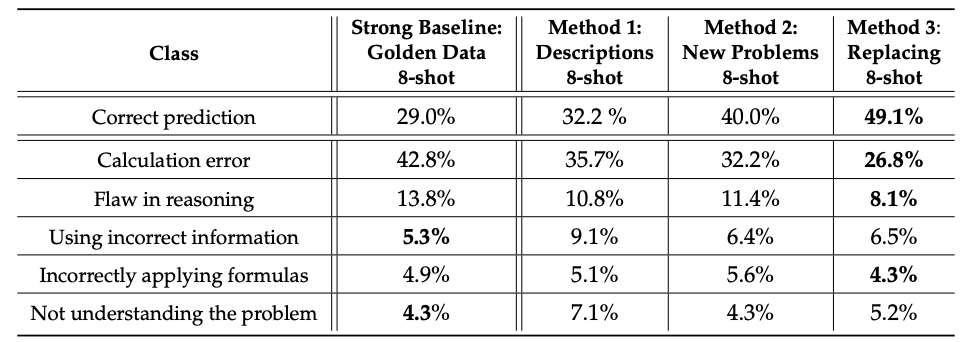
链路追踪作为一种用于监控和观察分布式系统中请求流动和性能的技术,在现代微服务架构中扮演着重要角色。
在复杂的分布式环境中,它可以记录并可视化跨多个服务与组件的完整请求路径,并提供每个服务节点上的执行时间,帮助开发人员清晰地掌握请求走向、识别性能瓶颈。
在出现故障或错误时,链路追踪能够提供详细的信息,帮助开发人员快速定位问题的根源,加速故障排查过程。通过分析链路追踪数据,团队可以基于实际使用情况优化服务、调整资源配置,从而进行容量规划和设计决策。
本文将介绍 EMQX ECP 和 Datalayers 如何通过 OpenTelemetry Collector 集成以实现链路追踪功能,基于 ECP 通过 Datalayers 的 REST API 查询,可以实现对链路追踪数据的检索和展示,辅助用户对分布式系统的监控和诊断。
产品介绍
EMQX ECP:是一款面向工业 4.0 工业互联数据平台,能够满足工业场景大规模数据采集、处理和存储分析的需求,提供边缘服务的快速部署、远程操作和集中管理等功能,助力工业领域数据互联互通,以数据 + AI 驱动生产监测、控制和决策,实现智能化生产,提高效率、质量和可持续性。
Datalayers:是澜图未来(成都)数据科技有限公司开发的一款为工业物联网、车联网、能源行业设计的分布式多模态、超融合数据库,具备时序数据存储、多模融合、键值存储、存算分离、读写分离、自适应压缩、原生 SQL、边云同步和云原生等特点,支持边缘向云端的数据同步,并针对受限设备进行优化。
链路追踪的实现
数据写入
EMQX ECP 相关的链路追踪服务 NeuronEX 和 EMQX 的 Trace 数据都支持通过 otlp protocol 写入到 otlp 协议的服务端,通过 OpenTelemetry Collector 的 otlp receivers 插件,可以开启 http 和 grpc 两种协议的接收器,OpenTelemetry Collector 收到 trace 数据后,通过各种 Exporter 插件可以将数据写入不同的后端数据库中。
