前言
对任意突发性的,无法预先感知的热点数据,包括热点数据(如突发大量请求同一个商品)、热用户(如恶意爬虫刷子)、热接口(突发海量请求同一个接口)等,一瞬间打到我们的服务器,这些突发的无法预先感知的压力,将会使我们系统潜在巨大风险。
譬如我们在Mysql之上做一层缓存,将数据存放在redis,那个未知的热数据会按照hash规则被存在于某个redis分片上,平时使用时都从该分片获取它的数据。由于redis性能还不错,再加上集群模式,每秒我们假设它能支撑20万次读取,这足以支持大部分的日常使用了。但是,以京东为例的这些头部互联网公司,动辄某个爆品,会瞬间引入每秒上百万甚至数百万的请求,当然流量多数会在几秒内就消失。但就是这短短的几秒的热key,就会瞬间造成其所在redis分片集群瘫痪。
原因也很简单,redis作为一个单线程的结构,所有的请求到来后都会去排队,当请求量远大于自身处理能力时,后面的请求会陷入等待、超时。由于该redis分片完全被这个key的请求给打满,导致该分片上所有其他数据操作都无法继续提供服务,也就是热key不仅仅影响自己,还会影响和它合租的数据。很显然,在这个极短的时间窗口内,我们是无法快速扩容10倍以上redis来支撑这个热点的。虽然redis已经很优秀,但面对这种场景时,往往也是redis成为最大的瓶颈。
譬如我们在Redis之上再做一层JVM的缓存,先访问JVM的缓存,数据不存在,我们再从Redis中获取数据,如果 Redis 中的数据也不存在的话,最后才从Mysql 中获取数据。但有个问题,对任意突发性的,无法预先感知的热点数据,我们将什么数据放在JVM缓存呢?
对于这个问题,JD-hotkey 提供了一整套解决方案,我们可以直接使用这个框架来解决我们的问题。
JD-hotkey 框架介绍
JD-hotkey 项目地址
在经历了多次被突发海量请求压垮数据层服务的场景,并时刻面临大量的爬虫刷子机器人用户的请求,京东根据既有经验设计开发了一套通用轻量级热key探测框架——JdHotkey。
它很轻量级,既不改redis源码也不改redis的客户端jar包,当然,它与redis没一点关系,完全不依赖redis。它是一个独立的系统,部署后,在server代码里引入jar,之后就像使用一个本地的HashMap一样来使用它即可。
框架自身会完成一切,包括对待测key的上报,对热key的推送,本地热key的缓存,过期、淘汰策略等等。框架会告诉你,它是不是个热key,其他的逻辑交给你自己去实现即可。
它有很强的实时性,默认情况下,500ms即可探测出待测key是否热key,是热key它就会进到jvm内存中。当然,我们也提供了更快频率的设置方式,通常如果非极端场景,建议保持默认值就好,更高的频率带来了更大的资源消耗。
它有着强悍的性能表现,一台8核8G的机器,在承担该框架热key探测计算任务时(即下面架构图里的worker服务),每秒可以处理来自于数千台服务器发来的高达16万个的待测key,8核单机吞吐量在16万,16核机器每秒可达30万以上探测量,当然前提是cpu很稳定。高性能代表了低成本,所以我们就可以仅仅采用10台机器,即可完成每秒近300万次的key探测任务,一旦找到了热key,那该数据的访问耗时就和redis不在一个数量级了。如果是加redis集群呢?把QPS从20万提升到200万,我们又需要扩充多少台服务器呢?

JD-hotkey 核心结构
1、etcd集群
etcd作为一个高性能的配置中心,可以以极小的资源占用,提供高效的监听订阅服务。主要用于存放规则配置,各worker的ip地址,以及探测出的热key、手工添加的热key等。
2、client端jar包
就是在服务中添加的引用jar,引入后,就可以以便捷的方式去判断某key是否热key。同时,该jar完成了key上报、监听etcd里的rule变化、worker信息变化、热key变化,对热key进行本地caffeine缓存等。
3、worker端集群
worker端是一个独立部署的Java程序,启动后会连接etcd,并定期上报自己的ip信息,供client端获取地址并进行长连接。之后,主要就是对各个client发来的待测key进行累加计算,当达到etcd里设定的rule阈值后,将热key推送到各个client。
4、dashboard控制台
控制台是一个带可视化界面的Java程序,也是连接到etcd,之后在控制台设置各个APP的key规则,譬如2秒出现20次算热key。然后当worker探测出来热key后,会将key发往etcd,dashboard也会监听热key信息,进行入库保存记录。同时,dashboard也可以手工添加、删除热key,供各个client端监听。
综上,可以看到该框架没有依赖于任何定制化的组件,与redis更是毫无关系,核心就是靠netty连接,client端送出待测key,然后由各个worker完成分布式计算,算出热key后,就直接推送到client端,非常轻量级。
JD-hotkey 工作流程
1、首先搭建etcd集群
etcd作为全局共用的配置中心,将让所有的client能读取到完全一致的worker信息和rule信息。
2、启动dashboard可视化界面
在界面上添加各个APP的待测规则,如app1它包含两个规则,一个是userId_开头的key,如userId_abc,每2秒出现20次则算热key,第二个是skuId_开头的每1秒出现超过100次则算热key。只有命中规则的key才会被发送到worker进行计算。
3、启动worker集群
worker集群可以配置APP级别的隔离,也可以不隔离,做了隔离后,这个app就只能使用这几个worker,以避免其他APP在性能资源上产生竞争。worker启动后,会从etcd读取之前配置好的规则,并持续监听规则的变化。
然后,worker会定时上报自己的ip信息到etcd,如果一段时间没有上报,etcd会将该worker信息删掉。worker上报的ip供client进行长连接,各client以etcd里该app能用的worker信息为准进行长连接,并且会根据worker的数量将待测的key进行hash后平均分配到各个worker。
之后,worker就开始接收并计算各个client发来的key,当某key达到规则里设定的阈值后,将其推送到该APP全部客户端jar,之后推送到etcd一份,供dashboard监听记录。
4、client端
client端启动后会连接etcd,获取规则、获取专属的worker ip信息,之后持续监听该信息。获取到ip信息后,会通过netty建立和worker的长连接。
client会启动一个定时任务,每500ms(可设置)就批量发送一次待测key到对应的worker机器,发送规则是key的hashcode 对worker数量取余,所以固定的key肯定会发送到同一个worker。这500ms内,就是本地搜集累加待测key及其数量,到期就批量发出去即可。注意,已经热了的key不会再次发送,除非本地该key缓存已过期。
当worker探测出来热key后,会推送过来,框架采用caffeine进行本地缓存,会根据当初设置的rule里的过期时间进行本地过期设置。当然,如果在控制台手工新增、删除了热key,client也会监听到,并对本地caffeine进行增删。这样,各个热key在整个client集群内是保持一致性的。
jar包对外提供了判断是否是热key的方法,如果是热key,那么你只需要关心自己的逻辑处理就好,是限流它、是降级它访问的部分接口、还是给它返回value,都依赖于自己的逻辑处理,非常的灵活。
注意,我们关注的只有key本身,也就是一个字符串而已,而不关心value,我们只探测key。那么此时必然有一个疑问,如果是redis的热key,框架告诉了我哪个是热key,并没有给我value啊。是的,框架提供了是否是热key的方法,如果是redis热key,就需要用户自己去redis获取value,然后调用框架的set方法,将value也set进去就好。如果不是热key,那么就走原来的逻辑即可。所以可以将框架当成一个具备热key的HashMap但需要自己去维护value的值。
综上,该框架以非常轻量级的做法,实现了毫秒级热key精准探测,和集群规模一致性,适用于大量场景,任何对某些字符串有热度匹配需求的场景都可以使用。
JD-hotkey 安装流程
-
安装etcd
在etcd下载页面下载对应操作系统的etcd,https://github.com/etcd-io/etcd/releases 使用3.4.x以上。相关搭建细节,及常见问题会发布到CSDN博客内。
-
启动worker(集群) 下载并编译好代码,将worker打包为jar,启动即可。如:
java -jar $JAVA_OPTS worker-0.0.1-SNAPSHOT.jar --etcd.server=${etcdServer}worker可供配置项如下:

etcdServer为etcd集群的地址,用逗号分隔
JAVA_OPTS是配置的JVM相关,可根据实际情况配置
threadCount为处理key的线程数,不指定时由程序来计算。
workerPath代表该worker为哪个应用提供计算服务,譬如不同的应用appName需要用不同的worker进行隔离,以避免资源竞争。
-
启动控制台
下载并编译好dashboard项目,创建数据库并导入resource下db.sql文件,注意JD-hotkey的配置都是使用Mysql8.0的,最好使用Mysql8.0,不然需要自己去改配置和调试。 配置一下application.yml里的数据库相关和etcdServer地址。
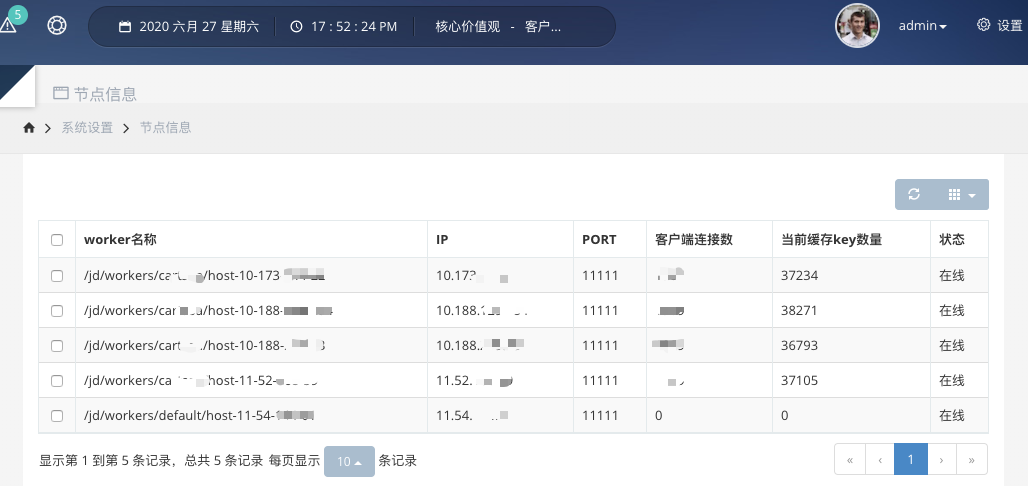
启动dashboard项目,访问ip:8081,即可看到界面。
其中节点信息里,即是当前已启动的worker列表。
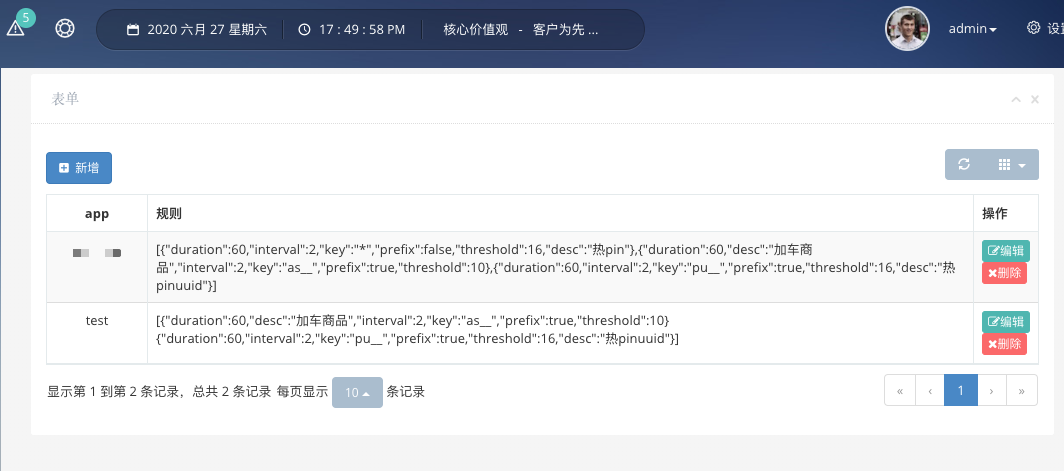
规则配置就是为各app设置规则的地方,初次使用时需要先添加APP。在用户管理菜单中,添加一个新用户,设置他的APP名字,如sample。之后新添加的这个用户就可以登录dashboard给自己的APP设置规则了,登录密码默认123456。
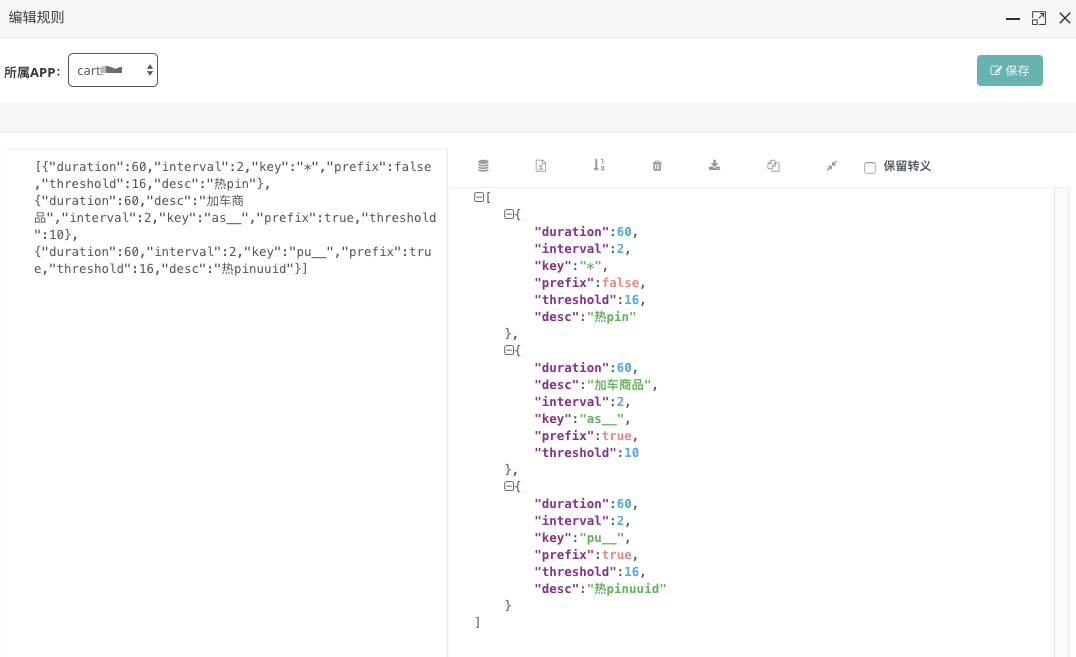
key-(*代表任意以key为前缀), prefix-是否前缀, interval-间隔时间(秒), threshold-阈值, duration-缓存时间(秒),默认60 如图就是一组规则,譬如其中as__开头的热key的规则就是interval-2秒内出现了threshold-10次就认为它是热key,它就会被推送到jvm内存中,并缓存60秒,prefix-true代表前缀匹配。那么在应用中,就可以把一组key,都用as__开头,用来探测。
-
-
client端 打包
需要注意:JD-hotkey 没有放在Maven仓库中,所以需要自己下载源码,编译,然后打包成Jar 放在自己的仓库里面,然后给项目引用。
JD-hotkey 使用流程
在项目中引入client的pom依赖。
<dependency><groupId>com.jd.platform.hotkey</groupId><artifactId>hotkey-client</artifactId><version>0.0.4-SNAPSHOT</version></dependency>初始化连接etcd配置
@Configuration
public class HotKeyConfig {@PostConstructpublic void initHotkey() {ClientStarter.Builder builder = new ClientStarter.Builder();// 注意,setAppName很重要,它和dashboard中相关规则是关联的。ClientStarter starter = builder.setAppName("gorgor").setEtcdServer("http://127.0.0.1:2379").setCaffeineSize(10).build();starter.startPipeline();}
}其中还可以setCaffeineSize(int size)设置本地缓存最大数量,默认5万,setPushPeriod(Long period)设置批量推送key的间隔时间,默认500ms,该值越小,上报热key越频繁,相应越及时,建议根据实际情况调整,如单机每秒qps10个,那么0.5秒上报一次即可,否则是空跑。该值最小为1,即1ms上报一次。
注意:
如果原有项目里使用了guava,需要升级guava为以下版本,否则过低的guava版本可能发生jar包冲突。或者删除自己项目里的guava的maven依赖,guava升级不会影响原有任何逻辑。
<dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>28.2-jre</version><scope>compile</scope>
</dependency>
有时可能项目里没有直接依赖guava,但是引入的某个pom里引了guava,也需要将guava排除掉。
如果原有项目使用了fastjson,需要降为2.0.0版本以下, 在2.0.0版本以上,com.alibaba.fastjson.serializer.JSONLibDataFormatSerializer类已经删除。 导致JSON工具类com.jd.platform.hotkey.common.tool.FastJsonUtils初始化时找不到类。 规则配置的json转换有问题。 推荐使用与HotKey相同的版本:
<dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.70</version>
</dependency>
使用:
主要有如下4个方法可供使用
- boolean JdHotKeyStore.isHotKey(String key)
- Object JdHotKeyStore.get(String key)
- void JdHotKeyStore.smartSet(String key, Object value)
- Object JdHotKeyStore.getValue(String key)
boolean isHotKey(String key) ,该方法会返回该key是否是热key,如果是返回true,如果不是返回false,并且会将key上报到探测集群进行数量计算。该方法通常用于判断只需要判断key是否热、不需要缓存value的场景,如刷子用户、接口访问频率等。
Object get(String key),该方法返回该key本地缓存的value值,可用于判断是热key后,再去获取本地缓存的value值,通常用于redis热key缓存
void smartSet(String key, Object value),方法给热key赋值value,如果是热key,该方法才会赋值,非热key,什么也不做
