目录
0. 前置准备
0.1 安装虚拟机
0.2 Linux统一设置
1. Hadoop安装配置
1.1 环境准备
1.2 Hadoop伪分布式安装
1.3 Hadoop集群安装
2. HDFS实验,包括Shell命令操作和Java接口访问
2.1 HDFS操作命令
2.2 通过Java项目访问HDFS
2.3 使用winutils解决警告信息
3. 实现MapReduce的WordCount
3.1 MapReduce的运算过程
3.2 WordCount示例
3.3 可能遇到的bug
4.Hbase安装配置实验
4.1 HBase的安装
4.1.1 HBase的单节点安装
4.1.2 HBase的伪分布式安装
0. 前置准备
0.1 安装虚拟机
(若已安装则可跳过)
· 接下来设置静态IP地址。打开终端,先通过ifconfig命令查询IP地址,在ens33处,并记住。
然后在使用vim /etc/sysconfig/network-scripts/ifcfg-ens33
vim /etc/sysconfig/network-scripts/ifcfg-ens33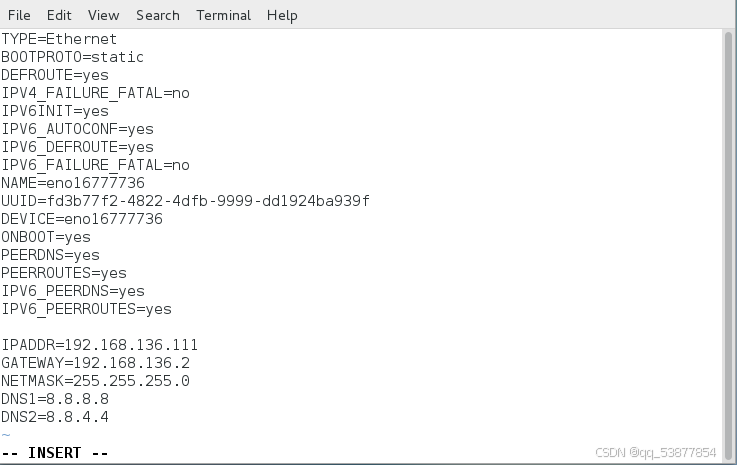
0.2 Linux统一设置
步骤01 配置主机名称。
将主机名取为server+IP最后一部分作为主机名称,下面例子取主机名为server201,是因为本主机的IP地址设置为192.168.56.201。若是xxx.xxx.xxx.22,则改为server22
hostnamectl set-hostname server201步骤02 修改hosts文件。
192.168.56.201 server201步骤03 关闭且禁用防火墙。
systemctl stop firewalld
systemctl disable firewalld步骤04 禁用SELinux,需要重新启动。
vim /etc/selinux/config
SELINUX=disabled步骤05 在/usr/java目录下,安装JDK1.8.x。
首先在Oracle官网下载JDK1.8的Linux版本,如图所示。

可通过winscp上传到Linux中的/usr/java/目录下并解压:
tar -zxvf jdk-8u281-linux-x64.tar.gz -C /usr/java/步骤06 配置JAVA_HOME环境变量。
vim /etc/profile在profile文件最后,添加以下配置:
export JAVA_HOME=/usr/java/jdk1.8.0_281
export PATH=.:$PATH:$JAVA_HOME/bin让环境变量生效:
source /etc/profile检查Java版本:
[root@localhost bin]# java -versionjava version "1.8.0_281"Java(TM) SE Runtime Environment (build 1.8.0_192-b12)Java HotSpot(TM) 64-Bit Server VM (build 25.192-b12, mixed mode)至此,基本的环境就配置完成了。
1. Hadoop安装配置
1.1 环境准备
步骤01 关闭防火墙。
以下命令检查防火墙的状态:
sudo firewall-cmd --state
runningrunning表示防火墙正在运行。以下命令用于停止和禁用防火墙:
systemctl stop firewalld.service
systemctl disable firewalld.service步骤02 配置免密码登录。
配置免密码登录的主要目的,就是在使用Hadoop脚本启动Hadoop的守护进程时,不需要再提示用户输入密码。SSH免密码登录的主要实现机制,就是在本地生成一个公钥,然后将公钥配置到需要被免密码登录的主机上,登录时自己持有私钥与公钥进行匹配,如果匹配成功,则登录成功,否则登录失败。
可以使用ssh-keygen命令生成公钥和私钥文件,并将公钥文件复制到被SSH登录的主机上。以下是ssh-keygen命令,输入后直接按两次回车即可生成公钥和私钥文件:

如上面所说,生成的公钥和私钥文件将被放到~/.ssh/目录下。其中id_rsa文件为私钥文件,rd_rsa.pub为公钥文件。现在我们再使用ssh-copy-id将公钥文件发送到目标主机。由于登录的是本机,所以直接输入本机名即可:
[hadoop@server201 ~]$ ssh-copy-id server201/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/hadoop/.
ssh/id_rsa.pub"The authenticity of host 'server201 (192.168.56.201)' can't be established.ECDSA key fingerprint is SHA256:KqSRs/H1WxHrBF/tfM67PeiqqcRZuK4ooAr+xT5Z4OI.ECDSA key fingerprint is MD5:05:04:dc:d4:ed:ed:68:1c:49:62:7f:1b:19:63:5d:8
e.Are you sure you want to continue connecting (yes/no)? yes 输入yes/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filt
er out any that are already installed/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are pro
mpted now it is to install the new keys输入密码然后按回车键,将会提示成功信息:
hadoop@server201's password:Number of key(s) added: 1Now try logging into the machine, with: "ssh 'server201'"and check to make sure that only the key(s) you wanted were added.此命令执行以后,会在~/.ssh目录下多出一个用于认证的文件,其中保存了某个主机可以登录的公钥信息,这个文件为~/.ssh/authorized_keys。
现在再使用ssh server201命令登录本机,将会发现不用再输入密码,即可以直接登录成功。
[hadoop@server201 ~]$ ssh server201
Last login: Tue Mar 9 20:52:56 2021 from 192.168.56.11.2 Hadoop伪分布式安装
在安装之前,请确定已经安装了JDK1.8,并正确配置了JAVA_HOME、PATH环境变量。
在磁盘根目录下,创建一个app目录,并授权给hadoop用户。然后将会把Hadoop安装到此目录下。先切换到根目录下:
[hadoop@server201 ~]$ cd /添加sudo前缀使用mkdir创建/app目录:
[hadoop@server201 /]$ sudo mkdir /app将此目录的所有权授予给hadoop用户和hadoop组:
[hadoop@server201 /]$ sudo chown hadoop:hadoop /app切换进入/app目录:
[hadoop@server201 /]$ cd /app/使用ll -d命令查看本目录的详细信息,可看到此目录已经属于hadoop用户:
[hadoop@server201 app]$ ll -d
drwxr-xr-x 2 hadoop hadoop 6 3月 9 21:35 .下载hadoop:Index of /apache/hadoop/common/stable (tsinghua.edu.cn)

