MEME在线进行蛋白氨基酸序列的保守基序预测的具体分析步骤
使用 MEME Suite 的在线工具预测蛋白质氨基酸序列的保守基序(motif)可分为以下步骤:
1. 数据准备
输入格式:
支持 FASTA 格式的氨基酸序列(如 `>Protein1\nMSTVDE...`)。
确保序列无非法字符(如空格、数字),仅包含标准氨基酸缩写(AZ)。
序列要求:
建议提交 5~1000条 序列,单条序列长度建议 ≥6 aa。
若序列数量过多(>100),可先通过聚类减少冗余。
2. 访问MEME在线工具
打开 MEME 官网:[MEME Suite](https://memesuite.org/meme/tools/meme)
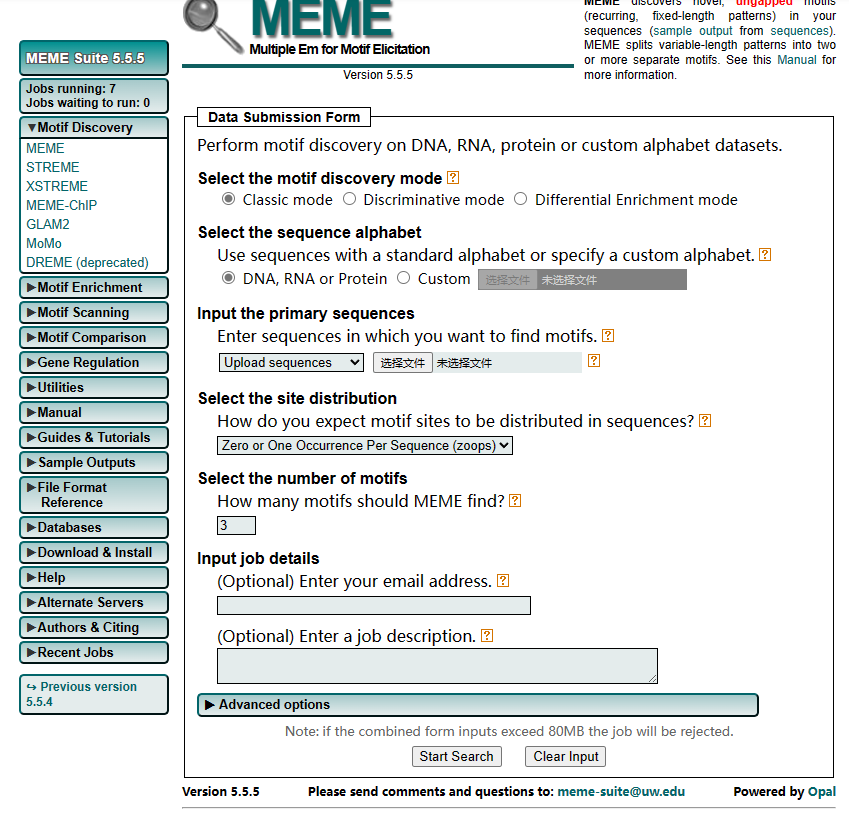
点击 Submit a Job → 选择 MEME 工具。 运行界面如下,可以填写邮箱(结果发送指定的邮箱)
3. 参数设置
核心参数(必填):
Motif数量(Number of motifs):
默认 3,可根据需求调整(如 5~10)。
Motif宽度(Width):
设置基序的最小/最大长度(如 6~50 aa)。
默认 `Minimum=6`,`Maximum=50`。
输出模式(Output mode):
选择 `Any number of repetitions`(默认)或 `Zero or one per sequence`。
高级参数(可选):
统计模型(Statistical model):
默认 `zoops`(每个序列出现零次或一次基序),适合多数情况。
其他选项:`oops`(每个序列必须包含一个基序),`anr`(允许重复)。
背景模型(Background model):
默认使用输入序列的氨基酸频率,或选择 `Uniform`(均等分布)。
4. 提交任务
1. 上传FASTA文件或直接粘贴序列。
2. 输入任务名称(可选)和邮箱(接收结果链接)。
3. 点击 Start Search 提交。
5. 结果解读
主要输出文件:
MEME.html:可视化报告,包含以下关键信息:
保守基序(Motifs):以序列标志图(Sequence Logo)展示,显示每个位点的氨基酸保守性。
Evalue:评估基序显著性(值越小越显著,通常 <0.05)。
匹配序列:列出包含该基序的序列及位置。
示例结果:
```
MOTIF 1: Width=12, Sites=20, Evalue=1.2e10
Sequence Logo: [LVI] [DE] [GAS] ...
匹配序列: Protein1(1223), Protein2(4556)...
```
6. 下游分析
比对验证:
使用 MAST 工具(MEME Suite)在数据库(如 UniProt)中搜索匹配的已知基序。
功能预测:
结合 InterPro 或 Pfam 注释基序功能(如激酶结构域、锌指等)。
可视化优化:
使用 Togo 或 WebLogo 美化序列标志图。
注意事项
1. 运行时间:
短序列(<50 aa)通常需 1~5 分钟,长序列(>1000 aa)可能需要数小时。
2. 失败处理:
若报错 `No motifs found`,尝试放宽宽度范围或增加序列数量。
3. 数据安全:
敏感数据建议使用本地版 MEME Suite(需Linux环境)。
通过以上步骤,可系统性地预测蛋白质序列中的保守功能基序。如需进一步分析(如多序列比对共定位),可结合 Tomtom 工具比对已知基序数据库(如 JASPAR)。