Object getValue(String key),该方法是一个整合方法,相当于isHotKey和get两个方法的整合,该方法直接返回本地缓存的value。 如果是热key,则存在两种情况,1是返回value,2是返回null。返回null是因为尚未给它set真正的value,返回非null说明已经调用过set方法了,本地缓存value有值了。 如果不是热key,则返回null,并且将key上报到探测集群进行数量探测。
最佳实践:
1 判断用户是否是刷子
if (JdHotKeyStore.isHotKey(“pin__” + thePin)) {//限流他,do your job}
2 判断商品id是否是热点
Object skuInfo = JdHotKeyStore.getValue("skuId__" + skuId);if(skuInfo == null) {JdHotKeyStore.smartSet("skuId__" + skuId, theSkuInfo);} else {//使用缓存好的value即可}
或者这样:
if (JdHotKeyStore.isHotKey(key)) {//注意是get,不是getValue。getValue会获取并上报,get是纯粹的本地获取Object skuInfo = JdHotKeyStore.get("skuId__" + skuId);if(skuInfo == null) {JdHotKeyStore.smartSet("skuId__" + skuId, theSkuInfo);} else {//使用缓存好的value即可}}
综合实践
@RestController
@RequestMapping("/index")
public class IndexController {/*** 热key代码综合实践* @param key* @return*/@RequestMapping("/get/{key}")public Object get(@PathVariable String key) {//key skuId__1String cacheKey = "gorgor_" + key;if (JdHotKeyStore.isHotKey(cacheKey)) {System.out.println("hotkey:"+ cacheKey);//注意是get,不是getValue。getValue会获取并上报,get是纯粹的本地获取Object skuInfo = JdHotKeyStore.get(cacheKey);if (skuInfo == null) {Object theSkuInfo = "123" + "[" + key + "]" + key;JdHotKeyStore.smartSet(cacheKey, theSkuInfo);return theSkuInfo;} else {//使用缓存好的value即可return skuInfo;}//["skuId__1","skuId__2","skuId__3"]} else {System.out.println("not hot:"+ cacheKey);return "123" + "[" + key + "]" + key;//从redis当中获取数据//mysql当中获取数据}}/*** 限流* @return*/@RequestMapping("/get/info")public Object getGoodsInfo(){String cacheKey = "sk_user";//if (JdHotKeyStore.isHotKey(cacheKey)) {System.out.println("hot:"+ cacheKey);return "访问次数太多请稍后再试!";} else {System.out.println("not hot:"+ cacheKey);return "ok";}}
}