LIDC-IDRI数据集切割代码教程【pylidc库】
数据集:
通过网盘分享的文件:LIDC
链接: 百度网盘 请输入提取码 提取码: ywb8
代码:
通过网盘分享的文件:LIDC-IDRI-Preprocessing.rar
链接: 百度网盘 请输入提取码 提取码: b1za
【代码里的部分数据就不删了,方便你们照着放】
一、如何运行
1.输入
把数据集放到这个位置:
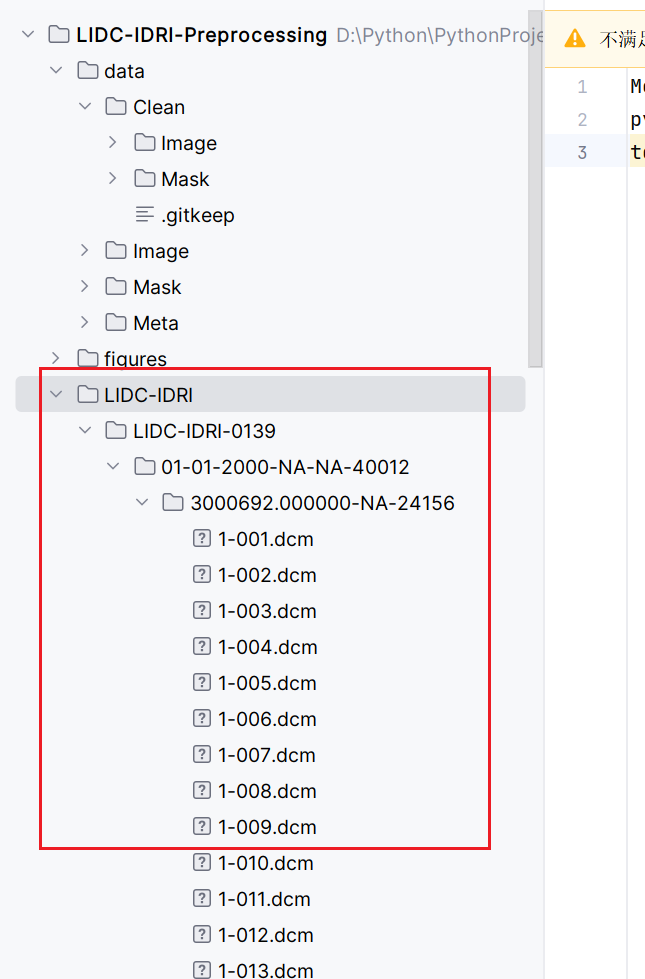
运行这个文件:
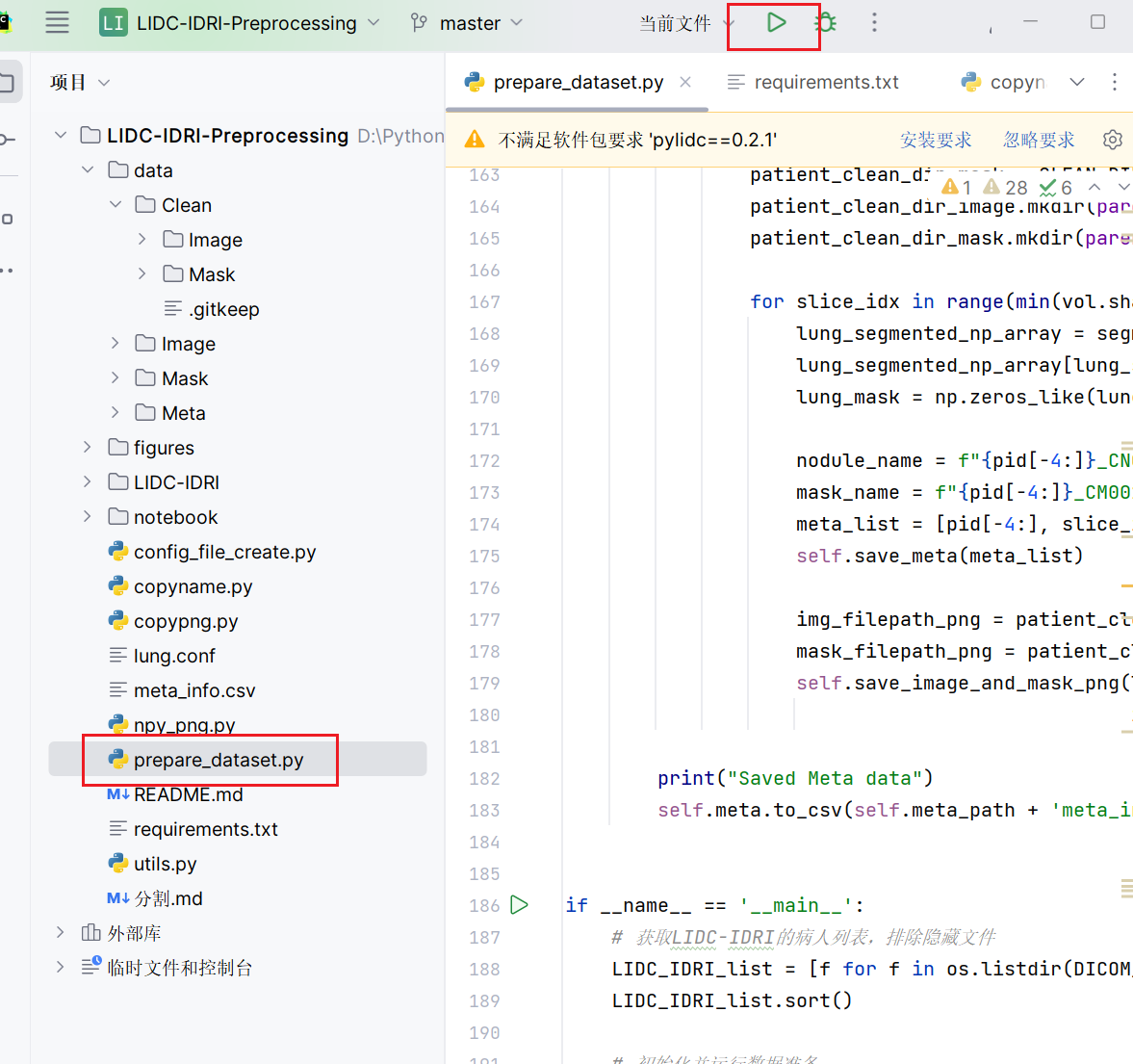
2.输出
下面文件夹里就是要的,clean文件里是过滤掉的
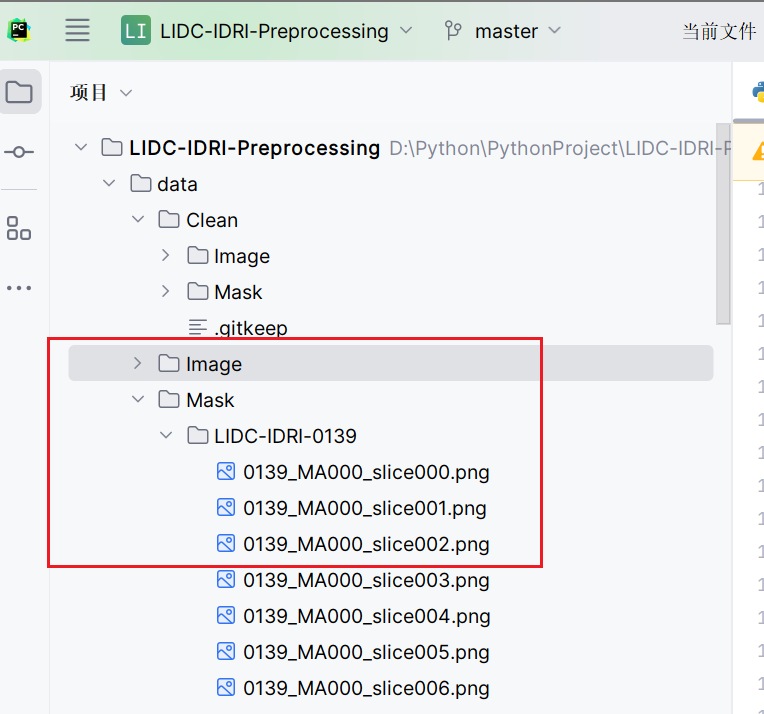
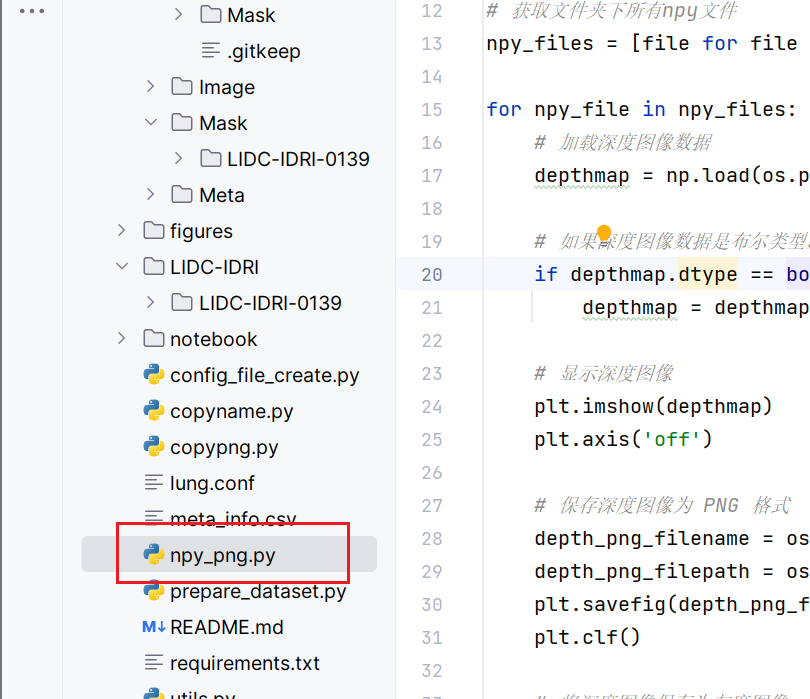
为方便模型分割我改成输出png格式的了,如果需要npy格式的自己改一下输出格式,复制给ai让ai改
在这里也有npy转png的工具类
二、原理和流程
核心文件
1.读取数据【把一个病人的肺部CT组合成3D图像】
- 医院CT扫描后,一位病人的一整个肺部扫描,通常是几十上百张单独的 DICOM 文件。
- 每一张DICOM相当于是一张灰度图片,比如 512x512 pixels。
- 同一个病人的多张图片,沿着Z轴叠加,组成一个3D体积(Volume)。
每张DICOM除了图像,还有重要的元数据,比如:
- Slice位置(在身体的哪个位置)
- Pixel Spacing(像素大小,毫米)
- Slice Thickness(切片厚度,毫米)
- 这些元数据会影响图像在3D空间的实际物理大小。
把每个病人的 CT 扫描(DICOM文件)加载成一个3D体积数组, ,即 (height, width, slices) 这样的 numpy array。
让后续处理可以直接基于体素( 在三维医学影像里,一个小立方体就是一个体素 )操作,而不是一张张2D图片
pylidc.Scan.to_volume() ——>自动帮你把同一病人的多张 DICOM 按照 slice 位置组合成 3D Volume。
