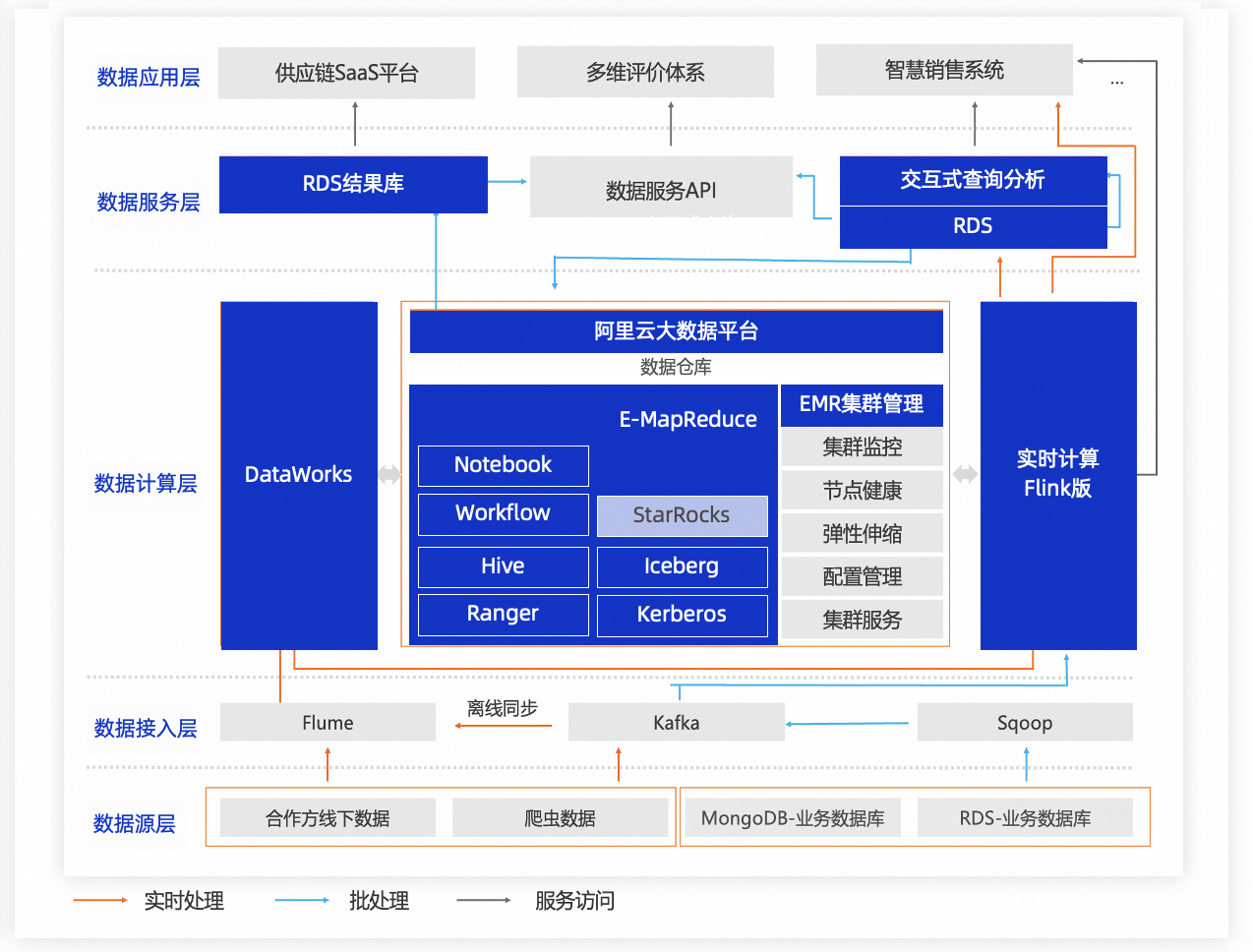
前言
今天10.23日,明天1024则将作为长沙程序员代表,在CSDN和长沙相关部门举办的1024程序员节开幕式上发言,欢迎广大开发者来长工作 生活 考察 创业,包括我司七月也一直在招聘大模型与机器人开发人员

