小白如何学会完整挪用Github项目?(以pix2pix为例)
[目录]
0.如何完整地复现/应用一个Github项目
1.建立适用于项目的环境
2.数据准备与模型训练阶段
3.训练过程中的一些命令行调试必备知识
0.如何完整地复现/应用一个Github项目
前日在健身房的组间同一位好友交流时,得到了一个一致结论—— ** Github \texttt{Github} Github 上有 80% \texttt{80\%} 80%的项目都是垃圾代码**,有包括笔者在内的不少小白尝试复用某些看似高大上的项目时,发现其code存在各种千奇百怪的问题最严重时可能导致我们电脑损坏。并且,在复现项目的过程中,会涉及到许多新手不甚熟悉的常用命令行操作,因此,本文目标旨在为新手梳理复现一个可靠的 Github \texttt{Github} Github项目的完整的复现/应用过程,以及帮助大家熟悉常见的命令行操作。
首先,本文选用的是pix2pix,一个 star \texttt{star} star数超 23.9k \texttt{23.9k} 23.9k、并且其论文发表在2017年的 CVPR \texttt{CVPR} CVPR的超强风格迁移模型(这些数据表明了这个项目是可靠的):

而在此处,直接给出复现项目的一个完整流程图。这个流程图相当之重要,几乎所有的复现项目思路都是如此:
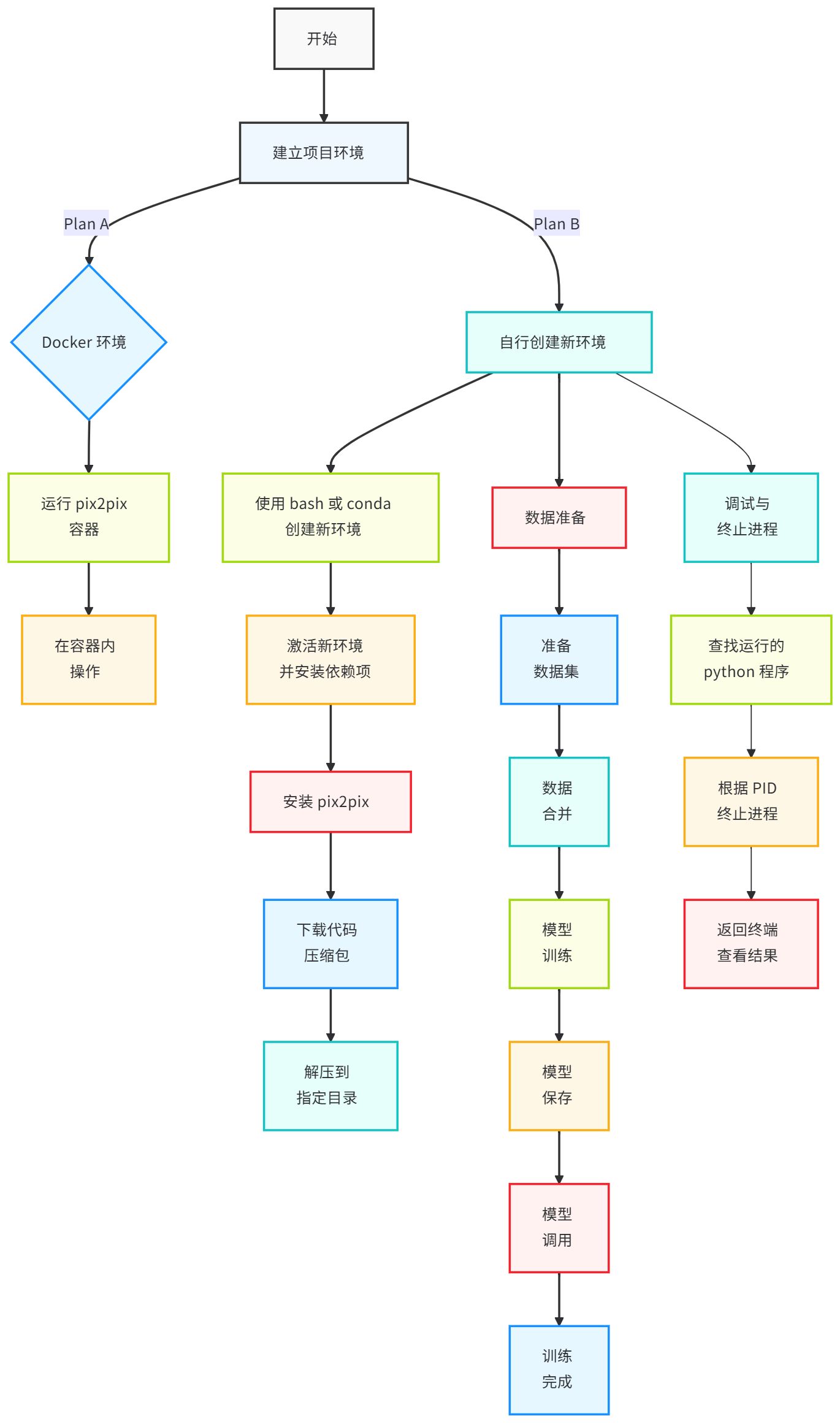
如果有初学者想要挑战一下的话,不妨可以直接就着这张流程图,通过下面两种方式,试试自己能不能实现复现:
-
自行上 pix2pix \texttt{pix2pix} pix2pix官网,尤其是
issues部分,这里可能有很多人与你的问题能够共鸣。 -
合理使用
LLMs。尤其是对这种开放网站,AI的阅读效率可比人高多了:

1.建立适用于项目的环境
-
安装 pix2pix \texttt{pix2pix} pix2pix
- 访问pytorch-CycleGAN-and-pix2pix GitHub 仓库
- 点击页面上绿色的 “Code” 按钮,选择 “Download ZIP” 下载代码压缩包。
- 将压缩包解压到一个目录,例如:
"D:\Sophomore\DesignExperiment\pytorch-CycleGAN-and-pix2pix"
-
本地环境配置
P l a n A Plan \ A Plan A:使用 Docker \texttt{Docker} DockerDocker \texttt{Docker} Docker是一个容器化平台,简单来说,它就像一个“打包好的软件箱子”。
这个箱子里包含了运行 pix2pix 所需的所有东西(比如 Python、PyTorch 等依赖项),我们无需自己手动安装这些依赖。使用 Docker \texttt{Docker} Docker的好处是:
- 环境一致:无论您用的是 Windows、Mac 还是 Linux,pix2pix 的运行效果都一样。
- 省去麻烦:不用自己配置复杂的深度学习环境。
但是! 考虑到并非所有Github项目的作者都准备好了一个预构建的 Docker \texttt{Docker} Docker镜像,我们的重点还是讲解 P l a n B Plan \ B Plan B:
自行创建新环境:
- 为什么要建立一个新环境?
最主要的目的还是避免与自己原有的环境相冲突。
-
使用
bash或者conda创建一个新环境
bash命令python -m venv pix2pix_envconda命令
conda create -n pix2pix_env python=3.11pix2pix_env是环境名,大家取啥都可以。 -
激活该新环境并安装依赖项:
激活环境(确保有这个步骤,避免安装到默认的base环境):conda activate pix2pix_env安装依赖项
