概述
谷歌的 Gemini Ultra(2023 年)和 OpenAI 的 GPT-4 (2023 年)等大规模语言模型在许多任务中都表现出了令人印象深刻的性能。然而,这些模型不仅推理成本高昂,而且运行于数据中心,而数据中心并非本地环境,无法获得私人数据。另一方面,可以在私人环境中运行的模型,如 Gemini Nano,可以在用户的设备上运行,但其性能有限。
为了在私密环境中实现最先进的性能,需要本地模型具有隐私保护机制,可以在不共享敏感数据的情况下向远程模型发送查询。在传统的级联系统中,人们已经研究了较小、能力较弱的模型向较大、能力较强的模型发送查询的机制,但尚未研究保护隐私的机制。在当前的级联系统中,使用大型模型的决定通常基于查询是否可以由较小的模型独立处理。
如果决定在大型模型中进行处理,则包含私人数据的查询会被原封不动地传输。这会造成隐私威胁,例如敏感数据泄露或转发的查询被纳入远程系统的训练数据集。
本文首次提出了级联系统的隐私保护方法。与传统的级联系统不同,本文提出的方法假定本地模型始终保持其数据的私密性。因此,本地模型不会与远程模型共享任何隐私信息。此外,即使本地模型不逐字共享隐私信息,也能防止远程模型的操作员利用辅助信息重建隐私数据。为了应对这些挑战,我们假设不存在效率限制,本地模型可以随时向远程模型寻求帮助。因此,这种方法的最佳级联设置在于最大限度地降低隐私损失,同时最大限度地提高任务性能。
为了成功完成这项任务,通常规模较小、能力较弱的本地模型需要在以下两个方面找到平衡点:既要暴露足够多的问题信息,以便从能力更强的远程模型那里接收有用的信号,又要保护隐私细节。为了向远程模型学习,本地模型利用大规模语言模型的上下文学习(ICL)能力,通过自然语言实现无梯度学习功能。它还利用了 Mohtashami 等人(2023 年)和 Bandura & Walters(1977 年)最近提出的社会学习范式,即通过自然语言向其他大规模语言模型学习。
解决问题
本文探讨了一种没有标签数据的社会学习形式。本地模型 "学生 "拥有私人数据,自身无法很好地标注数据,而更大的远程模型 "教师 "则能更好地标注数据。这两个模型形成一个级联,如下图所示,"学生 "通过与"教师 "的交流提高性能。学生"发送给 "教师 "的信息称为 “查询”。

从 "学生 "到 "教师 "的查询有两个限制:第一个限制涉及隐私保护。第二个限制是单轮通信。学生 "和 "老师 "之间的交流只进行一轮,双方都无法保持对对方能力的了解,也无法更新自己的模型。因此,所有算法都遵循相同的结构。也就是说,如果 "学生 "需要帮助,"学生 "会使用私人数据向 "老师 "提出询问。然后,"教师 "使用该查询为 "学生 "生成一个 ICL(上下文学习)示例。最后,"学生 "使用 ICL 示例解决原始问题。