将Hadoop的压缩包通过winscp上传到/app目录下,并解压到此文件中。可用ll命令查看本目录是否上传成功。
[hadoop@server201 app]$ ll
总用量 386184
-rw-rw-r-- 1 hadoop hadoop 395448622 3月 9 21:40 hadoop-3.4.0.tar.gz使用tar命令-zxvf参数解压此文件:
[hadoop@server201 app]$ tar -zxvf hadoop-3.4.0.tar.gz以下开始配置Hadoop。Hadoop的所有配置文件都在hadoop-3.4.0/etc/hadoop目录下。首先切换到此目录下,然后开始配置:
[hadoop@server201 hadoop-3.4.0]$ cd /app/hadoop-3.4.0/etc/hadoop/步骤01 配置hadoop-env.sh文件。
hadoop-env.sh文件是Hadoop的环境文件,在此文件中需要配置JAVA_HOME变量。在此文件的最后一行输入以下配置,然后按Esc键,再输入:wq保存退出即可:
export JAVA_HOME=/usr/java/jdk1.8.0_281
步骤02 配置core-site.xml文件。core-site.xml文件是HDFS的核心配置文件,用于配置HDFS的协议、端口号和地址。注意:Hadoop 3.0以后HDFS的端口号建议为8020,但如果查看Hadoop的官网示例,依然延续使用的是Hadoop 2之前的端口9000,以下配置我们将使用8020端口,只要保证配置的端口没有被占用即可。配置时,需要注意大小写。使用vim打开core-site.xml文件,进入编辑模式:
[hadoop@server201 hadoop]$ vim core-site.xml
在<configuration></configuration>两个标签之间输入以下内容:(注意修改server201)
<property><name>fs.defaultFS</name><value>hdfs://server201:8020</value></property><property><name>hadoop.tmp.dir</name><value>/app/datas/hadoop</value></property>配置说明:● fs.defaultFS:用于配置HDFS的主协议,默认为file:///。● hadoop.tmp.dir:用于指定NameNode日志及数据的存储目录,默认为/tmp。
步骤03 配置hdfs-site.xml文件。hdfs-site.xml文件用于配置HDFS的存储信息。使用vim打开hdfs-site.xml文件,并在<configuration></configuration>标签中输入以下内容:
<property><name>dfs.replication</name><value>1</value></property><property><name>dfs.permissions.enabled</name><value>false</value></property>配置说明:● dfs.replication:用于指定文件块的副本数量。HDFS特别适合于存储大文件,它会将大文件切分成每128MB一块,存储到不同的DataNode节点上,且默认会每一块备份2份,共3份,即此配置的默认值为3,最大为512。由于我们只有一个DataNode,所以这儿将文件副本数量修改为1。● dfs.permissions.enabled:访问时,是否检查安全,默认为true。为了方便访问,暂时把它修改为false。
步骤04 配置mapred-site.xml文件。
通过名称可见,此文件是用于配置MapReduce的配置文件。通过vim打开此文件,并在<configuration>标签中输入以下配置:
$ vim mapred-site.xml<property><name>mapreduce.framework.name</name><value>yarn</value></property>配置说明:● mapreduce.framework.name:用于指定调试方式。这里指定使用YARN作为任务调用方式。
步骤05 配置yarn-site.xml文件。由于上面指定了使用YARN作为任务调度,所以这里需要配置YARN的配置信息,同样,使用vim编辑yarn-site.xml文件,并在<configuration>标签中输入以下内容:
<property><name>yarn.resourcemanager.hostname</name><value>server201</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>通过hadoop classpath命令获取所有classpath的目录,然后配置到上述文件中。由于没有配置Hadoop的环境变量,所以这里需要输入完整的Hadoop运行目录,命令如下:
[hadoop@server201 hadoop]$ /app/hadoop-3.4.0/bin/hadoop classpath
输入完成后,将显示所有classpath信息:
/home/hadoop/program/hadoop-3.2.2/etc/hadoop:/home/hadoop/program/hadoop-3.
2.2/share/hadoop/common/lib/*:/home/hadoop/program/hadoop-3.2.2/share/hadoop/co
mmon/*:/home/hadoop/program/hadoop-3.2.2/share/hadoop/hdfs:/home/hadoop/program
/hadoop-3.2.2/share/hadoop/hdfs/lib/*:/home/hadoop/program/hadoop-3.2.2/share/h
adoop/hdfs/*:/home/hadoop/program/hadoop-3.2.2/share/hadoop/mapreduce/lib/*:/ho
me/hadoop/program/hadoop-3.2.2/share/hadoop/mapreduce/*:/home/hadoop/program/ha
doop-3.2.2/share/hadoop/yarn:/home/hadoop/program/hadoop-3.2.2/share/hadoop/yar
n/lib/*:/home/hadoop/program/hadoop-3.2.2/share/hadoop/yarn/*然后将上述的信息复制一下,并配置到yarn-site.xml文件中:
<property><name>yarn.application.classpath</name><value>/home/hadoop/program/hadoop-3.2.2/etc/hadoop:/home/hadoop/program/hadoop-3.
2.2/share/hadoop/common/lib/*:/home/hadoop/program/hadoop-3.2.2/share/hadoop/co
mmon/*:/home/hadoop/program/hadoop-3.2.2/share/hadoop/hdfs:/home/hadoop/program
/hadoop-3.2.2/share/hadoop/hdfs/lib/*:/home/hadoop/program/hadoop-3.2.2/share/h
adoop/hdfs/*:/home/hadoop/program/hadoop-3.2.2/share/hadoop/mapreduce/lib/*:/ho
me/hadoop/program/hadoop-3.2.2/share/hadoop/mapreduce/*:/home/hadoop/program/ha
doop-3.2.2/share/hadoop/yarn:/home/hadoop/program/hadoop-3.2.2/share/hadoop/yar
n/lib/*:/home/hadoop/program/hadoop-3.2.2/share/hadoop/yarn/*</value></property>配置说明:
● yarn.resourcemanager.hostname:用于指定ResourceManger的运行主机,默认为0.0.0.0,即本机。
● yarn.nodemanager.aux-services:用于指定执行计算的方式为mapreduce_shuffle。
● yarn.application.classpath:用于指定运算时的类加载目录。
步骤06 配置workers文件。
这个文件在之前的版本叫作slaves,但功能一样。主要用于在启动时启动DataNode和NodeManager。编辑workers文件,并输入本地名称:
server201
步骤07 配置Hadoop环境变量。
编辑/etc/profile文件:
$ sudo vim /etc/profile
并在里面添加以下内容:
export HADOOP_HOME=/app/hadoop-3.4.0
export PATH=$PATH:$HADOOP_HOME/bin
使用source命令,让环境变量生效:
source /etc/profile
然后使用hdfs version查看命令环境变量是否生效,如果配置成功,则会显示Hadoop的版本:
[hadoop@server201 hadoop]$ hdfs version Hadoop 3.4.0 Source code repository Unknown -r 7a3bc90b05f257c8ace2f76d74264906f0f7a932 Compiled by hexiaoqiao on 2024-08-03T09:26Z Compiled with protoc 2.5.0 From source with checksum 5a8f564f46624254b27f6a33126ff4 This command was run using /app/hadoop-3.4.0/share/hadoop/common/hadoop-comm on-3.4.0.jar
步骤08 初始化Hadoop的文件系统。
Hadoop在使用之前,必须先初始化HDFS文件系统,初始化的文件系统将会生成在hadoop.tmp.dir配置的目录下,即上面配置的/app/datas/hadoop目录下。
$ hdfs namenode -format
在执行命令完成以后,请在输出的日志中找到以下这句话,即为初始化成功:
Storage? directory /opt/hadoop_tmp_dir/dfs/name has been successfully formatted.
步骤09 启动HDFS和YARN。
启动和停止HDFS及YARN的脚本在$HADOOP_HOME/sbin目录下。其中start-dfs.sh为启动HDFS的脚本,start-yarn.sh为启动ResourceManager的脚本。以下命令分别启动HDFS和YARN:
[hadoop@server201 /]$ /app/hadoop-3.4.0/sbin/start-dfs.sh
[hadoop@server201 /]$ /app/hadoop-3.4.0/sbin/start-yarn.sh
启动完成以后,通过jps来查看Java进程快照,会发现有5个进程正在运行:
[hadoop@server201 /]$ jps12369 NodeManager12247 ResourceManager11704 NameNode12025 SecondaryNameNode12686 Jps11839 DataNode其中:NameNode、SecondaryNameNode、DataNode是通过start-dfs.sh脚本启动的。ResourceManager和NodeManager是通过start-yarn.sh脚本启动的。启动成功以后,也可以通过
http://server201:9870 查看NameNode的信息,如图所示。

