MySQL学习总结
文章目录
- MySQL
- 语句的执行流程
- 覆盖索引与索引下推
- 覆盖索引
- 索引下推
- 区别总结
- 记录的存储结构
- 数据页
- COMPACT 行格式
- 二叉树、B 树、B+ 树
- 索引
- 索引的数据结构
- 索引失效
- 事务
- 并发问题
- 隔离级别
- MCVV - 多版本并发控制
- 锁
- 全局锁
- 表级锁
- 行级锁
- 索引与锁
- 日志
- Buffer Pool
MySQL
语句的执行流程
- 解析器
- 预处理器
- 优化器
- 执行器
覆盖索引与索引下推
覆盖索引
- 原理 :覆盖索引指的是查询所需要的数据都能从索引中获取,而无需再到数据表中去查找数据。索引本身是有序的数据结构,查询索引的速度通常比查询数据表要快。所以,若查询能直接通过索引得到结果,就能避免回表操作(即从索引中找到记录的主键,再根据主键到数据表中查找完整的数据),从而提高查询效率。
- 示例 :假设存在一个
users表,包含id、name、age字段,并且在(name, age)上创建了联合索引。当执行查询SELECT name, age FROM users WHERE name = 'John';时,由于查询所需的name和age字段都包含在索引中,MySQL 可以直接从索引中获取这些数据,而不需要回表到users表中去查找。 - 适用场景 :适用于查询字段较少,且这些字段都包含在同一个索引中的情况。