还有两个简化假设:第一个假设是,与远程 "教师 "的交流总是有益的;第二个假设是,"学生 "和 "教师 "都知道示例的格式。这一假设是有用的,因为"学生 "不仅仅是在学习格式和思维链(CoT),而是在向"教师 "学习有关数据的更复杂的东西。
在这种问题设置中,"学生 "的目标是在不泄露属于自己数据的私人信息的情况下,最大限度地提高准确标注数据的性能。
隐私保护措施
学生 "数据可能包含敏感的个人信息,这些信息应向 "教师 "保密。例如,在描述用户在某项活动后出现的健康症状的查询中,将某项活动或一组症状与特定用户联系起来就会侵犯隐私。
为了解决这些隐私泄露问题,可以考虑采用数据匿名化技术,如差分隐私(DP),但 DP 适用于计算许多用户的汇总数据;使用 DP 时,查询中的隐私和非隐私信息都会被掩盖,从而生成对任务无用的查询。这可能会产生对任务无用的查询。使用 DP-ICL 模型也更难将 "学生 "数据的敏感部分保密。
这是因为我们假设 "学生 "在生成查询时会考虑许多私人示例。在本文中,我们希望即使 "学生 "只有少量私人示例,也能生成保护隐私的查询。然而,DP-ICL 在这种情况下不起作用。
因此,它利用了数据最小化隐私技术,特别是上下文完整性。这将隐私描述为信息的正常流动。在这种技术中,"学生 "会保留对任务有用的信息,并删除与查询上下文无关的个人身份信息。即使有完美的掩码,如果 "教师 "模型获得了可用于识别某些特征的补充信息,敏感信息也会泄露。因此,所提方法的一个重要贡献就是提供了一种测量和评估辅助信息泄漏的方法。
拟议方法的成功取决于能否在不篡改任务描述的情况下正确识别和屏蔽查询的敏感部分。为此,我们提出了不同的技术来分析查询中的信息,并生成可与 "教师 "模型共享的安全查询。为了评估查询的私密性,我们考虑了两个特定的指标:实体泄漏指标和映射泄漏指标,后者考虑了考虑到辅助信息的配置。
上下文完整性将隐私定义为适当的信息流。在大多数生产应用中,很难确定哪些信息适合共享。作为替代,可以考虑对受损实体进行可解释的度量。数据集中的所有实体,如姓名、地点、电子邮件地址或号码,都被视为隐私。屏蔽后,我们会测量 "学生 "查询中还保留了多少原始示例中的实体。
即使从 "学生 "的查询中删除了所有实体,"教师 "仍有可能通过仔细分析查询来重建私人信息。事实上,"教师 "可以访问的辅助信息有助于提高其效率。这种分析是在最坏的情况下进行的。