pip install -r requirements.txtP.S.:
requirements.txt中并不一定有运行 pix2pix \texttt{pix2pix} pix2pix中所需的所有库,譬如OpenCV。不过这其实也好办,大家大可以先去run后面的代码,系统提醒你还缺什么库时再安装即可。P.S.S: 如果大家使用的是
VScode的话,那么选择打开终端是默认打开的powershell,而我们更习惯使用的Anaconda Prompt间存在一定区别,好奇这两种Command Line Interface(CLI)区别的读者可以阅读本人本地通过Vscode连接服务器完整流程的第一部分。总而言之就是,如果你希望再powershell中使用conda命令,你需要进行一些对于系统路径进行一些微调,可以参考此文: 安装Anaconda后如何在powershell使用conda activate命令(Windows)
2.1数据准备与模型训练阶段
2.1数据准备
调用别人的模型前,肯定要仔细阅读关于数据格式的问题,pix2pix关于数据集的官方文档。
一个优秀的项目,关于如何能让别人使用,一定是说得清清楚楚的, pix2pix \texttt{pix2pix} pix2pix确实做到了一点。在此处不再赘述其官方处理数据的要求,只是提醒一点,务必按照指定的文件格式调用代码,比如在下面的数据合并代码中,/path/to/data/A文件夹中,一定还在在文件夹A中划分A/Test和A/Train,而非直接存放图片。在大家有足够的代码水平前,切莫随意自由发挥。
下面是从官网文档提取出的数据处理部分的代码,以及调用方式:
bash code
python datasets/combine_A_and_B.py --fold_A /path/to/data/A --fold_B /path/to/data/B --fold_AB /path/to/data
当然,想要调用上述代码,肯定得先进入存放 datasets \texttt{datasets} datasets的文件夹(以本人存放 pix2pix \texttt{pix2pix} pix2pix的 datasets \texttt{datasets} datasets为例)
cd "D:\Sophomore\DesignExperiment\pytorch-CycleGAN-and-pix2pix"
具体调用代码则是:
python datasets/combine_A_and_B_new.py --fold_A "D:\Sophomore\DesignExperiment\pytorch-CycleGAN-and-pix2pix\mydatasets\X" --fold_B "D:\Sophomore\DesignExperiment\pytorch-CycleGAN-and-pix2pix\mydatasets\Y" --fold_AB "D:\Sophomore\DesignExperiment\pytorch-CycleGAN-and-pix2pix\mydatasets\Converge"
文件名中切忌空格、中文等特殊字符。
P.S.: 细心的读者会发现,为啥调用的python文件是datasets/combine_A_and_B_new.py?对,datasets/combine_A_and_B_new.py是我自己在原本的datasets/combine_A_and_B_new.py上改的,至于原因,大家看到最后一节就明白了。
2.2模型训练、保存与调用
-
模型训练
- P.S.: 希望完成官方自带的完整可视化的话,首先需要
wandb包。下面给出的是训练模型的bash代码