索引下推
- 原理 :索引下推是 MySQL 5.6 及以后版本引入的优化策略。在使用索引进行查询时,当查询条件中有多个条件可以使用索引时,MySQL 会在索引遍历过程中对这些条件进行部分评估,过滤掉不满足条件的索引项,减少回表的次数。简单来说,就是在索引层面先对部分条件进行筛选,减少回表查询的数据量。
- 示例 :还是以
users表为例,在(name, age)上有联合索引。执行查询SELECT * FROM users WHERE name LIKE 'J%' AND age > 20;。在没有索引下推的情况下,MySQL 会先根据name LIKE 'J%'从索引中找出所有匹配的记录,然后回表到users表中再对age > 20这个条件进行过滤。而有了索引下推后,MySQL 会在索引遍历过程中同时对name LIKE 'J%'和age > 20这两个条件进行评估,只将满足这两个条件的索引项对应的记录进行回表操作,从而减少了回表的次数。 - 适用场景 :适用于查询条件中有多个可以使用索引的条件,并且这些条件可以在索引层面进行部分过滤的情况。
区别总结
- 侧重点不同 :覆盖索引着重于查询所需的数据能直接从索引中获取,避免回表;而索引下推侧重于在索引遍历过程中对部分查询条件进行提前过滤,减少回表的数据量。
- 应用条件不同 :覆盖索引要求查询字段必须包含在索引中;索引下推则要求查询条件中有多个可以使用索引的条件。
- 优化效果不同 :覆盖索引能够完全避免回表操作;索引下推则是减少回表的次数,在一定程度上提高查询效率。
记录的存储结构
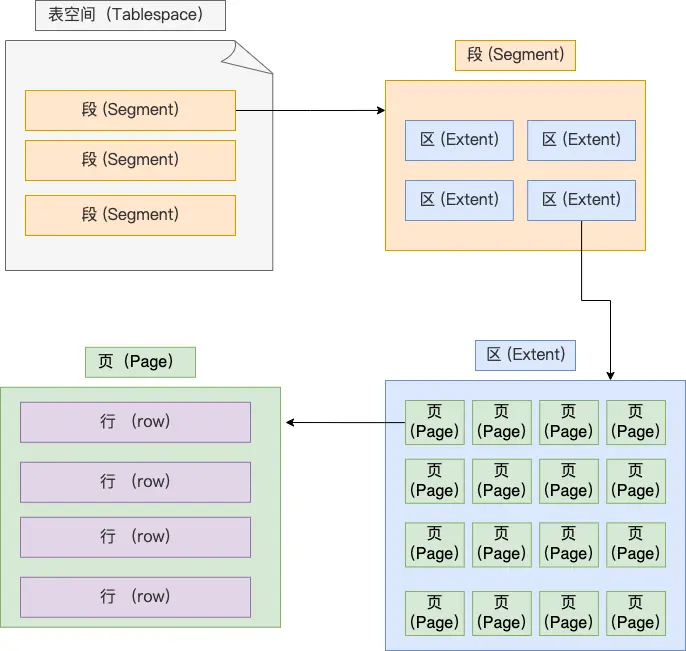
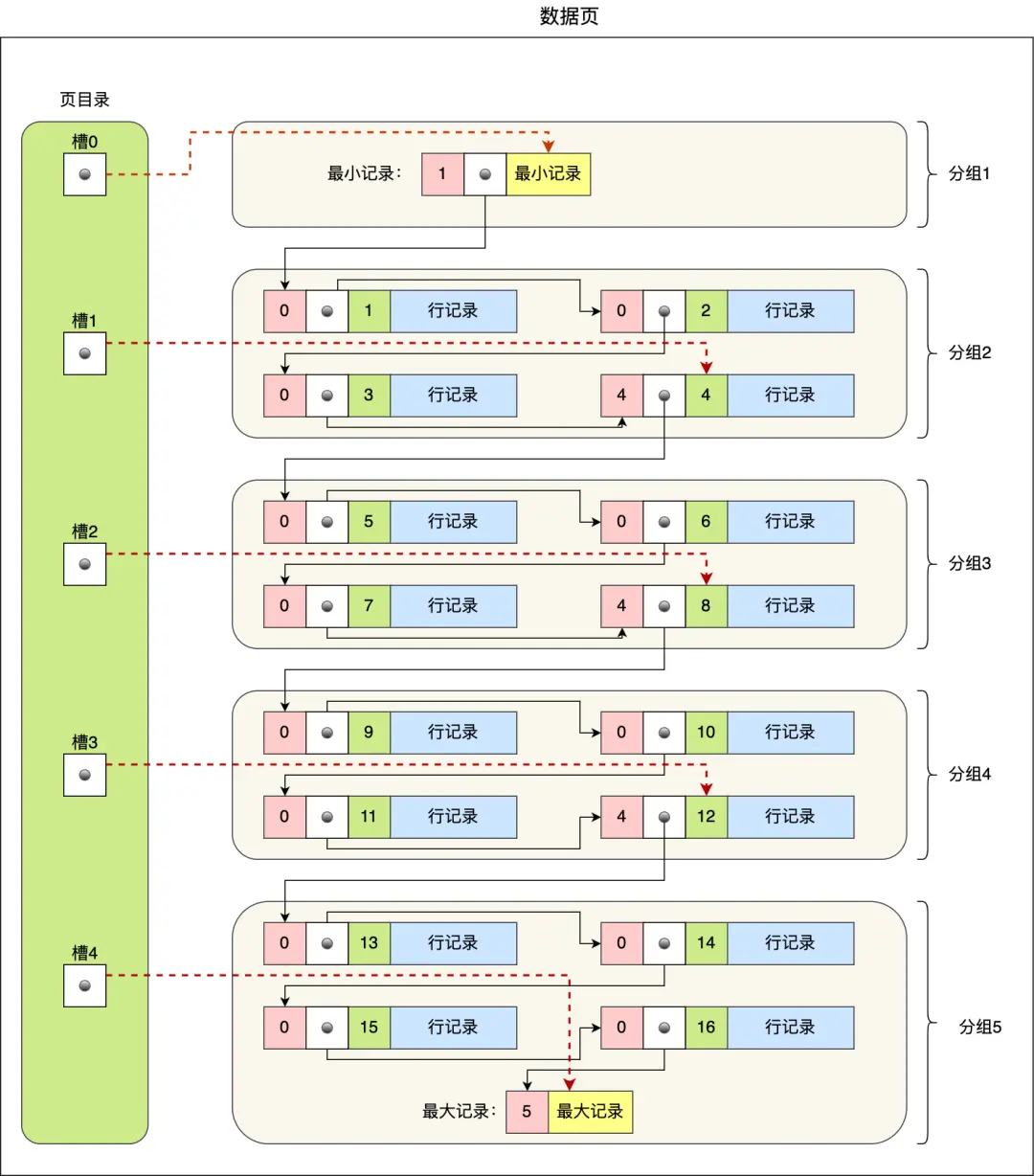
数据页
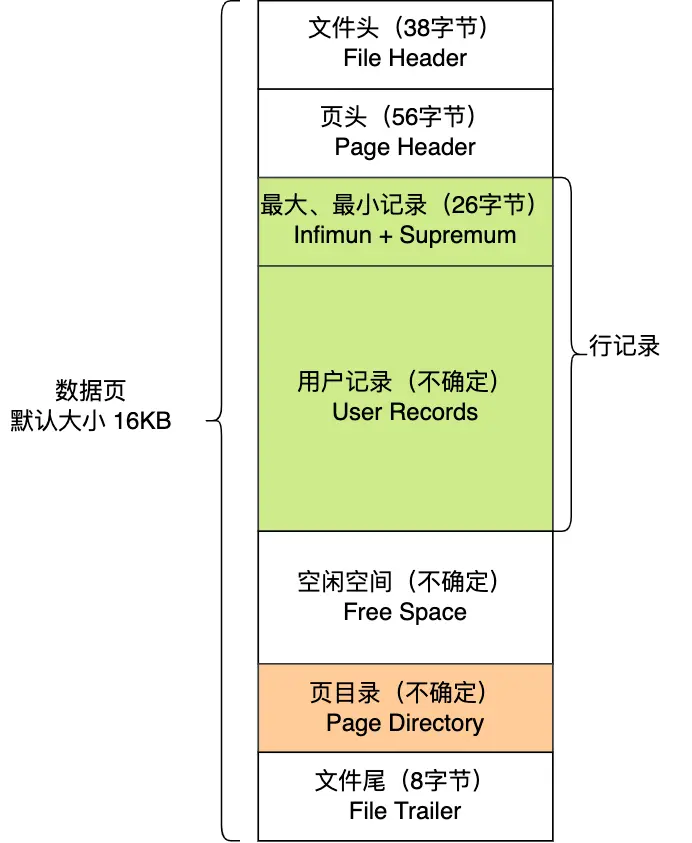
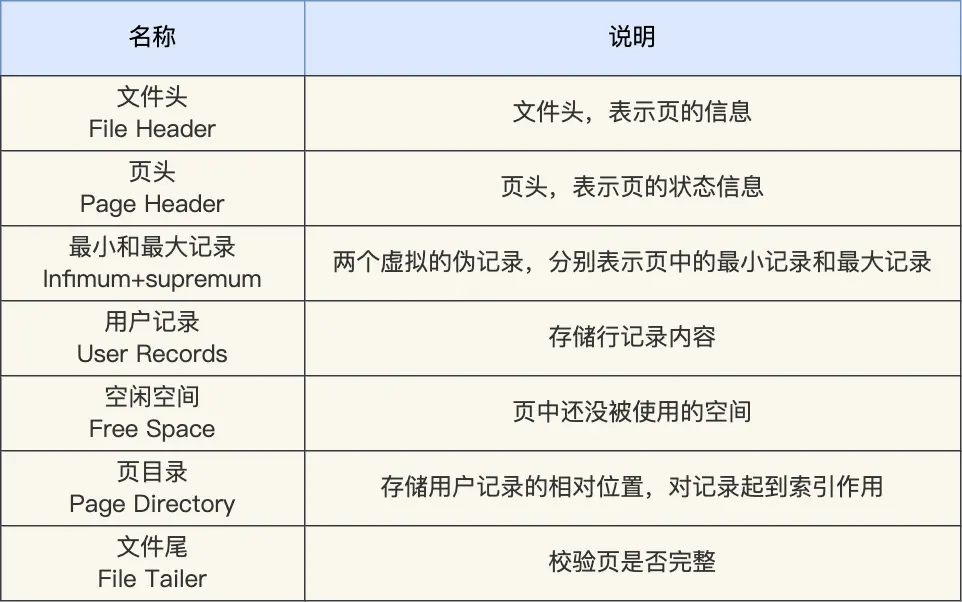
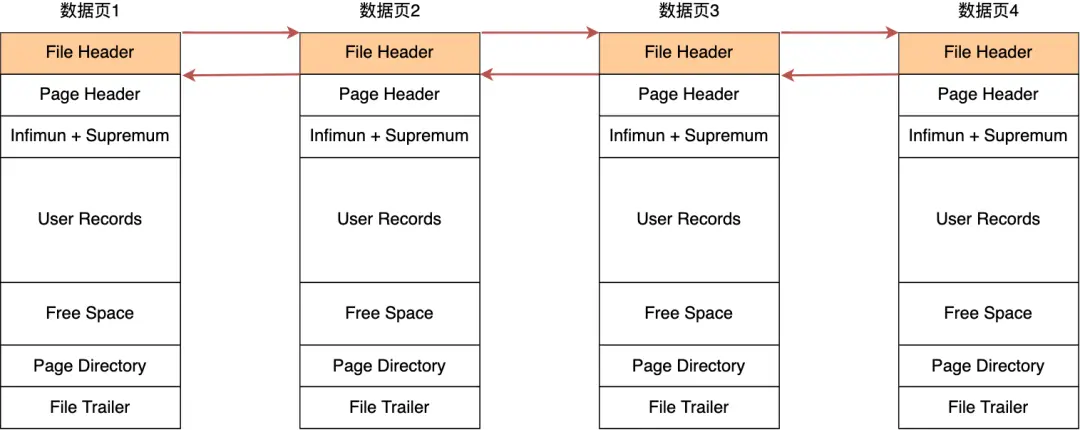
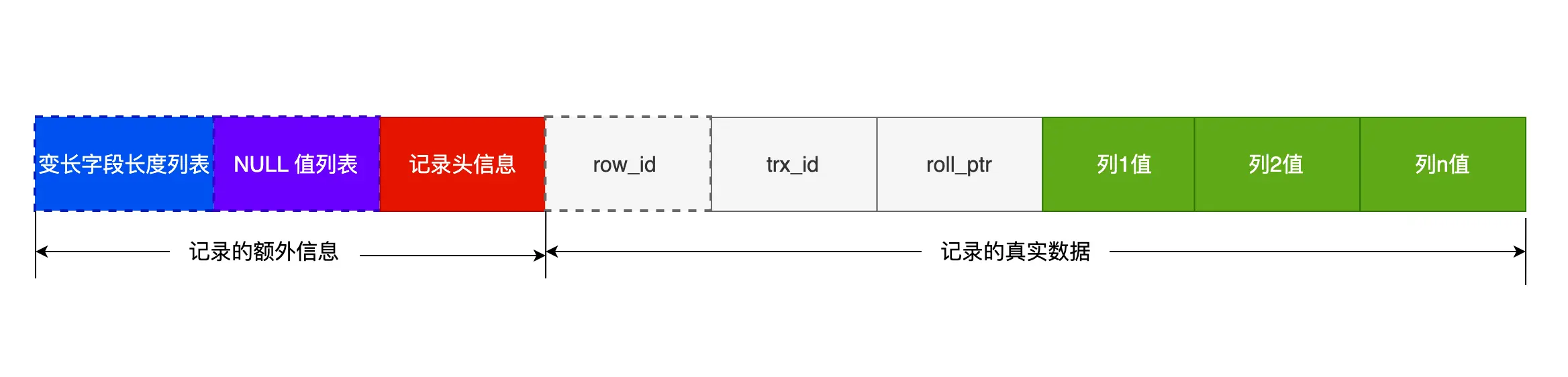
COMPACT 行格式
二叉树、B 树、B+ 树
- 二叉树: 不管平衡二叉查找树还是红黑树,都会随着插入的元素增多,而导致树的高度变高,这就意味着磁盘 I/O 操作次数多,会影响整体数据查询的效率。
