【大语言模型】ACL2024论文-10 CSCD-IME: 纠正拼音输入法产生的拼写错误
目录
文章目录
- 【大语言模型】ACL2024论文-10 CSCD-IME: 纠正拼音输入法产生的拼写错误
- 目录
- 摘要
- 研究背景
- 问题与挑战
- 如何解决
- 创新点
- 算法模型
- 1. 错误检测模型
- 2. 伪数据生成模块
- 3. n-gram语言模型过滤
- 4. 多任务学习(MTL)
- 5. 对抗训练
- 实验效果(包含重要数据与结论)
- 后续优化方向
- 后记

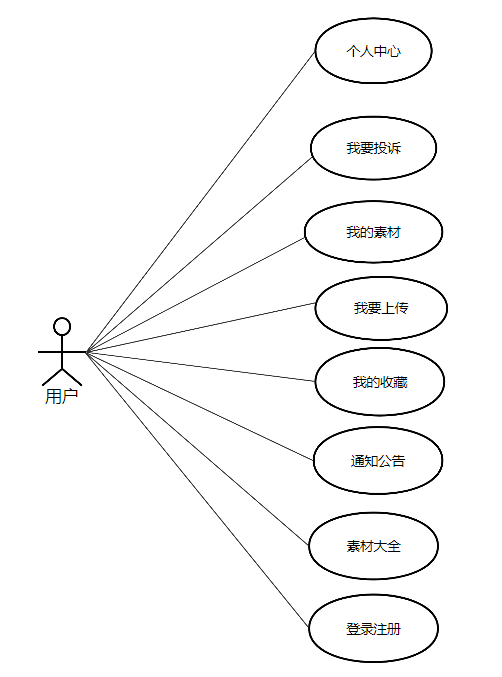
CSCD-IME: 纠正拼音输入法产生的拼写错误
摘要
本文研究了中文拼写校正(CSC)任务,特别是针对拼音输入法(IME)产生的错误。作者首先介绍了一个包含40,000个标注句子的中文拼写校正数据集(CSCD-IME),这些句子来自新浪微博上的官方媒体帖子。接着,提出了一种通过模拟拼音输入法输入过程自动构建大规模、高质量的伪数据的新方法。通过一系列分析和实验,展示了拼音IME产生的拼写错误在拼音层面和语义层面具有特定的分布,并且足够具有挑战性。同时,提出的伪数据构建方法能够更好地适应这种错误分布,并提高CSC系统的性能。最后,文章还提供了使用伪数据的有用指南,包括数据规模、数据来源和训练策略。
研究背景
中文拼写校正(CSC)任务旨在检测和纠正中文文本中的拼写错误。由于大多数中文输入依赖于拼音输入法,因此研究拼音输入法过程中的拼写错误更具实际价值。然而,目前还没有专门针对这一场景的研究。现有的研究通常使用SIGHAN数据集作为基线,但这些数据集无法准确评估CSC系统的真实性能,因为它们的错误来源与拼音IME产生的错误有很大差异。