pylidc已经帮你处理了像素间距(pixel_spacing)、切片厚度(slice_thickness)的问题,所以可以直接拿来用。
2.获取结节标记【把不同医生标注的同一个结节聚集、放到一起】
读取医生的手绘结节区域,有些病人的一个结节可能有 多位医生各自独立标注。
scan.cluster_annotations()➔ pylidc的这个函数会自动根据医生的标注,把不同医生标的 同一个结节聚合(clustering) ,形成一个结节簇 (nodule cluster)。
- 聚合之后,每个 "nodule cluster" 里面包含了1~4个医生给的单独mask。
- 不同医生的标注大小、形状、位置会有细微差异。
3. 结节融合【生成共识掩膜、把上面放到一起的意见生成一个】
把多个医生的标注融合成一张最终的掩膜(mask), 不是简单取平均,而是根据设定的置信度(confidence_level),来决定哪些地方算是结节。
pylidc.utils.consensus()
➔ 这个函数内部会对所有医生的mask叠加,然后根据设定的置信度,比如 0.5,选取至少有一半医生认为是结节的区域。
小细节
- padding 参数:扩展边界一点点,保证感兴趣区域 (ROI) 裁剪时不会把重要信息截断。
- 有时候也能防止小结节被裁掉。
4. 小块裁剪(提取ROI) 【把肺上的结节裁出来】
- 只取出 包含结节的小立方体区域。
- 不用处理整个大肺部Volume,加快后续处理速度,同时专注于结节本身。
直接索引裁剪 numpy 3D array:volume[cbbox], cbbox是 consensus 给出的bounding box,确定了x, y, z范围。 这样裁剪出来的3D小块,里面的像素就是肺部的一部分+结节。
5. 插值补齐(统一切片数量) ——可以在这里改变你想要的数量
有的裁剪块厚,有的薄,为了训练深度学习,需要统一每个样本的切片数(例如统一到120片)。如果原本切片数不够,就做插值上采样。
scipy.ndimage.zoom()
➔ 对第三个维度(z轴)做缩放插值。
