本文转载自:https://fangcaicoding.cn/course/11/58
大家好!我是方才,目前是8人后端研发团队的负责人,拥有6年后端经验&3年团队管理经验,截止目前面试过近200位候选人,主导过单表上10亿、累计上100亿数据量级的业务系统的架构和核心编码。
“学编程,一定要系统化” 是我一直坚持的学习之道。目前正在系统化分享从零到一的全栈编程入门以及项目实战教程。
无论你是编程新手,还是有经验的开发者,我都愿意与你分享我的学习方法、项目实战经验,甚至提供学习路线制定、简历优化、面试技巧等深度交流服务。
我创建了一个编程学习交流群(扫码关注后即可加入),秉持“一群人可以走得更远”的理念,期待与你一起 From Zero To Hero!
茫茫人海,遇见即是缘分!一键三连!方才兄送你ElasticSearch系列知识图谱、前端入门系列知识图谱、系统架构师备考资料!
今天,方才兄以个人最近开源的vue+springBoot前后端分离的博客系统为例,分享下前后端分离的项目的部署流程。
这个部署流程,适用于个人项目。企业级项目,都应是基于镜像,容器化部署的,但运行的原理是一致的。后续方才兄也会补充容器化部署的流程。若对你有帮助,记得一键三连哟!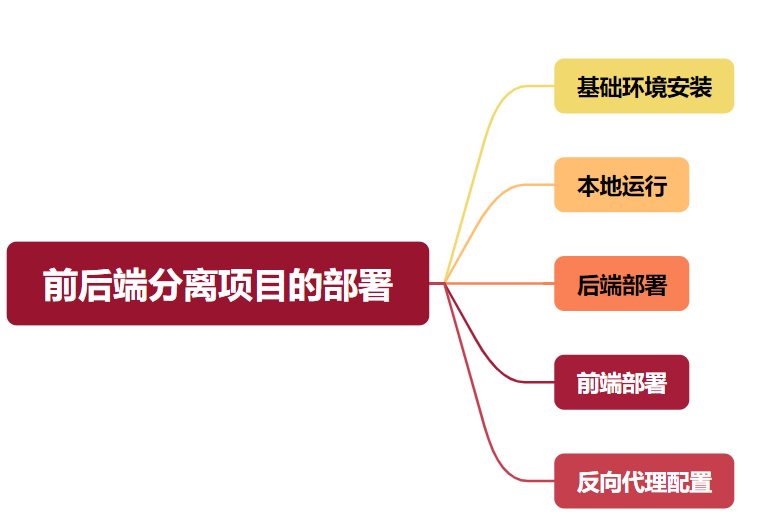
环境安装
jdk环境安装
fangcai-coding-blog是基于jdk21的,所以直接去oracle官网下载对应平台、对应版本的安装包即可(方才兄也下载了一份,需要的伙伴也可以后台回复【jdk】,直接获取,Windows、mac、linux 均提供了)。
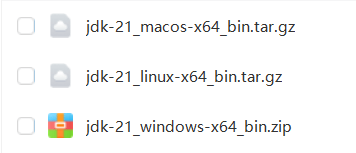
若需要其他版本,直接官方下载:https://www.oracle.com/java/technologies/downloads/#jdk21-windows
考虑大家学习的方便,方才兄这里会提供windows和linux两个操作系统的安装方式
windows环境安装
将
jdk-21_windows-x64_bin.zip安装包复制到你的软件安装目录(注意,不要有中文、空格等字符),解压即可,请记住该安装地址,后面要用到。
直接
windows搜索环境变量,进入环境变量配置页。

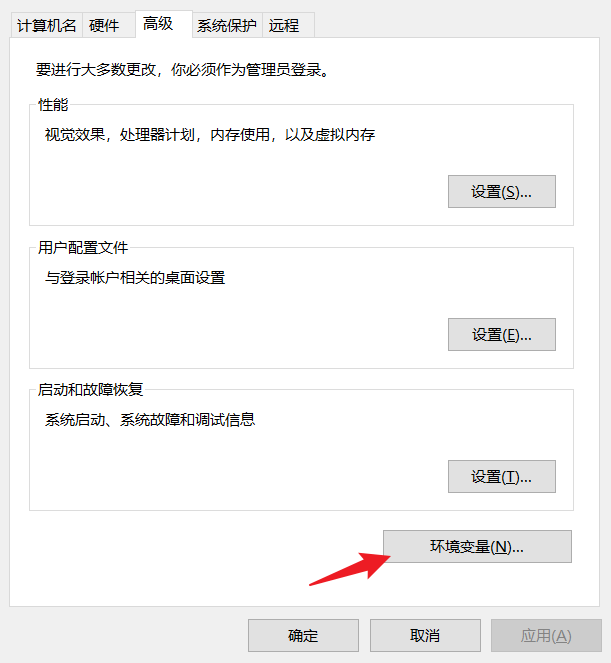
编辑系统变量的
path变量值
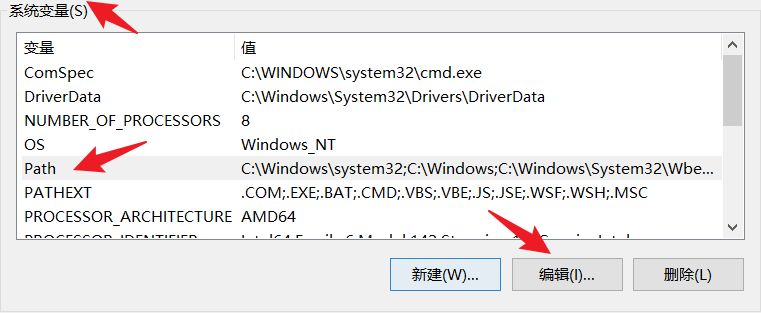
新建环境变量,将刚才
jdk21的安装包下的bin文件夹的全路径复制进来即可(ps:如果安装了多个版本的jdk,谁在上面谁生效)。