- B 树:B 树的每一个节点最多可以包括 M 个子节点,M 称为 B 树的阶,所以 B 树就是一个多叉树, B 树的每个节点都包含数据(索引+记录),而用户的记录数据的大小很有可能远远超过了索引数据,这就需要花费更多的磁盘 I/O 操作次数来读到「有用的索引数据」
- B+ 树:叶子节点(最底部的节点)才会存放实际数据(索引+记录),非叶子节点只会存放索引,所有索引都会在叶子节点出现,叶子节点之间构成一个有序链表;
索引
- 按「数据结构」分类:B+tree索引、Hash索引、Full-text索引。
- 按「物理存储」分类:聚簇索引(主键索引)、二级索引(辅助索引)。
- 按「字段特性」分类:主键索引、唯一索引、普通索引、前缀索引。
- 按「字段个数」分类:单列索引、联合索引。
索引的数据结构
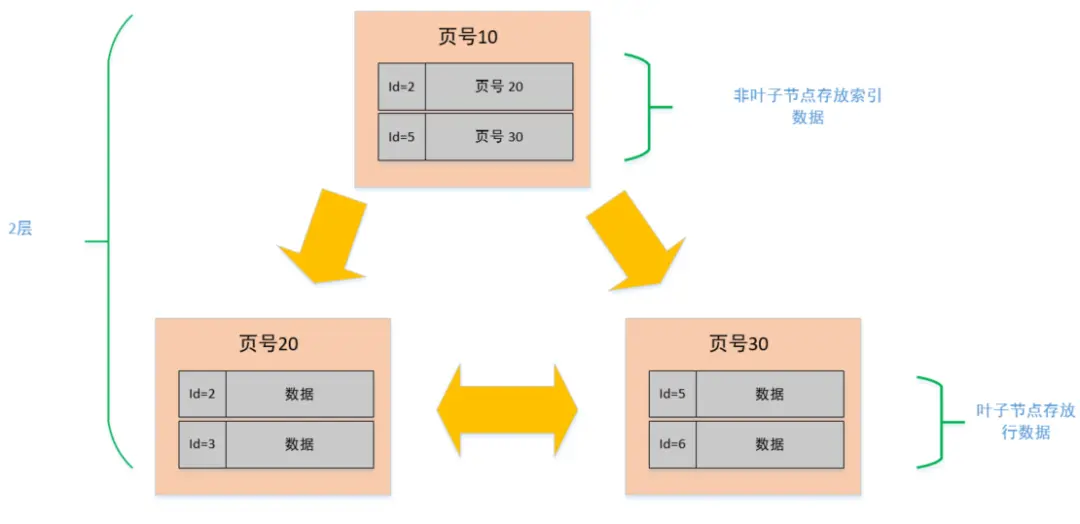
在 MySQL 中索引的数据结构和刚刚描述的页几乎是一模一样的,而且大小也是 16K。
但是在索引页中记录的是页 (数据页,索引页) 的最小主键 id 和页号,以及在索引页中增加了层级的信息,从 0 开始往上算,所以页与页之间就有了上下层级的概念。
索引失效