后天,则将和相关开发同事出发去南京,因为我司于本周末10.25/10.26,在南京将举办「大模型机器人(具身智能)线下营」
该「机器人线下营」群内一学员提到:学umi这个成本好高,一套配下3万不知道够不够
- 实话讲,搞机器人成本确实是比较大的,包括umi这套,在机械臂的迁移上 灵活度不太高,换个机械臂不是很顺畅
但有一些工作 可以提高umi在机械臂上迁移的灵活度,比如fastumi,此外,dexcap的在机械臂上的可迁移性 更高些 - 不过,相比起来,工业协作机器人还只是机械臂,人形成本更高,我最近一直在看各种人形paper,很多工作都想尝试,但有些系统开源了 但代码不全,而且不同的工作 换个人形 还不一定好work
正因为这里面的坑比较多,所以我一直在看各家的算法,看看他们是怎么解决一系列落地问题的,毕竟很多问题大家都会遇到
刚好我自己在视频号上看到了iDP3(且友人丁研究员也和我说了这个iDP3),于此便有了本文
PS,考虑到我司七月在线把umi/dexcap搞得差不多了,而iDP3和umi/dexcap有着一脉相承的紧密联系,故我们
- 准备再复现下斯坦福的这个iDP3「24年年底之前先在双臂上跑下斯坦福这个iDP3,然后再在多个人形机器人上 一并验证下」
- 之后再想办法把各个算法整合到一个统一的框架中,欢迎人形厂商、科研机构一块合作搞(有意私我)
第一部分 3D扩散策略DP3
// 待更
第二部分 改进的3D扩散策略iDP3
24年10.14日,来自斯坦福大学、西蒙弗雷泽大学、宾夕法尼亚大学、伊利诺伊大学厄巴纳-香槟分校、卡内基梅隆大学的研究者们(Yanjie Ze1、Zixuan Chen2、Wenhao Wang3、Tianyi Chen3、Xialin He4、Ying Yuan5、Xue Bin Peng2、Jiajun Wu1),提出了改进的3D扩散策略iDP3

- 其对应的论文为《Generalizable Humanoid Manipulation with Improved 3D Diffusion Policies》
- 其对应的项目网址为:humanoid-manipulation.github.io
这是其对应的学习代码:Improved-3D-Diffusion-Policy,这是其对应的遥操作代码:Humanoid-Teleoperation
2.1 iDP3与之前扩散策略、3D扩散策略的不同
2.1.1 视觉运动策略学习
最近,越来越多的趋势是通过端到端方式学习视觉运动策略来解决机器人问题[12],[17-3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations],[25]–[28],其中主要有两种途径:
- 模仿学习[12,即Diffusion policy],[15]–[21],[29]–[34]


- sim-to-real 的强化学习[35]–[44],其中第41篇所述的UMI on Legs,详见此文第一部分

在此之前
- 基于图像的模仿学习方法,例如Diffusion Policy[12],已经取得了显著的成功[10], [17], [22],[30], [45],但其有限的泛化能力限制了它们在复杂真实环境中的应用
- 最近的一些工作旨在解决这些限制[17], [22], [45]–[47]。其中,3D扩散策略(DP3,[17])展示了显著的泛化能力和在多样化机器人任务中的广泛适用性[10], [11],[22], [23]
尽管如此,3D视觉运动策略本质上依赖于精确的相机校准和细粒度的点云分割[17], [18], [21], [39], [47],这限制了它们在类人机器人等移动平台上的部署 - 另与iDP3类似的工作也有一些,比如Maniwhere [37]通过大规模模拟数据实现了真实场景的泛化。然而,由于显著的模拟到现实的差距,他们仅展示了在未见过的场景中推送等任务,而不是像拾取和放置这样的富含接触的任务
机器人实用模型[48-Transic: Sim-toreal policy transfer by learning from online correction]也通过模仿学习将技能泛化到新环境中,而他们必须使用从20个场景收集的数据进行场景泛化,相比之下iDP3只使用1个场景
此外,VISTA [47]使用视图合成模型展示了令人印象深刻的视图泛化。与他们复杂的流程相比,iDP3的自我中心3D表示自然地实现了稳健的视图不变性
2.1.2 iDP3所在系统的概述
iDP3所在的系统主要由四个部分组成:人形机器人平台、数据收集系统、视觉运动策略学习方法、现实世界的部署,如下图所示