问题与挑战
- 缺乏专业基准数据集:缺乏针对拼音IME错误生成的专业基准数据集。
- 错误分布差异:现有数据集的错误分布与拼音IME产生的错误分布不一致。
- 数据集规模小:现有数据集规模较小,可能导致评估结果不可靠。
- 拼写错误的特性:拼音IME产生的拼写错误在拼音层面和语义层面具有特定的分布,这对CSC系统来说是一个挑战。
如何解决
- 构建新的数据集CSCD-IME:包含40,000个标注句子,是迄今为止最大的CSC任务数据集。
- 设计拼音和语义层面的标注系统:深入分析拼写错误分布。
- 提出新的伪数据构建方法:通过模拟拼音IME输入过程并添加采样噪声来生成伪数据。
- 使用n-gram语言模型进行二次过滤:确保生成的伪数据质量。
创新点
- CSCD-IME数据集:提供了一个大规模、高质量的CSC任务数据集,填补了领域空白。
- 拼音IME模拟的伪数据构建方法:提出了一种新颖的方法,能够生成符合实际输入场景的高质量伪数据。
- 深入的错误分布分析:在拼音层面和语义层面对错误分布进行了深入分析,为CSC系统的改进提供了指导。
算法模型
- 错误检测模型:用于检测句子中的错误字符,基于预训练的编码器和词嵌入。
- 伪数据生成模块:模拟拼音IME输入过程,添加噪声生成伪数据。
- n-gram语言模型过滤:对生成的伪数据进行过滤,确保错误的真实性。
1. 错误检测模型
错误检测模型是用于识别句子中的拼写错误。该模型的输出是一个概率序列,表示每个字符是错误字符的概率。具体来说,模型的输出 y d y_d yd 是一个概率序列,其中 y d i ∈ ( 0 , 1 ) y_{di} \in (0, 1) ydi∈(0,1) 表示字符 x w i x_{wi} xwi 是错误的概率。模型的公式化如下:
y d = sigmoid ( W T ( E ( e ) ) ) y_d = \text{sigmoid}(W^T(E(e))) yd=sigmoid(WT(E(e)))
其中 e = ( e w 1 , e w 2 , . . . , e w N ) e = (e_{w1}, e_{w2}, ..., e_{wN}) e=(ew1,ew2,...,ewN) 是词嵌入, E ( ∗ ) E(*) E(∗) 是预训练的编码器。这个模型基于SIGHAN13-15的训练数据和Wang的伪数据进行训练,并在SIGHAN13-15的测试数据上保存最佳检查点。
2. 伪数据生成模块
伪数据生成模块通过模拟拼音输入法的输入过程并添加噪声来构建伪数据。这个过程包括以下几个步骤:
- 采样拼音噪声 ν p i n y i n \nu_{pinyin} νpinyin、标记粒度噪声 ν t o k e n \nu_{token} νtoken 和错误数量噪声 ν n u m \nu_{num} νnum。
- 根据 ν n u m \nu_{num} νnum 确定要生成的错误数量。
- 对于每个错误,基于 ν t o k e n \nu_{token} νtoken 从正确的句子中随机选择一个词或字符。
- 输入所选标记的正确文本,并根据 ν p i n y i n \nu_{pinyin} νpinyin 输入所选标记的正确或错误的拼音。
- 如果拼音输入法推荐的首个标记是正确的,随机选择第二或第三个标记作为噪声;否则,直接选择第一个标记作为噪声。
- 用噪声标记替换原始句子中的正确标记。
这个过程生成的伪数据能够模拟真实世界中通过拼音输入法产生的错误,从而用于训练和改进拼写校正系统。
3. n-gram语言模型过滤
为了确保生成的伪数据质量,使用n-gram语言模型进行二次过滤。具体来说,计算生成句子和原始句子的困惑度(PPL)值,并且只有当添加噪声后PPL值相对于原始句子有所改善时,才认为生成的噪声确实是错误。公式化如下:
P P L ( noise ) − P P L ( origin ) P P L ( origin ) > δ \frac{PPL(\text{noise}) - PPL(\text{origin})}{PPL(\text{origin})} > \delta PPL(origin)PPL(noise)−PPL(origin)>δ
其中 δ \delta δ 是根据选定的语言模型调整的阈值。这一步骤确保了伪数据集的高质量。
4. 多任务学习(MTL)
文章中提到了多任务学习(MTL)的概念,这是一种训练模型以同时执行多个相关任务的方法。MTL的关键优势在于能够共享不同任务之间的通用特征,同时学习特定于任务的特征。这种方法可以提高模型的泛化能力,并在新任务上有更好的表现。MTL的一些关键技术包括软参数共享、块稀疏正则化和深度关系网络等。
5. 对抗训练
对抗训练是一种提高模型鲁棒性的方法,通过在训练过程中引入对抗性扰动来增强模型对输入扰动的抵抗力。文章中提到了对抗训练可能损害模型的泛化能力,但也提出了一些方法来平衡鲁棒性和泛化性,例如通过鲁棒关键微调(RiFT)来提升对抗训练模型的泛化性。
这些算法模型和方法共同构成了文章中提出的拼写校正框架,旨在提高对拼音输入法产生错误的检测和校正能力,并生成高质量的伪数据以支持模型训练和评估。
实验效果(包含重要数据与结论)
- 基准性能:在不使用任何伪数据的情况下,字符级别的整体校正F1分数接近67%;引入200万伪数据后,性能显著提升,但最佳性能仅略高于76%。
- 错误类型分析:所有模型在处理词级错误时的表现不如字符级错误,最大差距可达5%。
- 伪数据方法比较:提出的拼音IME基础的伪数据构建方法比其他现有方法更有效。




后续优化方向
- 模型改进:需要进一步改进模型以更好地理解和处理上下文和实体,特别是对于词级错误。
- 数据集扩展:继续扩展和丰富CSCD-IME数据集,以覆盖更广泛的错误类型和场景。
- 训练策略优化:探索更有效的训练策略,如多任务学习或对抗训练,以提高模型的鲁棒性和泛化能力。
- 跨领域适应性:研究模型在不同领域和风格文本上的适应性,提高模型的实用性。
后记
如果您对我的博客内容感兴趣,欢迎三连击 (***点赞、收藏和关注 ***)和留下您的评论,我将持续为您带来计算机人工智能前沿技术(尤其是AI相关的大语言模型,深度学习和计算机视觉相关方向)最新学术论文及工程实践方面的内容分享,助力您更快更准更系统地了解 AI前沿技术。