可以通过http://server201:8088页面查看MapReduce的信息,如图所示。

步骤10 关闭。
关闭HDFS的YARN可以分别执行stop-dfs.sh和stop-yarn.sh脚本:
[hadoop@server201 /]$ /app/hadoop-3.4.0/sbin/stop-yarn.shStopping nodemanagersStopping resourcemanager[hadoop@server201 /]$ /app/hadoop-3.4.0/sbin/stop-dfs.shStopping namenodes on [server201]Stopping datanodesStopping secondary namenodes [server201]至此,Hadoop单机即伪分布式模式安装和配置成功。
1.3 Hadoop集群安装
Hadoop分布式集群配置-CSDN博客
2. HDFS实验,包括Shell命令操作和Java接口访问
2.1 HDFS操作命令
hdfs命令位于$HADOOP_HOME/bin目录下。由于已经配置了HADOOP_HOME和PATH的环境变量,所以此命令可以在任意目录下执行。可以通过直接输入hdfs命令,查看它的使用帮助:
$ hdfsUsage: hdfs [--config confdir] [--loglevel loglevel] COMMANDwhere COMMAND is one of:dfs run a filesystem command on the file systems supported in Hadoop.classpath prints the classpathnamenode -format format the DFS filesystemsecondarynamenode run the DFS secondary namenodenamenode run the DFS namenodejournalnode run the DFS journalnodezkfc run the ZK Failover Controller daemondatanode run a DFS datanodedebug run a Debug Admin to execute HDFS debug commandsdfsadmin run a DFS admin clienthaadmin run a DFS HA admin clientfsck run a DFS filesystem checking utilitybalancer run a cluster balancing utilityjmxget get JMX exported values from NameNode or DataNode.mover run a utility to move block replicas acrossstorage typesoiv apply the offline fsimage viewer to an fsimageoiv_legacy apply the offline fsimage viewer to an legacy fsimageoev apply the offline edits viewer to an edits filefetchdt fetch a delegation token from the NameNodegetconf get config values from configurationgroups get the groups which users belong tosnapshotDiff diff two snapshots of a directory or diff thecurrent directory contents with a snapshotlsSnapshottableDir list all snapshottable dirs owned by the current userUse -help to see optionsportmap run a portmap servicenfs3 run an NFS version 3 gatewaycacheadmin configure the HDFS cachecrypto configure HDFS encryption zonesstoragepolicies list/get/set block storage policiesversion print the versionMost commands print help when invoked w/o parameters.在上面的列表中,第一个dfs是经常被使用的命令。可以通过hdfs dfs-help查看dfs的具体使用方法。dfs命令,就是通过命令行操作HDFS目录或是文件 的命令,类似于Linux文件命令一样,只不过dfs操作的是HDFS文件系统中的文件。下表列出HDFS几个常用命令。

完成以下示例:
显示根目录下的所有文件和目录:
[hadoop@server201 ~]$ hdfs dfs -ls /
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2021-03-10 20:41 /test
以递归的形式显示根目录下的所有文件或目录,注意-R参数:
[hadoop@server201 ~]$ hdfs dfs -ls -R /
drwxr-xr-x - hadoop supergroup 0 2021-03-10 20:41 /test
-rw-r--r-- 1 hadoop supergroup 6 2021-03-10 20:41 /test/a.txt
删除HDFS上的文件:
[hadoop@server201 ~]$ hdfs dfs -rm /test/a.txt
将本地文件上传到HDFS上:
[hadoop@server201 ~]$ hdfs dfs -copyFromLocal a.txt /test/a.txt
使用put命令,同样可以将本地文件上传到HDFS上:
[hadoop@server201 ~]$ hdfs dfs -put a.txt /test/b.txt
使用get/copyToLocal选项,可以下载文件到本地:
[hadoop@server201 ~]$ hdfs dfs -get /test/c.txt a.txt
[hadoop@server201 ~]$ hdfs dfs -copyToLocal /test/a.txt a1.txt
2.2 通过Java项目访问HDFS
不仅可以使用hdfs命令操作HDFS文件系统上的文件,还可以使用Java代码访问HDFS文件系统中的文件。在Java代码中,操作HDFS主要通过以下几个主要的类:
● Configuration:用于配置HDFS。
● FileSystem:表示HDFS文件系统。
● Path:表示目录或是文件路径。
首先须在window中配置java环境
1.JAVA jdk安装教程:JDK安装配置教程(保姆级)-CSDN博客
2.Maven安装教程:Maven的安装与配置及IDEA配置(超详细图文讲解)_maven安装及配置教程-CSDN博客
使用IDEA创建Java项目来操作HDFS文件系统。IDEA有两个版本IC和IU两个版本,其中IU为IDEA Ultimate为完全功能版本,此版本需要付费后才能使用,可以选择IC版本, C为Community即社区版本的意思,IC版本为免费版本。后面集成开发环境将选择此IDEA Community版本。IDEA的下载地址为https://www.jetbrains.com/idea/download/#section=windows。选择下载IDEA Community版本,如图所示。

选择下载zip版本即可,下载完成后,解压到任意目录下(建议使用没有中文没有空格的目录)。运行IdeaIC/bin目录下的idea64.exe即可启动IDEA。接下来,就开始创建Java项目,并通过Java代码访问HDFS文件系统。
步骤01 创建maven项目。
打开IDEA并选择创建新的项目,如图所示。

选择创建Maven项目,如图所示。

选择项目创建的目录,并输入项目的名称,如图所示。

为了方便管理,以模块方式来开发,每一个实验可以为一个模块,而Hadoop是这些模块的父项目。所以,在创建完成Hadoop项目后,修改Hadoop的项目类型为pom。以下Hadoop父项目的pom.xml文件部分内容,父项目的<package>类型为pom。
【代码】hadoop/pom.xml文件
<groupId>org.hadoop</groupId><artifactId>hadoop</artifactId><version>1.0</version><packaging>pom</packaging>在父项目中的dependencyManagement添加所需要的依赖后,子模块只需要添加依赖名称,不再需要导入依赖的版本。这样父项目就起到了统一管理版本的功能。
<dependencyManagement><dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.2.2</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.13.2</version></dependency></dependencies></dependencyManagement>再创建第一个模块。选择Hadoop项目,选择创建模块,如图所示。