由于 Datalayers 也支持 InfluxDB 行协议,可以通过 OpenTelemetry Collector 的 InfluxDB Exporter 插件与 Datalayers 实现集成。
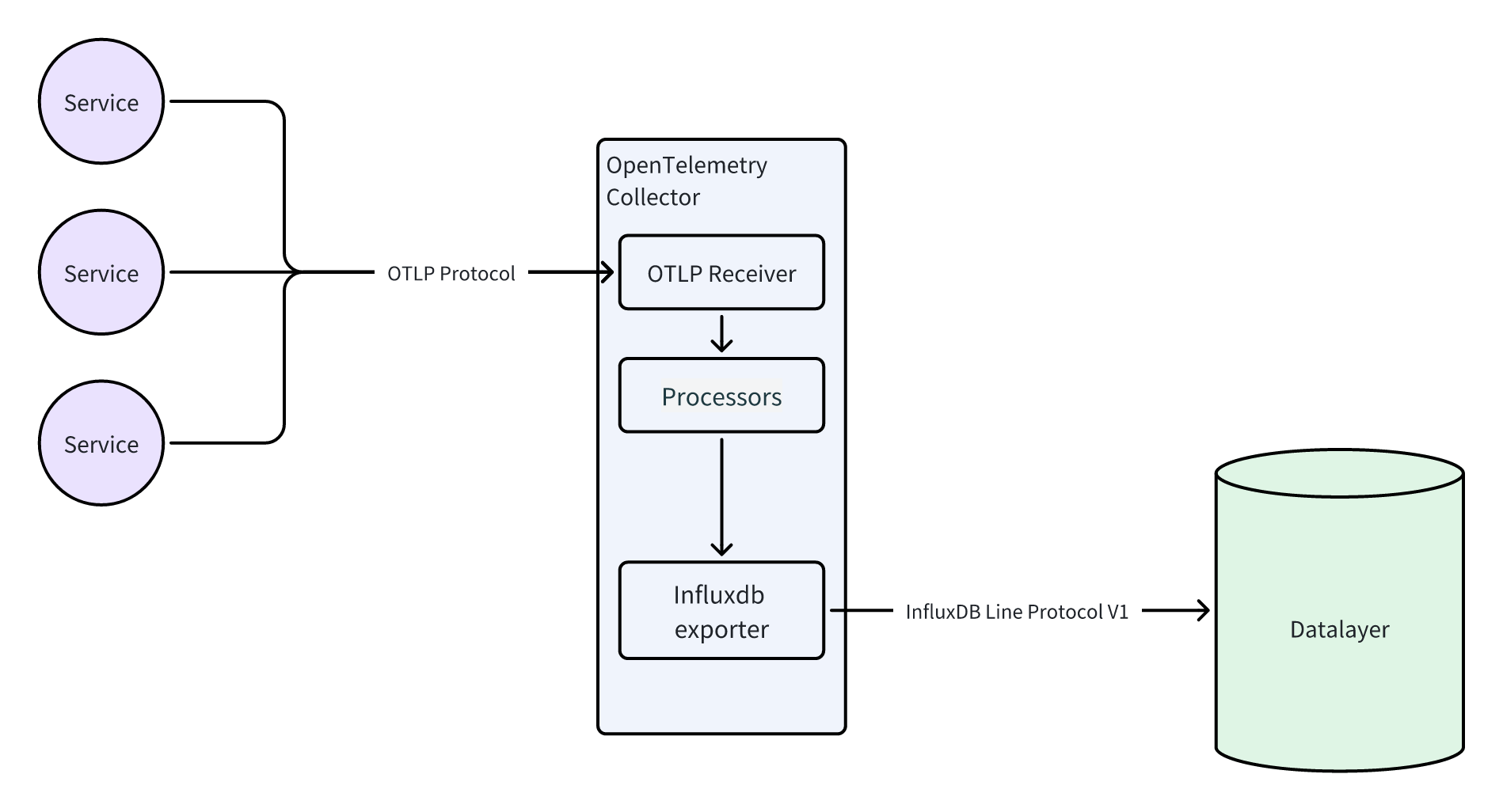
OpenTelemetry Collector 官方提供了 Core、 Contrib 两个不同的版本。 其中,前者只包基础的插件, 后者包含了所有的插件。Core 版本中没有 influxdb exporter 插件,而 Contrib 版本中有。用户也可以按需自己构建镜像,只包含自己需要的插件,建议生产环境采用这种方式, 参考:Building a custom collector。
由于 Datalayers 仅支持 InfluxDB v1.x API 行协议, 因此需要在 OpenTelemetry Collector 的 InfluxDB Exporter 插件配置中开启 v1_compatibility 相关配置。通过 span_dimensions 可以自定义行协议中的标签, 同时也是 Datalayers 表的联合索引字段, InfluxDB Exporter 默认强制 span_dimensions 会加上 trace_id, span_id, 和我们自己配置的 span_dimensions 共同构成协议中的标签。
InfluxDB Exporter 所有配置如下所示:
The following configuration options are supported:
- endpoint (required) HTTP/S destination for line protocol
- if path is set to root (/) or is unspecified, it will be changed to /api/v2/write.
