数据操作 + 数据预处理
- 1.数据操作
- 运行结果
- 2.数据预处理实现
- 运行结果
第四课链接
1.数据操作
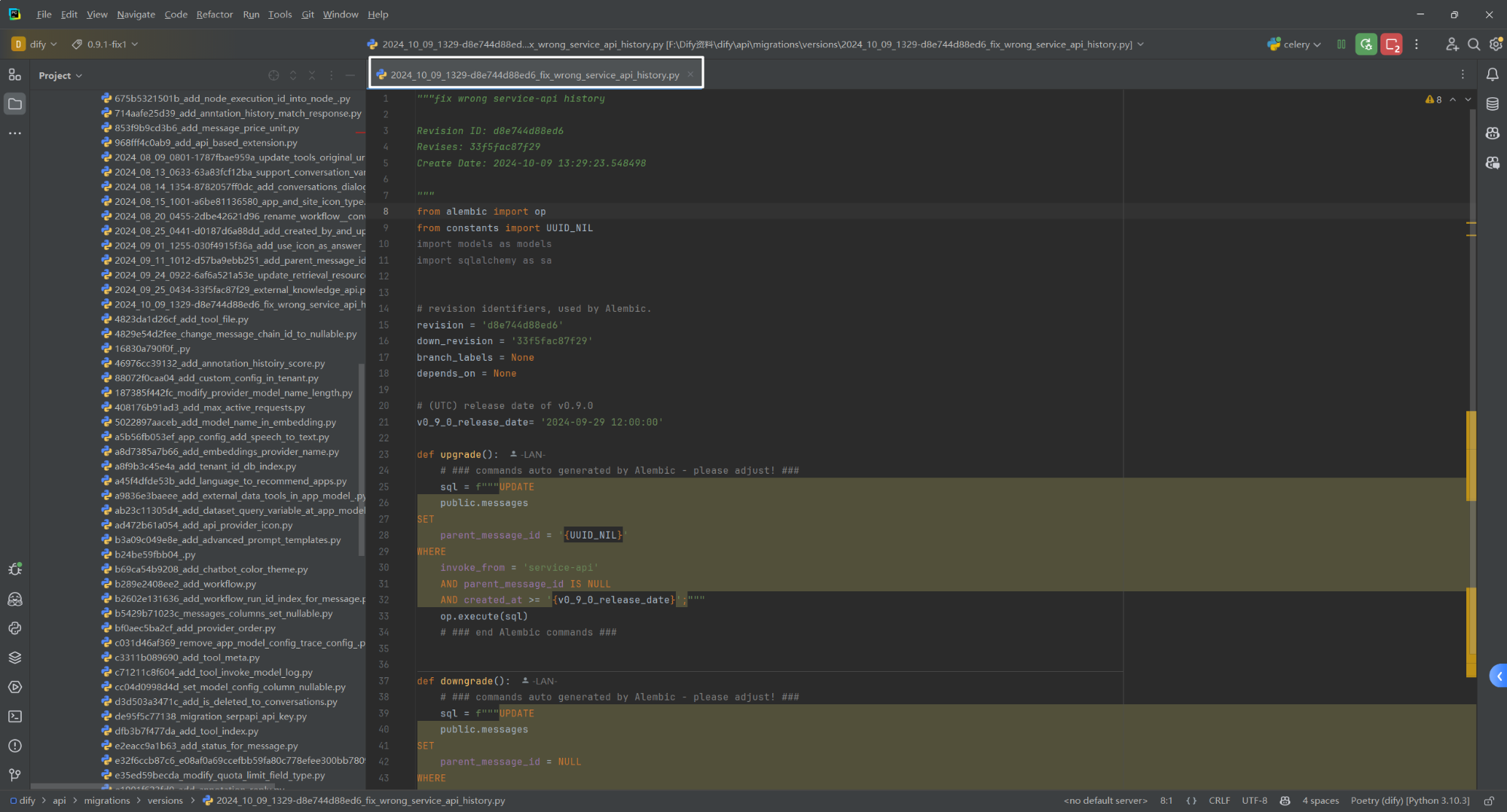
import torch
# 张量的创建
x1 = torch.arange(12)
print('1.有12个元素的张量:\n',x1)
print('2.张量的形状:\n',x1.shape)
print('3.张量中元素的总数:\n',x1.numel())y1=x1.reshape((3,4)) # 改变一个张量的形状而不改变元素数量和元素值
print('4.改变形状后的张量\n',y1)z=torch.zeros((2,3,4))
print('5.全0张量\n',z) # 创建一个张量,其中所有元素都设置为0
w=torch.ones((2,3,4))
print('6.全1张量\n',w)# 创建一个张量,其中所有元素都设置为1
q=torch.tensor([[1,2,3,4],[2,1,4,3],[2,3,4,1]])
print('7.特定值张量\n',q) # 通过提供包含数值的 Python 列表(或嵌套列表)来为所需张量中的每个元素赋予确定值# 张量的运算x=torch.tensor([1.0,2,4,8])
y=torch.tensor([2,2,2,2])
print('8.张量的运算,加减乘除求幂\n',x+y,x-y,x*y,x/y,x**y) # **运算符是求幂运算
print('9.按元素做指数运算\n',torch.exp(x))x2=torch.arange(12,dtype=torch.float32).reshape(3,4)
y2=torch.tensor([[2.0,1,4,3],[1,2,3,4],[4,3,2,1]])
print('10.连结:\n',torch.cat((x2,y2),dim=0),torch.cat((x2,y2),dim=1)) # 连结(concatenate) ,将它们端到端堆叠以形成更大的张量。
print('11.逻辑运算符 构建二元张量:\n',x2==y2) # 通过 逻辑运算符 构建二元张量
print('12.张量所有元素的和:\n',x2.sum()) # 张量所有元素的和# 广播机制
a=torch.arange(3).reshape(3,1)
b=torch.arange(2).reshape(1,2)
print('13.广播机制:\n',a+b)# 元素访问
x4=torch.arange(12,dtype=torch.float32).reshape(3,4)
print('14.元素访问:\n',x4[-1],x4[1:3]) # 用 [-1] 选择最后一个元素, 用 [1:3] 选择第二个和第三个元素]