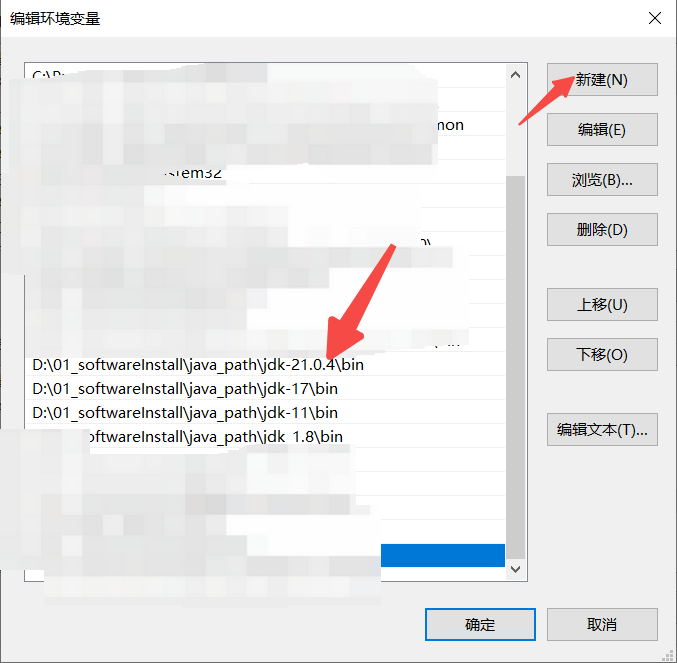
win+R,输入cmd,进入命令框,输入java -version,验证配置是否成功,如图能正常输出即正常了。

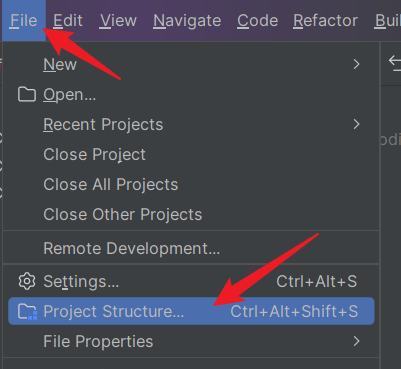
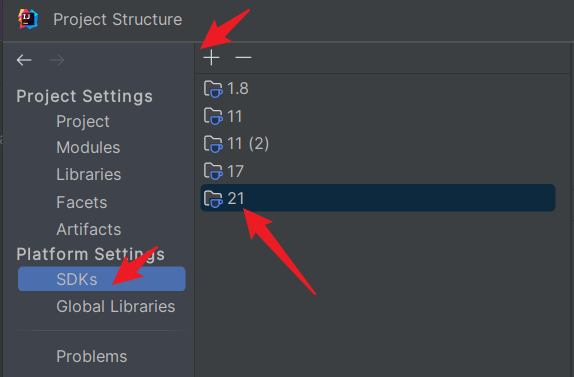
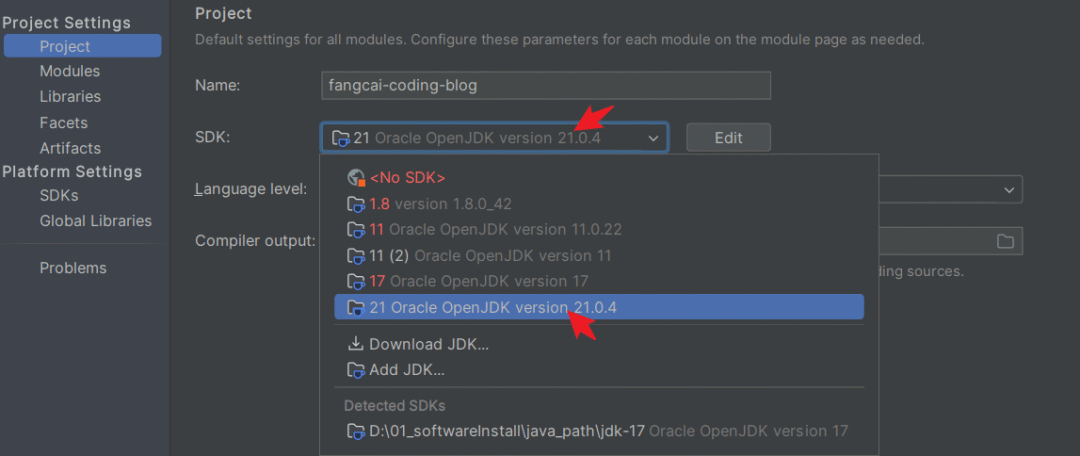
idea配置jdk
idea中,项目的jdk版本指定(这里方才兄就不细说了,简单放两个图):
linux环境安装
方才兄先建设你已经可以通过xshell等远程管理软件,连接上你的linux服务器了【若你不用linux虚拟机的安装或者说对常用的命令不熟悉,推荐阅读:https://fangcaicoding.cn/course/9/1】
进入
linux服务器,cd 到你期望安装的目录下,使用rz命令,将jdk对应的安装包上传到服务器中;

使用
tar -xvf jdk-21_linux-x64_bin.tar.gz解压文件,方才兄这里安装过了,可以使用mv命令给文件夹重命名下,记住该地址。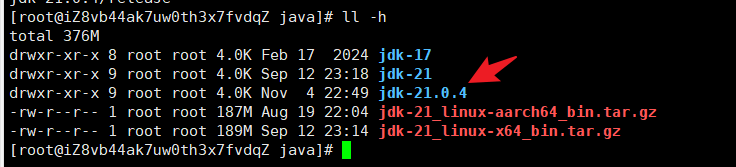
image-20241104225029980 linux系统就没必要去配置环境变量了,如果你只是运行项目的话,方才兄更习惯直接使用安装路径进行使用。但还是简单截图,分享下配置环境变量的过程:
# 编辑文件
vim ~/.bashrc#在文件中添加以下内容。注意 JAVA_HOME 是步骤2你自己的安装位置
export JAVA_HOME=/opt/java/jdk-21
export PATH=$JAVA_HOME/bin:$PATH# 保存文件,使配置生效
source ~/.bashrc
# 最后验证即可
java -version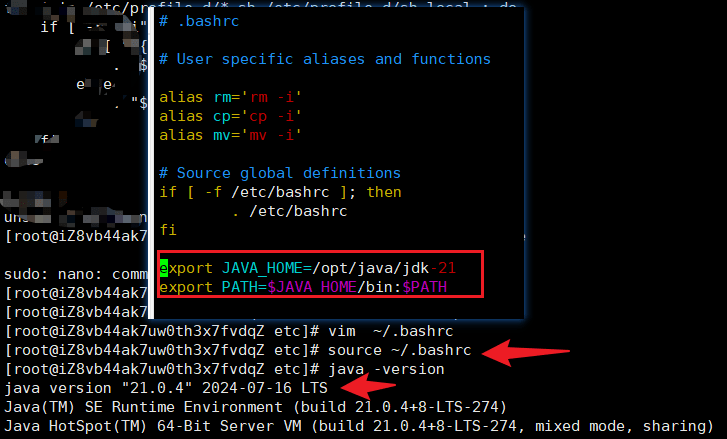
node环境
window环境安装
ps:如果是部署上线,是不需要node环境的,仅用于本地运行需要。
本项目基于node v20.18.0(LTS),建议和方才兄的版本保持一致,防止出现一些奇奇怪怪的问题。(官网下载地址:https://nodejs.org/en/download/prebuilt-installer,也可以直接回复【jdk】获取,方才兄和jdk的依赖一起提供了的。)
以windows环境安装为例:
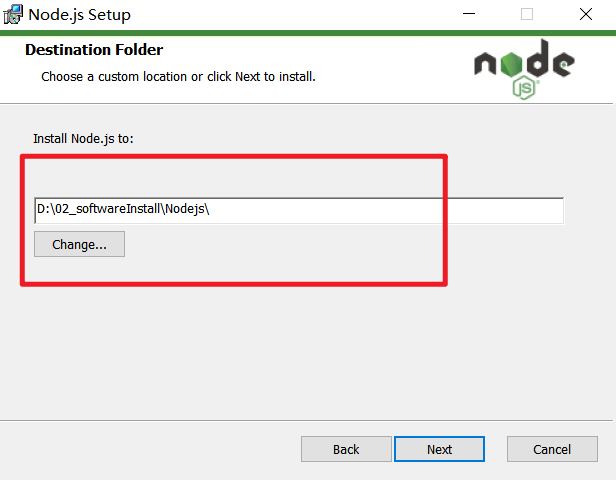
下载好安装包
