【LLM】Qwen3模型训练和推理
note
Qwen3相关亮点:
- MOE模型:Qwen3-235B-A22B (MoE, 总大小235B, 激活参数22B, 上下文128K),Qwen3-30B-A3B (MoE, 总大小30B, 激活参数3B, 上下文128K)。
- 推理能力增强、代理能力增强
- 支持思考和非思考模式的切换
- 支持119种语言
- Qwen3 dense基础模型的整体性能与参数更多的 Qwen2.5 基础模型相当。例如,Qwen3-1.7B/4B/8B/14B/32B-Base 的性能分别与 Qwen2.5-3B/7B/14B/32B/72B-Base 相当
文章目录
- note
- 一、Qwen3
- 二、思考开关
- 三、模型训练
- 1. 预训练阶段
- 2. Post-training
- 四、模型部署
- 五、模型评测
- 六、Agent方面
- Reference
一、Qwen3
Qwen3发布。体验链接:chat.qwen.ai
技术报告地址: qwenlm.github.io/blog/qwen3/
模型地址: modelscope.cn/collections/Qwen3-9743180bdc6b48
Github Repo: github.com/QwenLM/Qwen3
1、MoE模型有Qwen3-235B-A22B (MoE, 总大小235B, 激活参数22B, 上下文128K),Qwen3-30B-A3B (MoE, 总大小30B, 激活参数3B, 上下文128K)。
2、Dense模型:Qwen3-32B,Qwen3-14B,Qwen3-8B,Qwen3-4B,Qwen3-1.7B,Qwen3-0.6B,
新版本的 Qwen3 特性包括:混合思维模式, 搭载了 thinking 开关, 可以直接手动控制要不要开启 thinking,多语言支持, 支持 119 种语言和方言,Agent 能力提升, 提升了编码和 Agent 方面的表现,并加强了 MCP 的支持,另外, chat.qwen.ai 的 Qwen3 也上线。

相关dense模型参数:

相关MOE模型参数:
(1)本地测试及科研
Qwen3-0.6B/1.7B,硬件要求低,适合快速实验
