【AI论文】BitNet v2:针对1位LLM的原生4位激活和哈达玛变换
摘要:激活异常值阻碍了1位大型语言模型(LLM)的有效部署,这使得低比特宽度的量化变得复杂。 我们介绍了BitNet v2,这是一个新的框架,支持1位LLM的原生4位激活量化。 为了解决注意力和前馈网络激活中的异常值,我们提出了H-BitLinear,这是一个在激活量化之前应用在线哈达玛变换的模块。 这种转换将尖锐的激活分布平滑为更像高斯的形式,适合低位表示。 实验表明,从零开始训练的BitNet v2(采用8位激活)与BitNet b1.58的性能相当。 至关重要的是,BitNet v2在使用原生4位激活进行训练时实现了最小的性能下降,显著减少了批量推理的内存占用和计算成本。Huggingface链接:Paper page,论文链接:2504.18415
研究背景和目的
研究背景
随着深度学习技术的飞速发展,特别是在自然语言处理(NLP)和计算机视觉(CV)领域的突破,大型语言模型(LLMs)的部署和应用变得越来越广泛。然而,这些模型通常具有庞大的参数规模和计算需求,限制了它们在资源受限环境中的应用。为了提高LLMs的部署效率,量化技术成为了一个重要的研究方向。量化技术通过减少模型的位宽,可以在不显著牺牲性能的情况下显著降低模型的内存占用和计算成本。
然而,现有的量化方法在低比特宽度(如4位或更低)下仍然面临挑战。特别是在处理1位LLMs时,激活异常值成为了一个主要问题。这些异常值在量化过程中会引入显著的误差,从而影响模型的性能。因此,如何在低比特宽度下有效地量化1位LLMs的激活,同时保持其性能,是当前研究中的一个难点。
针对这一挑战,研究者们提出了多种方法,如选择性量化、稀疏化等。然而,这些方法往往需要在性能和效率之间进行权衡,无法同时实现最优的性能和最低的计算成本。因此,开发一种能够原生支持低比特宽度激活量化的框架,同时保持模型的高性能,是当前研究的重要目标。
研究目的
本研究旨在提出一种新颖的框架——BitNet v2,用于实现1位LLMs的原生4位激活量化。通过引入在线哈达玛变换(Hadamard Transformation),BitNet v2能够有效地解决激活异常值问题,从而在低比特宽度下保持模型的高性能。同时,本研究还旨在通过实验验证BitNet v2的有效性,并探索其在不同任务上的性能表现。
具体来说,本研究的目标包括:
- 提出BitNet v2框架,支持1位LLMs的原生4位激活量化。
- 引入在线哈达玛变换,解决激活异常值问题,提高量化性能。
- 通过实验验证BitNet v2在多个语言任务上的有效性,并与现有量化方法进行对比。
- 探索BitNet v2在批量推理场景下的效率提升,为实际应用提供技术支持。
研究方法
BitNet v2框架
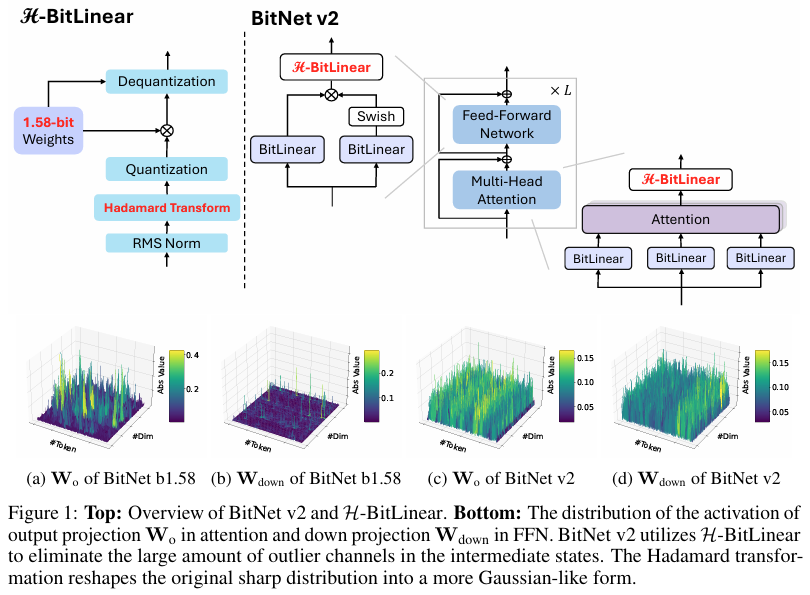
BitNet v2框架基于LLaMA等现有LLM架构,通过引入H-BitLinear模块实现原生4位激活量化。H-BitLinear模块在激活量化之前应用在线哈达玛变换,将尖锐的激活分布平滑为更像高斯的形式,从而更适合低比特宽度表示。这种变换有效地减少了激活异常值对量化性能的影响。
在训练过程中,BitNet v2首先使用8位激活进行预训练,以确保模型的收敛性。然后,通过继续训练将模型的激活位宽降低到4位,同时保持模型的高性能。为了支持这种混合精度训练,本研究采用了直通估计器(Straight-Through Estimator, STE)进行梯度近似,并使用了混合精度训练来更新参数。
在线哈达玛变换
在线哈达玛变换是BitNet v2框架的核心创新点之一。它通过将原始的激活分布转换为更像高斯的形式,显著减少了激活异常值对量化性能的影响。具体来说,哈达玛变换通过乘以一个哈达玛矩阵来实现,该矩阵具有正交性和快速计算的性质。在BitNet v2中,哈达玛变换被应用于注意力机制中的输出投影和前馈网络中的下投影。