node-v20.18.0-x64.msi后,直接双击安装即可,建议更改下安装目录,其他配置都不用变更,直接使用默认的即可:
验证安装情况:
C:\Users\moufa>node -v v20.18.0
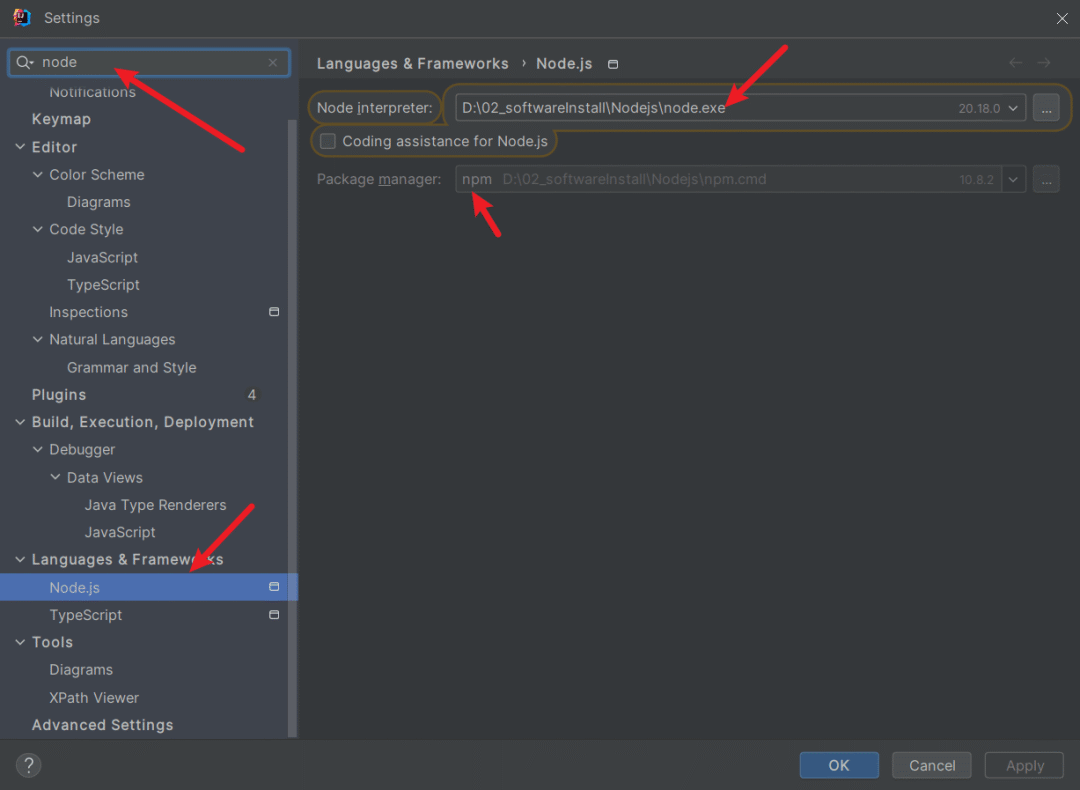
idea配置使用
直接在settings中的配置node即可:
数据库初始化
本站使用的数据库是mysql,建议版本5.7及以上即可:
手动先
create database xx你的DB名称,再use xx你的DB名称;本站的
sql脚本都放在了/upgrade路径下;先复制
init-latest.sql的内容执行,创建数据库表;再复制
init-data.sql的内容执行,初始化角色权限等数据;
本地运行
本站采用的前后端分离架构,所以在本地运行,需要分别启动后端接口和前端vue项目,入口如下:
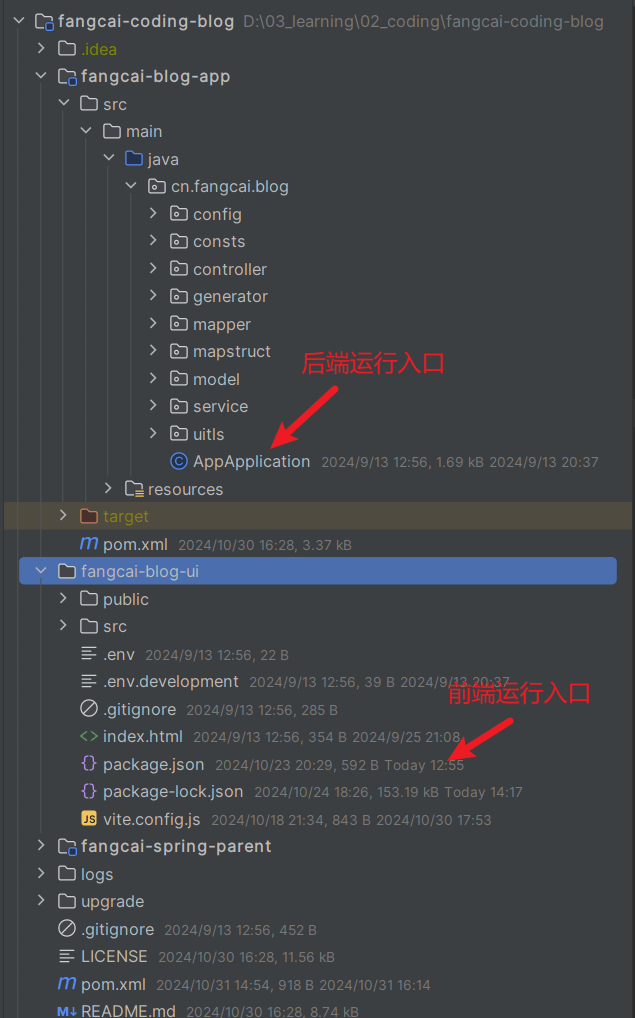
后端运行
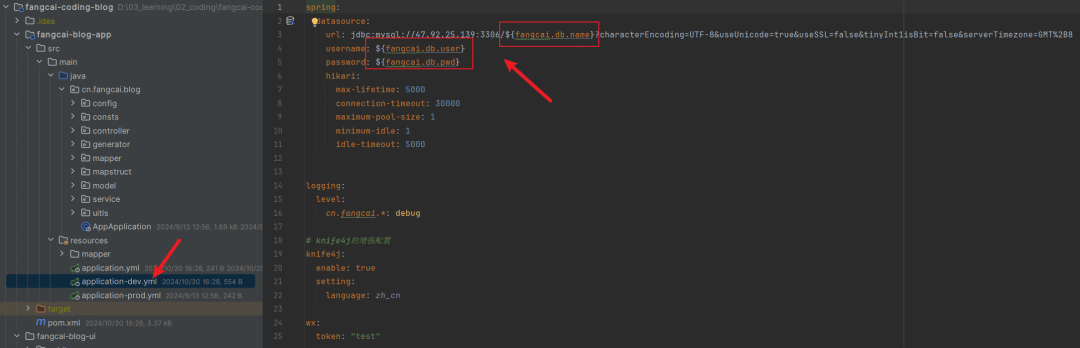
项目默认启动的是
dev环境,需要将数据库的信息修改为你们自己的。
进入启动类
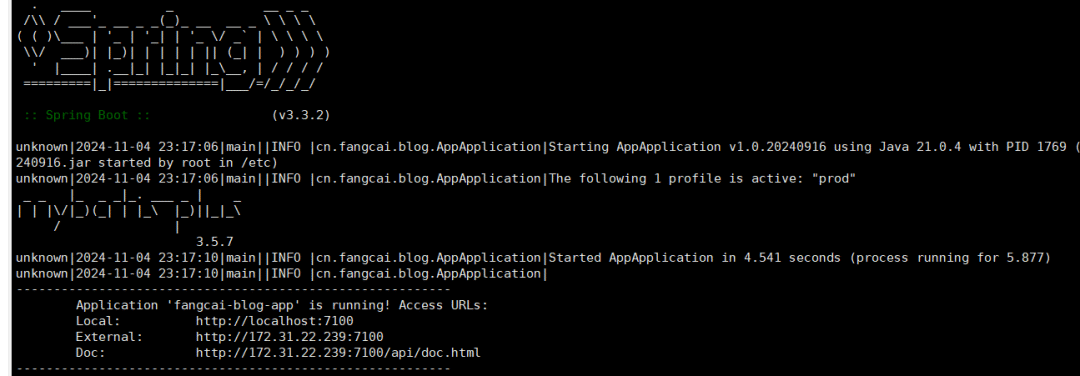
AppApplication运行即可:
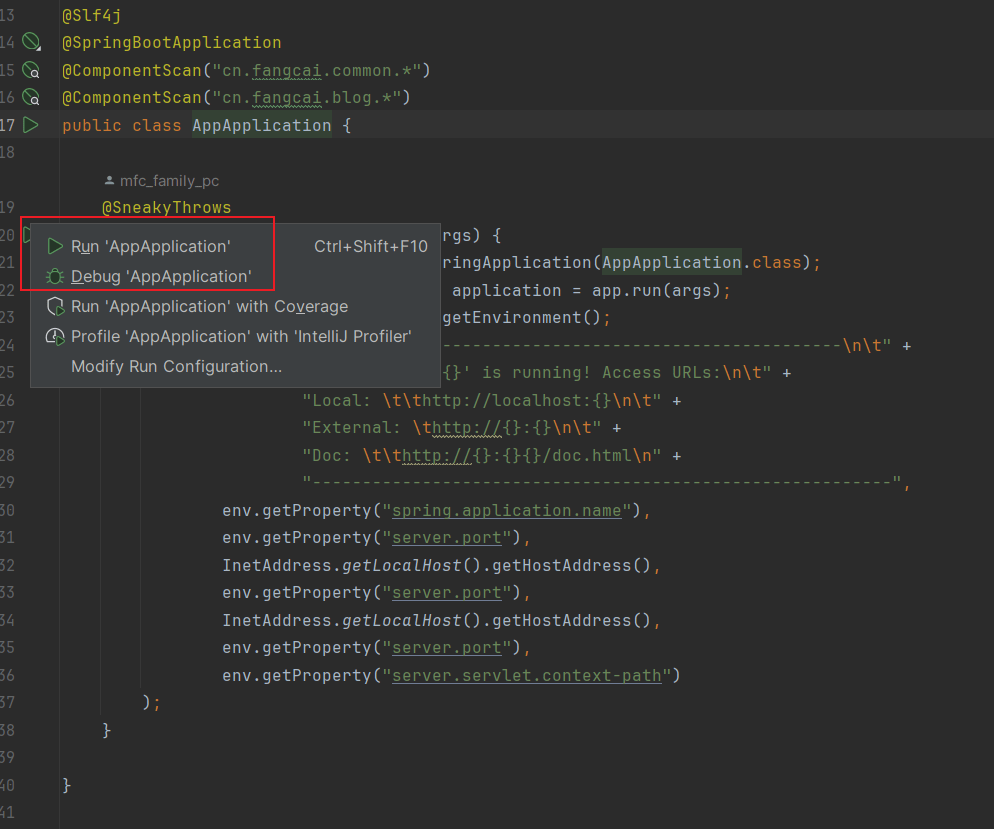
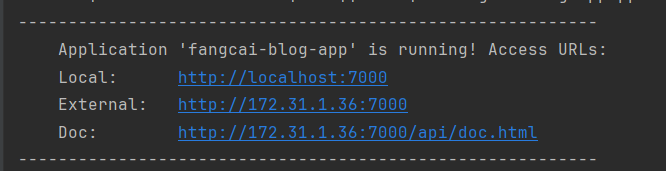
启动成功的效果(ps:Doc 的地址是,在线接口文档地址):
前端运行
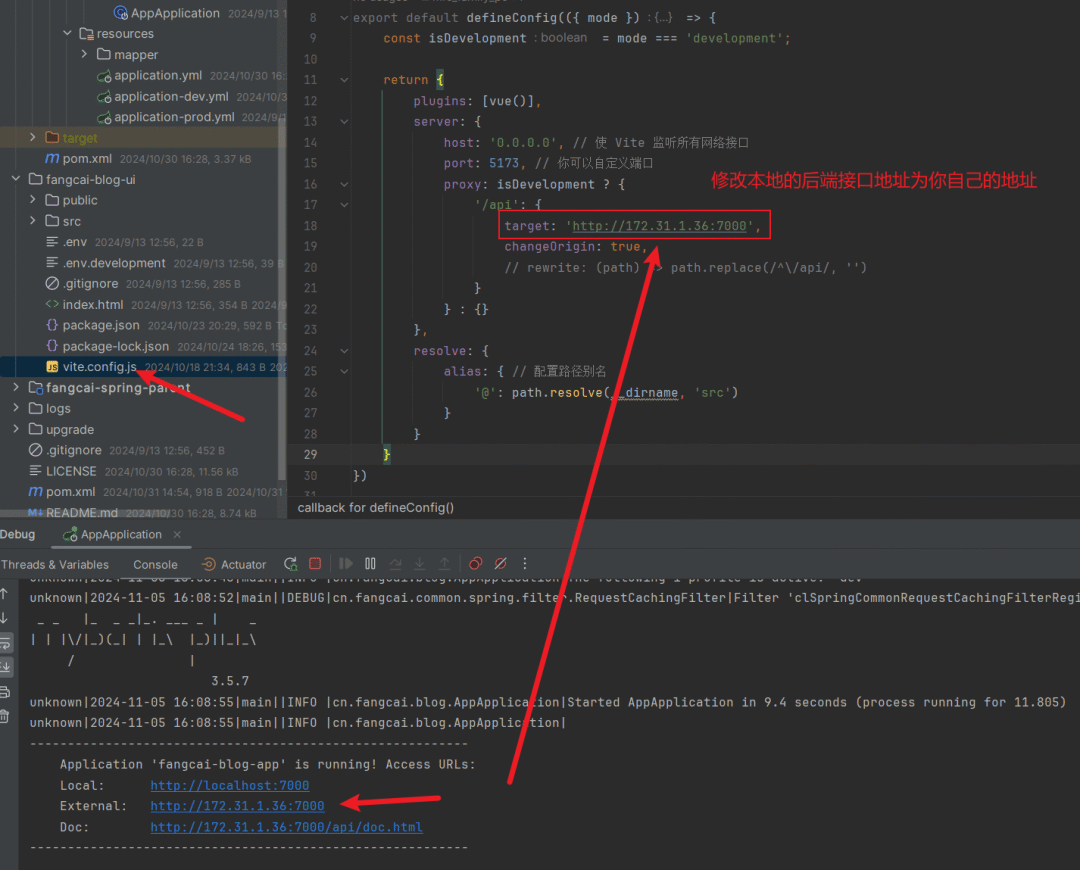
在后端接口服务启动成功后,基于启动信息,去修改前端项目的
vite.config.js中的后端接口的代理地址为实际地址。
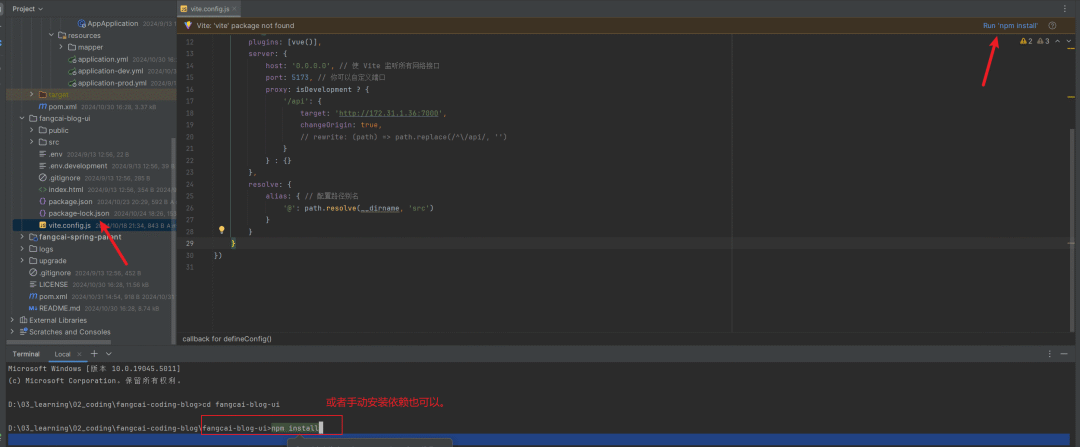
安装前端依赖,打开
fangcai-blog-ui/vite.config.js文件,idea右上角有提示,可直接点击安装或者进入命令行,手动运行npm install,等待安装包安装完成,会自动生成目录fangcai-blog-ui/node_modules:
打开
fangcai-blog-ui/package.json文件,点击dev的启动按钮,或者命令行输入npm run dev:
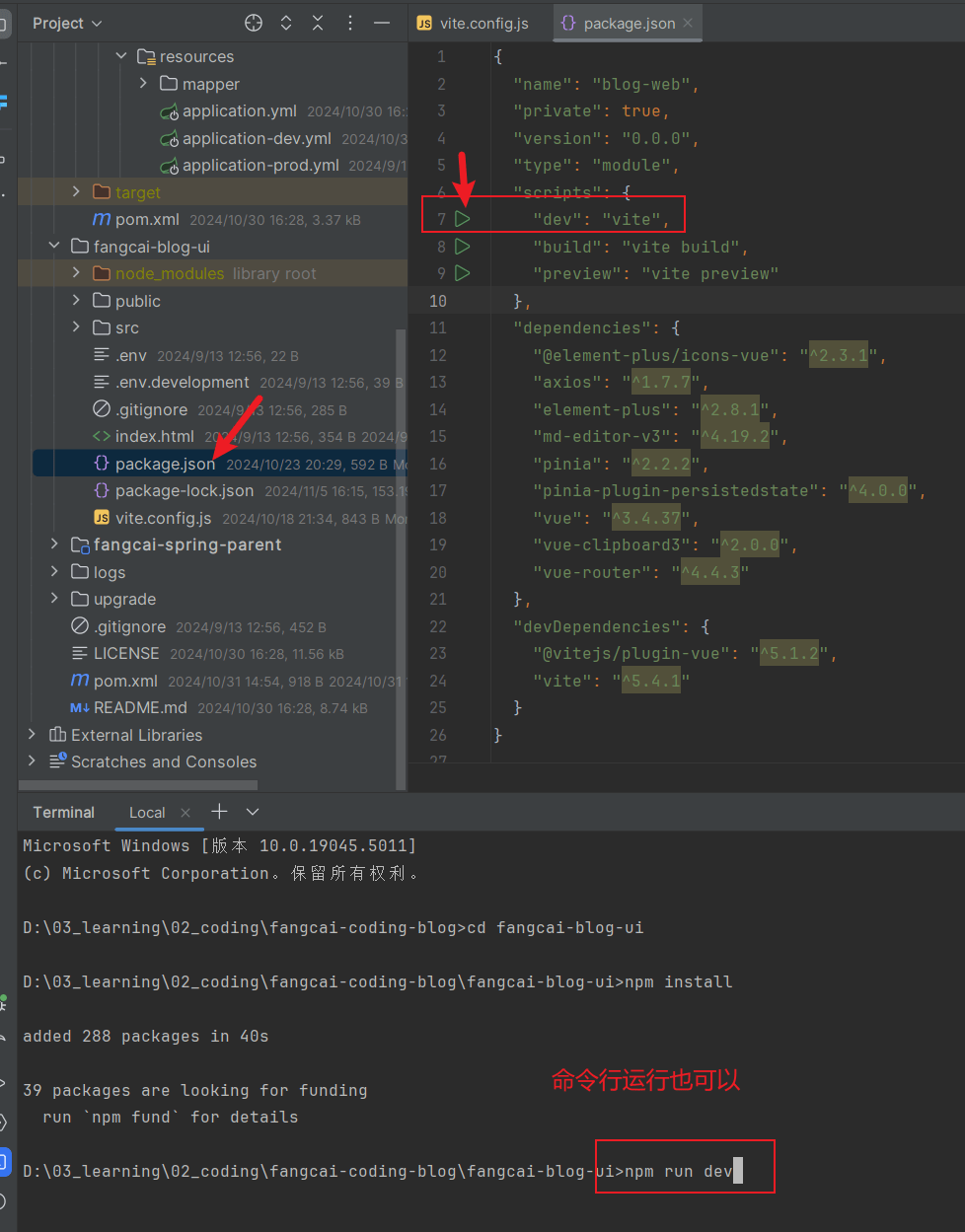
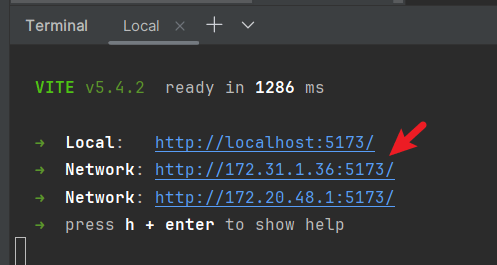
有几个网卡,都有个访问地址,随意访问一个即可:

后端部署
项目打包
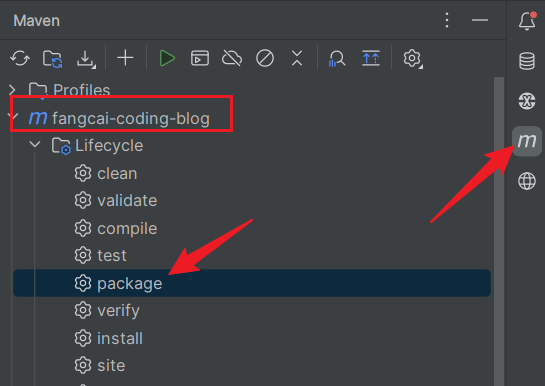
直接使用
maven的package命令,进行打包即可:
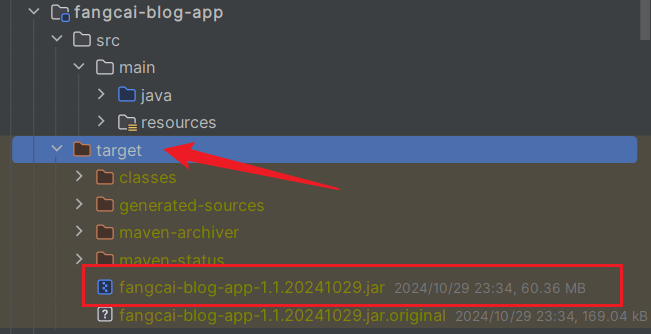
打包完成,会自动生成
target文件夹,下面的xxx.jar就是可执行的运行包
部署至linux服务器
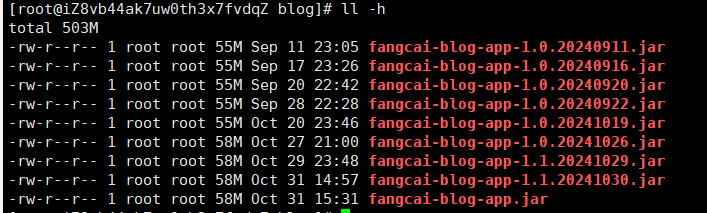
将打包好的
jar包,使用rz命令上传到linux服务器中对应的目录中:
方才兄这里假设你已经安装好了
mysql数据库,并完成了数据库初始化操作。直接使用
java -jar运行jar包:/opt/java/jdk-21/bin/java -jar -Xmx1024M -Xms256M /opt/blog/fangcai-blog-app-1.0.20240916.jar --server.port=7100 --spring.profiles.active=prod --knife4j.enable=true --knife4j.production=true --fangcai.db.name=数据库名 --fangcai.db.user=数据库用户名 --fangcai.db.pwd=数据库密码 --wx.token=微信token可随便给值
线上环境部署
刚才的部署方式,如果你退出会话后,服务器就会自动停止运行,当然可以通过nohup命令后台运行,这也是比较常用的:
nohup /opt/java/jdk-21/bin/java -jar -Xmx1024M -Xms256M /opt/blog/fangcai-blog-app-1.0.20240916.jar --spring.profiles.active=prod --knife4j.enable=true --knife4j.production=true --fangcai.db.name=数据库名 --fangcai.db.user=数据库用户名 --fangcai.db.pwd=数据库密码 --wx.token=微信token可随便给值但如果是线上环境,建议使用systemd启动守护进程【ps:若不了解的,可以百度下,方才兄这里就直接贴脚本,让大家使用了】,实现开机自动启动功能。
使用文本编辑器,如
vim创建并编辑family-app.service文件。vi /etc/systemd/system/fangcai_blog.service写入内容:
[Unit] # 服务名称,可自定义 Description = fangcai_blog.service After = network.target syslog.target Wants = network.target [Service] Type = simple # 启动命令 ExecStart = /opt/java/jdk-21/bin/java -jar -Xmx1024M -Xms256M /opt/blog/fangcai-blog-app-1.0.20240916.jar --spring.profiles.active=prod --knife4j.enable=true --knife4j.production=true --fangcai.db.name=数据库名 --fangcai.db.user=数据库用户名 --fangcai.db.pwd=数据库密码 --wx.token=微信token可随便给值 [Install] WantedBy = multi-user.target使用
systemd命令,管理family-app.service:# 重新加载 systemctl daemon-reload # 配置 开机自启 systemctl enable fangcai_blog # 启动 systemctl start fangcai_blog # 停止 systemctl stop fangcai_blog # 重启 systemctl restart fangcai_blog # 查看运行状态 systemctl status fangcai_blog # 禁止开机启动 systemctl disable fangcai_blog

前端部署
项目打包
直接运行
package.json下的build命令即可:
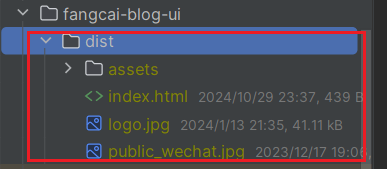
打包完成,会在当前项目路径下自动生成一个
dist的文件夹,整个文件夹都是前端打包的代码。
部署
前端的部署需要有一个web服务器,常用的是nginx,因为方才兄之前部署过halo,就使用了1panel运维面板(用的宝塔也是可以的,都类似),使用的服务器就是OpenResty了。
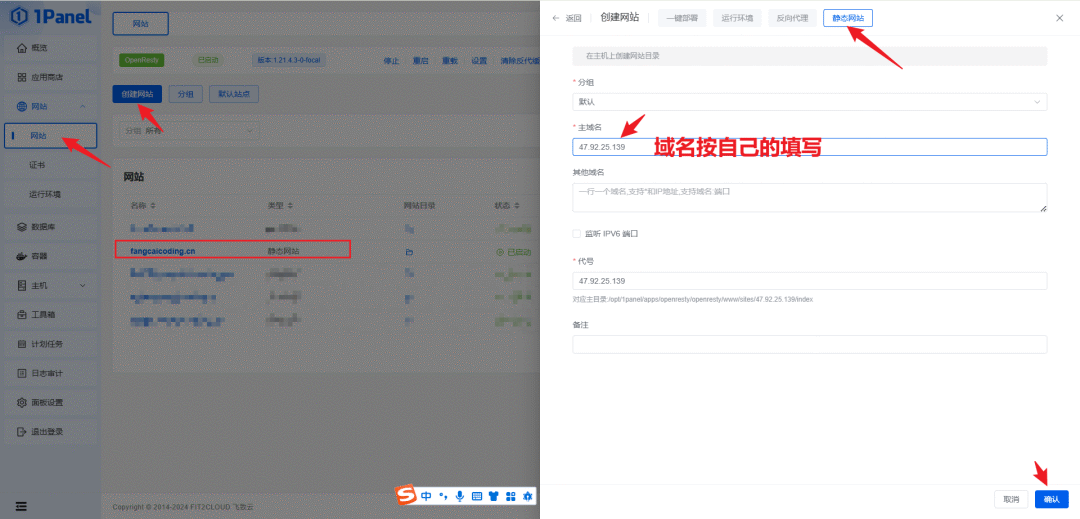
先安装
OpenResty,这个1panel操作很简单,就不截图了。使用
OpenResty创建静态站点,域名这里,有就配置域名,没有也可以直接配置服务器公网ip也是可以的(如果是本地linux机器,配置为私有ip也是可以的)。
进入网站配置,找到网站目录进入:

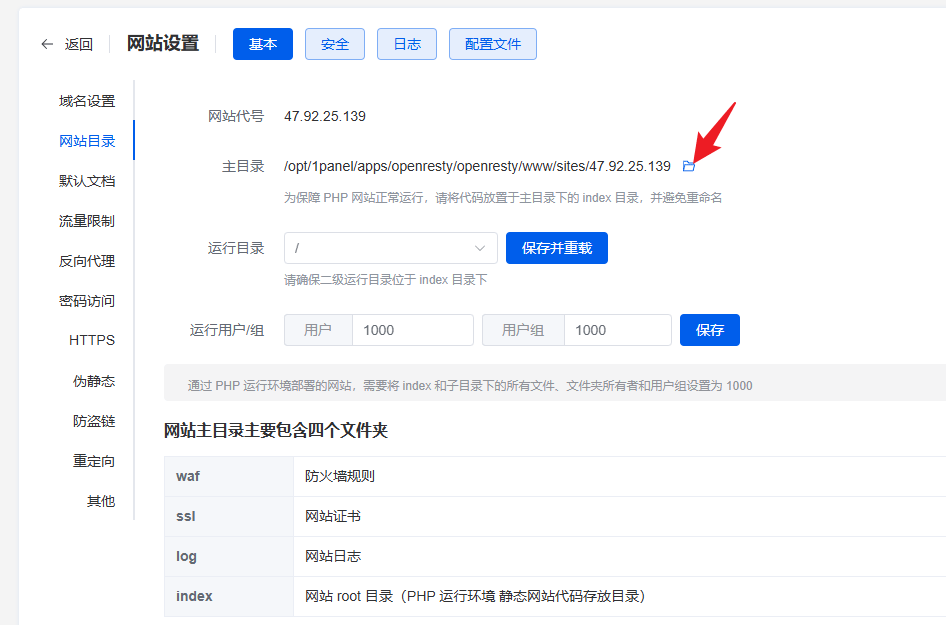
将打包的好的前端文件夹
