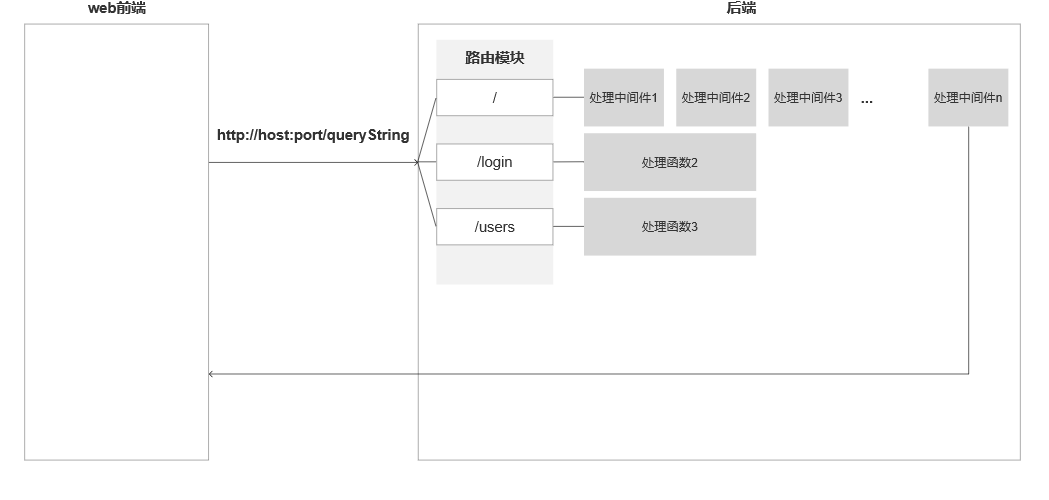
DIP(Deep Image Prior,深度图像先验)和DMs(Diffusion Models,扩散模型)是计算机视觉和深度学习领域中的两种重要模型,它们各自具有独特的特点和优势。以下是对这两个模型无监督特性和生成能力的详细解释:
DIP的无监督特性
无监督学习:
DIP是一种无监督的深度学习方法,它不需要大量的标注数据来进行训练。在DIP中,网络架构本身被用作隐式正则化,通过对网络输入的随机噪声进行优化,可以逐渐生成与输入图像相似的图像。
扫描自适应:
DIP具有扫描自适应的特性,即它能够根据输入图像的特定特征进行自适应的学习和优化。这使得DIP在处理不同类型的图像时能够表现出更好的泛化能力。
隐式正则化:
DIP利用网络架构的先验知识作为正则化手段,避免了传统方法中需要显式正则化的复杂过程。这种隐式正则化方式使得DIP在图像恢复问题中能够取得较好的效果。
易于实现:
DIP的实现相对简单,只需要一个基本的深度学习框架和少量的代码即可实现。这使得DIP在研究和应用中具有广泛的适用性。
DMs的生成能力
生成式模型:
DMs是一种生成式模型,它通过学习数据的分布来生成新的数据样本。与判别式模型不同,生成式模型能够捕捉到数据的内在结构和特征,从而生成与真实数据相似的样本。
扩散过程:
DMs通过模拟一个扩散过程来逐渐将噪声数据转换为真实数据。在训练过程中,DMs学习如何将噪声数据映射到真实数据的分布上,从而生成高质量的样本。
稳定性好:
相比于其他生成式模型(如GANs),DMs在训练过程中表现出更好的稳定性。它们不容易出现模式崩溃或训练不稳定的问题,这使得DMs在生成高质量样本方面更具优势。
多样性高:
DMs能够生成具有多样性的样本。由于它们是通过学习数据的分布来生成新样本的,因此可以生成与真实数据相似但又不完全相同的样本,这增加了生成样本的多样性和丰富性。
应用广泛:
DMs在图像生成、视频合成、音频生成等领域具有广泛的应用前景。它们可以生成高质量的图像、视频和音频样本,为这些领域的研究和应用提供了有力的支持。
综上所述,DIP和DMs是两种具有不同特点和优势的深度学习模型。DIP利用无监督学习和隐式正则化的特性在图像恢复问题中取得了良好的效果;而DMs则通过模拟扩散过程和生成式学习的特性在图像生成和其他相关领域中展现出强大的生成能力。