LangGraph简单使用
一、 LangGraph简介
LangGraph 是基于 LangChain 构建的一种 状态机驱动的智能体编排框架,它将 Agent 系统建模设计
为(有向图)流程图,每个节点为一个计算步骤,每条边()表示状态转移路径,适合处理复杂流程或多
Agent 协作系统。
LangGraph 的特点:
✅ 更清晰的任务流程建模能力(流程图)
✅ 支持复杂控制流(如循环、条件分支、并行)
✅ 状态可持久化,适合长周期任务
✅ 灵活集成 Tool、Memory、Agent 等组件
官方文档
二、LangGraph 与 LangChain 对比
| 特性 | LangChain(Chain) | LangGraph(Graph) |
|---|---|---|
| 控制流程 | 线性 | 可分支、循环、并行 |
| 复杂度管理 | 较难 | 模块化、清晰可控 |
| 多 Agent 协作 | 较难实现 | 易于设计多个节点交互 |
| 适合任务类型 | 单步/固定任务 | 多步骤、有状态流程 |
| 智能体开发 | 不适合 ❌ | 适合 ✅ |
三、LangGraph 核心概念
| 概念 | 说明 |
|---|---|
| Graph | 表示整个(有向图)流程图,由多个节点(函数 |
| Node | 流程中的一个步骤,如“请求接口”,“查询知识库” |
| State | 每个节点输入输出的共享上下文(支持记忆),字典(一个Graph中只有一个state) |
| Edge | 节点之间的连接,可以是条件跳转、循环或并行 |
| Runnable | 可执行单元,如一个 chain 或工具调用 |
| Config | 流程执行配置,包括初始状态、路由逻辑等 |
四、Graph的标准构建流程
1. 定义状态(State)
也就是流程中用于交互的数据
注意:
- 所有流转的数据都必须是字典格式
- 类型标注是强制要求(提升开发正确性),一个流程只能有一个State
from typing import TypedDict
# 定义状态
class State(TypedDict):user_input: stranswer: strquery_type: str
2.定义节点(执行的函数)
每一个节点就是一个处理函数,它接受一个 State 作为输入,并返回一个更新后的State。
注意:
- 必须返回字典
- 可以只返回局部更新字段,LangGraph自动合并回完整状态
# ######## 定义节点 #########
# 定义选择节点
def select_node(state: State) -> dict:prompt = f"""你是一个AI智能体,你的任务是判断用户输入的是什么学科类型的信息,有物理,数学,历史这三种类型。如果是物理类型的问题就回答"物理",如果是数学类型的问题就回答"数学",如果是历史相关就回答"历史"如果都不是则返回"其他"用户输入如下:{state['user_input']}"""res = llm.invoke(prompt)if "物理" in res.content:return {"query_type": "physics"}elif "数学" in res.content:return {"query_type": "math"}elif "历史" in res.content:return {"query_type": "history"}else:return {"query_type": "other"}# 定义物理节点
def physics(state: State) -> dict:physics_template = f"""你是一位物理学家,擅长回答物理相关的问题,当你不知道问题的答案时,你就回答不知道。具体问题如下:{state['user_input']}"""res = llm.invoke(physics_template)return {"answer": res.content}# 数学节点
def math(state: State) -> dict:math_template = f"""你是一个数学家,擅长回答数学相关的问题,当你不知道问题的答案时,你就回答不知道。具体问题如下:{state['user_input']}"""res = llm.invoke(math_template)return {"answer": res.content}# 历史节点