输入模块的名称,如图所示。

在创建的子模块chapter02中,修改pom.xml文件,添加以下依赖。注意,只输入groupId和artifactId,不需要输入版本,因为Hadoop项目作为父项目管理依赖的版本。
<dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><scope>test</scope></dependency></dependencies>查看hadoop client Aggretator的依赖关系,如图所示。

至此已经可以开发Java代码,访问HDFS文件系统了。
步骤02 HDFS操作示例。
(1)显示HDFS指定目录下的所有目录
显示所有目录,使用fileSystem.listStatus方法。
【代码】Demo01AccessHDFS.java
package org.hadoop;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
import org.apache.hadoop.fs.FileStatus;public class Demo01AccessHDFS {public static void main(String[] args) {System.setProperty("HADOOP_USER_NAME", "hadoop");Configuration config = new Configuration();config.set("fs.defaultFS", "hdfs://192.168.56.201:8020");//注意修改IPFileSystem fs = null;try {fs = FileSystem.get(config);} catch (IOException e) {throw new RuntimeException(e);}FileStatus[] stas = null;try {stas = fs.listStatus(new Path("/"));} catch (IOException e) {throw new RuntimeException(e);}for (FileStatus f : stas) {System.out.println(f.getPermission().toString()+" "+f.getPath().toString());}try {fs.close();} catch (IOException e) {throw new RuntimeException(e);}}
}
输出的结果如下所示:
rwxr-xr-x hdfs://192.168.56.201:8020/test
代码说明:
● 第1行代码用于设置访问Hadoop的用户名。
● 第2行代码用于声明一个新的访问配置对象。
● 第3行代码设置访问的具体地址。
● 第4行代码创建一个文件系统对象。
● 第5行~8行代码为输出根目录下的所有文件或目录,不包含子目录。
● 第9行代码关闭文件系统。
(2)显示所有文件显示所有文件,使用fileSystem.listFiles函数,第二个参数boolean用于指定是否递归显示所有文件。
【代码】Demo02ListFiles.java
package org.hadoop;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;
import java.io.IOException;public class Demo02ListFiles {public static void main(String[] args) {FileSystem fs = null;try {// 设置 Hadoop 用户名System.setProperty("HADOOP_USER_NAME", "hadoop");// 创建 Hadoop 配置对象Configuration config = new Configuration();config.set("fs.defaultFS", "hdfs://192.168.56.201:8020");// 获取 FileSystem 实例fs = FileSystem.get(config);// 列出 HDFS 上的文件RemoteIterator<LocatedFileStatus> files = fs.listFiles(new Path("/"), true);// 遍历并输出文件信息while (files.hasNext()) {LocatedFileStatus file = files.next();System.out.println(file.getPermission() + " " + file.getPath());}} catch (IOException e) {e.printStackTrace();} finally {// 确保在完成后关闭 FileSystem 实例try {if (fs != null) fs.close();} catch (IOException e) {e.printStackTrace();}}}
}
添加了true参数以后,执行的结果如下所示:
rw-r--r-- hdfs://192.168.56.201:8020/test/a.txt
(3)读取HDFS文件的内容
读取HDFS上的内容,可以和fileSystem.open(...)打开一个文件输入流,然后读取文件流中的内容即可。
【代码】Demo03ReadFile.java
package org.hadoop;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.DataInputStream;
import java.io.IOException;public class Demo03ReadFile {public static void main(String[] args) {String server = "hdfs://192.168.56.201:8020";String filePath = "/test/a.txt"; // 文件在 HDFS 中的路径System.setProperty("HADOOP_USER_NAME", "hadoop");Configuration config = new Configuration();config.set("fs.defaultFS", server);try (FileSystem fs = FileSystem.get(config);DataInputStream in = fs.open(new Path(filePath))) {byte[] bs = new byte[1024];int len;while ((len = in.read(bs)) != -1) {String str = new String(bs, 0, len);System.out.print(str);}} catch (IOException e) {e.printStackTrace();}}
}
(4)向HDFS写入数据
向HDFS写入数据,可以使用fileSysten.create/append方法,获取一个OutputStream,然后向里面输入数据即可。
【代码】Demo04WriteFile.java
package org.hadoop;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
import java.io.OutputStream;public class Demo04WriteFile {public static void main(String[] args) {String server = "hdfs://192.168.56.201:8020"; // HDFS 的 URISystem.setProperty("HADOOP_USER_NAME", "hadoop"); // 设置 HDFS 用户Configuration config = new Configuration();config.set("fs.defaultFS", server);try (FileSystem fs = FileSystem.get(config)) {Path filePath = new Path("/test/b.txt"); // 文件路径try (OutputStream out = fs.create(filePath)) {out.write("Hello Hadoop\n".getBytes());out.write("中文写入测试\n".getBytes());// No need to explicitly close OutputStream, it's handled by try-with-resources} catch (IOException e) {e.printStackTrace();}} catch (IOException e) {e.printStackTrace();}}
}
代码输入完成以后,通过cat查看文件中的内容:
[hadoop@server201 ~]$ hdfs dfs -cat /test/b.txt
Hello Hadoop
中文写入测试
2.3 使用winutils解决警告信息
Hadoop通常运行在Linux上,而开发程序通常是Windows,执行代码时,为了看到更多的日志信息,需要添加log4j.properties或log4j2的log4j2.xml。通过查看hadoop-client-3.2.2依赖可知,系统中已经包含了log4j 1.2的日志组件,如图所示。