(2)手机端侧应用
Qwen3-4B,性能与效率兼顾,适合移动端部署
(3)电脑或汽车端
Qwen3-8B,适用于对话系统、语音助手等场景
(4)企业落地
Qwen3-14B/32B 性能更强,适合复杂任务
(5)云端高效部署
MoE 模型,Qwen3-30B-A3B 速度快
Qwen3-235B-A22B 性能强劲且显存占用低
二、思考开关
Qwen3 引入了“思考模式”和“非思考模式”,使模型能够在不同场景下表现出最佳性能。在思考模式模式下,模型会进行多步推理和深度分析,类似于人类在解决复杂问题时的“深思熟虑”。(eg:在回答数学题或编写复杂代码时,模型会反复验证逻辑并优化输出结果。)
在非思考模式模式下,模型优先追求响应速度和效率,适用于简单任务或实时交互。(eg:在日常对话或快速问答中,模型会跳过复杂的推理步骤,直接给出答案。)
三、模型训练
1. 预训练阶段
在预训练方面,Qwen3 的数据集相比 Qwen2.5 有了显著扩展。Qwen2.5 预训练了 18 万亿个 token,而 Qwen3 使用的 token 数量几乎是 Qwen2.5 的两倍,约有 36 万亿个 token,涵盖 119 种语言和方言。为了构建这个庞大的数据集,我们不仅从网络收集数据,还从类似 PDF 的文档中收集数据。我们使用 Qwen2.5-VL 从这些文档中提取文本,并使用 Qwen2.5 来提升提取内容的质量。为了增加数学和代码数据量,我们使用 Qwen2.5-Math 和 Qwen2.5-Coder 生成合成数据,其中包括教科书、问答对和代码片段。
预训练过程包含三个阶段:
- 在第一阶段(S1),我们利用超过 30 万亿个 tokens 预训练模型,上下文长度为 4000 个 tokens。此阶段为模型提供了基本的语言技能和常识。
- 在第二阶段(S2),我们通过增加知识密集型数据(例如 STEM、编码和推理任务)的比例来改进数据集。之后,我们又利用另外 5 万亿个 tokens 对模型进行了预训练。
- 在最后阶段,我们使用高质量的长上下文数据将上下文长度扩展至 32000 个 tokens,以确保模型能够有效地处理更长的输入。
2. Post-training
为了开发既能进行逐步推理又能快速响应的混合模型,我们实现了一个四阶段的训练流程。该流程包括:
(1)长思维链 (CoT) 冷启动,
(2)基于推理的强化学习 (RL),
(3)思维模式融合,
(4)通用强化学习。
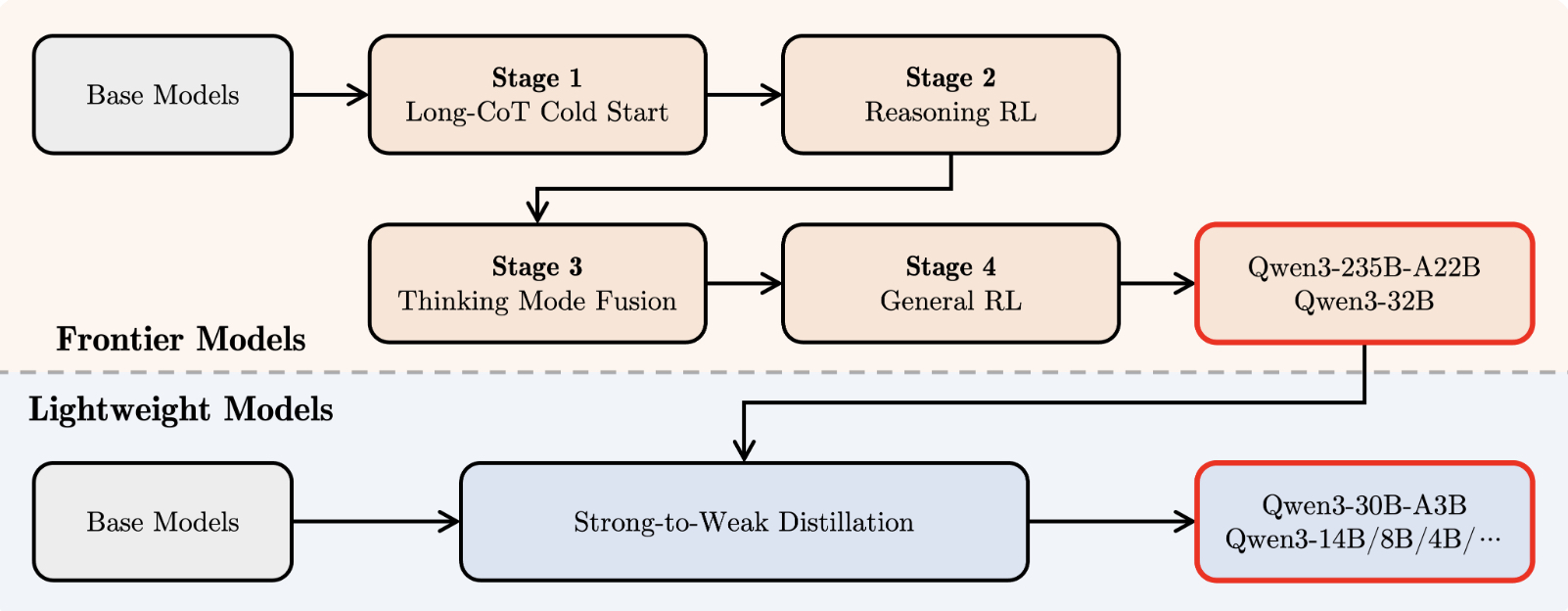
在第一阶段,我们使用各种长 CoT 数据对模型进行微调,涵盖数学、编程、逻辑推理和 STEM 问题等各种任务和领域。此过程旨在使模型具备基本的推理能力。
第二阶段专注于扩展强化学习的计算资源,利用基于规则的奖励来增强模型的探索和利用能力。
在第三阶段,我们通过结合长CoT数据和常用的指令调整数据对思维模型进行微调,将非思维能力融入到思维模型中。这些数据由第二阶段的增强型思维模型生成,确保推理能力与快速响应能力的无缝融合。
在第四阶段,我们将强化学习应用于20多个通用领域任务,以进一步增强模型的通用能力并纠正不良行为。这些任务包括指令遵循、格式遵循和代理能力等。
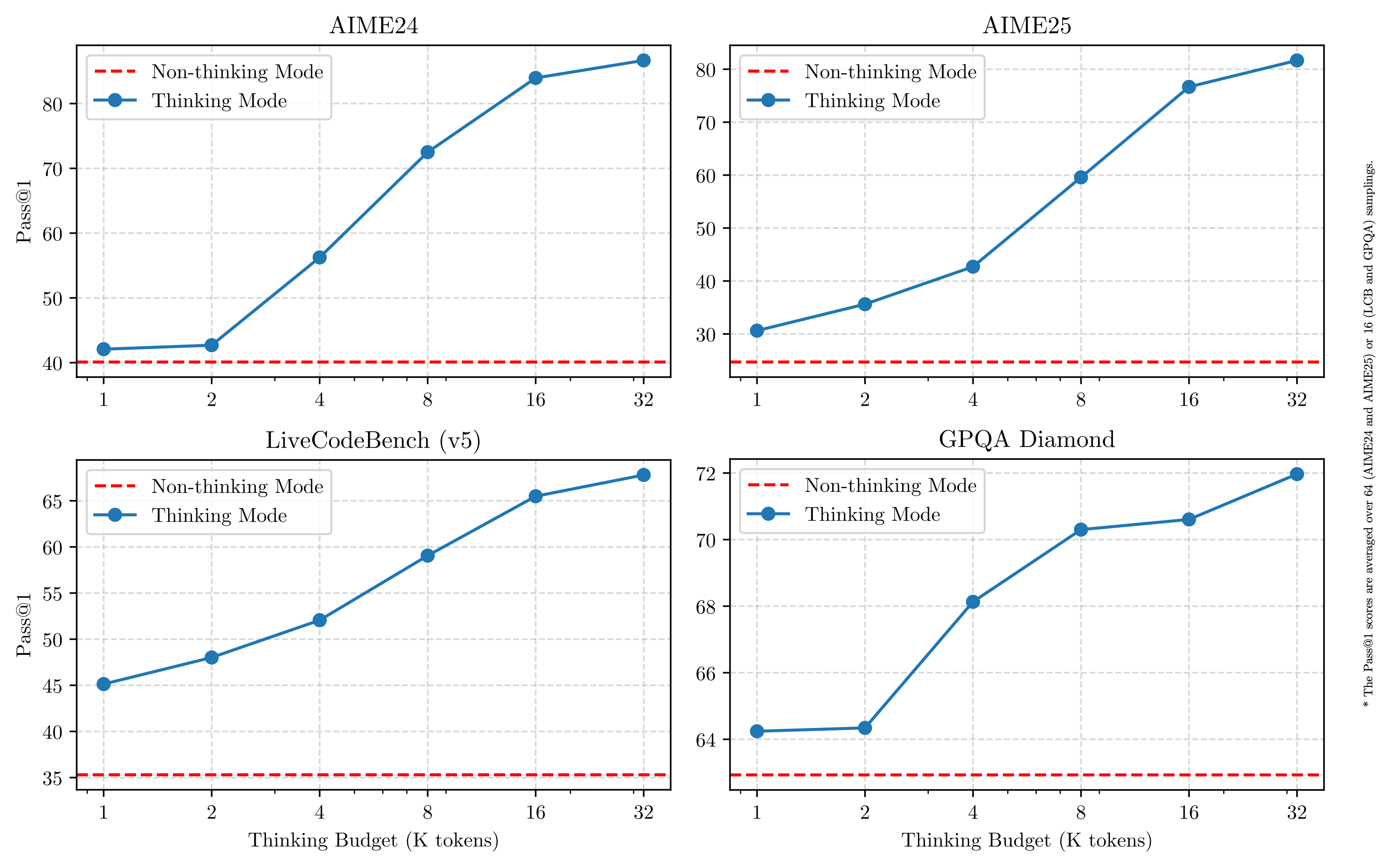
随着推理预算的增加,实验发现确实能在一些hard benchmark上取得递增的效果
四、模型部署
对于部署,我们建议使用SGLang和vLLM等框架。对于本地使用,强烈推荐使用Ollama、LMStudio、MLX、llama.cpp和KTransformers等工具
在 Hugging Face Transformer 中使用 Qwen3-30B-A3B 的标准示例:
from modelscope import AutoModelForCausalLM, AutoTokenizermodel_name = "Qwen/Qwen3-30B-A3B"# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name,torch_dtype="auto",device_map="auto"
)# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True,enable_thinking=True # Switch between thinking and non-thinking modes. Default is True.
