文章目录
- 一、位图
- 1.基本概念
- 2.基本实现
- 3.基本应用
- 3.1 找100亿个整数只出现一次的数
- 3.2 两个文件分别有100亿整数,1G内存,求交集
- 二、布隆过滤器
- 1、基本实现
- 2、基本应用
- 2.1过滤一部分的数据
- 2.2 两个文件,分别100亿个查询,1G内存,精确求文件交集
- 2.3给一个超过100G大小的文件 其中存着IP地址, 找到出现次数最多的IP地址
- 总结
一、位图
1.基本概念
假如要给你几万个整形数据判断在不在,想必你一定会用哈希,但是如果给你40亿个整形数据,限制运行内存为16GB,然后再判断在不在,不知阁下当如何应对?
首先,我们先来分析一下问题,40亿个整形数据,为160亿个字节,又因为10亿个字节,大概为1GB,由此可换算为16GB,到这你可会觉得刚好,好继续分析如果采用哈希或者红黑树,哈希表要开的数据一定比16GB还要大,如果红黑树还有指针的信息,也比16GB要大,那么有没有什么方法呢?
- 分析在不在只需用1个比特位即可表示。
2.基本实现
#include<vector>
using namespace std;
namespace MY_STL
{template<size_t N>class bitset{public:bitset(){//N——数据,换算成比特int size = N / 32 + 1;//向上取整_bit.resize(size,0);}void set(size_t n){//求出所在第pos个整形位置int pos = n / 32;//求出在第pos位置的num位数.int num = n % 32;//对pos位置的num位变1(或操作)_bit[pos] |= (1 << num);}void reset(size_t n){//求出所在第pos个整形位置int pos = n / 32;//求出在第pos位置的num位数.int num = n % 32;//将pos个整形的num位变0,其它位置不变。_bit[pos] &= ~(1 << num);}bool test(size_t n){//求出所在第pos个整形位置int pos = n / 32;//求出在第pos位置的num位数.int num = n % 32;return _bit[pos] & (1 << num);//只要指定是0,就为假,非0为真。}private:vector<int> _bit;};
}
3.基本应用
3.1 找100亿个整数只出现一次的数
- 思路:两个位图,组合起来,01表示只出现一次,00表示出现两次,10表示出现两次及以上。
基本实现:
template<size_t N>class TwoBitSet{public:void set(size_t n){//01表示出现一次if (!_bit1.test(n) && _bit2.test(n)){//改成10_bit1.set(n), _bit2.reset(n);}//00表示出现0次else if (!_bit1.test(n) && !_bit2.test(n)){_bit2.set(n);}//出现两次以上不用改。}bool is_once(size_t n){//01表示出现一次。return !_bit1.test(n) && _bit2.test(n);}private:bitset<N> _bit1;bitset<N> _bit2;};
测试代码:
void TwoBitSet()
{MY_STL::TwoBitSet<-1> twobits;//-1表示无符号的最大整数。int arr[] = { 1,1,2,2,3,4,5,7,5,7,8,0,8,0 };for (auto e : arr){twobits.set(e);}for (auto e : arr){if (twobits.is_once(e)){cout << e << " ";}}
}
3.2 两个文件分别有100亿整数,1G内存,求交集
- 思路:两个数求交集,要先在bitset里面去重,然后一个一个数据进行比对,如果两个数都存在,则是交集的数字。
测试代码:
void BitTest1()
{MY_STL::bitset<300> bit1;MY_STL::bitset<300> bit2;int arr1[] = { 1,1,2,3,4,5,7,8,9,10 };int arr2[] = { 4,5,7,11,23,45,23,254,231 };for (auto e : arr1){bit1.set(e);}for (auto e : arr2){bit2.set(e);}vector<int> same;for (size_t i = 0; i < 251; i++){if (bit1.test(i) && bit2.test(i)){same.push_back(i);}}for (auto e : same){cout << e << " ";}
}
二、布隆过滤器
当转换为字符串时,进行哈希处理,难免就会产生冲突,通过之前的学习,我们可以从中了解到,冲突是无法避免的,只能尽可能的减少,布隆过滤器就是用来处理海量数据(一般情况下为字符串),减少冲突的。
如何尽可能的减少冲突呢?
