【随笔】地理探测器原理与运用
文章目录
- 一、作者与下载
- 1.1 软件作者
- 1.2 软件下载
- 二、原理简述
- 2.1 空间分异性与地理探测器的提出
- 2.2 地理探测器的数学模型
- 2.21 分异及因子探测
- 2.22 交互作用探测
- 2.23 风险区与生态探测
- 三、使用:excel
一、作者与下载
1.1 软件作者
作者:

DOI: 10.11821/dlxb201701010
文献:地理探测器:原理与展望。直接看这个文献也可以。
1.2 软件下载
主页:http://www.geodetector.cn/Download.html
分别是excel宏、R包、QGIS和ArcGIS Pro工具箱。
excel的都带有示例数据,不过第三个和第一个的数据是相同的(可能是网站文件设置错误,截至我发文日期)。
二、原理简述
2.1 空间分异性与地理探测器的提出
空间分异性的科学意义:
空间分异性(空间分层异质性)表现为地理现象在子区域内的方差小于总区域方差,例如气候带、土地利用分区等。地理探测器通过量化这一分异性,为揭示其驱动因子提供了统计学工具。
地理探测器的核心优势:
- 无需线性假设:适用于非线性关系分析。
- 物理含义明确:通过方差分解直接量化因子解释力。
- 多类型数据兼容:支持类型量(如分类地图)和离散化数值量的分析。
基本逻辑:
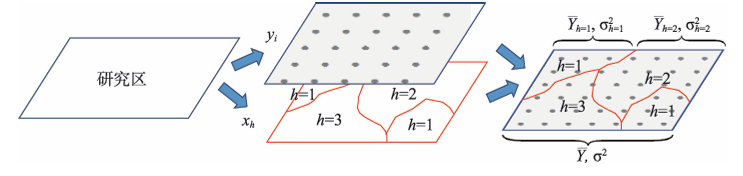
- 分异性检验:若子区域方差和( S S W SSW SSW)小于总方差( S S T SST SST),则存在空间分异。
- 因子关联性:若两变量空间分布一致,则存在统计关联。
2.2 地理探测器的数学模型
2.21 分异及因子探测
q统计量用于度量因子解释力:
q = 1 − ∑ h = 1 L N h σ h 2 N σ 2 = 1 − S S W S S T q = 1 - \frac{\sum_{h=1}^{L} N_h \sigma_h^2}{N\sigma^2} = 1 - \frac{SSW}{SST} q=1−Nσ2∑h=1LNhσh2=1−SSTSSW
式中:
- L L L为分层数, N h N_h Nh和 N N N为子区域与全区域样本数。
- σ h 2 \sigma_h^2 σh2和 σ 2 \sigma^2 σ2为子区域与总体方差。
显著性检验通过非中心F分布实现:
F = N − L L − 1 ⋅ q 1 − q ∼ F ( L − 1 , N − L ; λ ) F = \frac{N-L}{L-1} \cdot \frac{q}{1-q} \sim F(L-1, N-L; \lambda) F=L−1N−L⋅1−qq∼F(L−1,N−L;λ)
其中非中心参数 λ \lambda λ为:
λ = 1 σ 2 [ ∑ h = 1 L Y ˉ h 2 − 1 N ( ∑ h = 1 L N h Y ˉ h ) 2 ] \lambda = \frac{1}{\sigma^2} \left[ \sum_{h=1}^{L} \bar{Y}_h^2 - \frac{1}{N} \left( \sum_{h=1}^{L} N_h \bar{Y}_h \right)^2 \right] λ=σ21 h=1∑LYˉh2−N1(h=1∑LNhYˉh)2
某个因子的q值越大,他对因变量的解释力就越强。显著性检验的p值,就不用说了吧,比如小于0.01,就代表xxx.
