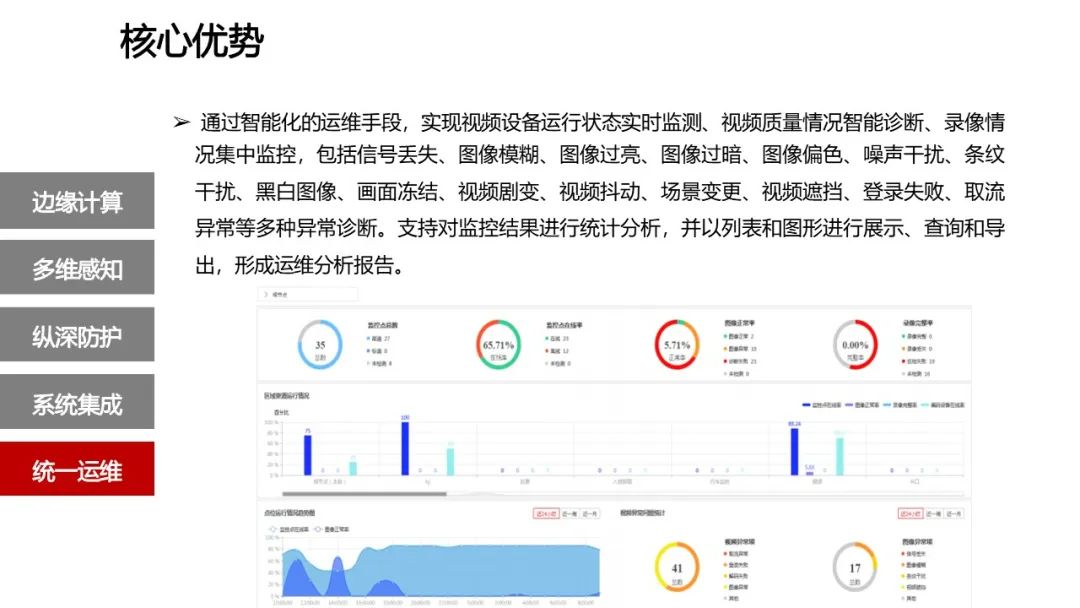
终于力扣的每日一题打卡完成了,以后应该只会偶尔写题解了,力扣的大概率应该不会再写了,以后还是专心读论文。定个小目标,每次在看完一篇论文之后不管看懂没看懂看得多不多都写一篇阅读笔记。
不过目前这一篇说是阅读笔记,估计论文翻译的比重更大一点吧,实在不太能看懂。
如果我没搞错的话,这篇应该是2021年发布在CVPR上的一篇关于深度伪造检测的论文。简单来说这篇论文提出了一种“新”的对深度伪造视频的检测方法。论文提出“现在”大多数深度伪造检测的方法是将其视为一种简单的二元分类问题,基本步骤就是先利用骨干网络(backbone network)提取出图像的全局特征,然后把它喂给二元分类器(binary classifier)就可以得到一个真或假的结果。
但由于真假图像往往只在某些局部地区有微小差异,作者认为这并不是一个很好的方法。作者在论文中选择将其视为一种细粒度的的分类问题(fine-grained classification),提出了一种新的多注意力(multi-attentional)深度伪造检测网络。
这个模型主要由三个部分构成,1)使用注意力模块生成多个空间注意力头,用来关注图像的不同的局部地区。2)使用稠密连接的卷积层作为纹理特征增强块(textural feature enhancement block),用来提取并放大浅层特征中的细微伪影(subtle artifacts)。3)使用BAP(Bilinear Attention Pooling)替换全局平均池化层(global average pooling)聚合低级的纹理特征并保留高级的语义特征。
但这种设计还存在一点小问题。不像单注意的网络可以利用视频级标签分类进行监督学习,多注意网络缺少细粒度级的标签,所以只能使用无监督学习或者弱监督学习,但这也导致网络容易因为多个注意力都集中在一个区域从而退化为单注意力网络。所以作者提出了区域独立的损失(regional independence loss)减少每个注意力图关注的区域的重叠并且对不同的输入保持关注的语义区域的一致性。感觉自己只是在翻译摘要
待续,明天再写