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)# conduct text completion
generated_ids = model.generate(**model_inputs,max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist() # parsing thinking content
try:# rindex finding 151668 (</think>)index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:index = 0thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")print("thinking content:", thinking_content)
print("content:", content)
多轮对话的示例:
from transformers import AutoModelForCausalLM, AutoTokenizerclass QwenChatbot:def __init__(self, model_name="Qwen/Qwen3-30B-A3B"):self.tokenizer = AutoTokenizer.from_pretrained(model_name)self.model = AutoModelForCausalLM.from_pretrained(model_name)self.history = []def generate_response(self, user_input):messages = self.history + [{"role": "user", "content": user_input}]text = self.tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True)inputs = self.tokenizer(text, return_tensors="pt")response_ids = self.model.generate(**inputs, max_new_tokens=32768)[0][len(inputs.input_ids[0]):].tolist()response = self.tokenizer.decode(response_ids, skip_special_tokens=True)# Update historyself.history.append({"role": "user", "content": user_input})self.history.append({"role": "assistant", "content": response})return response# Example Usage
if __name__ == "__main__":chatbot = QwenChatbot()# First input (without /think or /no_think tags, thinking mode is enabled by default)user_input_1 = "How many r's in strawberries?"print(f"User: {user_input_1}")response_1 = chatbot.generate_response(user_input_1)print(f"Bot: {response_1}")print("----------------------")# Second input with /no_thinkuser_input_2 = "Then, how many r's in blueberries? /no_think"print(f"User: {user_input_2}")response_2 = chatbot.generate_response(user_input_2)print(f"Bot: {response_2}") print("----------------------")# Third input with /thinkuser_input_3 = "Really? /think"print(f"User: {user_input_3}")response_3 = chatbot.generate_response(user_input_3)print(f"Bot: {response_3}")
五、模型评测
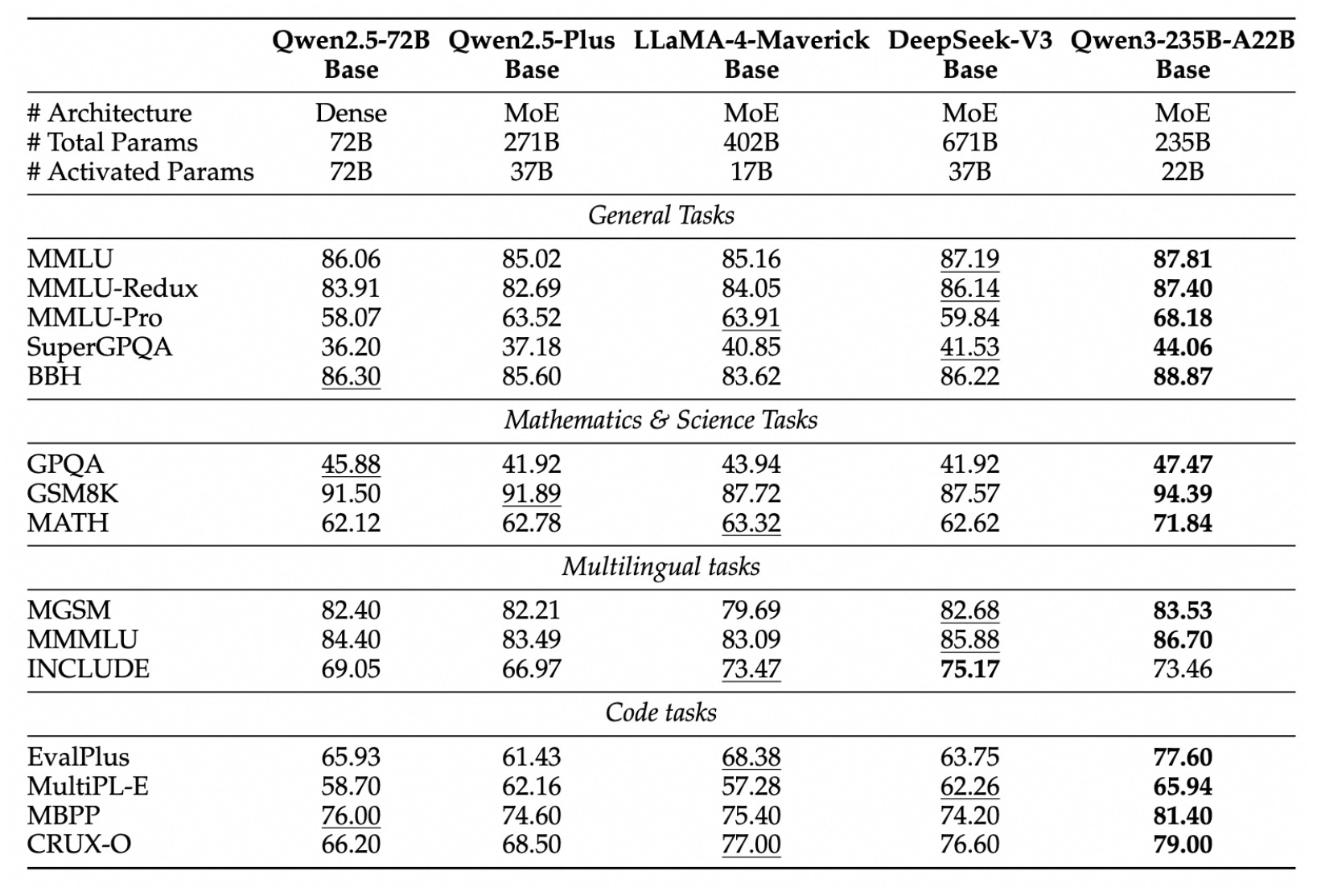
作为Qwen系列全新一代的混合推理模型,Qwen3 在 GPQA、AIME24/25、LiveCodeBench 等多个权威评测中表现出极具竞争力的结果。
六、Agent方面
为了充分发挥 Qwen3 的代理能力,我们推荐使用Qwen-Agent。Qwen -Agent 内部封装了工具调用模板和工具调用解析器,大大降低了代码复杂度。
参考:https://github.com/QwenLM/Qwen-Agent
定义可用的工具,可以使用MCP配置文件,使用Qwen-Agent集成的工具,或者自行集成其他工具。
from qwen_agent.agents import Assistant# Define LLM
llm_cfg = {'model': 'Qwen3-30B-A3B',# Use the endpoint provided by Alibaba Model Studio:# 'model_type': 'qwen_dashscope',# 'api_key': os.getenv('DASHSCOPE_API_KEY'),# Use a custom endpoint compatible with OpenAI API:'model_server': 'http://localhost:8000/v1', # api_base'api_key': 'EMPTY',# Other parameters:# 'generate_cfg': {# # Add: When the response content is `<think>this is the thought</think>this is the answer;# # Do not add: When the response has been separated by reasoning_content and content.# 'thought_in_content': True,# },
}# Define Tools
tools = [{'mcpServers': { # You can specify the MCP configuration file'time': {'command': 'uvx','args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']},"fetch": {"command": "uvx","args": ["mcp-server-fetch"]}}},'code_interpreter', # Built-in tools
]# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):pass
print(responses)
Reference
体验链接:chat.qwen.ai
技术报告地址: qwenlm.github.io/blog/qwen3/
模型地址: modelscope.cn/collections/Qwen3-9743180bdc6b48
Github Repo: github.com/QwenLM/Qwen3
https://mp.weixin.qq.com/s/NrS8SR9_FMq5GW-SJQPn8w