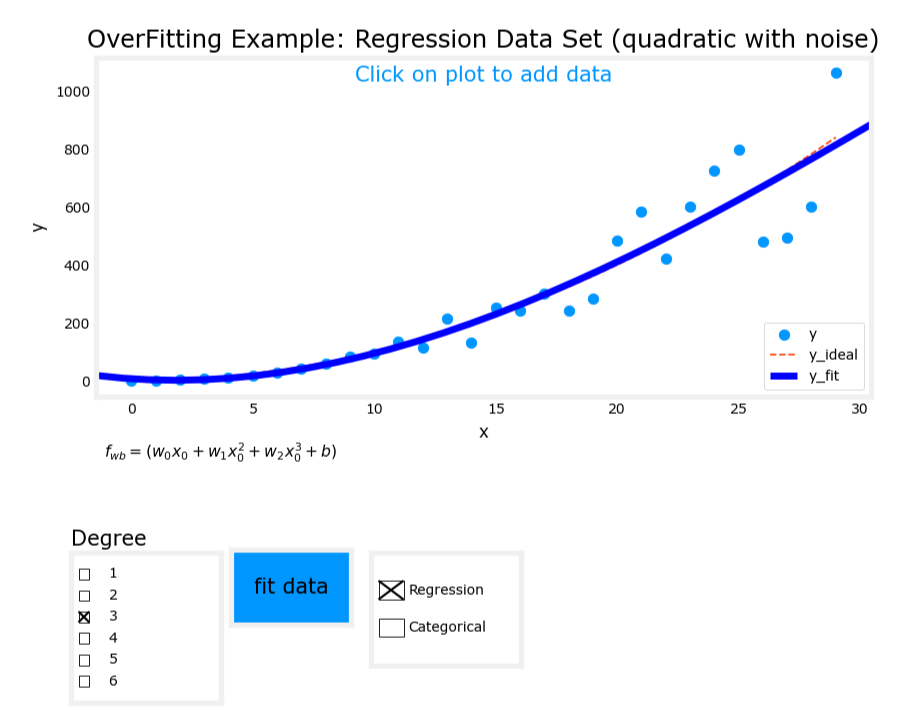
过拟合
二、分类问题中的过拟合
在分类问题中,过拟合问题同样存在。
1. 欠拟合(Underfit)
- 模型表达式: z = w 1 x 1 + w 2 x 2 + b z = w_1x_1 + w_2x_2 + b z=w1x1+w2x2+b, f w , b ( x ) = g ( z ) f_{\mathbf{w},b}(\mathbf{x}) = g(z) fw,b(x)=g(z),其中(g)是Sigmoid函数。
- 特征:仅使用线性特征。
- 表现:模型无法很好地划分数据,存在高偏差(high bias)。
2. 刚好拟合(Just right)
- 模型表达式: z = w 1 x 1 + w 2 x 2 + w 3 x 1 2 + w 4 x 2 2 + w 5 x 1 x 2 + b z = w_1x_1 + w_2x_2 + w_3x_1^2 + w_4x_2^2 + w_5x_1x_2 + b z=w1x1+w2x2+w3x12+w4x22+w5x1x2+b, f w , b ( x ) = g ( z ) f_{\mathbf{w},b}(\mathbf{x}) = g(z) fw,b(x)=g(z)。
- 特征:使用二次项特征。
- 表现:模型能够很好地划分不同类别的数据。
3. 过拟合(Overfit)
- 模型表达式: z = w 1 x 1 + w 2 x 2 + w 3 x 1 2 + w 4 x 2 2 + w 5 x 1 3 x 2 + w 6 x 1 3 x 2 2 + ⋯ + b z = w_1x_1 + w_2x_2 + w_3x_1^2 + w_4x_2^2 + w_5x_1^3x_2 + w_6x_1^3x_2^2 + \cdots + b z=w1x1+w2x2+w3x12+w4x22+w5x13x2+w6x13x22+⋯+b, f w , b ( x ) = g ( z ) f_{\mathbf{w},b}(\mathbf{x}) = g(z) fw,b(x)=g(z)。