- 插值后要确保最终切片数恰好是目标值(如120 slice)。
- 这里用的是线性插值 (order=1),平滑过渡,不会产生噪点。
6. 遍历切片(过滤小面积掩膜)
每一片切片都单独检查:
- 如果当前mask面积太小(比如很少像素是结节区域),就跳过这张片。
- 这样避免保存很多无意义的图片。
判断掩膜面积:np.sum(mask[:, :, slice_idx]), 阈值来自 config 文件里的 mask_threshold 参数。
这样可以大大减少无效样本,提升训练时数据质量。
7. 肺部分割(清理背景)【去除所有非肺部区域、 如气管、肺外的组织等】
把CT切片上除了肺以外的部分(比如骨骼、气管)剔除,只留下纯净的肺部区域。
segment_lung() 函数(项目自带的)
- 典型实现是:
-
- 用
K-Means聚类找出低密度的肺部。 - 形态学操作(如闭运算)连通肺部区域。
- 再用 largest connected component 提取左右肺叶。
- 用
1. 聚类算法:无监督学习算法、根据数据点之间的相似性来将其分组
2. K-Means: 一种聚类算法、 用于将数据分成多个类别(或簇)
将数据中的样本点分配到预定数量的簇中,使得簇内的样本点相似度尽可能高,而簇之间的样本点相似度尽可能低。
a. K-Means 算法的工作原理:
- 初始化:选择 K 个初始簇的中心(通常随机选择 K 个点)。
- 分配:将每个数据点分配到离它最近的簇中心。
- 更新:计算每个簇的平均值,并将这个平均值作为新的簇中心。
- 迭代:重复步骤 2 和 3,直到簇中心不再变化,或者变化非常小,达到收敛条件。
b. K-Means 算法应用在肺部分割中的作用:
- 我们可以将这些点分成两个簇,一个簇表示肺部的低密度区域,另一个簇表示高密度区域(如骨骼)
- 低密度区域(肺部)会被分到一个簇中。——我们要的
- 高密度区域(骨骼、血管等)会被分到另一个簇中。
3. 形态学操作:处理图像中形状的方法
更简单举个例子
想象一张黑白图片:
- 白色代表肺部
- 黑色代表背景
但这张图可能:
- 有很多小白点噪声(误判成肺)