2.22 交互作用探测
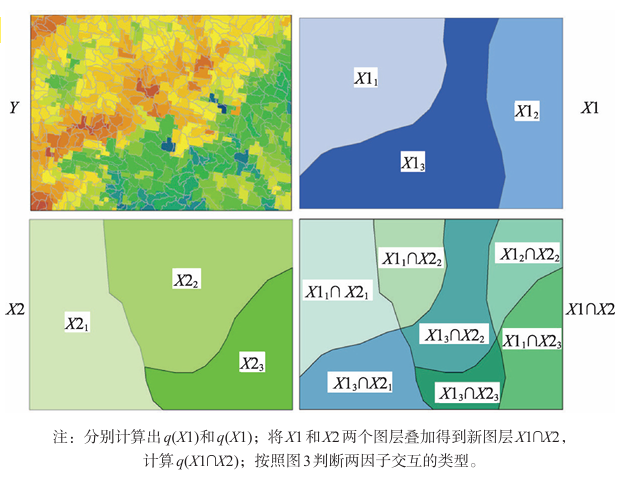
通过比较单因子与多因子叠加的 q q q值,判断交互作用类型:
- 非线性增强: q ( X 1 ∩ X 2 ) > q ( X 1 ) + q ( X 2 ) q(X_1 \cap X_2) > q(X_1) + q(X_2) q(X1∩X2)>q(X1)+q(X2)
- 双因子增强: q ( X 1 ∩ X 2 ) > max ( q ( X 1 ) , q ( X 2 ) ) q(X_1 \cap X_2) > \max(q(X_1), q(X_2)) q(X1∩X2)>max(q(X1),q(X2))
- 单因子主导: max ( q ( X 1 ) , q ( X 2 ) ) < q ( X 1 ∩ X 2 ) < q ( X 1 ) + q ( X 2 ) \max(q(X_1), q(X_2)) < q(X_1 \cap X_2) < q(X_1) + q(X_2) max(q(X1),q(X2))<q(X1∩X2)<q(X1)+q(X2)
- 独立作用: q ( X 1 ∩ X 2 ) = q ( X 1 ) + q ( X 2 ) q(X_1 \cap X_2) = q(X_1) + q(X_2) q(X1∩X2)=q(X1)+q(X2)
- 非线性减弱: q ( X 1 ∩ X 2 ) < min ( q ( X 1 ) , q ( X 2 ) ) q(X_1 \cap X_2) < \min(q(X_1), q(X_2)) q(X1∩X2)<min(q(X1),q(X2))

这里的叠加,不是把各个因子相加,而是相交,简单来说就是分类增加了。看下图就明白了:
2.23 风险区与生态探测
-
风险区差异检验(t检验):
t Y ˉ h = 1 − Y ˉ h = 2 = Y ˉ h = 1 − Y ˉ h = 2 Var ( Y ˉ h = 1 ) n h = 1 + Var ( Y ˉ h = 2 ) n h = 2 t_{\bar{Y}_{h=1} - \bar{Y}_{h=2}} = \frac{\bar{Y}_{h=1} - \bar{Y}_{h=2}}{\sqrt{\frac{\text{Var}(\bar{Y}_{h=1})}{n_{h=1}} + \frac{\text{Var}(\bar{Y}_{h=2})}{n_{h=2}}}} tYˉh=1−Yˉh=2=nh=1Var(Yˉh=1)+nh=2Var(Yˉh=2)Yˉh=1−Yˉh=2
自由度 d f df df为:
d f = ( Var ( Y ˉ h = 1 ) n h = 1 + Var ( Y ˉ h = 2 ) n h = 2 ) 2 1 n h = 1 − 1 ( Var ( Y ˉ h = 1 ) n h = 1 ) 2 + 1 n h = 2 − 1 ( Var ( Y ˉ h = 2 ) n h = 2 ) 2 df = \frac{\left( \frac{\text{Var}(\bar{Y}_{h=1})}{n_{h=1}} + \frac{\text{Var}(\bar{Y}_{h=2})}{n_{h=2}} \right)^2}{\frac{1}{n_{h=1}-1} \left( \frac{\text{Var}(\bar{Y}_{h=1})}{n_{h=1}} \right)^2 + \frac{1}{n_{h=2}-1} \left( \frac{\text{Var}(\bar{Y}_{h=2})}{n_{h=2}} \right)^2} df=nh=1−11(nh=1Var(Yˉh=1))2+nh=2−11(nh=2Var(Yˉh=2))2(nh=1Var(Yˉh=1)+nh=2Var(Yˉh=2))2 -