源自于一个布隆的人,最开始想要避免冲突,最后发现是不可能实现的,转而想到如何尽可能的减少冲突,最后想到了既然冲突是由一个哈希函数产生的,那我多用几个哈希函数,同时处理,然后进行查找,如果有一个不在的话,这就说明不存在,这个结果是一定准确的,如果都在的话,说明存在,但结果不一定准确。
既然是多弄几种哈希函数这不简单,找几个现成的字符串哈希我们实现一波。
字符串哈希冲突算法
1、基本实现
namespace MY_STL
{struct BKDRHash{size_t operator()(const string& str){size_t hash = 0;for (auto ch : str){hash = hash * 131 + ch;}return hash;}};struct APHash{size_t operator()(const string& str){register size_t hash = 0;size_t ch;for (long i = 0; i < str.size(); i++){size_t ch = str[i];if ((i & 1) == 0){hash ^= ((hash << 7) ^ ch ^ (hash >> 3));}else{hash ^= (~((hash << 11) ^ ch ^ (hash >> 5)));}}return hash;}};struct SDBMHash{size_t operator()(const string& str){register size_t hash = 0;for (auto ch : str){hash = 65599 * hash + ch;}return hash;}};template<size_t N,class T,class Hash1 = BKDRHash,class Hash2 = APHash,class Hash3 = SDBMHash>class BloomFilter{public:void set(const T& data){size_t hash1 = Hash1()(data) % N;size_t hash2 = Hash2()(data) % N;size_t hash3 = Hash3()(data) % N;_bit.set(hash1);_bit.set(hash2);_bit.set(hash3);}bool test(const T& data){size_t hash1 = Hash1()(data) % N;size_t hash2 = Hash2()(data) % N;size_t hash3 = Hash3()(data) % N;if (!_bit.test(hash1) || !_bit.test(hash2) || !_bit.test(hash3))return false;return true;}private:bitset<N> _bit;};
}
说明:这里并没有写reset,也就是删除函数,原因很简单,因为一旦删除,那就会影响其它的值的查找。
拓展:如何选择适合的哈希长度?
- 这里给出一个由实验得出的公式。
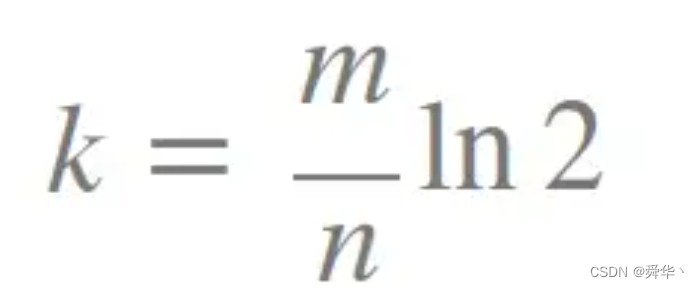
- k 为哈希函数个数,m 为布隆过滤器长度,n 为插入的元素个数,ln2约等于0.963
2、基本应用
2.1过滤一部分的数据
在数据库的查询中会比较慢,这时如果我们能用布隆过滤器查询,如果不在,则直接返回结果即可,如果在,再用数据库进行查询,这样效率会高不少,同时还能减少数据库的负载。
2.2 两个文件,分别100亿个查询,1G内存,精确求文件交集
首先100亿个查询,可以在文件中分成1000个左右的小文件,进行编号,然后再把这100亿个查询通过内存进行哈希再分发到这1000个小文件中,再对另一个文件执行同样的操作,最后两个文件的数据依次进行求交集,但是这样会涉及一个问题,首先哈希冲突如果大量聚集,就会导致某一个文件很大,这就要讨论两个问题,哈希冲突可能是由相同的数据产生的,如何判断这种情况呢?其实用set进行判断,把这个文件读到set里面,如果set没有抛异常,说明是由大量相同数据产生的,可以直接读到内存中,如果set抛异常了,说明不是有相同数据产生的,此时我们还要再把这个文件再进行分,比如再分成20份,再换一个哈希函数,再进行读。
2.3给一个超过100G大小的文件 其中存着IP地址, 找到出现次数最多的IP地址
利用上面一题的思路,对文件进行切分,然后依次对每一个小文件用map统计次数,保留最多的那一个,依次读取更新出现次数最多的Ip地址即可。
总结
今天的分享到此就结束了,如果有所帮助点个赞鼓励一下吧!
![[Linux入门]---管理者操作系统](https://img-blog.csdnimg.cn/c90fe7bf9c554cf5a6658f48024e91a2.png)