- 肺部有小黑洞(断开的地方)
这个时候,
- 形态学操作可以帮我们"修修补补",
让真正的肺叶连起来,让错误的小噪声消失掉。
就像是在清洗、修整一张地图,让肺部轮廓干净漂亮。
常见四种形态学操作
| 操作 | 直白解释 | 用在哪 |
| 腐蚀 (Erosion) | 白色区域缩小、收缩,小白点会被吃掉 | 去掉小的噪声点 |
| 膨胀 (Dilation) | 白色区域变大、扩张,小洞被补起来 | 连通断开的部分 |
| 开运算 (Opening) | 腐蚀 + 膨胀 | 清理小白点,但不影响大块肺部 |
| 闭运算 (Closing) | 膨胀 + 腐蚀 | 填补小黑洞,连接断裂的肺叶 |
腐蚀:用一个5X5的滑动窗口扫描,如果周围都是0,那就把中间这个像素填成0
用 K-Means 聚类找出低密度的肺部+ 形态学操作(如闭运算)连通肺部区域可以减少模型搜索的60%空间:
- 肺只占整幅CT的约30%~40%,剩下的60%~70%都是没用的背景、骨头——> 感兴趣区域
- 跳过背景噪声
传统的方法是: 灰度阈值分割——>肺部分割精度差,边界不平滑、无法处理复杂区域(气管、血管等)和小结节。
(原始的肺部区域体积-优化后的区域体积)/原始肺部区域体积X100%=减少的模型搜索空间
8. 保存图像(肺部切片 + 掩膜)
- 把分割好的单张切片(肺部图像)和对应的掩膜(mask)分别保存为 PNG 文件。
- 每个病人有单独的文件夹,按slice编号存。
matplotlib.pyplot.imshow()+savefig()- 保存时关掉坐标轴(
axis('off')),并去除白边(bbox_inches='tight', pad_inches=0)。 - 保存一张图后用
plt.clf()清空画布,防止内存泄漏。
9. 保存Meta信息表
- 记录每一张图片的元数据(病人ID、结节编号、切片编号、图像文件名、掩膜文件名、恶性程度、是否癌症、是否是干净片)
- 最后把所有记录保存成CSV表格,供训练/验证时检索。
- 是否癌症、是否清洁图(
is_cancer,is_clean)也是直接存在meta里面,免得推理时重复计算。