- 当我们使用左或者左右模糊匹配的时候,也就是 like %xx 或者 like %xx%这两种方式都会造成索引失效;
- 当我们在查询条件中对索引列使用函数,就会导致索引失效。
- 当我们在查询条件中对索引列进行表达式计算,也是无法走索引的。
- MySQL 在遇到字符串和数字比较的时候,会自动把字符串转为数字,然后再进行比较。如果字符串是索引列,而条件语句中的输入参数是数字的话,那么索引列会发生隐式类型转换,由于隐式类型转换是通过 CAST 函数实现的,等同于对索引列使用了函数,所以就会导致索引失效。
- 联合索引要能正确使用需要遵循最左匹配原则,也就是按照最左优先的方式进行索引的匹配,否则就会导致索引失效。
- 在 WHERE 子句中,如果在 OR 前的条件列是索引列,而在 OR 后的条件列不是索引列,那么索引会失效。
事务
并发问题
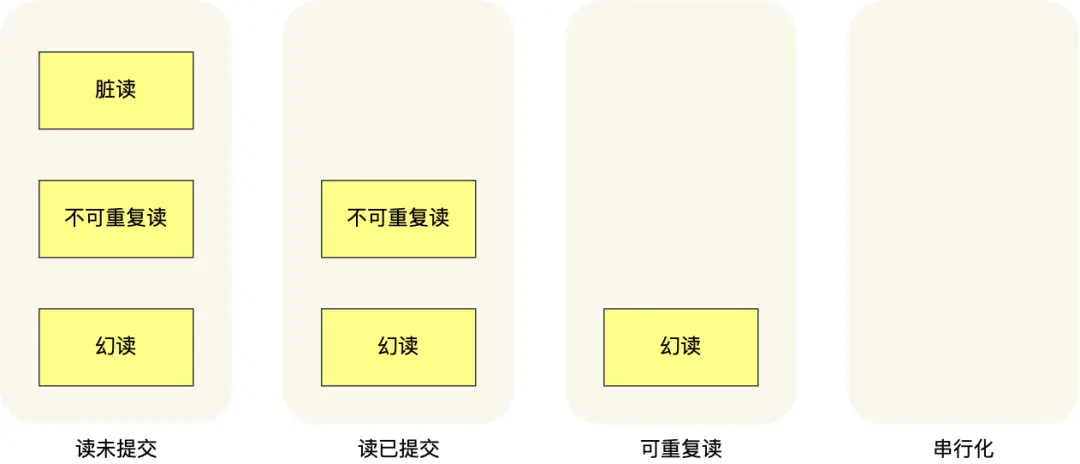
- 脏读
- 不可重复读
- 幻读
隔离级别
- 读未提交(read uncommitted),指一个事务还没提交时,它做的变更就能被其他事务看到;
- 读提交(read committed),指一个事务提交之后,它做的变更才能被其他事务看到;