- 特征:使用了过多的高次交叉项。
- 表现:模型在训练数据上表现完美,但在新数据上表现不佳,存在高方差(high variance)。
图像对比
欠拟合
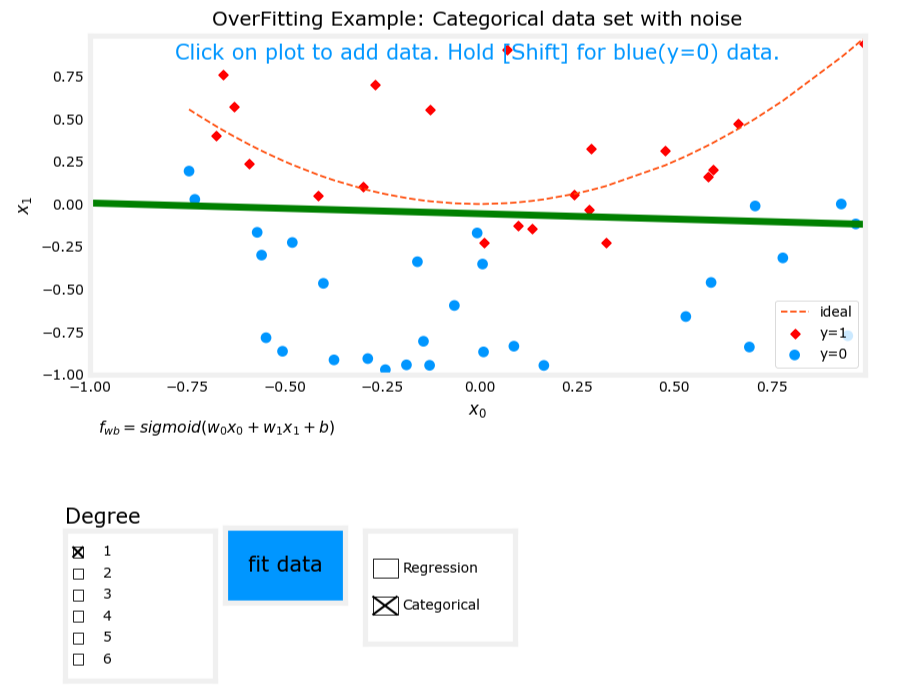
刚好拟合
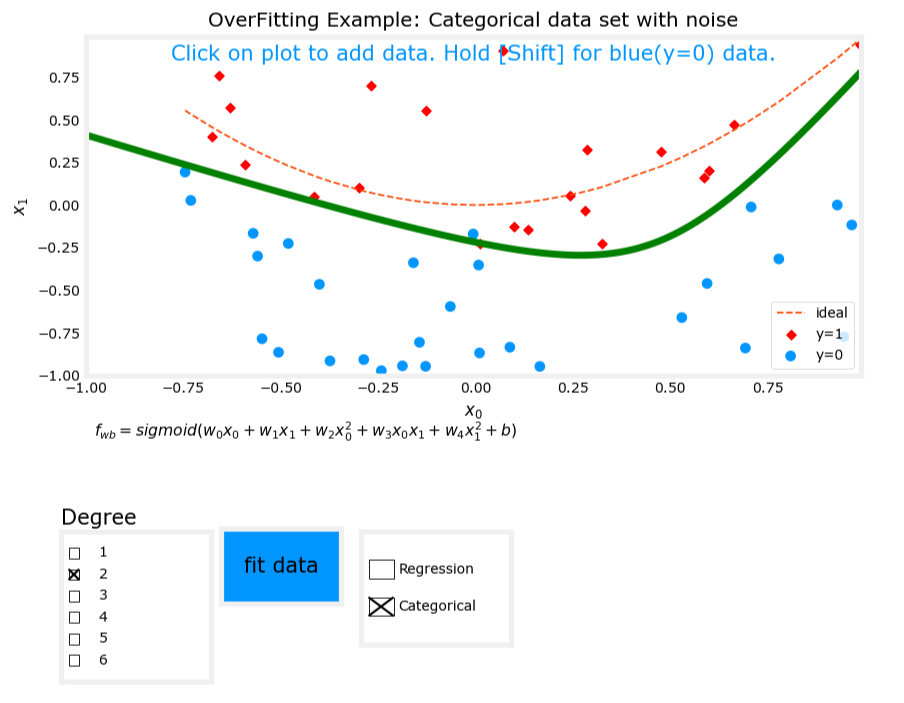
过拟合
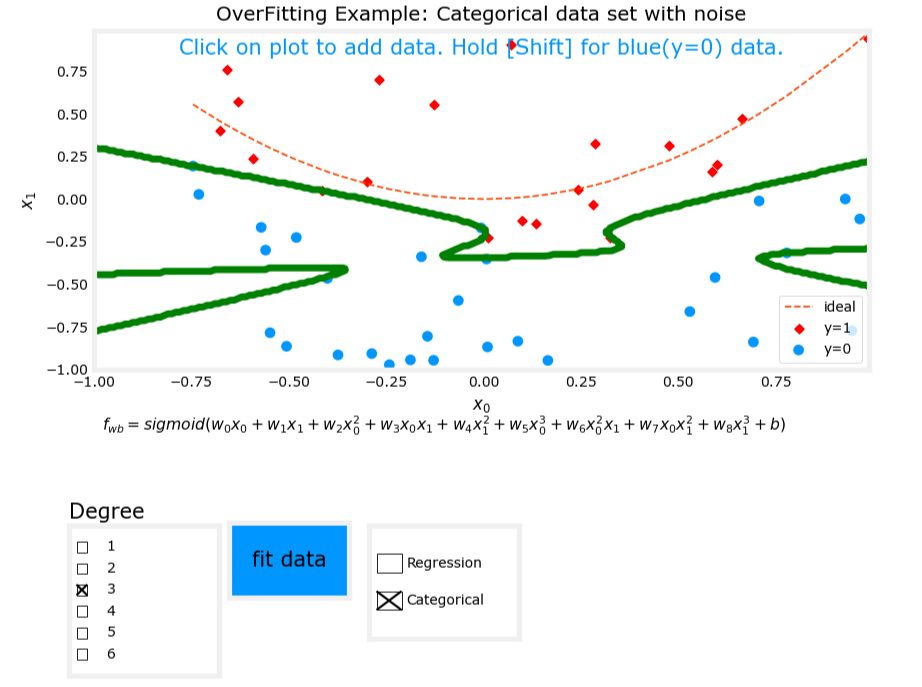
三、过拟合的原因及解决方法
过拟合原因
- 模型复杂度过高
- 训练数据量不足
- 特征过多或噪声特征
解决方法
| 方法 | 说明 |
|---|---|
| 增加训练数据 | 更多样化的数据有助于模型学习到更通用的模式。 |
| 减少特征数量 | 通过特征选择或降维技术减少输入特征的数量。 |
| 正则化 | 通过在损失函数中添加正则化项(如L1或L2正则化)来限制模型复杂度。 |
| 交叉验证 | 使用交叉验证技术评估模型在不同数据集上的表现,避免过拟合。 |
| 早停 | 在训练过程中,当验证集性能不再提升时提前停止训练。 |
解决过拟合问题
一、收集更多训练数据
增加训练数据量是解决过拟合的一种有效方法。更多的数据可以帮助模型学习到更通用的模式,减少过拟合的风险。
- 原理:更多的训练样本可以提供更全面的信息,使模型更好地泛化。
- 示例:如果模型在有限的房屋价格数据上过拟合,增加更多不同大小、价格的房屋数据可以使模型更准确地预测新数据。
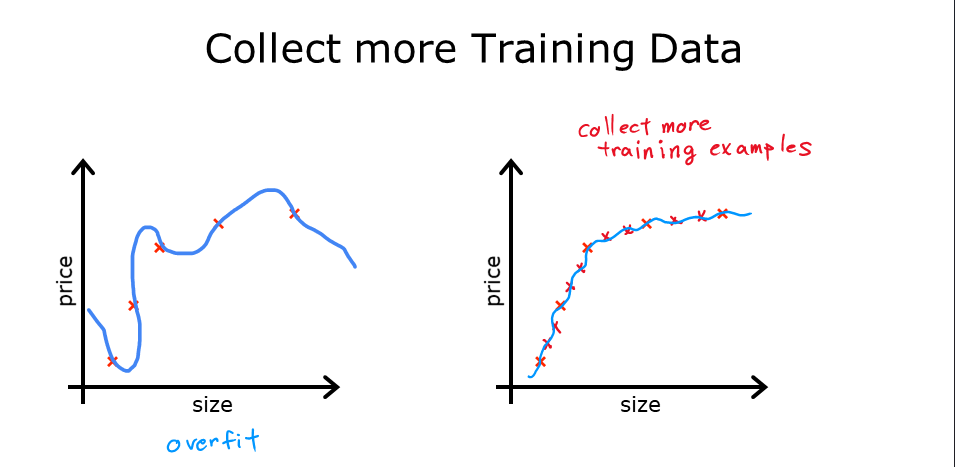
二、选择特征
选择合适的特征可以减少模型的复杂度,从而降低过拟合的可能性。
- 特征选择:从众多特征中选择最相关的特征,去除无关或冗余的特征。