具体来说,"教师 "会看到原始示例和 100 个屏蔽查询,假设其中只有一个是由原始示例生成的。测量"教师"在 100 个选项中能正确将原始示例映射到该特定(屏蔽)查询的频率。为 "教师 "提供一个完整的原始示例代表了"教师"可能拥有的辅助信息的上限。为了更好地进行映射,可以让 "教师 "查询 "学生 "模型。这一点很有用,因为它是用来生成屏蔽查询的。要进行映射,可对原始示例和 100 个生成查询的连续性进行评分,并衡量正确查询获得最高分的频率。对辅助信息的这种(最坏情况)访问表明,即使对实体进行了适当的屏蔽,仍可能导致严重的隐私泄露。
建议方法
它介绍了三种帮助 "学生 "私下向 "老师 "学习的算法。这些方法基于对 "学生 "所面临问题的描述,以及生成可由 "教师 "标记的类似非私人示例。所有方法都使用一个名为 "扩展大小 "的超参数来表示 "学生 "从 "教师 "那里获得的贴有标签的 ICL 示例的数量。
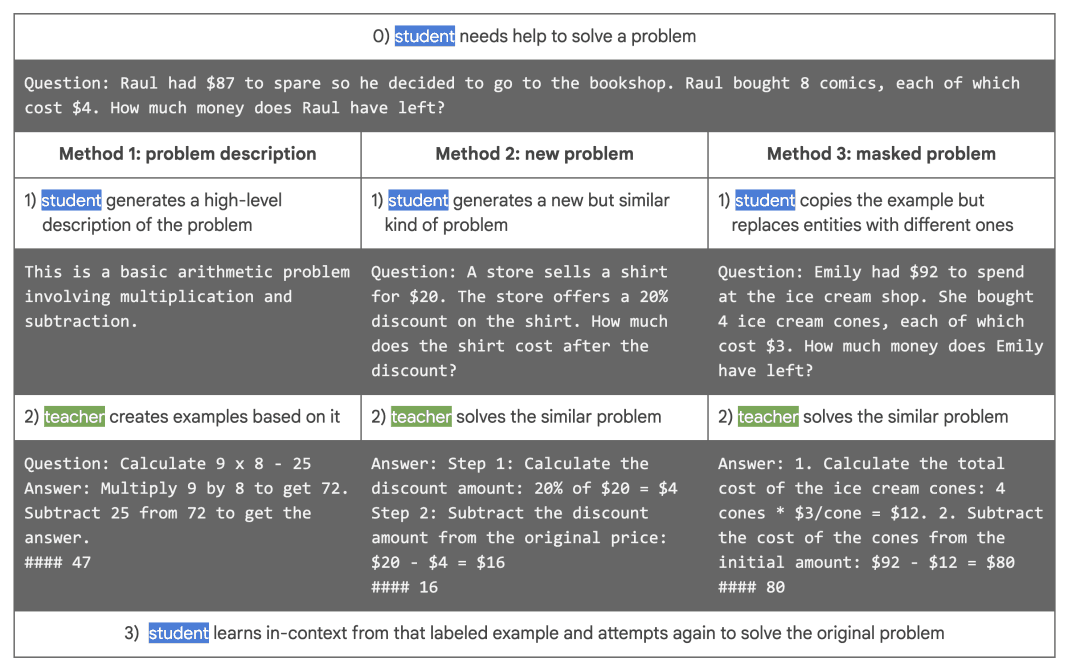
第一种方法(方法 1)是创建问题解释。这是一种 "学生 "首先分析给定问题,然后将其转化为高层次解释的方法。即使问题无法解决,"学生 "也能解释问题的类型。这一解释将成为 "教师 "的疑问。然后,"教师"会创建少量示例,帮助"学生"解决所面临的问题。教师"根据"学生"的描述,使用范例结构模板并生成新的范例。
第二种方法(方法 2)生成新的无标签示例。这种方法不是对"学生"面临的问题进行抽象描述,而是生成类似的新问题。例如,GSM8k 中学数学问题数据集可以生成细节不同但具有同等教育价值的类似数学问题。
研究表明,大规模语言模型可以从上下文中看到的原始示例生成新的示例。对于许多任务来说,生成示例比解决任务更容易。这种方法包括:(1)让"学生 "的大规模语言模型生成新的无标签示例;(2) "教师 "为这些示例贴标签;(3) "学生 "使用这些标签解决原始问题。
第三种方法(方法 3)是替换原始示例的实体。学生"不会生成一个全新的示例,而是替换原始示例中的实体,如姓名、地点、数字等。这样,它就生成了一个与原始示例相似的无标签新示例。这种方法还可以生成更大的示例。
大型语言模型在替换实体方面做得相当出色。因此,它指示 "学生 "模型查找并替换私有实体。除了在步骤 (1) 中替换实体外,该方法的整体流程与第二种方法相同。
在查询 "教师 "时,存在泄露私人信息的风险。因此,为了经济地使用 “教师”,我们引入了一个名为 "分组大小 "的超参数。这表示 "学生 "将对多少个私人示例进行分组,以创建扩展大小的 ICL 示例。学生 "结合分组示例的信息,合成新的示例。表示 "教师 "为每个原始示例创建标记示例的预算,即标记预算 = 扩展尺度/分组尺度。学生 "无法选择要分组的示例。