在学习部分,作者开发了改进的3D扩散策略(iDP3)作为通用机器人的视觉运动策略
2.1.3 iDP3是如何对3D扩散策略做改进的
3D扩散策略(DP3,[17])是一种有效的3D视觉-运动策略,将稀疏点云表示与扩散策略相结合。尽管DP3在广泛的操作任务中展示了令人印象深刻的结果,但由于其固有依赖于精确的相机校准和细致的点云分割,无法直接部署在通用机器人上,如类人机器人或移动操作器
此外,为在更复杂的任务中有效执行,DP3的准确性需要进一步提高
最终作者改进的算法被称为改进的3D扩散策略(iDP3),其重点做了以下改进
- 以自我为中心的3D视觉表示
DP3利用世界坐标系中的3D视觉表示,便于目标对象的分割[17],[53]。然而,对于类人机器人等通用机器人,相机安装位置并不固定,使得相机校准和点云分割变得不切实际
为了解决这个问题,作者提出直接使用相机坐标系中的3D表示,如下图所示
作者将这类3D表示称为以自我为中心的3D视觉表示
- 扩展视觉输入
利用以自我为中心的3D视觉表示在消除多余点云(如背景或桌面)时存在挑战,特别是在不依赖基础模型的情况下
为此,作者提出了一种简单但有效的解决方案:扩展视觉输入。与之前的系统[17],[22],[53]中使用标准稀疏点采样不同,他们显著增加了样本点的数量以捕获整个图像场景 - 改进的视觉编码器
作者将DP3中的MLP视觉编码器替换为金字塔卷积编码器
因为他们发现,在从人类数据中学习时,卷积层比全连接层产生更平滑的行为,并且结合来自不同层的金字塔特征进一步提高了准确性 - 更长的预测视野。人类专家的抖动和噪声传感器在从人类示范中学习时表现出很大的困难,这导致DP3在短期预测上遇到困难。通过延长预测视野,作者有效地缓解了这个问题
- 实现细节
对于优化,他们使用AdamW [55]训练iDP3和所有其他方法,总计300个epoch
对于扩散过程,他们使用DDIM [56]进行50个训练步骤和10个推理步骤
对于点云采样,他们用体素采样和均匀采样的级联替换DP3 [17]中使用的最远点采样(FPS)「For the point cloud sampling, we replace farthest point sampling (FPS) used inDP3 [17] with a cascade of voxel sampling and uniform sampling」,这确保了采样点覆盖3D空间并具有更快的推理速度
2.2 iDP3相关的硬件配置、数据采集、学习与部署
2.2.1 人形机器人相关的硬件配置
- 在人形机器人的选择上,他们使用Fourier GR1 [5],这是一款全尺寸人形机器人,配备了两个InspireHands [57]
不过,他们只启用了整个上半身{头部、腰部、手臂、手},总共25个自由度(DoF),然后禁用了下半身以保持稳定,并使用推车进行移动 - 激光雷达相机
为了捕捉高质量的3D点云,他们使用了RealSense L515 [58],这是一款固态激光雷达相机。相机安装在机器人头部以提供自我中心视觉
先前的研究表明,深度感知精度较低的相机,如RealSense D435 [59],可能导致DP3 [17], [60]的性能不佳
然而,需要注意的是,即使是RealSense L515也无法产生完全精确的点云 - 高度可调推车
将操作技能推广到现实世界环境的一个主要挑战是场景条件的广泛变化,特别是桌面高度的不同。为了解决这个问题,作者使用了一个高度可调的推车,消除了对复杂全身控制的需求
2.2.2 数据采集
- 为了遥操作机器人的上半身,作者采用了Apple Vision Pro(简称AVP,[61]),该设备能够精确跟踪人手、手腕和头部的姿态[62]。机器人使用Relaxed IK [63]来准确地跟随这些姿态
且他们还将机器人的视觉流回传至AVP。与[9]不同,我们将腰部纳入了遥操作流程,从而实现了更灵活的工作空间 - 遥操作的延迟
使用LiDAR传感器会显著占用机载计算机的带宽/CPU,导致遥操作延迟大约为0.5秒。他们还尝试了两个LiDAR传感器(一个额外安装在手腕上),这引入了极高的延迟,因此使得数据收集变得不可行 - 对于用于学习的数据。在遥操作过程中,他们收集了观察-动作对的轨迹,其中观察由两部分组成:
1)视觉数据,如点云和图像
以及2)本体感觉数据,如机器人关节位置。动作由目标关节位置表示。且他们还尝试使用末端执行器姿态作为本体感觉/动作,发现性能没有显著差异
2.2.3 学习与部署
最终,他们在收集的人类演示数据上训练 iDP3
值得注意的是,由于不依赖之前提到的相机校准或手动点云分割。因此,他们认为他们的iDP3策略可以无缝转移到新场景,而无需额外的校准/分割等工作
2.3 实验效果及与各个相似策略的对比
在测试中,让机器人完成下图所示的三个任务:拾取/放置、倒水和擦拭