- 优点:减少模型复杂度,提高训练速度。
- 缺点:可能丢失一些有用的信息。
| 特征选择方法 | 说明 |
|---|---|
| Filter Methods | 通过相关性分析等方法预选特征 |
| Wrapper Methods | 通过模型性能评估选择特征组合 |
| Embedded Methods | 在模型训练过程中自动选择特征 |
三、正则化
正则化是一种通过在损失函数中添加惩罚项来限制模型复杂度的方法。
- L1正则化:添加参数的绝对值之和。公式为: λ ∑ j = 1 n ∣ w j ∣ \lambda \sum_{j=1}^{n} |w_j| λj=1∑n∣wj∣
- L2正则化:添加参数的平方和。公式为: λ ∑ j = 1 n w j 2 \lambda \sum_{j=1}^{n} w_j^2 λj=1∑nwj2
- 作用:使参数值更小,减少模型对单个特征的依赖。
| 正则化方法 | 优点 | 缺点 |
|---|---|---|
| L1正则化 | 可进行特征选择,稀疏性好 | 收敛速度较慢 |
| L2正则化 | 收敛速度快,稳定性好 | 无法进行特征选择 |
四、过拟合解决方法总结
| 方法 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 收集更多数据 | 训练数据量不足时 | 提高模型泛化能力 | 数据收集成本高 |
| 特征选择 | 特征数量多且存在冗余特征时 | 减少模型复杂度,提高训练速度 | 可能丢失有用信息 |
| 正则化 | 模型参数量大,容易过拟合时 | 有效控制模型复杂度,提高泛化能力 | 需要调整正则化参数 |
| 交叉验证 | 数据集有限,需要充分利用数据进行模型评估时 | 减少数据浪费,提高模型评估准确性 | 计算成本高 |
| 早停 | 模型训练时间长,容易过拟合时 | 防止模型在训练集上过优化,保存较好的泛化能力 | 需要确定合适的停止点 |
