【AI论文】Skywork R1V2:用于推理的多模态混合强化学习
摘要:我们展示了Skywork R1V2,这是下一代多模态推理模型,也是其前身Skywork R1V的重大飞跃。 R1V2的核心是引入了一种混合强化学习范式,将奖励模型指导与基于规则的策略相协调,从而解决了长期以来在复杂的推理能力和广泛的泛化能力之间取得平衡的挑战。 为了进一步提高训练效率,我们提出了选择性样本缓冲(SSB)机制,该机制通过在整个优化过程中优先考虑高价值样本,有效地解决了组相对策略优化(GRPO)中固有的“消失优势”困境。 值得注意的是,我们观察到过度的强化信号可以诱导视觉幻觉——一种我们通过在整个训练过程中校准奖励阈值来系统地监测和减轻的现象。 实证结果证实了R1V2的卓越能力,其基准领先性能如OlympiadBench为62.6,AIME2024为79.0,LiveCodeBench为63.6,MMMU为74.0。 这些结果凸显了R1V2相对于现有开源模型的优越性,并证明了在缩小与包括Gemini 2.5和OpenAI o4-mini在内的主要专有系统的性能差距方面取得了重大进展。 Skywork R1V2模型的权重已公开发布,以促进开放性和可重复性。 https://huggingface.co/Skywork/Skywork-R1V2-38B。Huggingface链接:Paper page,论文链接:2504.16656
研究背景和目的
研究背景
随着人工智能技术的飞速发展,尤其是在自然语言处理(NLP)和计算机视觉(CV)领域的突破,多模态推理模型逐渐成为研究热点。这些模型旨在整合来自不同模态的信息,如文本、图像和视频,以实现更高级别的理解和推理能力。然而,尽管现有模型在多模态任务上取得了显著进展,但在复杂推理和泛化能力之间取得平衡仍然是一个重大挑战。特别是在处理需要深入理解和结构化推理的问题时,如数学、科学问题和一些需要视觉解释的复杂场景,现有模型往往表现出性能不足或泛化能力有限的问题。
传统上,多模态模型的训练依赖于大规模标注数据,通过监督学习的方式进行。然而,这种方法在提升模型的推理能力方面存在局限性,尤其是在面对需要高度创造性和抽象思维的任务时。此外,一些先进模型虽然展示了强大的推理能力,但它们在通用视觉任务上的表现却不尽如人意,这表明了推理能力和泛化能力之间的权衡问题。
为了应对这些挑战,研究者们开始探索强化学习(RL)和偏好学习(Preference Learning)在多模态模型训练中的应用。强化学习通过为模型提供奖励信号来指导其行为,使其能够在没有显式监督的情况下学习复杂的策略。偏好学习则通过比较不同候选输出的质量来优化模型,使其输出更符合人类的期望。然而,将这两种方法有效地结合到多模态模型的训练中,特别是针对复杂推理任务,仍然是一个待解决的问题。
研究目的
本研究旨在提出一种新颖的多模态混合强化学习范式,以解决在多模态推理模型中平衡复杂推理能力和广泛泛化能力的挑战。具体目标包括:
- 开发一种混合强化学习范式:结合奖励模型指导和基于规则的策略,以在复杂推理和泛化能力之间取得平衡。
- 提升训练效率:提出选择性样本缓冲(SSB)机制,通过优先考虑高价值样本来解决GRPO中的“消失优势”问题。
- 减轻视觉幻觉现象:通过校准奖励阈值来系统地监测和减轻由于过度强化信号引起的视觉幻觉现象。
- 展示模型的卓越性能:在多模态推理基准上评估所提出的模型,并证明其在缩小与专有系统性能差距方面的进展。
研究方法
模型架构
Skywork R1V2模型是在其前身Skywork R1V的基础上发展而来的下一代多模态推理模型。R1V2的核心是引入了一种混合强化学习范式,该范式结合了Mixed Preference Optimization(MPO)和Group Relative Policy Optimization(GRPO)算法。
- MPO:用于优化响应对的相对偏好、单个响应的绝对质量以及生成优选响应的过程。通过Skywork-VL奖励模型提供高质量的偏好信号,MPO有效地减轻了输出中的重复链式思考和过度思考现象。