此时只需要添加一个log4j与slf4j整合的依赖即可,所以添加以下依赖:
<dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.26</version></dependency>同时添加日志文件。直接在classpath下创建log4j.properties文件,即在项目的main/resources目录下添加log4j.properties文件即可:
log4j.rootLogger = debug,stdoutlog4j.appender.stdout = org.apache.log4j.ConsoleAppenderlog4j.appender.stdout.Target = System.outlog4j.appender.stdout.layout = org.apache.log4j.PatternLayoutlog4j.appender.stdout.layout.ConversionPattern = [%-5p] %d{yyyy-MM-dd HH:mm:
ss,SSS} method:%l%n%m%n再次运行上面访问HDFS的代码,将出现以下问题:
java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset
意思为HADOOP_HOME和hadoop.home.dir没有设置。虽然出现上述问题,但程序仍然可以执行成功。出现上述问题的原因是本地没有Hadoop的程序。此时,我们需要在本地,即Windows上解压一个相同的Hadoop版本,并配置HADOOP_HOME环境变量,将hadoop 3.2.2也同时解压到Windows系统的D:/program目录下(可根据实际配置),则配置环境变量为:
HADOOP_HOME=D:\program\hadoop-3.2.2
hadoop.home.dir=D:\program\hadoop-3.2.2
同时还需要添加winutils,可以从GitHub或Gitee网站上找到相关版本的winutils。将下载的文件放到D:\program\hadoop-3.2.2\bin中即可。再次运行,就没有任何警告信息了。
3. 实现MapReduce的WordCount
3.1 MapReduce的运算过程
MapReduce为分布式计算模型,分布式计算最早由Google提出。MapReduce将运算的过程分为两个阶段,map和reduce阶段。用户只需要实现map和reduce两个函数即可。这两个函数参数的形式都是以Key-Value的形式成对出现,Key为输出或输出的信息,Value为输入或输出的值。
如图展示了MapReduce的运算过程。将大任务交给多个机器分布式进行计算,然后再进行汇总合并。

图介绍如下:
第1行,Input为输入源,因为输入源是以分布式形式保存到HDFS上的,所以可以同时开启多个Mapper程序,同时读取数据。读取数据时,Mapper将接收两个输入的参数,第一个Key为读取到的文件的行号,Value为读取到的这一行的数据。
第2~3行,Mapper在处理完成以后,也将输出Key-Value对形式的数据。
第4行,是Reducer接收Mapper输入的数据,在接收数据之前进行排序操作,这个排序操作我们一般称为shuffle。注意,Reducer接收到的Value值是一个数组,多个重复Key的Value会在Reducer程序中合并成数组。
第5行,是Reducer的输出,也是以Key-Value对象的形式对外输出到文件或其他存储设备中。
以WordCount为示例,再理解一下MapReduce的过程,如图所示。

(1)标注为1的部分为Hadoop的HDFS文件系统中的文件,即被处理的数据应该首先保存到HDFS文件系统上。
(2)标注为2的部分,将接收FileInputFormat的输入数据。在处理WordCount示例时,接收到的数据key1为LongWritable类型,即为字节的偏移量。比如,标注为2的部分中第一行输入为0,其中0为字节0下标的开始;第二行为11,则11为文本中第二行字节的偏移量,以此类推。而Value1则为Text即文本类型,其中第一行Hello Jack为读取的第一行的数据,以此类推。然后,此时我们将开发代码对Value1的数据进行处理,以空格或是\t作为分割,分别将Hello和Jack依次输出。此时每一次输出的算是一个字符,所以在Map中的输出格式Key2为Text类型,而Value2则为LongWritable类型。
(3)标注为3的部分,接收Map的输出,所以Key3和Value3的类型应该与Key2和Value2的类型一致。现在只需要将Value中的值相加,就可以得到Hello出现的次数。然后直接输出给Key4和Value4。如果已经理解了这个MapReduce的过程,接下来就可以快速开发WordCount代码了。注意:LongWritable和Text为Hadoop中的序列化类型。可以简单理解为Java中的Long和String。
3.2 WordCount示例
以本地运行和服务器运行的方式分别部署,能更深入了解MapReduce的开发、运行和部署。
使用打包的方式将程序打包后放到Hadoop集群上运行。
步骤01 创建Java项目并添加依赖。
创建Java项目,并添加以下依赖。注意,本次以添加的依赖为hadoop-mincluster,且设置scope的值为provided(意思是,在打包时将不会被打包到依赖的jar包中)。
<dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-minicluster</artifactId><scope>provided</scope><version>3.2.2</version></dependency>步骤02 开发WordCount的完整代码。
【代码】WordCount.java
package org.hadoop;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
public class WordCount extends Configured implements Tool {public static void main(String[] args) throws Exception {int result = ToolRunner.run(new WordCount(), args);System.exit(result);}//声明嗠顺地址private static String server = "hdfs://server201:8020";public int run(String[] args) throws Exception {if (args.length != 2) {System.err.println("usage: " + this.getClass().getSimpleName() + " <inPath> <outPath>");ToolRunner.printGenericCommandUsage(System.out);return -1;}Configuration config = getConf();config.set("fs.defaultFS", server);//指定resourcemanger的地址config.set("yarn.resourcemanager.hostname", "server201");config.set("dfs.replication", "1");config.set("dfs.permissions.enabled", "false");FileSystem fs = FileSystem.get(config);Path dest = new Path(server + args[1]);if (fs.exists(dest)) {fs.delete(dest, true);}Job job = Job.getInstance(config,"WordCount");job.setJarByClass(getClass());job.setMapperClass(WordCountMapper.class);job.setReducerClass(WordCountReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(LongWritable.class);FileInputFormat.addInputPath(job, new Path(server + args[0]));FileOutputFormat.setOutputPath(job, dest);boolean boo = job.waitForCompletion(true);return boo ? 0 : 1;}public static class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable> {private LongWritable count = new LongWritable(1);private Text text = new Text();@Overridepublic void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {String str = value.toString();String[] strs = str.split("\\s+");for (String s : strs) {text.set(s);context.write(text, count);}}}public static class WordCountReducer extends Reducer<Text, LongWritable, Text, LongWritable> {@Overridepublic void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {long sum = 0;for (LongWritable w : values) {sum += w.get();}context.write(key, new LongWritable(sum));}}
}上例代码中,由于我们声明了完整的地址,所以可以在本地运行测试。在本地运行测试需要输入两个参数。选择IDEA的run > Edit Configurations,并在Program Arguments位置输入读取文件的地址和输出结果的目录,如图所示。