试验
为了评估所提方法的有效性,我们使用不同的数据集对其准确性和隐私性进行了评估,并与两种基线方法进行了比较。
本文使用谷歌提供的双子座 1.0 应变模型。我们使用功能最强大的 Ultra作为 “老师”,Nano-2(3.5B 参数模型,可在移动设备上部署)作为 “学生”。在某些实验中,Pro 被用作 “学生”,因为 "学生 "模型的能力会影响方法的性能。在所有实验中,任务成功率均以 "教师 "的性能为标准,这是基于之前有关 Nano 性能的报告(Google,2023 年)。
为了证明拟议方法的多功能性,我们使用了以下不同的数据集
- GSM8k 数学问题(Cobbe 等人,2021 年)。
- 助理意图检测(Srivastava 等人,2022 年)。
- 主观/客观分类(Conneau & Kiela,2018)。
- 利用中等资源进行机器翻译(Tiedemann,2020 年)。
与基线的比较还包括两种基线:弱基线和强基线。在弱基线中,"学生 "完全不与 "教师 "交流,自己也没有标签数据,因此是零镜头设置。在强基线中,我们评估的是 "学生 "可以访问 8 个任意完美标记示例的情况。这些示例被认为是强基线,因为它们被完美标注,而且与 "学生 "试图解决的任务完全相同。但实际上,这样的数据并不存在,而且也不容易适应 "学生 "的问题。
结果如下表所示。在所有数据集中,建议的方法都优于弱基线和强基线。然而,对于 GSM8k,我们发现需要一个强大的 "学生 "模型,如 Pro。
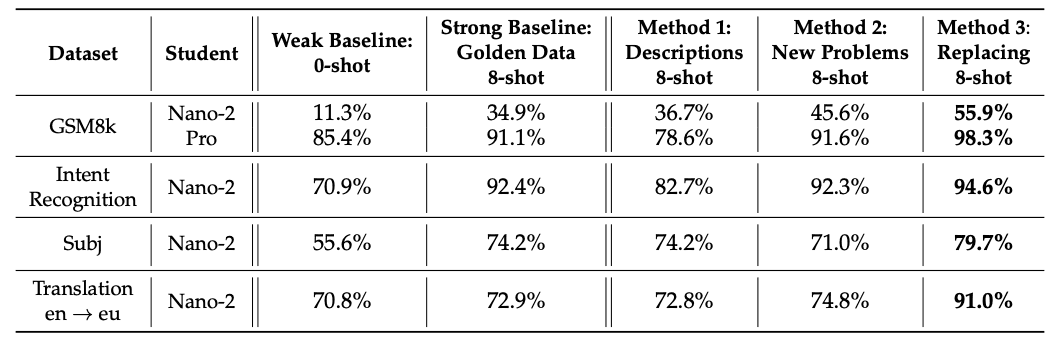
(方法 3)在所有数据集上的表现都非常好。这可能是因为这种方法生成的查询最接近"学生 "试图解决的问题。(方法 1)的表现最差,我们发现这种方法最难发挥作用。例如,对于意图识别等任务,这种方法的竞争力较弱,因为只有在学生模型可以被标记的情况下,这种方法才能明确考虑未标记的示例。
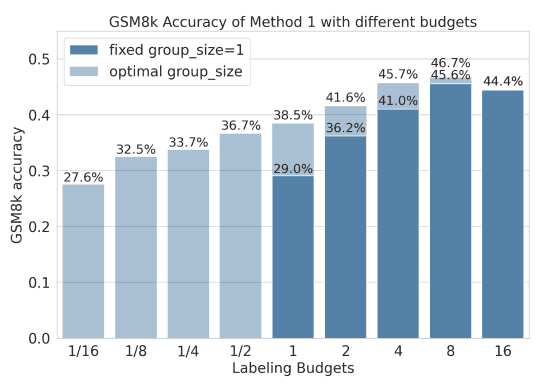
此外,还使用不同的方法进行了全网格搜索,以研究标签预算(扩展大小/组大小)的最佳使用方法。对于每种贴标预算,都能获得最佳性能。如下图所示,选择这些超参数可以使预算小于 1,而如果不分组,预算是不可能小于 1 的。
此外,为了分析所建议的方法在隐私方面的表现,我们计算了两个指标:实体泄漏指标和映射泄漏指标,后者考虑了辅助信息的配置,Gemini 1.0 Ultra 被用作实体检测器和名称、私人实体,如位置、号码等。为了确保它能可靠地检测到所需的实体,我们对一部分示例进行了人工验证。分析结果如下表所示。