正则化的应用
一、带正则化的代价函数
在带正则化的代价函数中,我们在原始代价函数的基础上添加了一个正则化项。对于线性回归模型,其带正则化的代价函数形式如下:
J ( w , b ) = 1 2 m ∑ i = 1 m ( f w , b ( x ( i ) ) − y ( i ) ) 2 + λ 2 m ∑ j = 1 n w j 2 J(\mathbf{w}, b) = \frac{1}{2m} \sum_{i=1}^{m} \left( f_{\mathbf{w},b}(\mathbf{x}^{(i)}) - y^{(i)} \right)^2 + \frac{\lambda}{2m} \sum_{j=1}^{n} w_j^2 J(w,b)=2m1i=1∑m(fw,b(x(i))−y(i))2+2mλj=1∑nwj2
其中:
- m m m是训练样本的数量
- n n n 是特征的数量
- λ \lambda λ 是正则化参数,用于控制正则化的强度
正则化项 λ 2 m ∑ j = 1 n w j 2 \frac{\lambda}{2m} \sum_{j=1}^{n} w_j^2 2mλ∑j=1nwj2 会惩罚过大的参数值,使模型更倾向于学习较小的参数,从而降低模型的复杂度。
二、正则化线性回归
在正则化线性回归中,我们通过梯度下降算法来最小化带正则化的代价函数。其梯度下降的更新规则如下:
w j = w j − α [ 1 m ∑ i = 1 m ( f w , b ( x ( i ) ) − y ( i ) ) x j ( i ) + λ m w j ] w_j = w_j - \alpha \left[ \frac{1}{m} \sum_{i=1}^{m} \left( f_{\mathbf{w},b}(\mathbf{x}^{(i)}) - y^{(i)} \right) x_j^{(i)} + \frac{\lambda}{m} w_j \right] wj=wj−α[m1i=1∑m(fw,b(x(i))−y(i))xj(i)+mλwj]