x4[1,2]=9 # 写入元素。
x4[0:2,:]=12 # 写入元素。
print('15.写入元素:\n',x4)#转换为其他python对象a2= x.numpy()
print('16.转换为numpy张量:\n',type(a2))
b2=torch.tensor(a2)
print('17.转换为torch张量:\n',type(b2))a3=torch.tensor([3.5])
print('18.转换为python标量:\n',a3,a3.item(),float(a3),int(a3))运行结果


2.数据预处理实现
读取csv原始数据文件,做一定的预处理(处理缺失数据),再变为torch可用的tensor
csv:每一行是一个数据,域用逗号隔开
NA:未知的数
一般读取csv文件使用pandas库
import os
import pandas as pd
import torch
# 创建csv文件
os.makedirs(os.path.join('..','data'), exist_ok=True) # 在上级目录创建data文件夹
data_file=os.path.join('..','data','house_tiny.csv') # 创建文件
with open(data_file,'w')as f: # 创建文件f.write('NumRooms,Alley,prince\n') #列名f.write('NA,Pave,127500\n') #每行表示一个数据样本f.write('2,NA,10600\n')f.write('4,NA,178100\n')f.write('NA,NA,140000\n') # 第4行的值
# 加载CSV文件
data=pd.read_csv(data_file)
print('1.原始数据:\n',data)# 数据预处理,处理缺失的数据(插值)inputs,outputs=data.iloc[:,0:2],data.iloc[:,2]
#数值预处理
inputs=inputs.fillna(inputs.mean()) # 用均值填充NaN
#非数值预处理
# 利用pandas中的get_dummies函数来处理离散值或者类别值。
# [对于 inputs 中的类别值或离散值,我们将 “NaN” 视为一个类别。] 由于 “Alley”列只接受两种类型的类别值 “Pave” 和 “NaN”
inputs=pd.get_dummies(inputs,dummy_na=True)print('2.预处理后的数据:\n',inputs)x,y=torch.tensor(inputs.values),torch.tensor(outputs.values)
print('3.转换为张量:\n',x,y)
运行结果