- 可重复读(repeatable read),指一个事务执行过程中看到的数据,一直跟这个事务启动时看到的数据是一致的,MySQL InnoDB 引擎的默认隔离级别;
- 串行化(serializable );会对记录加上读写锁,在多个事务对这条记录进行读写操作时,如果发生了读写冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行;
MCVV - 多版本并发控制
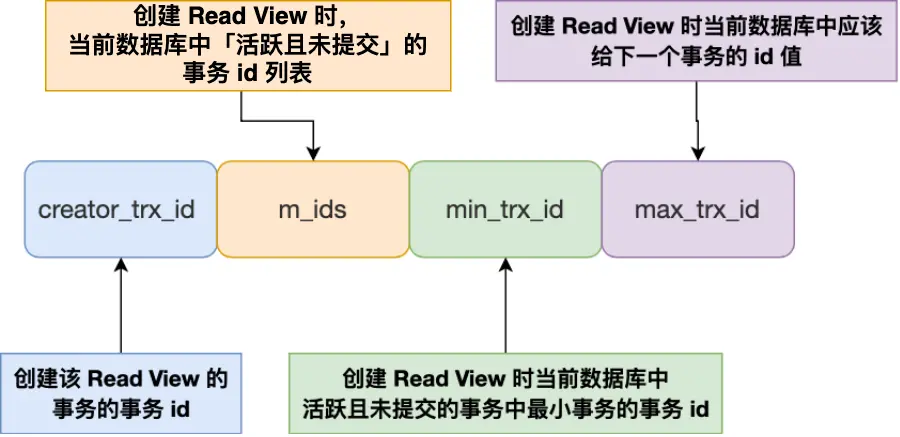
- m_ids :指的是在创建 Read View 时,当前数据库中「活跃事务」的事务 id 列表,注意是一个列表,“活跃事务”指的就是,启动了但还没提交的事务。
- min_trx_id :指的是在创建 Read View 时,当前数据库中「活跃事务」中事务 id 最小的事务,也就是 m_ids 的最小值。
- max_trx_id :这个并不是 m_ids 的最大值,而是创建 Read View 时当前数据库中应该给下一个事务的 id 值,也就是全局事务中最大的事务 id 值 + 1;
- creator_trx_id :指的是创建该 Read View 的事务的事务 id。
锁
全局锁
表级锁
- 表锁
- 元数据锁(MDL)
- 意向锁