dist里的内容,上传到网站目录中的index目录下:


访问刚才配置的域名(域名的解析配置和ssl证书配置后续再出教程)或者ip地址,就可以访问了:

反向代理配置
通过前端部署,发现页面是可以访问了,但无法访问后端接口,会报错。这里基于ng或OpenResty的反向代理功能即可。
后端接口代理
进入到网站管理中的 反向代理配置:
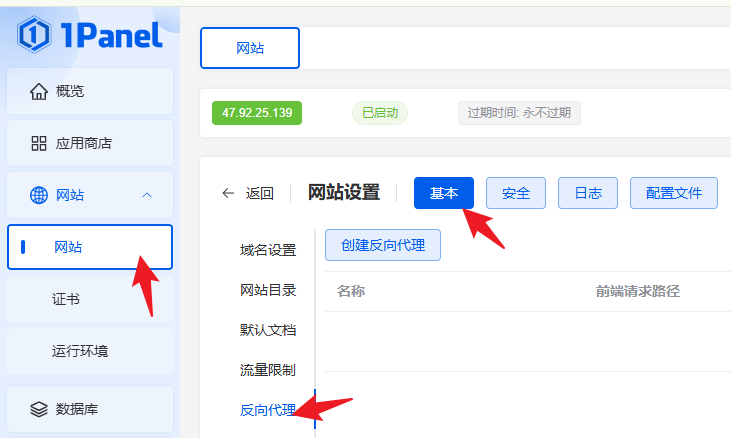
反向代理配置
看效果:

子路径刷新报404的问题
因为本站的前端是基于vue-router实现,首次点击菜单,会经过router处理,能正常访问页面。但刷新网页是,会报404【对比上面的效果截图,都是一样的路径】。
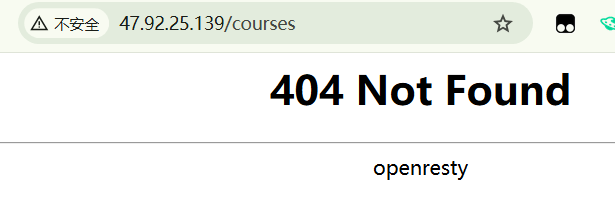
出现这个问题的原因是,Vue Router 在前端是通过 JavaScript 处理的“单页应用”(SPA)。当你在本地启动时,开发服务器(如 Vite)会处理所有的路由请求,即使你刷新页面,它仍然会通过 JavaScript 将请求重定向到正确的 Vue 组件。而当你在 NGINX 上部署时,服务器的行为和本地开发环境不同。
在 NGINX 中,当你直接访问 /courses 并刷新页面时,NGINX 会尝试从服务器的物理路径中找到这个路径对应的文件或目录。因为这是一个 SPA 项目,实际上不存在 /courses 这样的物理路径,服务器就会返回 404 错误。
解决方法:
我们需要在 NGINX 配置中将所有未知的请求(非静态文件请求)都重定向到 index.html,这样 Vue Router 才能够处理这些路径。
在 NGINX 配置中,添加以下配置:
location / {try_files $uri $uri/ /index.html;
}配置说明:
try_files $uri $uri/ /index.html;:NGINX会依次尝试用户请求的URI、URI作为目录路径、以及将请求转发到index.html,以便由前端的Vue Router处理。
添加这行配置后,刷新页面就不会再出现 404 错误了,所有的路由请求都会交由 Vue Router 处理。
OpenResty 配置步骤:
配置后再去刷新子路径,都可以正常访问了。
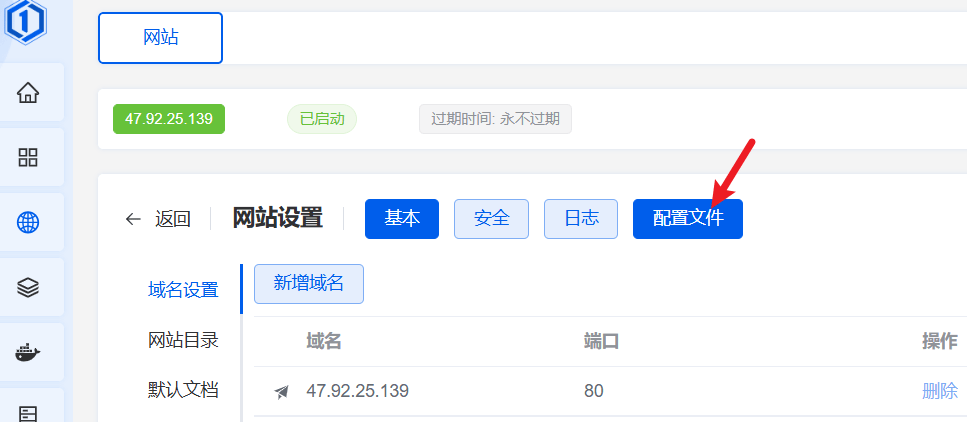
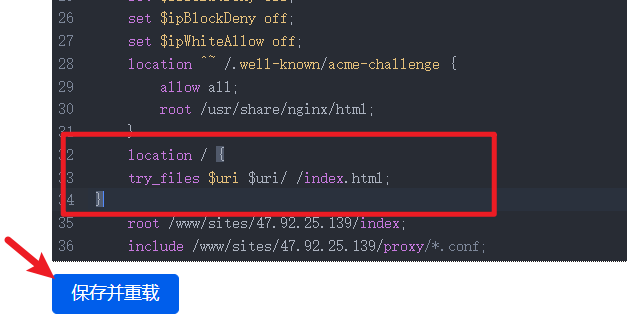
完整的配置文件
静态站点的完整配置:
server {listen 80; # 监听80端口server_name 47.92.25.139; # 服务器域名或IP地址index index.php index.html index.htm default.php default.htm default.html; # 指定默认首页文件# 设置代理请求的头部信息proxy_set_header Host $host; # 原始主机头部proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; # 获取客户端IP地址proxy_set_header X-Forwarded-Host $server_name; # 获取原始的主机名proxy_set_header X-Real-IP $remote_addr; # 获取真实的客户端IP地址proxy_http_version 1.1; # 使用HTTP/1.1版本进行代理proxy_set_header Upgrade $http_upgrade; # 用于 WebSocket 升级请求proxy_set_header Connection "upgrade"; # 连接升级# 日志文件的设置access_log /www/sites/47.92.25.139/log/access.log; # 访问日志路径error_log /www/sites/47.92.25.139/log/error.log; # 错误日志路径# 加载WAF(Web应用防火墙)访问控制逻辑access_by_lua_file /www/common/waf/access.lua; # 设置一些变量set $RulePath /www/sites/47.92.25.139/waf/rules; # WAF规则路径set $logdir /www/sites/47.92.25.139/log; # 日志目录set $redirect on; # 是否启用重定向set $attackLog on; # 是否启用攻击日志set $CCDeny off; # 是否启用CC攻击防护set $urlWhiteAllow off; # URL白名单set $urlBlockDeny off; # URL黑名单set $argsDeny off; # 请求参数禁用set $postDeny off; # 禁用POST请求set $cookieDeny off; # 禁用Cookieset $fileExtDeny off; # 文件扩展名禁用set $ipBlockDeny off; # IP黑名单set $ipWhiteAllow off; # IP白名单# 处理Let's Encrypt的挑战请求location ^~ /.well-known/acme-challenge {allow all; # 允许所有访问root /usr/share/nginx/html; # 指定根目录}# 解决子路由404的问题location / {# 尝试查找请求的URI,未找到时会请求index.htmltry_files $uri $uri/ /index.html; }root /www/sites/47.92.25.139/index; # 设置网站根目录# 包含其他配置文件,引入后端接口代理相关的配置include /www/sites/47.92.25.139/proxy/*.conf;
}后端接口的代理配置:
location ^~ /api {# 将请求转发到本地7000端口的服务proxy_pass http://127.0.0.1:7000; # 设置代理请求的头部信息proxy_set_header Host $host; # 原始主机头部proxy_set_header X-Real-IP $remote_addr; # 真实客户端IPproxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; # 包含原始的客户端IP地址proxy_set_header REMOTE-HOST $remote_addr; # 记录远程主机地址proxy_set_header Upgrade $http_upgrade; # 用于 WebSocket 升级请求proxy_set_header Connection "upgrade"; # 连接升级proxy_set_header X-Forwarded-Proto $scheme; # 原始请求协议(http或https)proxy_http_version 1.1; # 使用HTTP/1.1版本进行代理# 设置缓存相关的响应头add_header X-Cache $upstream_cache_status; # 添加缓存状态头add_header Cache-Control no-cache; # 禁用缓存
}docker镜像部署
todo-待更新---
近期更新计划
近期更新计划(有需要的小伙伴,记得点赞关注哟!)
vue、router、elementplus等前端框架入门教程,预计11中旬更新完成;博客系统功能完善,实现评论系统等功能;
基于vue3+springboot3的前后端分离的博客系统已经开源啦,欢迎大家star!
“学编程,一定要系统化”——若你也是系统学习的践行者,记得点赞关注,期待与你一起 From Zero To Hero!


