python train.py `--dataroot "D:\Sophomore\DesignExperiment\pytorch-CycleGAN-and-pix2pix\mydatasets\Converge" `--model pix2pix `--dataset_mode aligned `--direction AB `--name just_a_try `--display_id 0 `--gpu_ids -1 `--batch_size 1上述的各行代码意思应该都比较直接,比如
--gpu_ids -1表示使用CPU,--display_id 0表示不启动过程中的可视化。有些训练选项是必须的,比如--name,--dataroot等等;还有一部分则是非必须的,会有默认值,比如--display_id默认是0.上述并非全部的训练可调选项,还可以调整
--niter(初始学习率下的轮数)和--niter_decay(线性衰减学习率到零的轮数)等等,大家可以在官网 Github \texttt{Github} Github上找到完整的可调选项(不过似乎藏得挺深)。官网给出的
bash代码是写在一行之中的,考虑到事实上这样并没有那么便于阅读,本人改写成了多行的方式。“ ` (反引号 )”类似与告诉Windows命令行“我在换行”。 - P.S.: 希望完成官方自带的完整可视化的话,首先需要
-
模型保存(训练数据记录)与调用
训练好的模型保存在 ./checkpoints/[name] 目录下,例如我的 --name just_a_try 会保存在 ./checkpoints/just_a_try。在./checkpoints/[name]中,会有loss_log的文档记录训练过程的Loss情况。
如果希望调用模型,可以使用如下代码:
python test.py --dataroot [测试数据路径] `
--name just_a_try `
--model pix2pix`
--direction AB`
3.训练过程中的一些 CLI \texttt{CLI} CLI调试必备知识:如何终止进程
随着我们完成的任务难度上升,尤其是使用 CLI \texttt{CLI} CLI直接与电脑交互时,我们可能会遇到一些意料不到的情况:譬如,在数据合并时,如果我们真的直接在Windows系统上直接调用了combine_A_and_B.py,我们会发现自己的CPU不幸地被干烧,并且我们不知道如何停止。关于为什么会出现该情况,具体原因可以看看为什么我们需要if name == main(所以这也是为何我在前文写了combine_A_and_B_new.py文件的原因)。
现在我们来说说如何终止 CLI \texttt{CLI} CLI中的进程:
-
按下
Win+X,打开“终端(管理员)”。一定要选择带“管理员”的,否则有时可能无法终止进程。 -
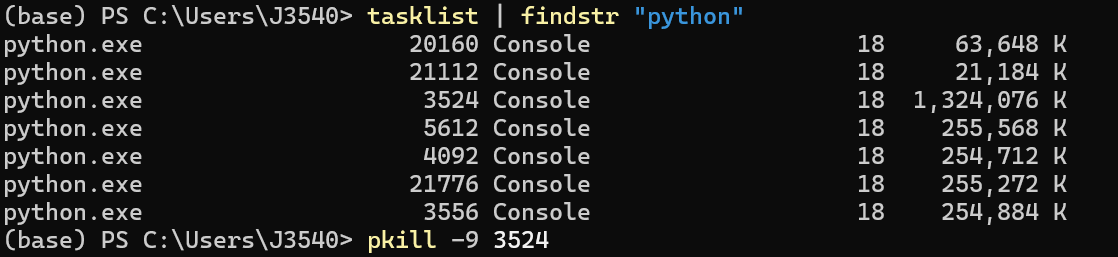
查找正在运行的
python程序:tasklist finstr | "python" -
这时会弹出一串正在运行的
python程序,几列的含义分别为进程名称(如python.exe,这意味着它们是由Python解释器启动的进程)、PID(Process Identifier,进程标识符)、会话类型(如Console,这意味着它们是在命令行或控制台窗口中启动的)、优先级类以及内存使用量。假定是在我们的调试情境下,那么占用内存最多的肯定就是正在干烧我们GPU的执行数据合并的程序。
-
于是我们根据PID精准地将其终结:
taskkill /F /PID 3524

当然,我们如果拿不准到底是哪个程序的话,完全可以一棒子打死:
taskkill /F /IM python.exe
其中/F是强制终止进程,/IM是指定进程名
在输入上述的终止代码后,再返回原本正在run模型的终端,会出现令人长舒一口气的显示:
