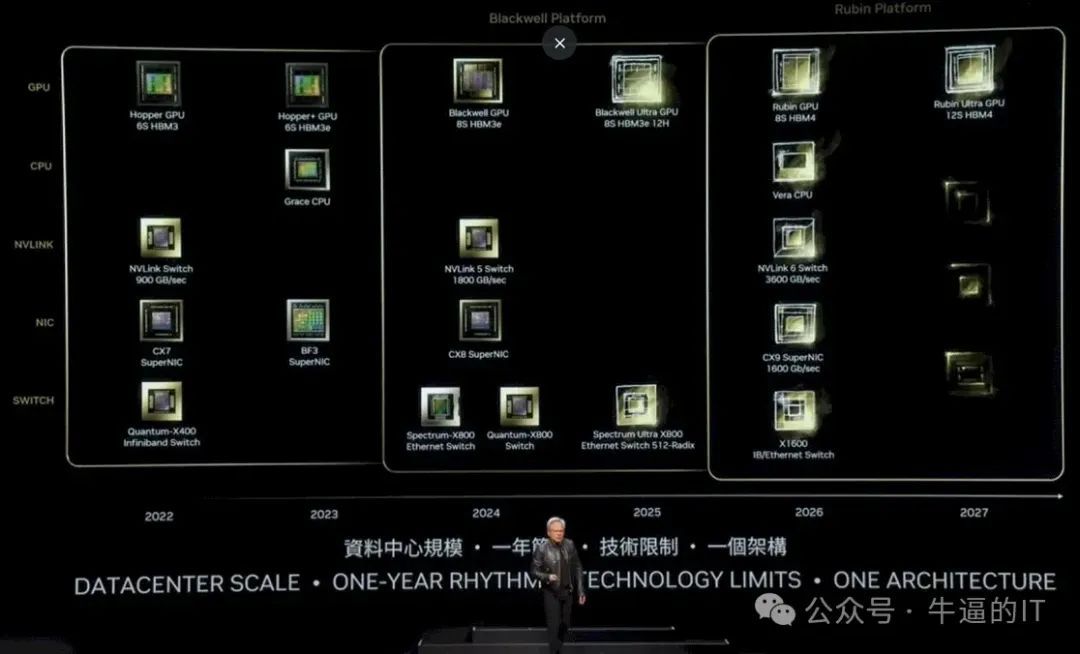
🌺系列文章推荐🌺
扩散模型系列文章正在持续的更新,更新节奏如下,先更新SD模型讲解,再更新相关的微调方法文章,敬请期待!!!(本文及其之前的文章均已更新)
SD模型原理:
- Stable Diffusion概要讲解
- Stable diffusion详细讲解
- Stable Diffusion的加噪和去噪详解
- Diffusion Model
- Stable Diffusion核心网络结构——VAE
- Stable Diffusion核心网络结构——CLIP Text Encoder
- Stable Diffusion核心网络结构——U-Net
- Stable Diffusion中U-Net的前世今生与核心知识
- SD模型性能测评
- Stable Diffusion经典应用场景
- SDXL的优化工作
微调方法原理:
- DreamBooth
- LoRA
- LORA及其变种介绍
- ControlNet
- ControlNet文章解读
- Textual Inversion 和 Embedding fine-tuning

Stable Diffusion核心网络结构
摘录来源:https://zhuanlan.zhihu.com/p/632809634
目录
Stable Diffusion核心网络结构
SD模型整体架构初识
U-Net模型
【1】U-Net的核心作用
【2】U-Net模型的完整结构图
(1)ResNetBlock模块
(2)CrossAttention模块
(3)BasicTransformer Block模块
(4)Spatial Transformer模块
(5)CrossAttnDownBlock/CrossAttnUpBlock/CrossAttnMidBlock模块
(6)Stable Diffusion U-Net整体宏观角度小结
【3】Stable Diffusion中U-Net的训练过程与损失函数
【4】SD模型融合详解(Merge Block Weighted,MBW)
SD模型整体架构初识
Stable Diffusion模型整体上是一个End-to-End模型,主要由VAE(变分自编码器,Variational Auto-Encoder),U-Net以及CLIP Text Encoder三个核心组件构成。
本文主要介绍U-Net,CLIP Text Encoder和VAE请参考:
- Stable Diffusion核心网络结构——VAE
- Stable Diffusion核心网络结构——CLIP Text Encoder
在FP16精度下Stable Diffusion模型大小2G(FP32:4G),其中U-Net大小1.6G,VAE模型大小160M以及CLIP Text Encoder模型大小235M(约123M参数)。其中U-Net结构包含约860M参数,FP32精度下大小为3.4G左右。

U-Net模型
【1】U-Net的核心作用
在Stable Diffusion中,U-Net模型是一个关键核心部分,能够预测噪声残差,并结合Sampling method(调度算法【这里其实不是调度算法,是采样算法】:DDPM、DDIM、DPM++等)【去噪】对输入的特征矩阵进行重构,逐步将其从随机高斯噪声转化成图片的Latent Feature。
【 “并结合Sampling method(调度算法:DDPM、DDIM、DPM++等)”这句话DDPM、DDIM、DPM++是Sampling method,不是调度算法。调度算法是线性调度、余弦调度等】
具体来说,在前向推理过程中【不是训练过程】,SD模型通过反复调用 U-Net,将预测出的噪声残差从原噪声矩阵中去除,得到逐步去噪后的图像Latent Feature,再通过VAE的Decoder结构将Latent Feature重建成像素级图像。
从噪声到图片的生成过程,其中就是U-Net在不断的为大家去除噪声的过程。
在扩散模型(如Stable Diffusion)中,首先需要明确采样方法和调度算法的区别和各自的作用:
1. 采样方法(Sampling Methods),去噪过程用于推断每一步如何从当前噪声生成下一步图像,解决去噪过程中的不确定性。如DDIM、DPM++等。加噪过程不需要采样算法,因为噪声注入是确定性的,按照调度器规则进行。
2. 调度算法(Schedule Methods),加噪过程中控制每个时间步向图像中注入的噪声比例,逐步将图像转化为纯噪声。去噪过程中控制每个时间步去除的噪声比例,确保噪声逐步减少,图像逐步恢复。如线性调度、余弦调度等。
1. DDPM(Denoising Diffusion Probabilistic Model)
DDPM是最基础的扩散模型,它通过在多个时间步中逐步去除噪声,最终从一个接近随机噪声的状态生成高质量图像。这个采样过程通常是随机的,充满了不确定性。
反向扩散:模型学习如何从每个时间步中的带噪声图像中去除噪声,从而逐渐恢复到原始的清晰图像。
特点:
逐步采样:每个时间步依赖前一步的结果,因此采样过程是逐步完成的,通常需要数百或上千步来生成图像。
采样效率:DDPM的采样过程比较慢,因为需要多次迭代逐步去噪。
优点:
生成质量高:通过多次迭代,DDPM能生成高质量图像。
理论上稳定:每一步的去噪过程都有明确的概率分布。
缺点:
速度慢:因为需要数百甚至上千个时间步,生成过程非常耗时。
2. DDIM(Denoising Diffusion Implicit Models)
DDIM是对DDPM的一种改进。它的设计目标是减少生成步骤的数量,从而提高采样速度,同时保留高质量的生成结果。DDIM通过引入一个非马尔可夫链的确定性采样方法,对时间步的改变,允许模型跳过某些时间步,实现更高效的采样。
在 DDPM 中,每一步的采样过程通常是随机的,从模型预测的噪声分布中随机采样。所以每次生成的图像会有细微差异。
DDIM通过引入一种确定性采样方法,它不依赖于每个时间步的随机性,而是通过显式公式一步步更新,而不是从噪声分布中随机采样。这意味着给定相同的初始噪声,DDIM可以在多次生成中输出相同的图像。它能够将原本长时间的采样过程减少为较少的时间步(例如从1000步减少到几十步)。
特点:
跳跃采样:DDIM可以通过控制时间步之间的跳跃,减少采样步骤。
确定性生成:与DDPM的随机采样不同,DDIM的采样过程是确定性的,即给定相同的输入,会产生相同的输出。
优点:
速度更快:通过跳跃时间步,DDIM大幅减少了采样时间。
可调节采样质量:采样步数可以调整,少步采样仍能生成高质量图像。
缺点:
生成质量可能稍差:与DDPM相比,在减少时间步数时,生成图像的质量可能会稍有下降。
3. DPM++(Denoising Diffusion Probabilistic Models++)
DPM++是对扩散采样过程的进一步优化,旨在同时提高生成的效率和质量。DPM++在采样过程中结合了多种策略,使得生成过程可以在少量时间步中保持图像质量。
DPM++通过优化反向过程中的噪声估计,使每个时间步的去噪过程更加精确。这种方法能够在保持较少时间步的同时,生成更高质量的图像。
特点:
多策略融合:结合了多个不同的采样优化策略,以提高采样速度和质量。
噪声在不同时间步的强度分配
减少采样步数
结合了确定性采样和随机性采样的优势。在某些阶段采用确定性采样来保持图像的生成一致性,而在另一些阶段采用随机性采样,增加生成多样性。
多重时间步架构。在早期快速消除大部分噪声,而在后期对图像进行更精细的处理。
更好的噪声估计:DPM++的噪声估计过程更加精准,反向扩散过程进行了更精确的建模和改进,减少了在推理阶段的误差累积,能够更好地去除噪声。
优点:
效率与质量平衡:在较少的时间步中依然能生成高质量图像。
速度更快:相比于DDPM,DPM++在大幅减少时间步的同时保持了生成质量。
缺点:
复杂度较高:DPM++的采样算法更复杂,可能在某些实现中不如DDIM或DDPM直观。
总结:DDPM、DDIM、DPM++的对比
采样方法
生成速度
生成质量
工作机制
优缺点
DDPM
慢
高
多时间步逐步去噪(随机性强)
质量高,但采样步骤多,生成时间长
DDIM
较快
中-高
确定性采样,可跳过时间步
速度快,质量与时间步数相关,可调节
DPM++
快
高
多策略优化噪声估计,减少时间步
高质量与快速采样的平衡,采样过程复杂
选择使用的采样方法:
如果生成速度是关键,如在推理时实时生成图像,建议使用DDIM或DPM++,因为它们可以减少时间步数,并且仍能保持良好的图像质量。
如果质量是第一位且时间不敏感,DDPM的逐步采样过程可能是最好的选择,尽管它的采样过程较慢。
DPM++在实际应用中提供了最好的速度与质量平衡,特别适合对高质量生成有要求的场景。
【2】U-Net模型的完整结构图
Stable Diffusion中的U-Net,在传统深度学习时代的Encoder-Decoder结构的基础上,增加了以下的模块:
- ResNetBlock(包含Time Embedding)模块
- Spatial Transformer(SelfAttention + CrossAttention + FeedForward)模块
- CrossAttnDownBlock,CrossAttnUpBlock和CrossAttnMidBlock模块。
那么各个模块都有什么作用呢?不着急,咱们先看看SD U-Net的整体架构(AIGC算法工程师面试核心考点)。
下图是Rocky梳理的Stable Diffusion U-Net的完整结构图:

上图中包含Stable Diffusion U-Net的十四个基本模块:
- GSC模块:Stable Diffusion U-Net中的最小组件之一,由GroupNorm+SiLU+Conv三者组成。【VAE用的Swish,SiLU(Sigmoid-Weighted Linear Unit)和 Swish 实际上是同一种激活函数,它们的定义完全相同,只是在不同的文献和框架中使用了不同的名称。】
- DownSample模块:Stable Diffusion U-Net中的下采样组件,使用了Conv(kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))进行采下采样。
- UpSample模块:Stable Diffusion U-Net中的上采样组件,由插值算法(nearest)+Conv组成。
- ResNetBlock模块:借鉴ResNet模型的“残差结构”,让网络能够构建的更深的同时,将Time Embedding信息嵌入模型。【处理的主要是图像特征】
- CrossAttention模块:将文本的语义信息与图像的语义信息进行Attention机制,增强输入文本Prompt对生成图片的控制。
- SelfAttention模块:SelfAttention模块的整体结构与CrossAttention模块相同,这是输入全部都是图像信息,不再输入文本信息。
- FeedForward模块:Attention机制中的经典模块,由GeGlU+Dropout+Linear组成,增强模型的表达能力。
- BasicTransformer Block模块:由LayerNorm+SelfAttention+CrossAttention+FeedForward组成,是多重Attention机制的级联,并且也借鉴ResNet模型的“残差结构”。通过加深网络和多Attention机制,大幅增强模型的学习能力与图文的匹配能力。
- Spatial Transformer模块:由GroupNorm+Conv+BasicTransformer Block+Conv构成,ResNet模型的“残差结构”依旧没有缺席。确保局部特征和全局特征的有效融合。
- DownBlock模块:由两个ResNetBlock模块组成。
- UpBlock_X模块:由X个ResNetBlock模块和一个UpSample模块组成。
- CrossAttnDownBlock_X模块:是Stable Diffusion U-Net中Encoder部分的主要模块,由X个(ResNetBlock模块+Spatial Transformer模块)+DownSample模块组成。
- CrossAttnUpBlock_X模块:是Stable Diffusion U-Net中Decoder部分的主要模块,由X个(ResNetBlock模块+Spatial Transformer模块)+UpSample模块组成。
- CrossAttnMidBlock模块:是Stable Diffusion U-Net中Encoder和ecoder连接的部分,由ResNetBlock+Spatial Transformer+ResNetBlock组成。
接下来,为大家全面分析SD模型中U-Net结构的核心知识。
(1)ResNetBlock模块
借鉴ResNet模型的“残差结构”,让网络能够构建的更深的同时,将Time Embedding信息嵌入模型。【处理的主要是图像特征】

Stable Diffusion U-Net完整结构图中展示了完整的ResNetBlock模块,其输入包括Latent Feature和 Time Embedding。首先Latent Feature经过GSC(GroupNorm+SiLU激活函数+卷积)模块后和Time Embedding(经过SiLU激活函数+全连接层处理)做加和操作,之后再经过GSC模块和Skip Connection而来的输入Latent Feature做加和操作,进行两次特征融合后最终得到ResNetBlock模块的Latent Feature输出,增强SD模型的特征学习能力。
GSC模块:Stable Diffusion U-Net中的最小组件之一,由GroupNorm+SiLU+Conv三者组成。【VAE用的Swish,SiLU(Sigmoid-Weighted Linear Unit)和 Swish 实际上是同一种激活函数,它们的定义完全相同,只是在不同的文献和框架中使用了不同的名称。】
值得注意的是,Time Embedding输入到ResNetBlock模块中,为U-Net引入了时间信息(时间步长T,T的大小代表了噪声扰动的强度),模拟一个随时间变化不断增加不同强度噪声扰动的过程,让SD模型能够更好地理解时间相关性。能告诉U-Net现在是整个迭代过程的哪一步,并及时控制U-Net够根据不同的输入特征和迭代阶段而预测不同的噪声残差。
在迭代的早期,能够先生成整幅图片的轮廓与边缘特征,随着迭代的深入,再补充生成图片的高频和细节特征信息。
定义Time Embedding的代码如下所示,可以看到Time Embedding的生成方式,主要通过sin和cos函数再经过Linear层进行变换:
def time_step_embedding(self, time_steps: torch.Tensor, max_period: int = 10000):half = self.channels // 2frequencies = torch.exp(-math.log(max_period) * torch.arange(start=0, end=half, dtype=torch.float32) / half).to(device=time_steps.device)args = time_steps[:, None].float() * frequencies[None]return torch.cat([torch.cos(args), torch.sin(args)], dim=-1)(2)CrossAttention模块
CrossAttention模块是我们使用输入文本Prompt控制SD模型图片内容生成的关键一招。

