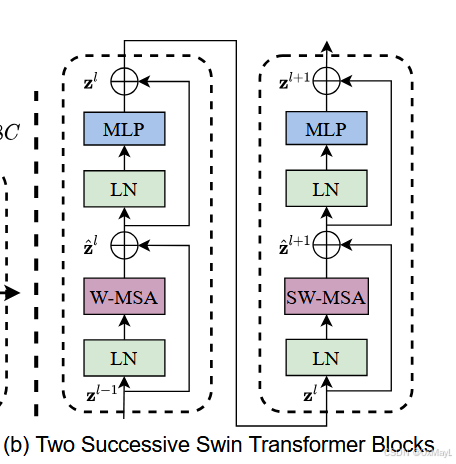
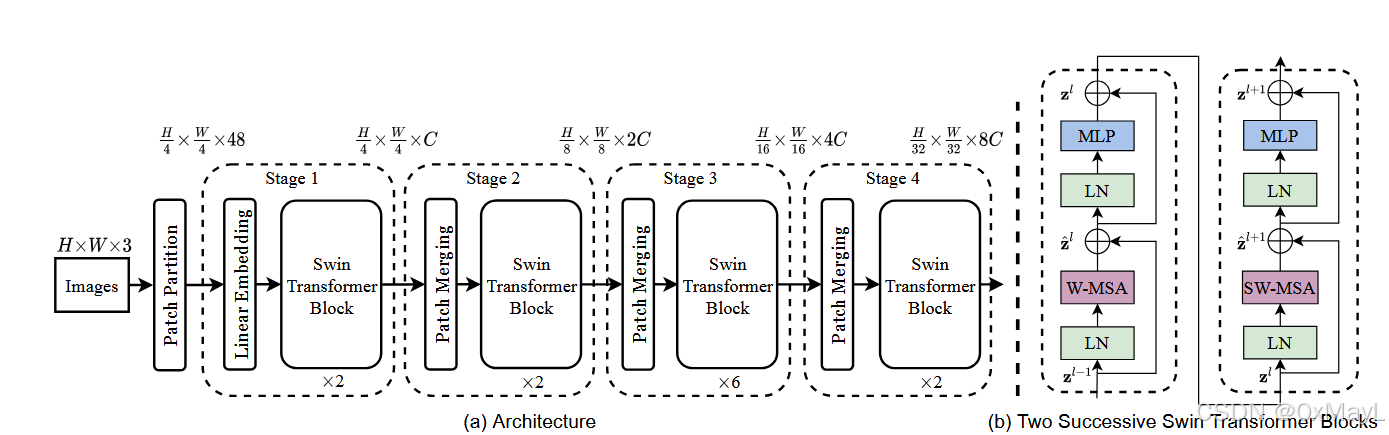
Conv2d 也可以先打包后使用embedding映射。 实现:获得相邻的Patch,然后在通道维度上concat ,维度变为 4 C 4C 4 C 线性层 投射回 2 C 2C 2 C [ [ 1 , 2 , 3 , 4 ] [ 5 , 6 , 7 , 8 ] [ 9 , 10 , 11 , 12 ] [ 13 , 14 , 15 , 16 ] ]
通过切片获得对应位置的元素 注意我们从通道维度上拼接,所以不能按照传统的上下拼接的思路理解 这段代码的效果是:编号1,2,5,6的特征向量拼接 ,(相邻元素就好像叠加 在一起) x0 = x[ : , 0 : : 2 , 0 : : 2 , : ] x1 = x[ : , 1 : : 2 , 0 : : 2 , : ] x2 = x[ : , 0 : : 2 , 1 : : 2 , : ] x3 = x[ : , 1 : : 2 , 1 : : 2 , : ] x = torch. cat( [ x0, x1, x2, x3] , - 1 )
这点就好比 8 ∗ 8 = 64 > > > 4 ∗ ( 2 ∗ 2 ) = 16 8*8=64>>>4*(2*2)=16 8 ∗ 8 = 64 >>> 4 ∗ ( 2 ∗ 2 ) = 16 2 ∗ 2 2*2 2 ∗ 2 8 ∗ 8 8*8 8 ∗ 8 输入: ( B ∗ N w , M h ∗ M w , C ) (B*N_w,M_h*M_w,C) ( B ∗ N w , M h ∗ M w , C ) N w N_w N w N w = H ∗ W M h ∗ M w N_w=\frac{H*W}{M_h*M_w} N w = M h ∗ M w H ∗ W 输入的理解:将窗口数量理解为一种批次 , M h ∗ M w M_h*M_w M h ∗ M w 序列的长度 ,reshape为指定维度: ( B ∗ N w , M h ∗ N w , C ) (B*N_w,M_h*N_w,C) ( B ∗ N w , M h ∗ N w , C ) 快速计算KQV,直接使用线性层映射 为 ( B ∗ N w , M h ∗ N w , 3 C ) (B*N_w,M_h*N_w,3C) ( B ∗ N w , M h ∗ N w , 3 C ) 拆分最后一个维度 3 C 3C 3 C ( 3 , B ∗ N w , M h ∗ N w , C ) (3,B*N_w,M_h*N_w,C) ( 3 , B ∗ N w , M h ∗ N w , C ) 多头注意力机制:每一个KQV维度 ( 3 , B ∗ N w , M h ∗ N w , C ) (3,B*N_w,M_h*N_w,C) ( 3 , B ∗ N w , M h ∗ N w , C ) ( 3 , B ∗ N w , N h e a d , M h ∗ N w , d i m h e a d ) (3,B*N_w,N_{head},M_h*N_w,dim_{head}) ( 3 , B ∗ N w , N h e a d , M h ∗ N w , d i m h e a d ) N h e a d N_{head} N h e a d 只需要最后两个维度 进行KQV的矩阵乘法即可获得最终的多头注意力输出! 然后就是Masked掩码操作:这里使用的是加性掩码 ,掩码的生成方式见下。 输出维度不变: ( B ∗ N w , M h ∗ M w , C ) (B*N_w,M_h*M_w,C) ( B ∗ N w , M h ∗ M w , C ) def forward ( self, x, mask: Optional[ torch. Tensor] = None ) : """Args:x: input features with shape of (num_windows*B, Mh*Mw, C)mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None""" B_, N, C = x. shapeqkv = self. qkv( x) . reshape( B_, N, 3 , self. num_heads, C // self. num_heads) . permute( 2 , 0 , 3 , 1 , 4 ) q, k, v = qkv. unbind( 0 ) q = q * self. scaleattn = ( q @ k. transpose( - 2 , - 1 ) ) relative_position_bias = self. relative_position_bias_table[ self. relative_position_index. view( - 1 ) ] . view( self. window_size[ 0 ] * self. window_size[ 1 ] , self. window_size[ 0 ] * self. window_size[ 1 ] , - 1 ) relative_position_bias = relative_position_bias. permute( 2 , 0 , 1 ) . contiguous( ) attn = attn + relative_position_bias. unsqueeze( 0 ) if mask is not None : nW = mask. shape[ 0 ] attn = attn. view( B_ // nW, nW, self. num_heads, N, N) + mask. unsqueeze( 1 ) . unsqueeze( 0 ) attn = attn. view( - 1 , self. num_heads, N, N) attn = self. softmax( attn) else : attn = self. softmax( attn) attn = self. attn_drop( attn) x = ( attn @ v) . transpose( 1 , 2 ) . reshape( B_, N, C) x = self. proj( x) x = self. proj_drop( x) return x
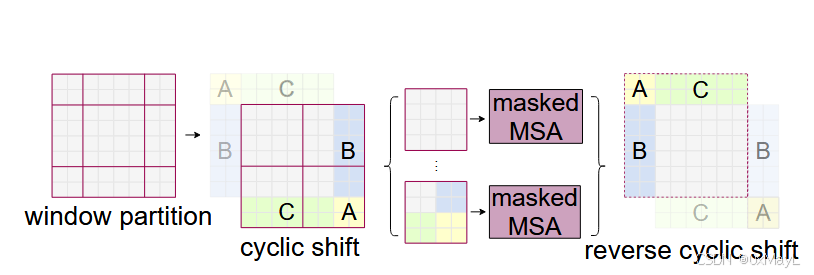
本文的核心操作:实现起来不难 实现代码:注意图像整体往右下,roll这个函数是相当于移动窗口的 ,所以是往左上移动窗口 输入和输出是以图片的格式: ( B , H ∗ W , C ) (B,H*W,C) ( B , H ∗ W , C ) if self. shift_size > 0 : shifted_x = torch. roll( x, shifts= ( - self. shift_size, - self. shift_size) , dims= ( 1 , 2 ) )
先调用移动窗口:对图像进行移动处理。 使用被移动后的图像进行窗口注意力计算,输出维度 ( B ∗ N w , M h ∗ M w , C ) (B*N_w,M_h*M_w,C) ( B ∗ N w , M h ∗ M w , C ) 还原为图像 ( B , H , W , C ) (B,H,W,C) ( B , H , W , C ) 以反方向 移动图像:x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2)) reshape为: ( B , H ∗ W , C ) (B, H * W, C) ( B , H ∗ W , C ) ,丢入MLP中处理,放大 4 C 4C 4 C C C C
def create_mask ( self, x, H, W) : Hp = int ( np. ceil( H / self. window_size) ) * self. window_sizeWp = int ( np. ceil( W / self. window_size) ) * self. window_sizeimg_mask = torch. zeros( ( 1 , Hp, Wp, 1 ) , device= x. device) h_slices = ( slice ( 0 , - self. window_size) , slice ( - self. window_size, - self. shift_size) , slice ( - self. shift_size, None ) ) w_slices = ( slice ( 0 , - self. window_size) , slice ( - self. window_size, - self. shift_size) , slice ( - self. shift_size, None ) ) cnt = 0 for h in h_slices: for w in w_slices: img_mask[ : , h, w, : ] = cntcnt += 1 mask_windows = window_partition( img_mask, self. window_size) mask_windows = mask_windows. view( - 1 , self. window_size * self. window_size) attn_mask = mask_windows. unsqueeze( 1 ) - mask_windows. unsqueeze( 2 ) attn_mask = attn_mask. masked_fill( attn_mask != 0 , float ( - 100.0 ) ) . masked_fill( attn_mask == 0 , float ( 0.0 ) ) return attn_mask