据观察,(方法 1)泄露的实体最多。虽然这种方法理论上应产生最高级别的查询,但在实践中却很难奏效。在原始示例的子集中,"学生 "可能无法合成高层次的解释,转而详细解释所面临的问题。另一方面,(方法 3)中的查询最接近原始信息,但泄露的实体最少。这可能是因为 "学生 "可以在没有充分理解问题的情况下找到并替换实体。
然而,在分析映射指标(表示攻击者利用辅助信息识别原始示例的能力)时,结果却有所不同。在这一指标上,(方法 3)明显逊色。虽然这种方法泄露的实体较少,但它保留了结构和风格,因此特别容易在原始示例和生成示例之间进行映射。在结构清晰的 GSM8k 和 Subj 数据集上尤其如此。
研究发现,分组示例与(方法 2)配合使用效果特别好。在分组大小 = 2 的情况下,两个指标的泄漏率都显著降低,这在 GSM8k 中可以实现而不会降低性能。
最后,应该指出的是,选择适当的方法取决于具体的威胁模型。虽然(方法 1)在质量和私密性方面并不令人信服,但(方法 3)在不包含辅助信息的威胁模型中却非常有效。另一方面,当考虑到辅助信息时,(方法 2)最为合适。
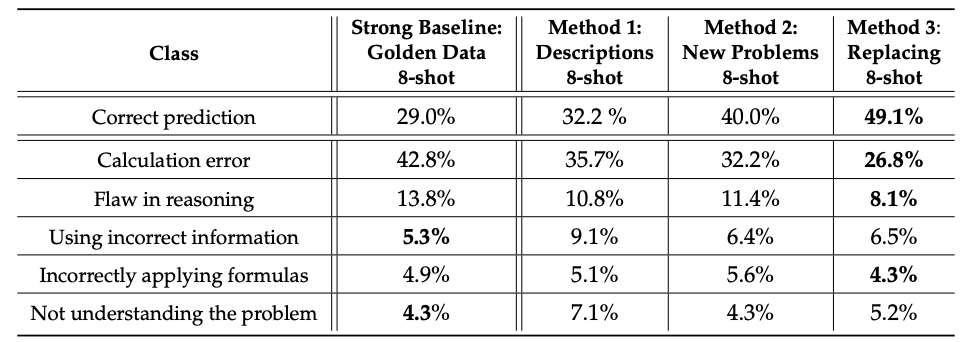
为了更好地理解所提出的方法在哪些方面行之有效,在哪些方面存在不足,我们还对 "学生 "模型在接受 "教师 "帮助后所能做出的预测进行了详细分析。为了进行大规模分析,我们要求Gemini 1.0 Ultra 查看黄金标签和"学生"预测,并将错误划分为特定类别。对一些案例的人工检查证实了这些分类是有效的。下表显示了基于强基线和每种方法的最佳设置对 500 个 GSM8k 案例的分析结果。
总结
本文研究了大规模语言模型能否向外部大规模语言模型发送保护隐私的查询并提高其性能。结果表明,所提出的方法明显优于有隐私限制的强基线方法。
我们使用了两个指标来评估所提出方法的隐私性能:一个是计算受损实体数量的简单指标,另一个是衡量拥有辅助信息的 "教师 "能从 "学生 "的查询中恢复多少信息的新指标。第一个指标发现,掩盖问题的方法是有效的,而当 "教师 "拥有辅助信息时,生成新问题的方法是有效的。
最终,选择哪种方法取决于具体的威胁模型。然而,对于这两种威胁模型,所提出的方法都显示出较低的泄漏率,并且优于强质量基线。此外,对样本进行分组还能提高隐私度量,这证明即使在特定的标签预算限制下,模型的质量也能得到提高。
预计未来的研究将考虑更复杂的 "学生 "和 "教师 "互动,进一步改进隐私指标,并关注文本以外的其他模式。
注:
论文地址:https://arxiv.org/abs/2404.01041