- AUTO-INC 锁
行级锁
- Record Lock
- Gap Lock
- Next-Key Lock
- 插入意向锁
在能使用记录锁或者间隙锁就能避免幻读现象的场景下, next-key lock 就会退化成记录锁或间隙锁
索引与锁
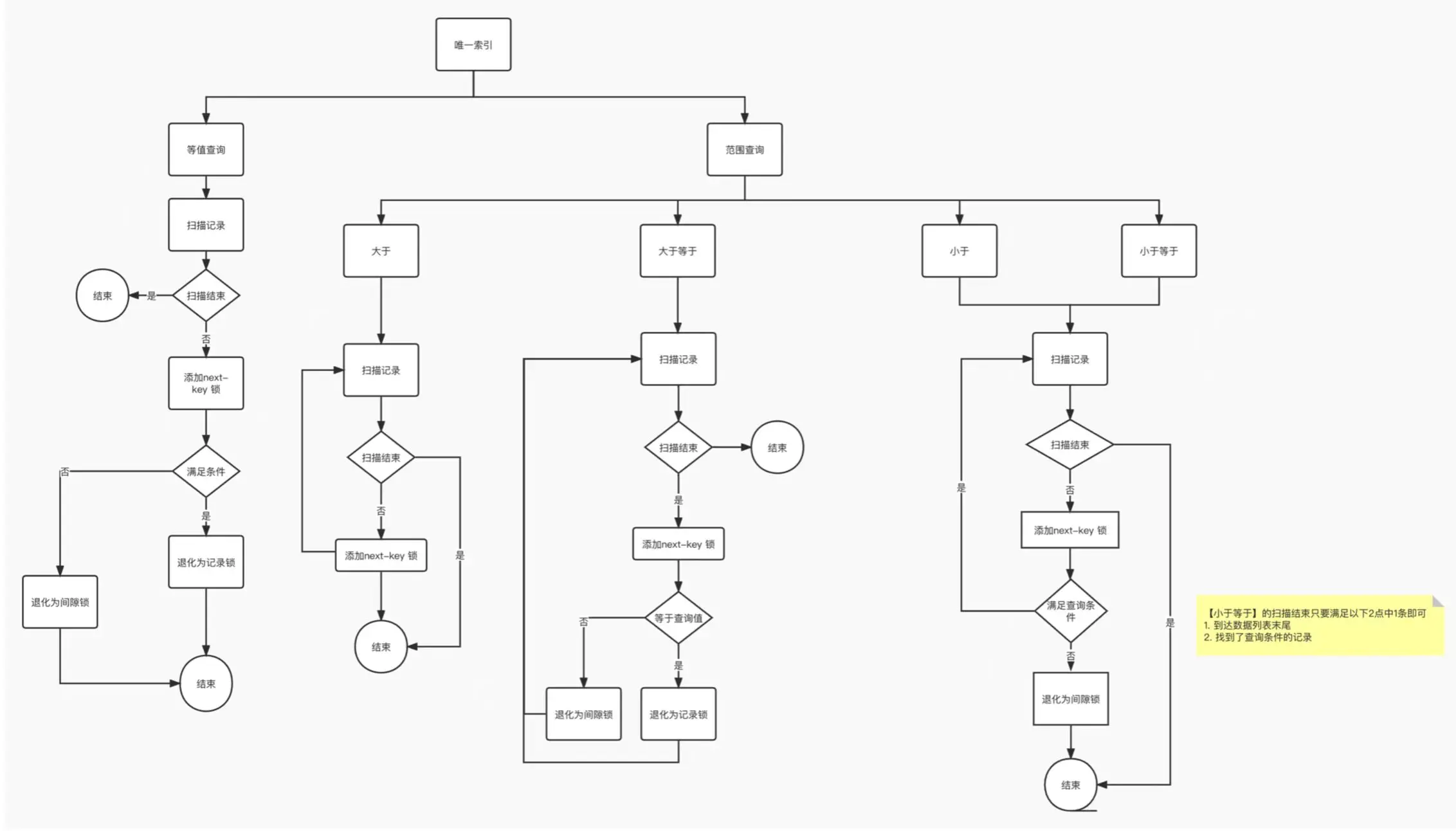
唯一索引等值查询:
- 当查询的记录是「存在」的,在索引树上定位到这一条记录后,将该记录的索引中的 next-key lock 会退化成「记录锁」。
- 当查询的记录是「不存在」的,在索引树找到第一条大于该查询记录的记录后,将该记录的索引中的 next-key lock 会退化成「间隙锁」。
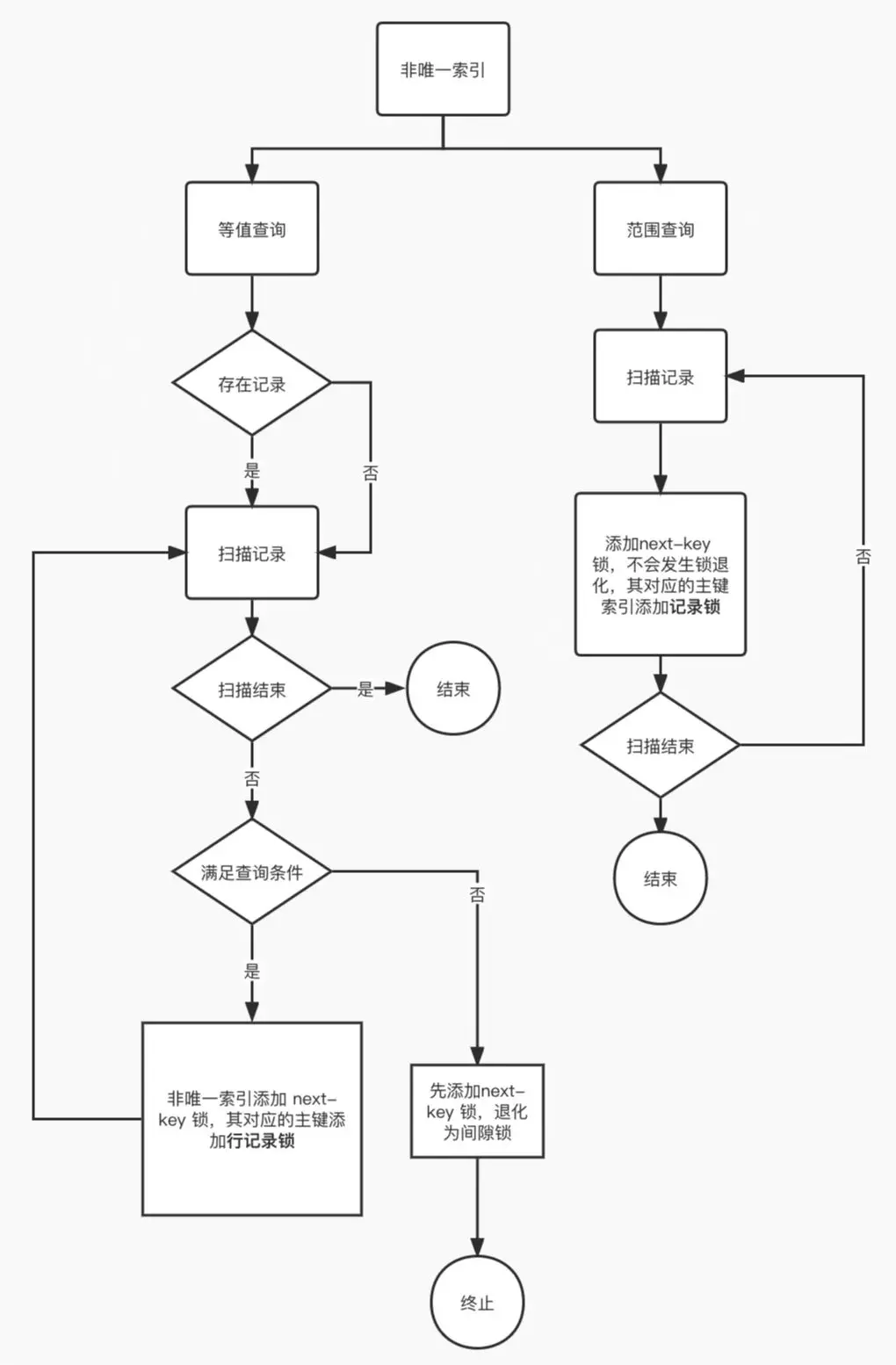
非唯一索引等值查询:
-
当查询的记录「存在」时,由于不是唯一索引,所以肯定存在索引值相同的记录,于是非唯一索引等值查询的过程是一个扫描的过程,直到扫描到第一个不符合条件的二级索引记录就停止扫描,然后在扫描的过程中,对扫描到的二级索引记录加的是 next-key 锁,而对于第一个不符合条件的二级索引记录,该二级索引的 next-key 锁会退化成间隙锁。同时,在符合查询条件的记录的主键索引上加记录锁。
-
当查询的记录「不存在」时,扫描到第一条不符合条件的二级索引记录,该二级索引的 next-key 锁会退化成间隙锁。因为不存在满足查询条件的记录,所以不会对主键索引加锁。
非唯一索引和主键索引的范围查询的加锁规则不同之处在于: -
唯一索引在满足一些条件的时候,索引的 next-key lock 退化为间隙锁或者记录锁。
-
非唯一索引范围查询,索引的 next-key lock 不会退化为间隙锁和记录锁。
日志
undo log 两大作用:
- 实现事务回滚,保障事务的原子性。事务处理过程中,如果出现了错误或者用户执 行了 ROLLBACK 语句,MySQL 可以利用 undo log 中的历史数据将数据恢复到事务开始之前的状态。
- 实现 MVCC(多版本并发控制)关键因素之一。MVCC 是通过 ReadView + undo log 实现的。undo log 为每条记录保存多份历史数据,MySQL 在执行快照读(普通 select 语句)的时候,会根据事务的 Read View 里的信息,顺着 undo log 的版本链找到满足其可见性的记录。
redo log:
bin log:
Buffer Pool
https://xiaolincoding.com/mysql/