生态探测(F检验):
F = N X 1 ( N X 2 − 1 ) S S W X 1 N X 2 ( N X 1 − 1 ) S S W X 2 F = \frac{N_{X1}(N_{X2}-1)SSW_{X1}}{N_{X2}(N_{X1}-1)SSW_{X2}} F=NX2(NX1−1)SSWX2NX1(NX2−1)SSWX1
其中 S S W X 1 SSW_{X1} SSWX1和 S S W X 2 SSW_{X2} SSWX2为两因子分层后的层内方差和。
三、使用:excel
以excel版本为例,R语言和GIS版本的也是类似的,R语言看它的help有函数说明的。
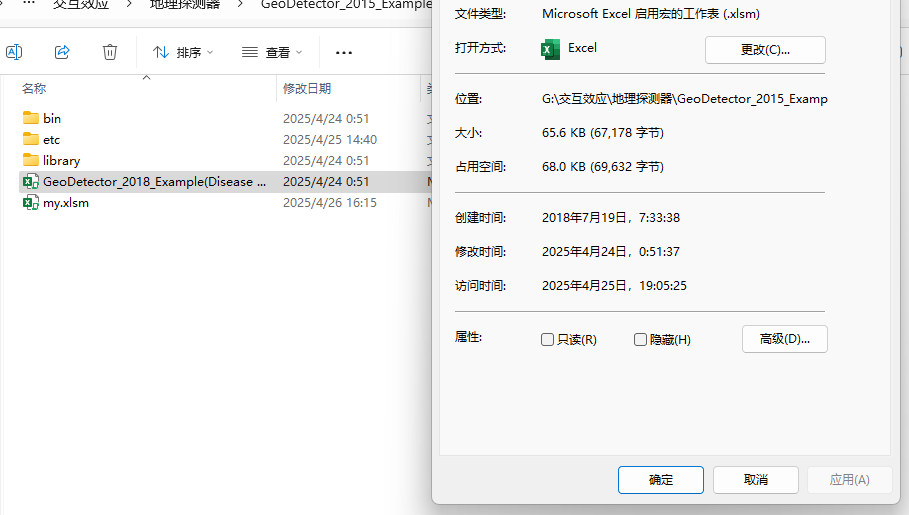
直接打开excel版本的xlsm文件,你可能无法使用,因为这是带宏的表格,系统会阻止运行。
在xlsm文件上右键–>属性:在最下面的位置会有一个解除阻止运行之类的选项(名字忘了),设置一下即可。图中我已经解除限制了,没有显示。
🟢打开表格:里面的数据可以删除换成自己的。自变量需要设置为分类变量。比如一个自变量是全国各个城市的GDP,你可以使用各自算法将数据分为几类,比如使用分位数,分为高中低三类,再编码为1、2、3这种。这个不会的话问AI即可。
接着读取数据到GUI界面,设置自变量、因变量,运行。
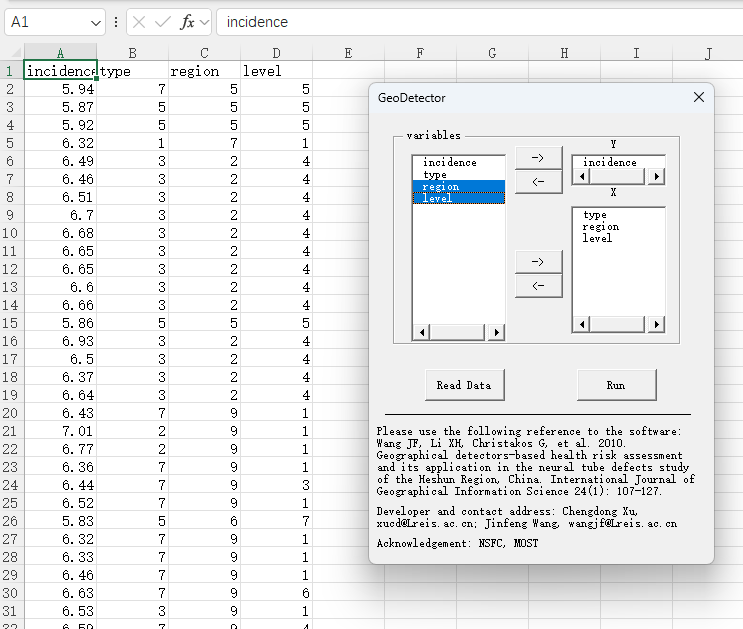
运行后会生成几个sheet:一般只使用交互效应和因子探测的表格,环境和风险的不常用。

🟢 数据说明:
他需要你提供一个“表格”形式的数据,比如ArcGIS的属性表。
数据量不要太大了:
- 第一是数据量大,你电脑内存可能不足,比如一个像元一个值,几十米分辨率,你的研究区可能就会有几十亿个像元,存为csv需要几十GB,运行的时候内存通常不足;
- 第二是运行时间太久,这个不用多说;
- 第三是使用excel的情况下,excel就支持几百万行数据。实际上几万行数据,这个程序就会溢出的。
- 第四十结果q值会非常小,因为这个计算出来的方差会非常小,那个比值接近1,q就接近0了。
建议的数据示例:每个城市的数据(因变量+自变量),这样就只有几百或者几十行数据。
另外一点是,自变量的分类(离散化)可能会影响结果:因为这个地理探测器的原理可以看作是,找到一条或者几条分界线,使得自变量和因变量都是用这一组分界线,能将数据很好的区分(当然这个比喻并不是是否准确)。这个分界线其实就相当于你对自变量的分类。
参考文献:
王劲峰, 徐成东. 地理探测器:原理与展望[J]. 地理学报, 2017, 72(1): 116-134 https://doi.org/10.11821/dlxb201701010
Jinfeng WANG, Chengdong XU. Geodetector: Principle and prospective[J]. Acta Geographica Sinica, 2017, 72(1): 116-134 https://doi.org/10.11821/dlxb201701010