GPU 架构入门笔记
引文位置:https://www.trainy.ai/blog/gpu-utilization-misleading
相关概念是通过 ChatGPT 迅速学习总结而成。
概念:
GPU
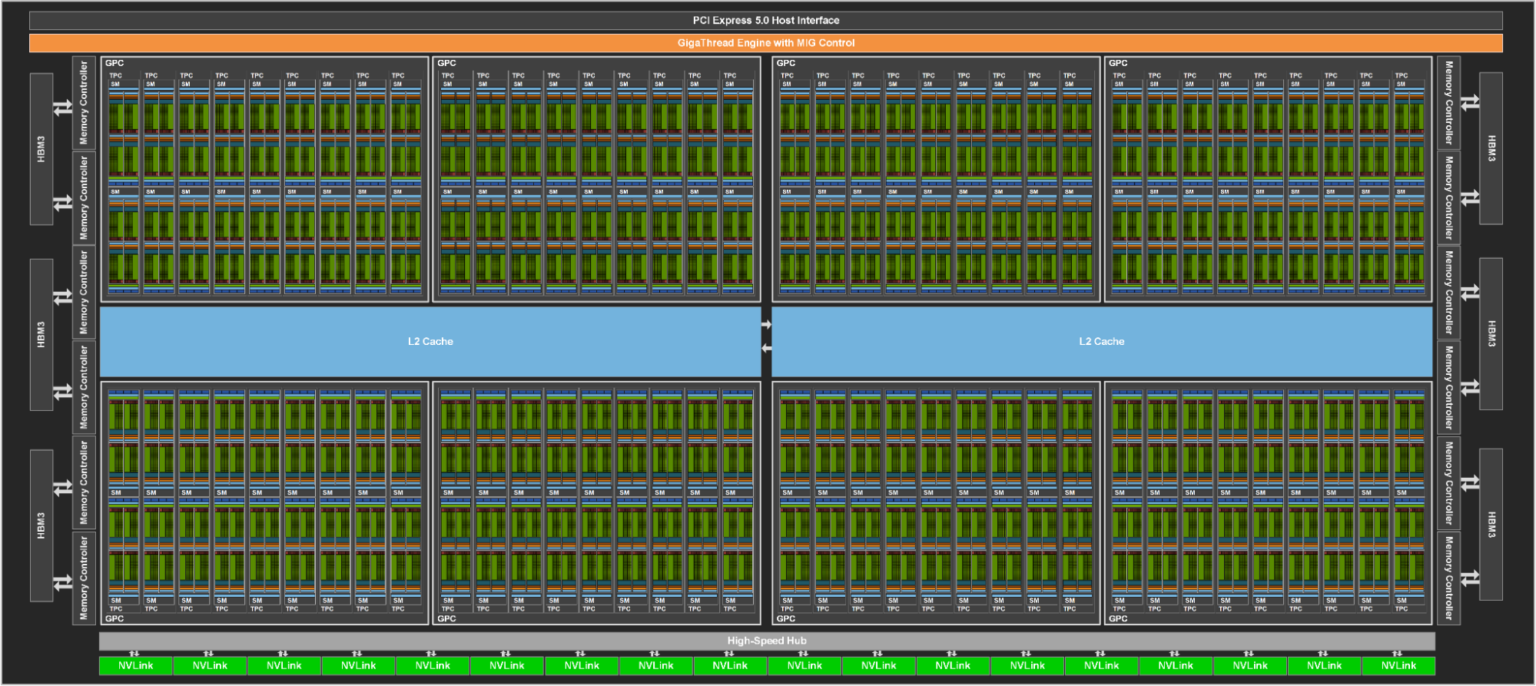
- H100 GPU, with 144 SMs
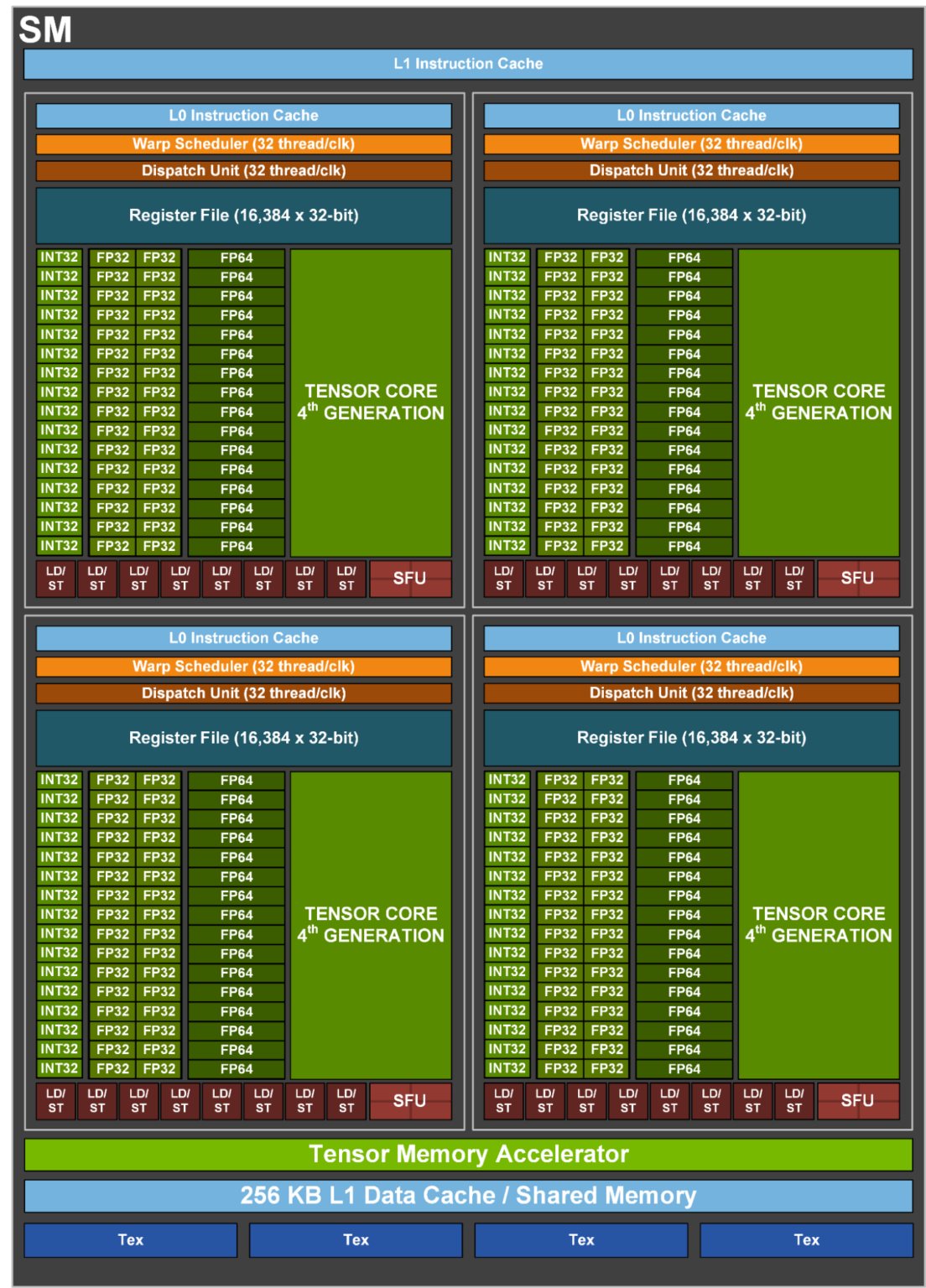
每个 SM(streaming multiprocessors) 的架构:
GPU Utilization:
- GPU Utilization, is only measuring whether a kernel is executing at a given time.
- 也就是数,只要有 kernel 在 GPU 上跑,就算把 GPU 利用起来了。至于这个 kernel 对硬件资源的利用率,GPU Utilization 不关心。比如,这个kernel 只是在做 GPU Memory 的读写,0 FLOPS,此时的 GPU Utilization 也能达到 100%。
SM efficiency:
- describing what % of SMs are active in a given time interval. SMs can be thought of as foremen for a group of CUDA cores. An Nvidia H100 GPU, for example, has 132 SMs, with 128 cores per SM, giving us a total of 16,896 cores. By measuring SM efficiency, we can determine whether our CUDA kernels are using our streaming multiprocessors. If we have a CUDA kernel that continuously runs for 10 seconds but only uses 1 SM, on an H100, this would register 100% utilization, but the SM efficiency would be 1 / 132 = 0.7%.
