从“拼凑”到“构建”:大语言模型系统设计指南!
你有没有试过在没有说明书的情况下组装宜家家具?那种手忙脚乱却又充满期待的感觉,和设计大语言模型(LLM)系统时如出一辙。如果没有一个清晰的计划,很容易陷入混乱。我曾经也一头扎进去,满心期待却又手足无措,被网上那些复杂的架构图搞得晕头转向。于是,我坐下来,把它们都梳理了一遍。今天,我就把这份“梳理心得”分享给你,希望能帮你少走些弯路。
你将在这份指南中学到什么
这份指南可不只是教你把大语言模型简单地连到一个输入框,而是带你深入系统设计的思维,教你如何打造一个可扩展、能在生产环境中稳定运行的人工智能应用。接下来的内容,都是干货:
-
大语言模型系统究竟是什么?
-
核心组件有哪些?
-
如何部署与扩展?
-
带检索的生成(RAG)到底值不值得追?
-
如何设置保障措施、监控和防护网?
-
怎样从原型迈向生产?
大语言模型系统究竟是什么?
如果把大语言模型比作大脑,那么一个真正智能的系统就是一个完整的人。它不仅能思考,还能记住事情、做出决策、检查自己的工作,还能根据不同的场景灵活调整。要构建这样的系统,光有模型可不行,还得给它配上一套“黄金搭档”的支持系统。
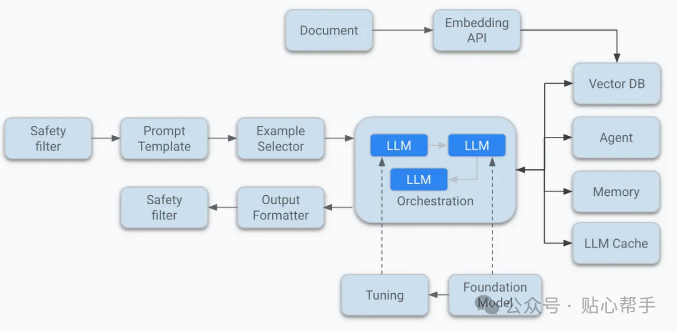
我们来逐一剖析这些“黄金搭档”:
检索器(Retrievers):大语言模型虽然知识渊博,但它可不是搜索引擎,没法实时获取最新的信息。这时候,检索器就派上用场了。它能通过语义搜索(通常借助 Pinecone、Weaviate、FAISS 或 Qdrant 这样的向量数据库)从你的文档、知识库、维基百科、数据库或 API 中找到最相关的资料,然后把这些资料注入到提示词里,再一起送给大语言模型。就好比给模型配了个“小助手”,在模型回答问题之前,先帮它把相关资料查一遍。
记忆模块(Memory modules):大多数大语言模型天生就是“健忘”的,它们默认不记得几分钟前发生的事。但用户可不希望跟一个“没记忆”的系统交流。他们期待系统能记住自己的名字、目标、之前的问题,甚至是对话中提到的内容。
记忆模块就有两种:
-
短期记忆:就像聊天时的“记忆窗口”,能记住最近几轮对话的内容,通常通过上下文窗口或缓存来管理。
-
长期记忆:则是把用户的一些持久性信息,比如偏好、历史对话等,存储在数据库里,或者把它们总结成向量嵌入,需要的时候再调出来。
评估器(Evaluators):大语言模型有时候会“自信过头”,即使输出的内容是错的、有害的,或者完全不搭边,它也毫不含糊地往外蹦。所以在生产环境中,我们不能完全信任它的输出。这时候,评估器就出场了。这些评估器可以是专门的子系统,比如另一个大语言模型或者分类器,它们的作用就是检查模型的输出是否符合我们的质量标准。
评估器可以在:
-
响应之前:过滤提示输入或者检索到的文档;
-
响应之后:对输出内容进行审核或者重新排序;
-
A/B 测试流程中:比较不同候选生成内容的好坏。
协调器(Orchestrators):大语言模型的本事可不少,总结、生成代码、搜索、规划、调用工具……样样都能来一手。可这么多功能,到底什么时候该用哪一个呢?这就得靠协调器来指挥了。它就像是人工智能交响乐团的“指挥家”,根据不同的场景和需求,决定模型在什么时候该做什么。