2.3.1 iDP3与几个的基线的比较
作者将iDP3与几个强大的基线进行比较,包括:
- DP:带有ResNet18编码器的扩散策略[12];
- DP(❄R3M):带有冻结R3M [64]编码器的扩散策略;
- DP (✶R3M):带有微调R3M编码器的扩散策略
- iDP3 (DP3编码器):使用DP3编码器[12]的iDP3
所有基于图像的方法都使用与iDP3相同的策略骨干,并采用随机裁剪和颜色抖动增强来提高鲁棒性和泛化能力,且RGB图像的分辨率是224×224(从RealSense相机的原始图像调整而来)
如下表所示「在四种设置下训练Pick&Place任务:{1st-1, 1st-2, 3rd-1, 3rd-2}。“1st”使用自我中心视角,而“3rd”使用第三人称视角。后面的数字表示用于训练的示范次数,每个示范由20轮成功执行组成,比如1st-2中的2 即代表示范次数为40次」

- iDP3显著优于普通DP、带冻结R3M编码器的DP以及带DP3编码器的iDP3
- 然而,我们发现带微调R3M的DP是一个特别强的基线,在这些设置中优于iDP3。作者认为这是因为微调预训练模型通常比从头开始训练更有效[26],而目前没有类似的用于机器人技术的预训练3D视觉模型。尽管DP+微调R3M在这些设置中更有效,但作者发现基于图像的方法过拟合于特定场景和对象,无法推广到一些比较极端的场景之下
作者在论文中表示,他们还进行了 iDP3 与 DP (✶R3M)(简称为 DP)之间的更多比较,并证明 iDP3 在具有挑战性和复杂性的现实世界中更具适用性
具体如下表所示
iDP3和DP在训练环境中对训练对象都取得了很高的成功率,并具备以下三个更好的属性
- 属性1:视图不变性View Invariance
iDP3的自我中心3D表示展示了令人印象深刻的视图不变性
如下图所示iDP3即使在视图发生较大变化时也能始终抓取物体,而DP即使是训练对象也难以抓取。DP仅在视图发生轻微变化时偶尔取得成功
值得注意的是,与最近的工作[22],[45],[47]不同,他们没有采用特定的设计来实现等变性或不变性- 属性2:对象泛化性
他们评估了训练杯之外的新型杯子/瓶子,如下图所示由于使用了颜色抖动增强,DP偶尔可以处理未见过的对象,但成功率很低。相比之下,iDP3由于使用了3D表示,自然能够处理广泛的对象
- 属性3:场景泛化性
他们进一步在各种真实世界场景中部署了iDP3的策略,如下图所示




2.3.2 iDP3的几个消融研究
最后,作者对DP3的几项修改进行了消融研究,包括改进的视觉编码器、缩放的视觉输入和更长的预测范围
实验表明如果没有这些修改,DP3要么无法有效地从人类数据中学习,要么表现出显著降低的准确性
更具体地说,他们观察到
- 他们改进的视觉编码器可以同时提高策略的平滑度和准确性

- 缩放视觉输入是有帮助的,但在他们的任务中更多的点数会使性能饱和(while the performance gets saturated in our tasks with more points)

- 一个合适的预测时间范围是关键,如果没有这个,DP3无法从人类演示中学习

最后论文中提到,iDP3的训练时间,与DiffusionPolicy相比,显示出显著的减少。这种效率即使在点云数量增加到DP3的几倍时仍然保持
第三部分 iDP3的源码解析
// 待更