在本地环境下直接运行,并查看HDFS上的结果目录,WordCount程序已经将结果输出到指定的目录中。
[hadoop@server201 ~]$ hdfs dfs -ls /out001
Found 2 items
-rw-r--r-- 1 mrchi supergroup 0 2024-09-13 22:14 /out001/_SUCCESS
-rw-r--r-- 1 mrchi supergroup 520 2024-09-13 22:14 /out001/part-r-00000
步骤03 使用Maven打包程序。
在IDEA右侧栏的Maven视图中,单击package并运行,可以得到一个jar包,如图所示。

打完的包可以在target目录下找到,将jar包上传到server201服务器的/root目录下,并使用yarn jar执行。
使用yarn jar执行,使用以下命令:
$ yarn jar chapter04-1.0.jar org.hadoop.WordCount /test/a.txt /out002
查看执行结果,即为单词统计的结果。根据处理的文件不同,这个结果文件的内容会有所不同。
[root@server201 ~]# hdfs dfs -cat /out002/* | head
-> 4
0 2
1 4
至此,已经学会如何在本地及打包到服务器上运行MapReduce程序了。
3.3 可能遇到的bug
注意:在本地运行时,有可能会出现以下错误:
Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.Nati veIO$Windows.access0(Ljava/lang/String;I)Z
解决方案是:将hadoop.dll文件放到windows/system32目录下即可。
4.Hbase安装配置实验
HBase是Hadoop DataBase的意思。HBase是一种构建在HDFS之上的分布式、面向列的存储系统。在需要实时读写、随机访问超大规模数据集时,可以使用HBase。HBase是Google Bigtable的开源实现,与Google Bigtable利用GFS作为其文件存储系统类似,HBase利用Hadoop HDFS作为其文件存储系统,也是利用HDFS实现分布式存储的。Google运行MapReduce来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据,Google Bigtable利用Chubby作为协同服务,HBase利用ZooKeeper作为协同服务。
HBase具有如下特点:
● 大:一个表可以有上亿行,上百万列。
● 面向列:面向列表(族)的存储和权限控制,列(族)独立检索。
● 稀疏:对于为空(NULL)的列,并不占用存储空间,因此表可以设计得非常稀疏。
● 无模式:每一行都有一个可以排序的主键和任意多的列,列可以根据需要动态增加,同一张表中不同的行可以有截然不同的列。
● 数据多版本:每个单元中的数据可以有多个版本。默认情况下,版本号自动分配,版本号就是单元格插入时的时间戳。
● 数据类型单一:HBase中的数据都是字符串,没有类型。
4.1 HBase的安装
HBase可能独立运行在一台主机上。此时HBase将只会有一个进程,即HMaster(这个HMaster内含HRegionServer和HQuorumPeer两个服务)。虽然只有一个进程,但也可以提供HBase的大部分功能。首先需要了解HBase的版本信息,可以在HBase的官方网站上,通过hbase documents查看HBase对JDK、Hadoop版本的兼容性,尤其是对Hadoop版本具有较强依耐性。下载的地址为https://mirrors.tuna.tsinghua.edu.cn/apache/hbase
4.1.1 HBase的单节点安装
HBase单节点安装可以快速学会HBase的基本使用。HBase的单节点安装不需要Hadoop,数据保存到指定的磁盘目录下。在hbase-site.xml文件中,通过“hbase.rootdir=file:///”来指定数据保存的目录。也不需要ZooKeeper,启动后HBase将使用自带的ZooKeeper。只有一个进程Hmaster(内部包含:HRegionServer和HQuorumPeerman两个子线程)。以下是HBase单节点安装的过程。
步骤01 上传并解压HBase(通过winscp)。
同样地,使用tar将HBase解压到/app/目录下:
$ tar -zxvf hbase-2.3.4-bin.tar.gz -C /app/
步骤02 修改配置文件。首先修改的是hbase-env.sh文件,此文件中保存了JAVA_HOME环境变量信息。配置如下:
$ vim /app/hbase-2.3.4/conf/hbase-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_281
export HBASE_MANAGES_ZK=true
再修改hbase-site.xml配置文件,此配置文件中,需要指定HBase数据的保存目录,由于目的是快速入门,所以可以先将HBase的数据保存到磁盘上。具体的配置如下:
$ vim /app/hbase-2.3.4/conf/hbase-site.xml<configuration><property><name>hbase.rootdir</name><value>file:///app/datas/hbase</value></property><property><name>hbase.zookeeper.property.dataDir</name><value>/app/datas/zookeeper</value></property><!--以下配置是否检查流功能--><property><name>hbase.unsafe.stream.capability.enforce</name><value>false</value></property></configuration>修改regionservers文件,此文件用于指定HRegionServer的服务器地址,由于是单机部署,所以指定本机名称即可。添加本机主机名:
$ vim regionservers server201
步骤03 启动/停止HBase。
启动HBase,只需要在HBase的bin目录下,执行start-hbase.sh即可。
[hadoop@server201 app]$ hbase-2.3.4/bin/start-hbase.shSLF4J: Class path contains multiple SLF4J bindings.SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]启动完成以后,通过jps查看进程,会发现HMaster进程已经运行:
[hadoop@server201 app]$ jps
7940 Jps
7785 HMaster
停止HBase只需要执行stop-hbase.sh即可:
[hadoop@server201 app]$ hbase-2.3.4/bin/stop-hbase.sh
stopping hbase...
步骤04 登录HBase Shell。
在bin目录下,使用hbase shell命令登录HBase Shell,即可操作HBase数据库。登录成功后,将显示hbase >命令行。
[hadoop@server201 app]$ hbase-2.3.4/bin/hbase shellHBase ShellUse "help" to get list of supported commands.Use "exit" to quit this interactive shell.For Reference, please visit: http://hbase.apache.org/2.0/book.html#shellVersion 2.3.4, rafd5e4fc3cd259257229df3422f2857ed35da4cc, Thu Jan 14 21:32:25 UTC 2021Took 0.0006 secondshbase(main):001:0>步骤05 HBase数据操作。
快速创建一个表,保存一些数据,以了解HBase是如何保存数据的。首先,如果不了解HBase命令,可以直接在HBase的命令行输入help,此命令将会显示HBase的帮助信息。
创建一个命名空间,可以理解成创建了一个数据库:
hbase(main):009:0> create_namespace 'ns1'
Took 0.1776 seconds
查看所有命名空间,可以理解成查看所有数据库:
hbase(main):010:0> list_namespaceNAMESPACEdefaulthbasens13 row(s)Took 0.0158 seconds创建一个表,在指定的命名空间下,并指定列族为“f”。可以理解为创建一个表,并指定一个列名为f:
hbase(main):011:0> create 'ns1:stud','f'Created table ns1:studTook 0.8601 seconds=> Hbase::Table - ns1:stud向表中写入一行记录,其中R001为主键,即Row Key,f:name为列名,Jack为列值。此处与关系型数据库有很大的区别,注意区分。
hbase(main):012:0> put 'ns1:stud','R001','f:name','Jack'Took 0.3139 secondshbase(main):013:0> put 'ns1:stud','R002','f:age','34'Took 0.0376 seconds查询表,类似于关系型数据库中的select:
hbase(main):014:0> scan 'ns1:stud'ROW COLUMN+CELLR001 column=f:name, timestamp=1568092417316, value=JackR002 column=f:age, timestamp=1568092435076, value=342 row(s)Took 0.0729 seconds4.1.2 HBase的伪分布式安装
HBase的伪分布式安装,是将HBase的数据保存到伪分布式的HDFS系统中。此时Hadoop环境为伪分布式,HBase的节点只有一个,HBase使用独立运行的ZooKeeper。以下步骤将配置一个HBase的伪分布式运行环境。需要:
● 配置好的Hadoop运行环境。
● 独立运行的ZooKeeper,只有一个节点即可。
● 将Hadoop的ZooKeeper指向这个独立的ZooKeeper。
步骤01 准备Hadoop和ZooKeeper。
配置好Hadoop的伪分布式运行环境。
配置好ZooKeeper的独立节点运行环境:ZooKeeper集群安装-CSDN博客。
测试以上两个环境正常运行并可用。
步骤02 修改HBase配置文件。
首先修改HBase的配置文件hbase-env.sh文件,在此配置文件中,重点配置ZooKeeper选项,配置为使用外部的ZooKeeper即可。具体配置如下:
$ vim /app/hbase-2.3.4/conf/hbase-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0-281
export HBASE_MANAGES_ZK=false
修改HBase配置文件hbase-site.xml文件,重点关注hbase.rootdir用于指定在Hadoop中存储HBase数据的目录。ZooKeeper用于指定ZooKeeper地址。
<configuration><property><name>hbase.cluster.distributed</name><value>true</value></property><property><name>hbase.tmp.dir</name><value>/app/datas/hbase/tmp</value></property><property><name>hbase.unsafe.stream.capability.enforce</name><value>false</value></property><property><name>hbase.rootdir</name><value>hdfs://server201:8020/hbase</value></property><property><name>hbase.zookeeper.quorum</name><value>server201:2181</value></property></configuration>步骤03 启动HBase。
直接使用start-hbase.sh启动HBase:
$ /app/hbase-2.3.4/bin/start-hbase.sh
查看HBase的进程如下:
[hadoop@server201 conf]$ jps2992 NameNode3328 SecondaryNameNode5793 Jps5186 Main3560 ResourceManager4120 QuorumPeerMain4728 HRegionServer3691 NodeManager4523 HMaster3119 DataNode同样地,可以通过浏览器查看16010端口,如图所示。



