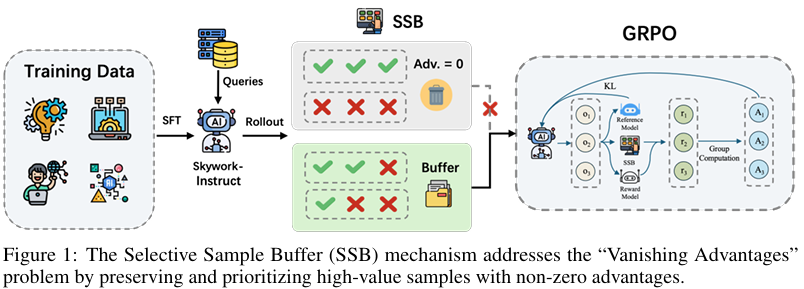
- GRPO:通过比较同一查询组内的候选响应来计算相对优势。然而,随着训练的进行,候选响应往往趋于一致(即全部正确或全部错误),导致优势信号消失和推理多样性受限。为了解决这个问题,R1V2引入了SSB机制。
选择性样本缓冲(SSB)机制
SSB机制通过识别和缓存先前迭代中具有非零优势的高质量训练样本来工作。这些样本在策略更新过程中被战略性地重新引入,从而维持了一个梯度丰富的训练环境。即使在模型响应趋于一致的情况下,SSB也能确保持续提供有价值的训练信号。
奖励模型校准
为了减轻由于过度强化信号引起的视觉幻觉现象,R1V2在整个训练过程中通过校准奖励阈值来系统地监测和减轻这一现象。通过调整奖励阈值,R1V2能够在保持模型推理能力的同时,减少不必要的幻觉输出。
训练和优化
R1V2的训练过程包括以下几个步骤:
- 预训练:使用预训练的视觉编码器(如InternViT-6B)和语言模型(如QwQ-32B)来初始化模型。
- MPO优化:通过MPO优化模型,使用Skywork-VL奖励模型提供的偏好信号来指导训练。
- GRPO优化:在MPO优化的基础上,应用GRPO算法进行进一步的策略优化,同时使用SSB机制来提高训练效率。
- 奖励模型校准:在整个训练过程中,通过校准奖励阈值来减轻视觉幻觉现象。
研究结果
基准性能
R1V2在多个多模态推理基准上展示了卓越的性能,包括:
- OlympiadBench:62.6%,显著优于现有开源模型,并接近专有系统的性能。
- AIME2024:79.0%,在多个数学竞赛问题上取得了优异的表现。
- LiveCodeBench:63.6%,在编程能力评估中展示了强大的代码理解和生成能力。
- MMMU:74.0%,在跨学科多模态理解基准上取得了领先性能。
与现有模型的比较
与现有开源模型(如Skywork-R1V1、InternVL3-38B、Qwen2.5-VL-72B等)相比,R1V2在大多数基准上均取得了显著的性能提升。与专有系统(如Gemini 2.5、OpenAI o4-mini)相比,R1V2的性能差距也大幅缩小,甚至在某些基准上超过了这些专有系统。
消融研究
消融研究进一步验证了R1V2中各个组件的有效性。特别是SSB机制显著提高了训练效率和模型性能,证明了其在解决“消失优势”问题中的关键作用。
研究局限
尽管R1V2在多模态推理任务上展示了卓越的性能,但仍然存在一些局限性:
- 模型复杂度:R1V2的模型复杂度较高,需要较大的计算资源来进行训练和推理。这限制了其在资源受限环境下的应用。
- 泛化能力:尽管R1V2在多个基准上展示了强大的泛化能力,但在某些特定领域或任务上仍可能存在泛化不足的问题。
- 数据依赖性:R1V2的性能在很大程度上依赖于训练数据的质量和多样性。如果训练数据不足以覆盖所有可能的场景和任务,模型的性能可能会受到影响。
未来研究方向
针对上述局限性,未来的研究可以从以下几个方面进行探索:
- 模型压缩和优化:研究如何降低R1V2的模型复杂度,提高其在资源受限环境下的应用性能。这可能包括模型剪枝、量化等技术。
- 增强泛化能力:探索如何通过引入更多的训练数据、使用数据增强技术或采用更先进的正则化方法来提高R1V2的泛化能力。
- 跨模态融合机制:进一步研究如何更有效地融合来自不同模态的信息,以提高R1V2在复杂多模态任务上的表现。这可能包括开发更先进的跨模态注意力机制或融合策略。
- 应用场景拓展:将R1V2应用于更多实际场景中,如自动驾驶、医疗影像分析、教育辅助等,以验证其在实际应用中的有效性和可靠性。
综上所述,本研究通过提出Skywork R1V2模型,为多模态推理领域带来了新的突破。未来的研究将继续探索如何进一步提高模型的性能和应用范围,以实现更智能、更可靠的多模态人工智能系统。