机器学习概述
1.什么是机器学习
机器学习,顾名思义,就是让机器去学习,我们先来看百度百科对于机器学习的定义:
(1)机器学习是一门人工智能的科学,该领域的主要研究对象是人工智能,特别是如何在经验学习中改善具体算法的性能;
(2)机器学习是对能通过经验自动改进的计算机算法的研究;
(3)机器学习是用数据或以往的经验,以此优化计算机程序的性能标准。
讲了这么多,在我看来,其实机器学习就是让计算机具备像人一样经验学习的能力。
我们举个例子,就拿五一放假来说,以往每年休假的经验告诉我们五一的时候会调休放假五天,而不是只放五一这一天。这个就是我们根据过往所总结出的规律,通过这个规律,我们能够在未放假前就能预测到五一的放假情况,整个过程图示如下:
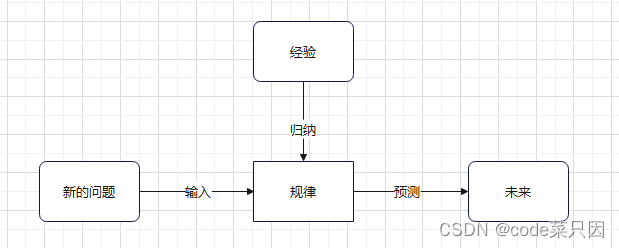
而这个过程的实现用机器学习来代替则是:
以往每年五一休假的经验是历史数据,我们用这个历史数据去训练一个模型,训练完成的模型就是我们所总结出的规律,当新的五一即将到来时,这个训练完成的模型就能预测到五一的调休放假情况,图示如下:
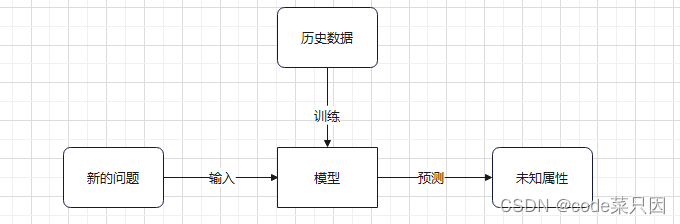
2.机器学习的工作流程
机器学习的工作流程分为以下几步:
获取数据、数据基本处理、特征工程、模型训练、模型评估。
如果评估的结果没有达到要求,那就要重复上面的流程,如果达到预期效果,则上线投入使用。
2.1 数据的简介及获取
2.1.1数据类型
在数据集中,有些数据是有特征值与目标值的(这些目标值是连续的和离散的),而有些数据是只有特征值而没有目标值,我们来举个例子:
就拿《机器学习》这本书中举的例子来说,判断西瓜是否成熟有根蒂、色泽、敲声三个因素,现在我们拿到数据如下:
| 根蒂 | 色泽 | 敲声 | 西瓜状态 |
| 蜷缩 | 深绿色 | 沉闷 | 熟瓜 |
| 笔直 | 浅白色 | 清脆 | 生瓜 |
在上面的数据中,我们一般将一行数据称为样本,将一列数据称为特征,在上面的表格中,很明显西瓜的生和熟就是我们上面所说的目标值,前面的三列是特征值。
2.1.2 数据的获取
我们可以从哪些地方获取数据集呢?这里给大家推荐几个网址。
UCI数据集官网:UCI Machine Learning Repository: Data Sets
kaggle:Kaggle: Your Machine Learning and Data Science Community
2.2 数据基本处理与特征工程
数据的基本处理包括对数据进行缺失值、去除异常值等处理。
特征工程是利用专业知识和现有的数据,创造出新的特征,使得特征能在算法当中发挥出更好的作用。
特征工程会直接影响机器学习的效果,俗话说:“数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。”
特征工程包含的内容有特征提取、特征预处理、特征降维;由于本篇文章是帮助小白快速了解机器学习的整体框架与含义,因此就不对特征工程进行进一步的说明,后续会再作补充。
3.机器学习分类
在完成前面那些步骤之后,就可以开始选择合适的算法对模型进行训练了,也叫做机器学习。
机器学习常见的分类有:
监督学习、无监督学习、半监督学习以及强化学习。
接下来就对这几类算法进行一个简单的介绍。
3.1 监督学习
监督学习的输入数据是由输入特征值和目标值所组成,监督学习中的问题大致可分为两类,若输出的是一个连续的值,可称为回归问题,若输出的是有限个离散值,可称为分类问题。
3.2 无监督学习
无监督学习的输入数据则是只有输入特征值,而没有目标值,简单来说,就是我们无法知道每个输入数据的输出会是什么。无监督学习的目标通常包括聚类、降维和异常检测。聚类是将数据点进行分组,使得同一组内的数据点相似度较高,不同组之间的相似度较低,常见的聚类算法有k-means和层次聚类等;降维则是在保留数据重要信息的前提下降低数据的维度,例如主成分分析、t-SNE等;异常检测则是识别与大多数据点不同的异常值。
3.3 半监督学习
半监督学习是一种监督学习和无监督学习相结合的学习方法,同时使用大量未标注的数据和已标注的数据进行模式识别工作。它的优势在于能够充分利用大量未标注数据结合少量已标注数据提升模型性能,而且大大减少了标签标注的成本和时间。半监督学习的分类有半监督分类、半监督回归、半监督聚类和半监督降维。半监督分类是在无类标签的样例的帮助下训练有类标签的样本;半监督回归是在无输出的输入的帮助下训练有输出的输入样本,通过半监督学习获得的分类器和回归器,其性能都要比使用监督学习的性能更优。半监督聚类则是在有类标签的样本的帮助下,获得比只用无类标签的样本得到的结果更好的簇,半监督降维是在有类标签的样本的帮助下,找到高维输入数据的低维结构。半监督学习的常见算法有自训练、协同训练、图基方法和生成模型等。
3.4 强化学习
3.4.1 强化学习的概念
强化学习介于监督学习与非监督学习之间,是一种基于试错法的机器学习范式。它主要由智能体、环境、状态、行动、奖励、策略和价值函数组成,智能体在环境给予的奖励或惩罚的刺激下不断尝试并通过反馈来调整其行为,以达到某种目标。强化学习的主要算法有Q-Learning、深度Q网络(DQN)、策略梯度等。
3.4.2 强化学习的分类及应用
强化学习主要可以分为有模型的强化学习和无模型的强化学习两类,有模型的强化学习有动态规划算法,无模型的强化学习有蒙洛卡特法和时间差分法。动态规划法是将大问题分解为多个小问题,通过求多个小问题的最优解来得到大问题的最优解。蒙洛卡特法则是通过构造概率统计模型给出问题的统计估计值和精度估计值。时间差分法可分为在线控制和离线控制,在线控制即一直使用一个策略来更新价值函数,离线控制则是使用两个策略,一个用于选择新动作,另一个用于更新价值函数。