Cross Attention模块接受两个输入:一个是ResNetBlock模块的输出【图像特征】,另外一个是输入文本Prompt经过CLIP Text Encoder模型编码后的Context Embedding【文本特征】。
两个输入首先经过Attention机制(将Context Embedding对应的语义信息与Latent Feature中对应的语义信息相耦合),输出新的Latent Feature【Q和K计算注意力得分】,再将新输出的Latent Feature与输入的Context Embedding再做一次Attention机制【与V做加权】,从而使得SD模型学习到了文本与图片之间的特征对应关系。
【通过CrossAttention机制将 ResNetBlock 输出的图像特征和 CLIP Text Encoder 编码后的文本提示结合起来,使生成的图像与输入的文本提示相匹配。】
看CrossAttention模块的结构图,大家可能会疑惑为什么Context Embedding用来生成K和V,Latent Feature用来生成Q呢?
原因也非常简单:因为在Stable Diffusion中,主要的目的是想把文本信息注入到图像信息中里,所以用图片token对文本信息做 Attention实现逐步的文本特征提取和耦合。
补充CrossAttention模块细节内容,在Stable Diffusion中:
- Text Condition信息,通过Cross Attention组件嵌入,作为K Matrix和V Matrix。
- 图片的Latent Feature作为Q Matrix。
Text Condition是三维的,而Latent Feature是四维的,那它们是怎么进行Attention机制的呢?
- 每次进行Attention机制前,需要将Latent Feature从四维转到三维[batch_size,channels,height,width]转换到[batch_size,height*width,channels] ,就能够和Text Condition做CrossAttention操作。
- 在完成CrossAttention操作后,我们再将Latent Feature从[batch_size,height*width,channels]转换到[batch_size,channels,height,width] ,这样就又重新回到原来的维度。
还有一点是Text Condition如何跟latent Feature大小保持一致呢?
因为latent embedding不同位置的H和W是不一样的,但是Text Condition是从文本中提取的,其H和W是固定的。这里在CorssAttention模块中有一个非常巧妙的点,那就是在不同特征做Attention操作前,使用Linear层将不同的特征的尺寸大小对齐。
摘录于:https://zhuanlan.zhihu.com/p/643420260
(3)BasicTransformer Block模块

BasicTransformer Block模块是在CrossAttention子模块的基础上,增加了SelfAttention子模块和Feedforward子模块共同组成的,并且每个子模块都是一个残差结构,这样除了能让文本的语义信息与图像的语义信息更好的融合之外,还能通过SelfAttention机制让模型更好的学习图像数据的特征。
![]()
- SelfAttention,输入只有图像信息,主要是为了让SD模型更好的学习图像数据的整体特征。
- 再者,SelfAttention可以将输入图像的不同部分(像素或图像Patch)进行交互,从而实现特征的整合和全局上下文的引入,能够让模型建立捕捉图像全局关系的能力,有助于模型理解不同位置的像素之间的依赖关系,以更好地理解图像的语义。
- 在此基础上,SelfAttention还能减少平移不变性问题,SelfAttention模块可以在不考虑位置的情况下捕捉特征之间的关系,因此具有一定的平移不变性。
FeedForward模块:Attention机制中的经典模块,由GeGlU+Dropout+Linear组成。
(4)Spatial Transformer模块

Spatial Transformer模块:在BasicTransformer Block模块基础上,加入GroupNorm和两个卷积层。在Encoder中的CrossAttnDownBlock模块,Decoder中的CrossAttnUpBlock模块以及CrossAttnMidBlock模块都包含了大量的Spatial Transformer子模块。
在生成式模型中,GroupNorm的效果一般会比BatchNorm更好,主要有以下一些优势,让其能够成为生成式模型的标配:
- 对训练中不同Batch-Size的适应性:在生成式模型中,通常需要使用不同的Batch-Size进行训练和微调。这会导致 BatchNorm在训练期间的不稳定性,而GroupNorm不受Batch-Size的影响,因此更适合生成式模型。
- 能适应通道数变化:GroupNorm 是一种基于通道分组的归一化方法,更适应通道数的变化,而不需要大量调整。
- 更稳定的训练:生成式模型的训练通常更具挑战性,存在训练不稳定性的问题。GroupNorm可以减轻训练过程中的梯度问题,有助于更稳定的收敛。
- 能适应不同数据分布:生成式模型通常需要处理多模态多模态多模态数据分布,GroupNorm 能够更好地适应不同的数据分布,因为它不像 Batch Normalization那样依赖于整个批量的统计信息。
(5)CrossAttnDownBlock/CrossAttnUpBlock/CrossAttnMidBlock模块
CrossAttnDownBlock:


在Stable Diffusion U-Net的Encoder部分中,使用了三个CrossAttnDownBlock_X模块,
- CrossAttnDownBlock_X模块由
X个(ResNetBlock模块+Spatial Transformer模块)+DownSample模块组成。 - Downsample是Stable Diffusion U-Net中的下采样组件,使用了Conv(kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))进行采下采样。
CrossAttnUpBlock:


在Decoder部分中,使用了三个CrossAttnUpBlock模块,
- CrossAttnUpBlock由
X个(ResNetBlock模块+Spatial Transformer模块)+UpSample模块组成。 - Upsample是上采样组件,使用插值算法+卷积来实现,插值算法将输入的Latent Feature尺寸扩大一倍,同时通过一个卷积(kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))改变Latent Feature的通道数,以便于输入后续的模块中。
CrossAttnMidBlock:

是Stable Diffusion U-Net中Encoder和Decoder连接的部分,由ResNetBlock+Spatial Transformer+ResNetBlock组成。
补充:
DownBlock模块:由两个ResNetBlock模块组成。
UpBlock_X模块:由X个ResNetBlock模块和一个UpSample模块组成。
DownBlock 和 CrossAttnDownBlock_X 的作用区别
- DownBlock 专注于提取图像特征,通过下采样操作逐步压缩图像分辨率,不涉及文本信息。
- CrossAttnDownBlock_X 在图像特征提取的同时加入了 Cross-Attention,使得图像特征能够与文本提示信息结合,为后续生成提供语义线索。
UpBlock_X 和 CrossAttnUpBlock_X 的作用区别
- UpBlock_X 仅专注于上采样和图像细节恢复,在解码器中通过逐步提高特征分辨率还原图像。
- CrossAttnUpBlock_X 在恢复图像的同时,通过 Cross-Attention 将文本信息持续注入到图像特征中,使重构的图像细节能够响应输入文本,确保图像生成的精细度和文本一致性。
DownBlock vs CrossAttnDownBlock_X:
- DownBlock 仅执行图像特征提取和下采样,适合普通的【图像】特征提取过程;
- CrossAttnDownBlock_X 则通过 Cross-Attention 将文本信息注入【图像】特征提取过程,使图像特征从编码器阶段开始就受到文本的影响。
UpBlock_X vs CrossAttnUpBlock_X:
- UpBlock_X 仅执行图像的上采样和细节恢复,专注于图像重构;
- CrossAttnUpBlock_X 则在恢复图像分辨率的同时注入文本信息,确保生成的图像符合输入文本的描述。


(6)Stable Diffusion U-Net整体宏观角度小结
从整体上看,不管是在训练过程还是前向推理过程,Stable Diffusion中的U-Net在每次循环迭代中Content Embedding部分始终保持不变,而Time Embedding每次都会发生变化。
和传统深度学习时代的U-Net一样,Stable Diffusion中的U-Net也是不限制输入图片的尺寸,因为这是个基于Transformer和卷积的模型结构。
【3】Stable Diffusion中U-Net的训练过程与损失函数
在我们进行Stable Diffusion模型训练时,VAE部分和CLIP部分都是冻结的,所以说官方在训练SD系列模型的时候,训练过程一般主要训练U-Net部分。
我们之前我们已经讲过在Stable Diffusion中U-Net主要是进行噪声残差预测,在SD系列模型训练时和DDPM一样采用预测噪声残差的方法来训练U-Net,其损失函数如下所示:

到这里,Stable Diffusion U-Net的完整核心基础知识就介绍好了。

【4】SD模型融合详解(Merge Block Weighted,MBW)
不管是传统深度学习时代,还是AIGC时代,模型融合永远都是学术界、工业界以及竞赛界的一个重要Trick。
在AI绘画领域,很多AI绘画开源社区里都有SD融合模型的身影,这些融合模型往往集成了多个SD模型的优点,同时规避了不足,让这些SD融合模型在开源社区中很受欢迎。
详细了解SD模型的模型融合过程与方法,大家可能会好奇为什么SD模型融合会在介绍SD U-Net的章节中讲到,原因是SD的模型融合方法主要作用于U-Net部分。
首先,我们需要知道SD模型融合的形式,一共三种有如下所示:
- SD模型 + SD模型 -> 新SD模型
- SD模型 + LoRA模型 -> 新SD模型
- LoRA模型 + LoRA模型 -> 新LoRA模型