实验设置
为了验证BitNet v2的有效性,本研究在多个语言任务上进行了实验,包括ARC-Easy、ARC-Challenge、Hellaswag、Winogrande、PIQA和LAMBADA等。这些任务涵盖了逻辑推理、常识推理和长文本理解等多个方面,能够全面评估模型的性能。
在实验过程中,本研究采用了lm-evaluation-harness工具包来评估模型的零样本准确率,并报告了C4验证集上的困惑度(PPL)。同时,为了与现有量化方法进行对比,本研究还实现了基于BitNet b1.58的基线模型,并采用了QuaRot和SpinQuant等后训练量化方法作为对比。
研究结果
性能表现
实验结果表明,BitNet v2在多个语言任务上均取得了优异的性能。具体来说,在使用8位激活进行预训练的情况下,BitNet v2的性能与BitNet b1.58相当,甚至在某些任务上取得了更好的表现。这表明BitNet v2框架能够有效地支持高性能LLMs的训练。
更重要的是,在使用原生4位激活进行训练的情况下,BitNet v2的性能下降非常有限。具体来说,对于3B和7B模型尺寸,BitNet v2的零样本准确率与8位激活版本相比下降了不到1个百分点,而困惑度则基本保持不变。这表明BitNet v2框架能够在保持高性能的同时,显著降低模型的内存占用和计算成本。
与现有方法的对比
与现有量化方法相比,BitNet v2在性能和效率之间取得了更好的平衡。具体来说,与QuaRot和SpinQuant等后训练量化方法相比,BitNet v2在零样本准确率和困惑度上均取得了更好的表现。这表明BitNet v2框架通过引入在线哈达玛变换和混合精度训练等技术,能够更有效地解决激活异常值问题,从而提高量化性能。
批量推理效率
此外,实验结果表明BitNet v2在批量推理场景下具有显著的效率提升。具体来说,使用原生4位激活的BitNet v2模型在进行批量推理时,能够显著减少内存占用和计算成本,从而提高推理速度。这对于资源受限环境下的LLM部署具有重要意义。
研究局限
尽管BitNet v2框架在1位LLMs的原生4位激活量化方面取得了显著进展,但仍然存在一些局限性。首先,BitNet v2的性能仍然受到量化误差的影响,特别是在处理极端复杂任务时可能会出现性能下降。其次,BitNet v2框架的复杂性较高,需要较高的计算资源来进行训练和推理。此外,BitNet v2的通用性仍有待验证,需要进一步探索其在其他类型LLMs和任务上的表现。
未来研究方向
针对上述局限性,未来的研究可以从以下几个方面进行探索:
-
优化量化算法:进一步研究和优化量化算法,减少量化误差对模型性能的影响。特别是针对极端复杂任务,可以探索更精细的量化策略和补偿方法。
-
提高计算效率:研究如何提高BitNet v2框架的计算效率,降低训练和推理过程中的资源消耗。特别是针对大规模LLMs,可以探索分布式训练、模型压缩等技术来提高计算效率。
-
增强通用性:进一步验证BitNet v2框架的通用性,探索其在其他类型LLMs和任务上的表现。特别是针对特定领域或任务,可以定制化的BitNet v2框架来提高性能。
-
结合其他技术:研究如何将BitNet v2框架与其他技术相结合,如知识蒸馏、剪枝等,以进一步提高模型的性能和效率。特别是针对资源受限环境,可以探索如何将这些技术应用于BitNet v2框架中以实现更高效的LLM部署。
综上所述,本研究通过提出BitNet v2框架,为1位LLMs的原生4位激活量化提供了新的解决方案。未来的研究将继续探索如何进一步优化该框架,提高模型的性能和效率,为实际应用提供更强有力的技术支持。