- timeout (default = 5s) Timeout for requests
- headers: (optional) additional headers attached to each HTTP request
- header User-Agent is OpenTelemetry -> Influx by default
- if token (below) is set, then header Authorization will overridden with the given token
- org (required) Name of InfluxDB organization that owns the destination bucket
- bucket (required) name of InfluxDB bucket to which signals will be written
- token (optional) The authentication token for InfluxDB
- v1_compatibility (optional) Options for exporting to InfluxDB v1.x
- enabled (optional) Use InfluxDB v1.x API if enabled
- db (required if enabled) Name of the InfluxDB database to which signals will be written
- username (optional) Basic auth username for authenticating with InfluxDB v1.x
- password (optional) Basic auth password for authenticating with InfluxDB v1.x
- span_dimensions (default = service.name), span.name) Span attributes to use as dimensions (InfluxDB tags)
- log_record_dimensions (default = service.name) Log Record attributes to use as dimensions (InfluxDB tags)
- payload_max_lines (default = 10_000) Maximum number of lines allowed per HTTP POST request
- payload_max_bytes (default = 10_000_000) Maximum number of bytes allowed per HTTP POST request
- metrics_schema (default = telegraf-prometheus-v1) The chosen metrics schema to write; must be one of:
- telegraf-prometheus-v1
- telegraf-prometheus-v2
- sending_queue details here
- enabled (default = true)
- num_consumers (default = 10) The number of consumers from the queue
- queue_size (default = 1000) Maximum number of batches allowed in queue at a given time
- retry_on_failure details here
- enabled (default = true)
- initial_interval (default = 5s) Time to wait after the first failure before retrying
- max_interval (default = 30s) Upper bound on backoff interval
- max_elapsed_time (default = 120s) Maximum amount of time (including retries) spent trying to send a request/batch
详见: influxdb-exporter configuration
最简 OpenTelemetry Collector 配置示例
receivers:otlp:protocols:grpc:endpoint: 0.0.0.0:4317http:endpoint: 0.0.0.0:4318
exporters:influxdb:endpoint: http://172.31.104.77:8361v1_compatibility:enabled: truedb: demousername: adminpassword: public
service:extensions: []pipelines:traces:receivers: [otlp]processors: []exporters: [influxdb]
配置中 Exporter 的 endpoint 需要替换成自己的 Datalayers 地址。由于当前 Datalayers 默认只支持 v1 版本的 InfluxDB Line Protocol,所以需要将 v1_compatibility 设置为 true。要使用的数据库名称需要提前在 Datalayers 中创建。
在 receivers 中选择一个协议(比如 otlp),和协议对应的 endpoint 配置。 从 receivers 中收到的数据会被 processor 处理,这里没有配置,所以直接发送到 exporters,即为 Datalayers。当 Datalayers 收到数据后,会根据配置的数据库名称,将数据写入到对应的数据库中, 如果没有对应的表, 则会自动创建(如果关闭了 Datalayers 的自动创建表功能, 则需要提前在 Datalayers 中创建表)。
数据查询
Datalayers 使用 SQL 作为查询语言,SQL 是一种相对简单的语言,易于学习和使用。它使用类似自然语言的语法,使得用户可以快速上手,从而减少了学习成本。
可以通过 REST API 或者 Arrow Flight SQL 进行查询。其中 REST API 是基于 HTTP 的,而 Arrow Flight SQL 是基于 gRPC 的,性能更好,并且提供了常见语言的 SDK 。ECP 目前使用的是 REST API 查询, 后期可能会切换到性能更好的 Arrow Flight SQL方式。此外,Datalayers 还支持按时间窗口进行聚合查询等功能, 此处不多做介绍, 感兴趣可以查阅官方文档。
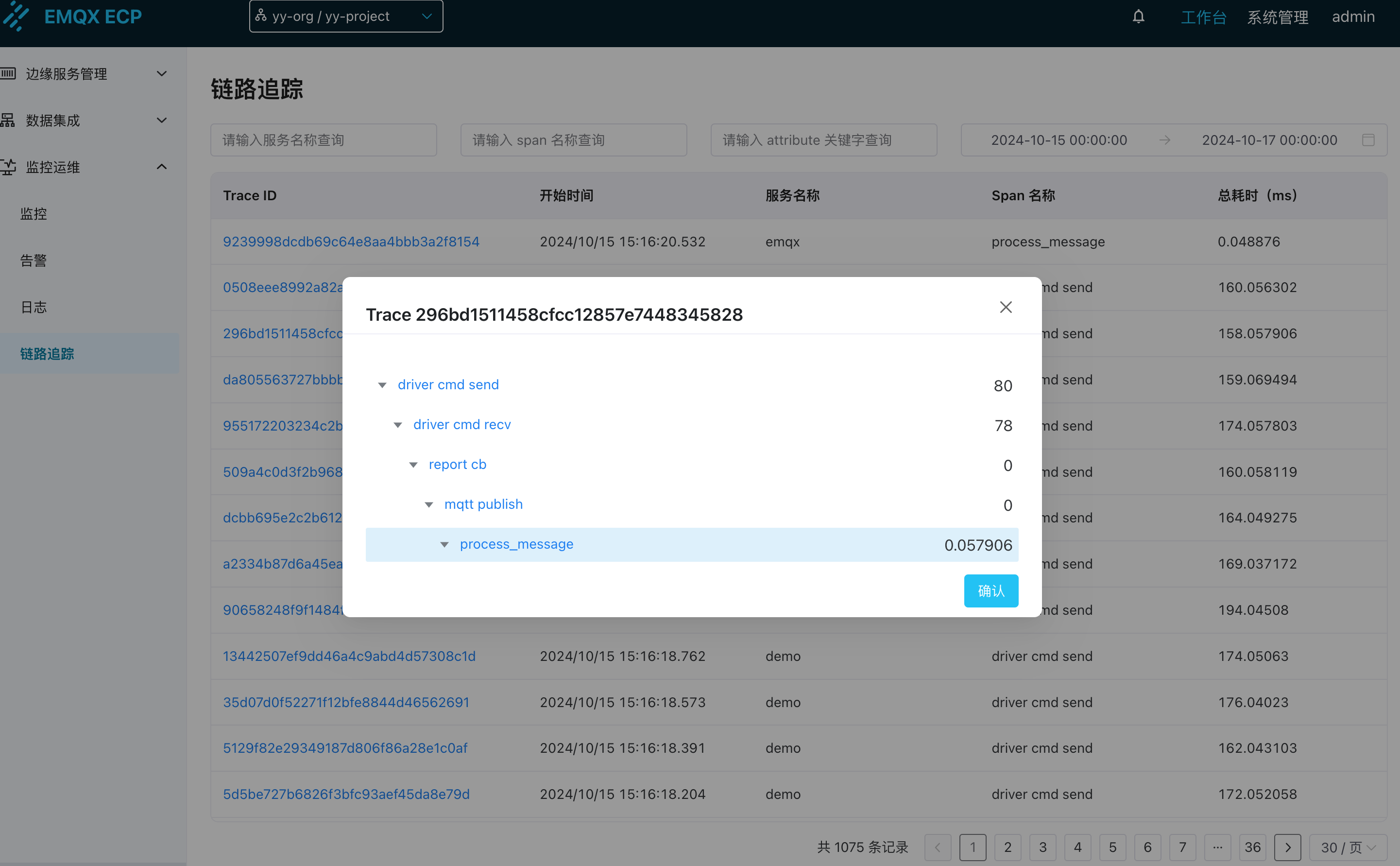
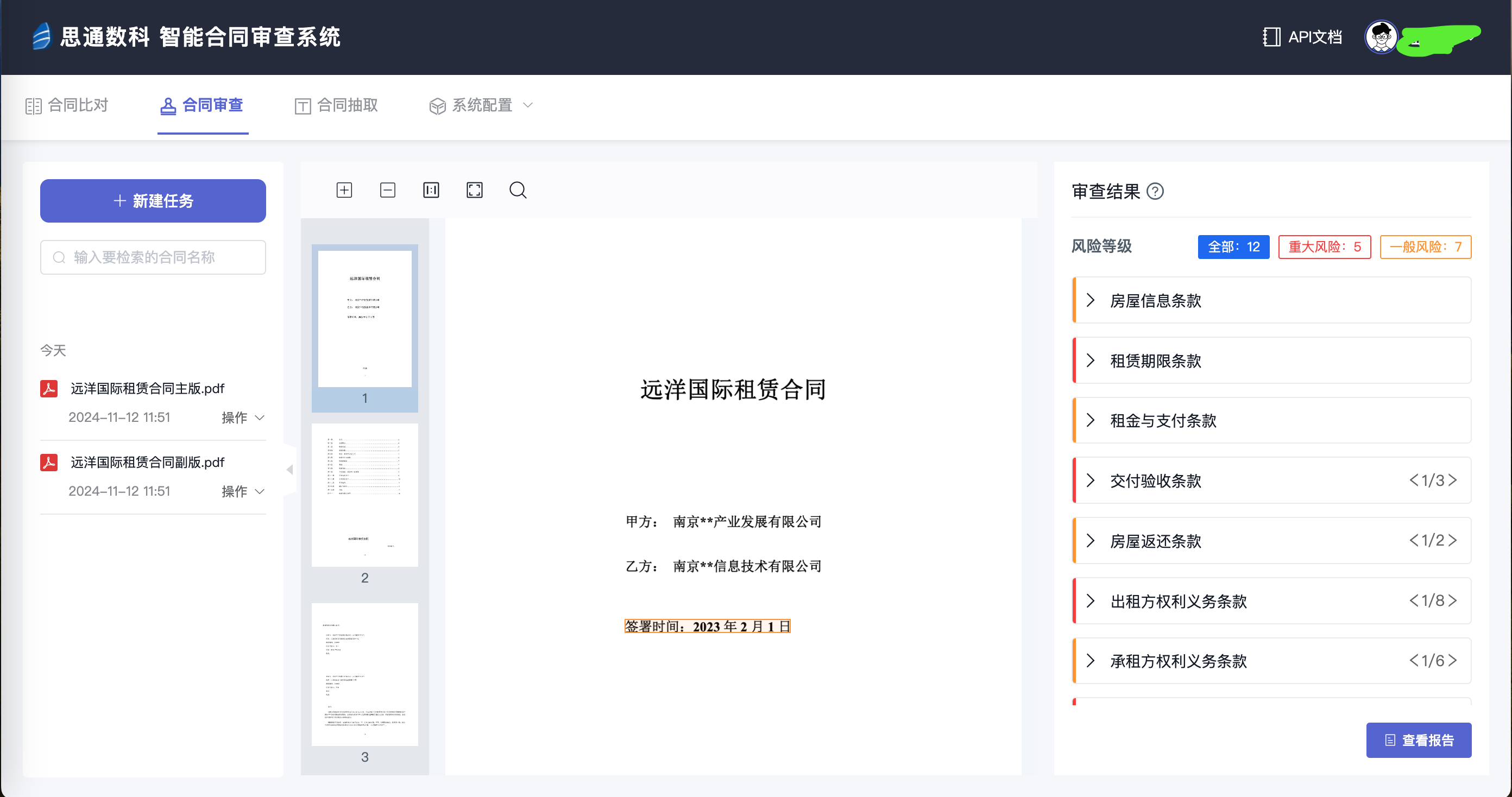
上图展示了 EMQX ECP 的链路追踪 trace_id 列表, 表格中列出了多个请求的追踪信息,包括它们的trace_id、开始时间、服务名称、Span 名称和总耗时。点开后还可以查阅每个 Trace 中所有的 Span, Span 之间的先后顺序, Span 的所有属性, 每个 Span 的耗时等等信息, 这些数据可以帮助开发者分析请求的处理效率,识别性能瓶颈,以及调试系统中的问题。
总结
至此,本文完整介绍了 EMQX ECP 和 Datalayers 通过 OpenTelemetry Collector 集成实现链路追踪功能。将 EMQX ECP 的链路追踪数据以 InfluxDB 行协议方式写入 Datalayers,并结合 Datalayers 的 REST API 和 Arrow Flight SQL 两种查询方式,检索和展示链路追踪数据,实现对分布式系统的监控和诊断。
未来,EMQX ECP 还会进一步拓展存储和查询指标数据的功能,敬请期待。
版权声明: 本文为 EMQ 原创,转载请注明出处。
原文链接:https://www.emqx.com/zh/blog/emqx-ecp-datalayers-and-open-telemetry-collector