- SM 效率关注的是 SM 是否被使用。每个 SM 里,哪怕只有一个 core 被使用,那么这个 SM 就是活跃的。
Core efficiency:
- Core:SM里面的最基本小算力单元,执行真正的加减乘除指令。
- 没找到这个概念。但理论上这个是最精确描述硬件利用率的指标。
编程接口侧,为了提升 GPU 利用率,定义了若干概念:
BLOCK:
- CUDA 为了让 GPU 跑满定义的概念。每个 BLOCK 会被调度到一个 SM 上。所以,一个 kernel 如果希望能充分利用上所有 SM,它的 BLOCK 数要尽量和总 SM 个数匹配,比如是 SM 的整数倍。
THREAD:
- 程序中定义的一个 thread 最终会被放到一个 WARP 中执行。
- kernel是你写的一段程序,当你 launch 一个kernel的时候,会分配一堆 thread 去执行这个 kernel。每个 thread 独立跑一遍你的 kernel代码。
KERNEL
- CUDA 定义的最小程序单元
- KERNEL 不宜过大,中间状态不宜过多。如果超过了寄存器限制,CUDA 则会编译成类似 C++ 里的方式,用显存做暂存区,会导致寄存器和显存的频繁交互,对性能的影响是致命的。
WARP:
- GPU 调度的最小单位,一个 WARP 打包 32 个 thread。
- 所谓 GPU 调度,是指将 kernel 代码调度到 SM 上执行。考虑一个 BLOCK 里写了 128 个 THREAD,但一个 SM 里寄存器资源远远低于128。GPU 定义的物理上限就是同一时间只能执行 32 组线程。 WARP 就是定义 32 这个概念的,它是物理概念。 BLOCK 是面向编程的逻辑概念。GPU 一次调度一个 WARP,一个 BLOCK 会被分成多个 WARP 依次调度执行。
- 为什么选 32?实际上,SM 里的物理资源不足以同时执行 32 个 thread。通过规划 32 个 thread,可以在局部形成流水线,隐藏掉大部分的访存延迟。32个访存,有机会做访存合并。
时钟周期: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 ...
warp1: 执行 → stall (等内存) ─────────────
warp2: 执行 → stall (等内存) ───────
warp3: 执行 → stall (等内存) ─
warp4: 执行 → stall
warp5: 执行 → stall