def history(state: State) -> dict:history_template = f"""你是一个非常厉害的历史老师,擅长回答历史相关的问题,当你不知道问题的答案时,你就回答不知道。具体问题如下:{state['user_input']}"""res = llm.invoke(history_template)return {"answer": res.content}def other(state: State) -> dict:return {"answer": "其他类型,不做处理"}
3. 创建langGraph对象
from langgraph.graph import StateGraph
graph = StateGraph(State)
4. 添加节点
# 添加节点
graph.add_node("select_node", select_node)
graph.add_node("physics", physics)
graph.add_node("math", math)
graph.add_node("history", history)
graph.add_node("other", other)
5. 添加边
也就是节点相互之间的联系
# 例如:
graph.add_edge('node1', "node2") # 表示节点1执行完成就执行节点2
from langgraph.constants import START, END
# 添加边Edge
graph.add_edge(START, "select_node")# 路由选择
def router(state: State):if state["query_type"] == "physics":return "physics"elif state["query_type"] == "math":return "math"elif state["query_type"] == "history":return "history"else:return "other"graph.add_conditional_edges("select_node", router, {"physics": "physics","math": "math","history": "history","other": "other"
})graph.add_edge("physics", END)
graph.add_edge("math", END)
graph.add_edge("history", END)
graph.add_edge("other", END)
add_conditional_edges 是添加条件节点,当节点"select_node"处理完成,就执行router函数,router返回"physics"就执行"physics"节点,这两个值不一定非要设置一样的,看自己节点怎么定义的。
6. 编译为可执行图
app = graph.compile()
6.1 查看流程图
pic = app.get_graph().draw_mermaid_png()
with open('./graph_pic.png', 'wb') as f:f.write(pic)
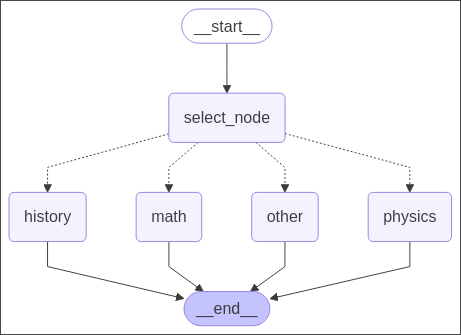
6.2 执行
if __name__ == "__main__":# pic = app.get_graph().draw_mermaid_png()# with open('./graph_pic.png', 'wb') as f:# f.write(pic)# 可以用invoke,也可以stream查看每一步操作res = app.stream({"user_input": "你好?"})# res = app.stream({"user_input": "秦始皇是谁?"})for i in res:print(i)
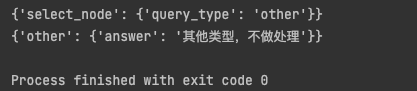

也可以从langsmith查看步骤
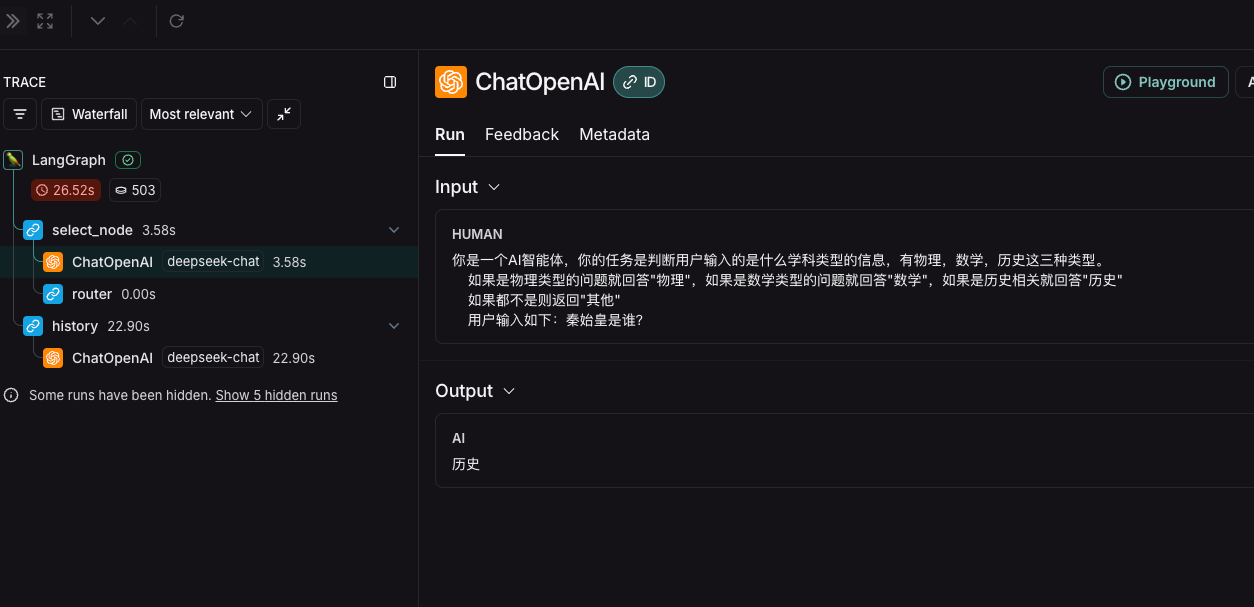
可以看到确实先将输入内容进行分析,然后选择不同的节点执行的。