b = b − α 1 m ∑ i = 1 m ( f w , b ( x ( i ) ) − y ( i ) ) b = b - \alpha \frac{1}{m} \sum_{i=1}^{m} \left( f_{\mathbf{w},b}(\mathbf{x}^{(i)}) - y^{(i)} \right) b=b−αm1i=1∑m(fw,b(x(i))−y(i))
其中:
- α \alpha α是学习率
- w j w_j wj 是特征 ( j ) 的参数
- b b b是偏置项
在梯度下降过程中,正则化项会使得参数 w j w_j wj在每次更新时都乘以一个因子 ( 1 − α λ m ) (1 - \alpha \frac{\lambda}{m}) (1−αmλ),从而实现参数的“收缩”。
| 正则化线性回归与普通线性回归对比 | 正则化线性回归 | 普通线性回归 |
|---|---|---|
| 更新规则 | 包含正则化项 | 不包含正则化项 |
| 参数变化 | 参数逐渐收缩 | 参数无收缩 |
| 泛化能力 | 更强 | 较弱 |
三、正则化逻辑回归
正则化逻辑回归与正则化线性回归类似,其代价函数也包含一个正则化项。对于逻辑回归模型,其带正则化的代价函数形式如下:
J ( w , b ) = − 1 m ∑ i = 1 m [ y ( i ) log ( f w , b ( x ( i ) ) ) + ( 1 − y ( i ) ) log ( 1 − f w , b ( x ( i ) ) ) ] + λ 2 m ∑ j = 1 n w j 2 J(\mathbf{w}, b) = -\frac{1}{m} \sum_{i=1}^{m} \left[ y^{(i)} \log(f_{\mathbf{w},b}(\mathbf{x}^{(i)})) + (1 - y^{(i)}) \log(1 - f_{\mathbf{w},b}(\mathbf{x}^{(i)})) \right] + \frac{\lambda}{2m} \sum_{j=1}^{n} w_j^2 J(w,b)=−m1i=1∑m[y(i)log(fw,b(x(i)))+(1−y(i))log(1−fw,b(x(i)))]+2mλj=1∑nwj2
其中:
- ( f w , b ( x ( i ) ) ) ( f_{\mathbf{w},b}(\mathbf{x}^{(i)}) ) (fw,b(x(i))) 是逻辑回归模型的预测输出,使用Sigmoid函数计算得到
正则化逻辑回归的梯度下降更新规则与正则化线性回归类似,也是在原始梯度的基础上添加了正则化项。
四、正则化参数的选择
正则化参数 λ \lambda λ 的选择对模型的性能有重要影响:
- λ \lambda λ 过小:正则化效果不明显,模型可能仍然过拟合
- λ \lambda λ 过大:过度正则化,模型可能欠拟合
可以通过交叉验证的方法来选择合适的 λ \lambda λ 值。
五、正则化方法对比
| 正则化方法 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| L1正则化 | 特征稀疏 | 可进行特征选择 | 收敛速度较慢 |
| L2正则化 | 参数平滑 | 收敛速度快 | 无法进行特征选择 |
通过合理应用正则化技术,可以有效防止模型过拟合,提高模型的泛化能力和实际应用效果。
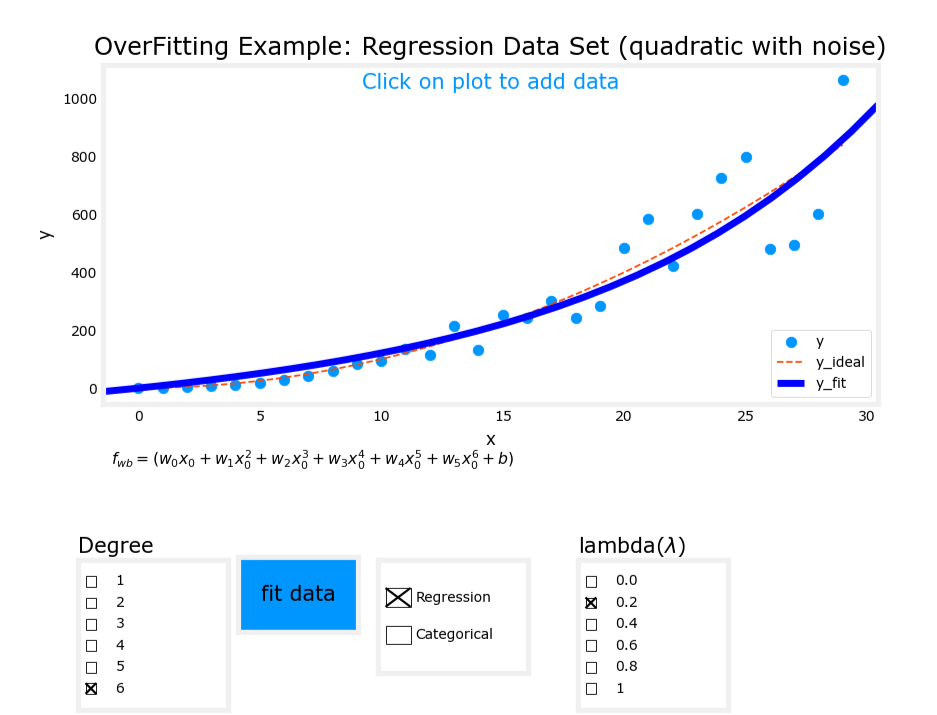
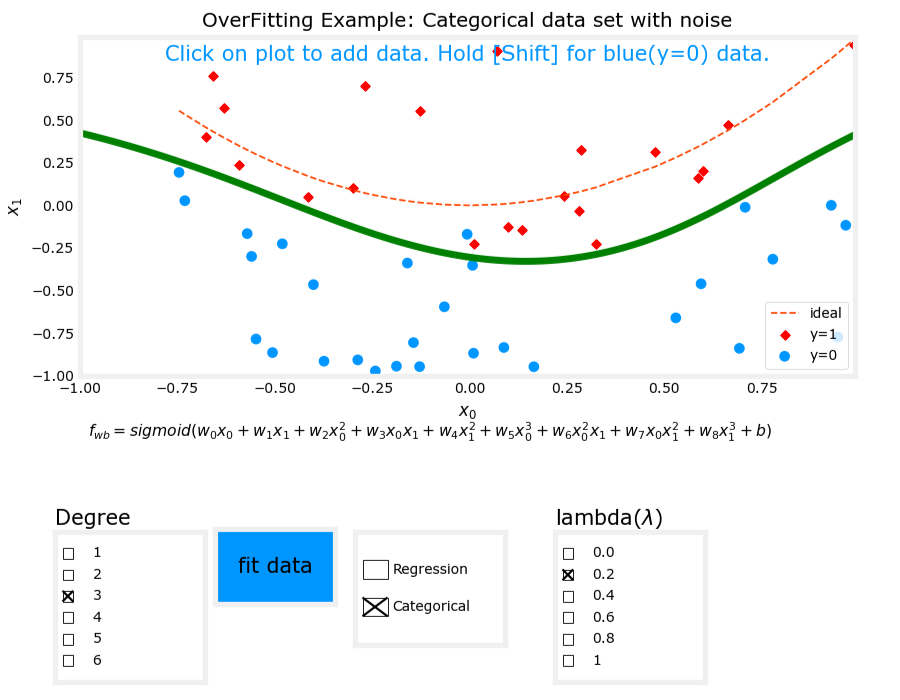
正则化后图像
线性回归
分类
end